Copia de datos con un sistema de archivos como origen o destino mediante Azure Data Factory o Azure Synapse Analytics | Microsoft Docs
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe cómo copiar datos a y desde el sistema de archivos. Para obtener más información, lea el artículo de introducción para Azure Data Factory o Azure Synapse Analytics.
Funcionalidades admitidas
Este conector del sistema de archivos es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/receptor) | ① ② |
| Actividad de búsqueda | ① ② |
| Actividad GetMetadata | ① ② |
| Actividad de eliminación | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
En concreto, este conector de sistema de archivos admite las siguientes funcionalidades:
- Copiar archivos con un recurso compartido de archivos de red como origen o destino. Para usar un recurso compartido de archivos de Linux, instale Samba en el servidor Linux.
- Copiar los archivos con la autenticación de Windows.
- Copiar los archivos tal cual, o bien analizarlos o generarlos, con los códecs de compresión y los formatos de archivo compatibles.
Requisitos previos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado del sistema de archivos mediante la interfaz de usuario
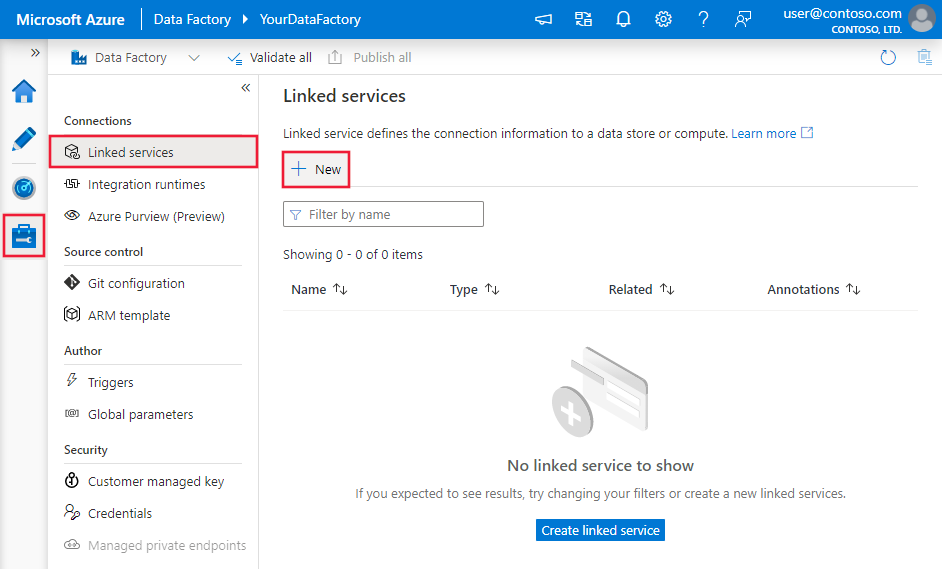
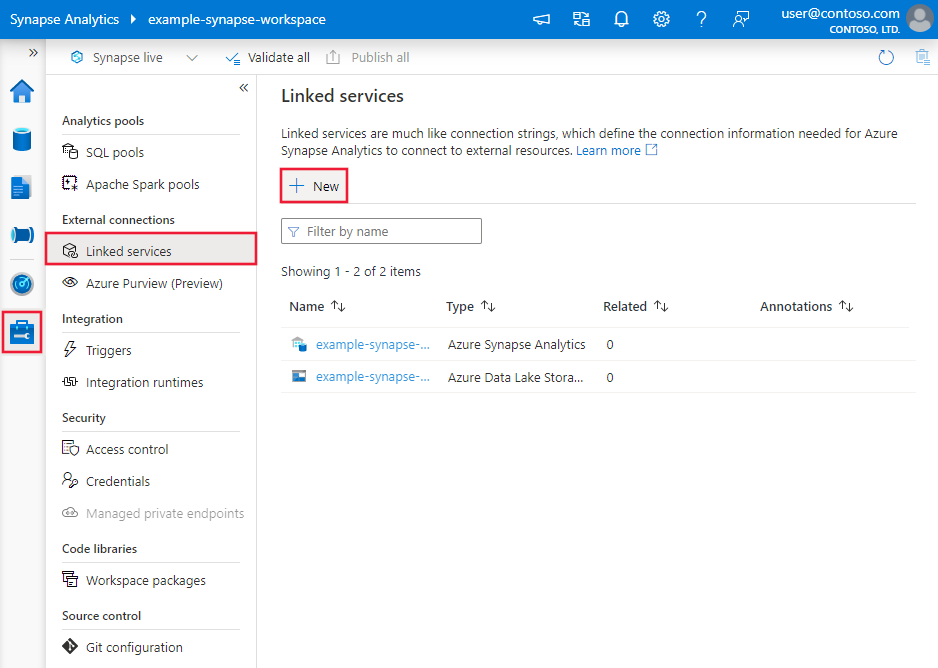
Siga estos pasos para crear un servicio vinculado del sistema de archivos en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar de su área de trabajo de Azure Data Factory o Synapse, y seleccione Servicios vinculados; a continuación, seleccione Nuevo:
Busque el archivo y seleccione el conector del sistema de archivos.
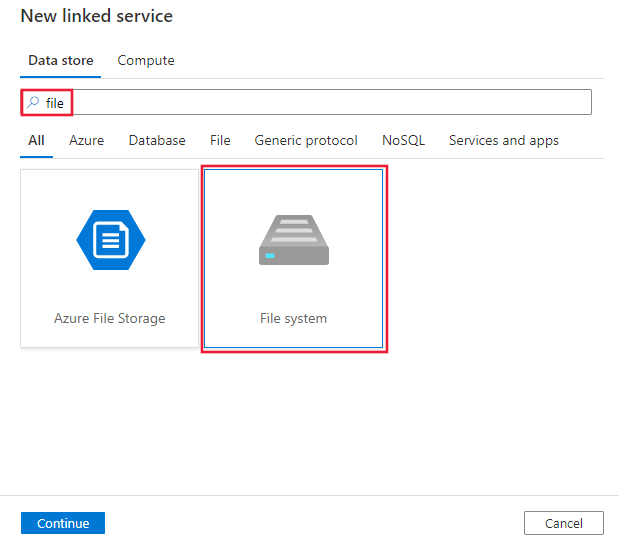
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
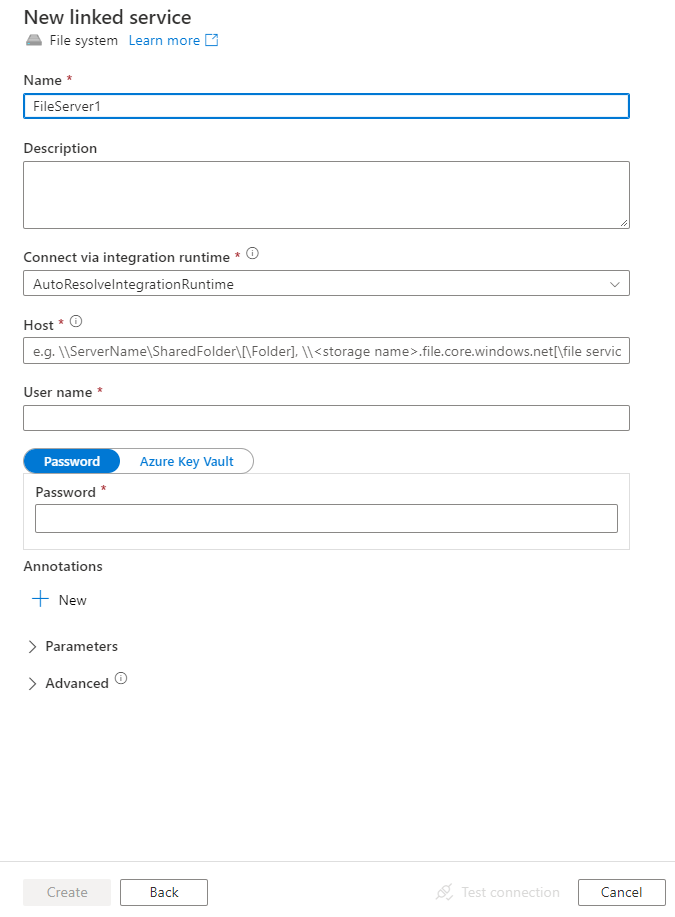
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de canalización de Data Factory y Synapse específicas del sistema de archivos.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de sistema de archivos:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en: FileServer. | Sí |
| host | Especifica la ruta de acceso raíz de la carpeta que quiere copiar. Use el carácter de escape "\" para los caracteres especiales de la cadena. Consulte los casos que se exponen en Ejemplos de definiciones de servicio vinculado y conjunto de datos . | Sí |
| userId | Especifique el identificador del usuario que tiene acceso al servidor. | Sí |
| password | Especifique la contraseña del usuario (userId). Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplos de definiciones de servicio vinculado y conjunto de datos
| Escenario | "host" en definición de servicio vinculado | "folderPath" en definición de conjunto de datos |
|---|---|---|
| Carpeta compartida remota: Ejemplos: \\myserver\share\* o \\myserver\share\carpeta\subcarpeta\* |
En JSON: \\\\myserver\\shareEn la interfaz de usuario: \\myserver\share |
En JSON: .\\ o folder\\subfolderEn la interfaz de usuario: .\ o folder\subfolder |
Nota
Cuando se crean a través de la interfaz de usuario, no es necesario escribir dos barras diagonales (\\) de escape como a través de JSON, solo una barra diagonal inversa.
Nota:
No se permite copiar archivos desde la máquina local en Azure Integration Runtime.
Consulte la línea de comandos aquí para habilitar el acceso a la máquina local en el entorno de ejecución de integración autohospedado. (Está deshabilitada de manera predeterminada).
Ejemplo:
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos.
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para el sistema de archivos en la configuración location del conjunto de datos basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de location en el conjunto de datos se debe establecer en FileServerLocation. |
Sí |
| folderPath | Ruta de acceso a la carpeta. Si quiere usar el carácter comodín para filtrar la carpeta, omita este valor y especifique la configuración del origen de actividad. Tendrá que configurar la ubicación del recurso compartido de archivos en el entorno Windows o Linux para exponer la carpeta para compartirla. | No |
| fileName | Nombre de archivo en la propiedad folderPath indicada. Si quiere usar el carácter comodín para filtrar los archivos, omita este valor y especifique la configuración del origen de actividad. | No |
Ejemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el receptor y el origen de sistema de archivos.
Sistema de archivos como origen
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para el sistema de archivos en la configuración storeSettings del origen de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de storeSettings se debe establecer en FileServerReadSettings. |
Sí |
| Buscar los archivos que se van a copiar: | ||
| OPCIÓN 1: ruta de acceso estática |
Copia de la ruta de acceso de archivo o carpeta especificada en el conjunto de datos. Si quiere copiar todos los archivos de una carpeta, especifique también wildcardFileName como *. |
|
| OPCIÓN 2: filtro del lado servidor - fileFilter |
Filtro nativo del lado servidor de archivos que proporciona un mejor rendimiento que el filtro comodín de la opción 3. Use * para buscar coincidencias con cero o más caracteres y ? para buscar coincidencias con cero o un solo carácter. Obtenga más información sobre la sintaxis y las notas del apartado Comentarios en esta sección. |
No |
| OPCIÓN 3: filtro del lado cliente - wildcardFolderPath |
Ruta de acceso de carpeta con caracteres comodín para filtrar las carpetas de origen. Este filtro se produce dentro del servicio, que enumera las carpetas o archivos en la ruta de acceso especificada y luego se aplica el filtro de caracteres comodín. Los caracteres comodín permitidos son: * (coincide con cero o más caracteres) y ? (coincide con cero o carácter individual); use ^ para el escape si el nombre real de la carpeta tiene un carácter comodín o este carácter de escape dentro. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
No |
| OPCIÓN 3: filtro del lado cliente - wildcardFileName |
Nombre de archivo con caracteres comodín en la propiedad folderPath o wildcardFolderPath indicada para filtrar los archivos de origen. Este filtro se produce dentro del servicio, que enumera los archivos de la ruta de acceso especificada y, a continuación, aplica el filtro comodín. Los caracteres comodín permitidos son: * (coincide con cero o más caracteres) y ? (coincide con cero o carácter individual); use ^ para el escape si el nombre real del archivo tiene un carácter comodín o este carácter de escape dentro.Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
Sí |
| OPCIÓN 3: una lista de archivos - fileListPath |
Indica que se copie un conjunto de archivos determinado. Apunte a un archivo de texto que incluya una lista de los archivos que quiere copiar, con un archivo por línea, que sea la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos. Al utilizar esta opción, no especifique el nombre de archivo en el conjunto de datos. Ver más ejemplos en Ejemplos de lista de archivos. |
No |
| Configuración adicional: | ||
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Cuando recursive se establece en true y el receptor es un almacén basado en archivos, no se crea una carpeta o una subcarpeta vacía en el receptor. Los valores permitidos son: True (valor predeterminado) y False. Esta propiedad no se aplica al configurar fileListPath. |
No |
| deleteFilesAfterCompletion | Indica si los archivos binarios se eliminan del almacén de origen después de pasar correctamente al almacén de destino. La eliminación de archivos es por archivo. Esto significa que cuando se produce un error en la actividad, verá que algunos archivos ya se copiaron en el destino y se eliminaron del origen, mientras que otros siguen estando en el almacén de origen. Esta propiedad solo es válida en el escenario de copia de archivos binarios. El valor predeterminado es false. |
No |
| modifiedDatetimeStart | Filtro de archivos basado en el atributo: Última modificación. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato de YYYY-MM-DDTHH:mm:ssZ. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene el valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora.Esta propiedad no se aplica al configurar fileListPath. |
No |
| modifiedDatetimeEnd | Igual que modifiedDateTimeStart. | No |
| enablePartitionDiscovery | Para archivos con particiones, especifique si desea analizar las particiones de la ruta del archivo y agregarlas como columnas de origen adicionales. Los valores permitidos son false (valor predeterminado) y true. |
No |
| partitionRootPath | Cuando esté habilitada la detección de particiones, especifique la ruta de acceso raíz absoluta para poder leer las carpetas con particiones como columnas de datos. Si no se especifica, de manera predeterminada, - Cuando se usa la ruta de acceso de archivo en un conjunto de datos o una lista de archivos del origen, la ruta de acceso raíz de la partición es la ruta de acceso configurada en el conjunto de datos. - Cuando se usa el filtro de carpeta con caracteres comodín, la ruta de acceso raíz de la partición es la subruta antes del primer carácter comodín. Por ejemplo, supongamos que configura la ruta de acceso en el conjunto de datos como "root/folder/year=2020/month=08/day=27": - Si especifica la ruta de acceso raíz de la partición como "root/folder/year=2020", la actividad de copia genera dos columnas más, month y day, con el valor "08" y "27", respectivamente, además de las columnas de los archivos.- Si no se especifica la ruta de acceso raíz de la partición, no se genera ninguna columna adicional. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Sistema de archivos como receptor
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
Nota:
La opción MergeFiles copyBehavior solo está disponible en canalizaciones de Azure Data Factory y no en canalizaciones de Synapse Analytics.
Las propiedades siguientes se admiten para el sistema de archivos en la configuración storeSettings del receptor de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de storeSettings se debe establecer en FileServerWriteSettings. |
Sí |
| copyBehavior | Define el comportamiento de copia cuando el origen son archivos de un almacén de datos basados en archivos. Los valores permitidos son: - PreserveHierarchy (valor predeterminado): conserva la jerarquía de archivos en la carpeta de destino. La ruta de acceso relativa del archivo de origen que apunta a la carpeta de origen es idéntica a la ruta de acceso relativa del archivo de destino que apunta a la carpeta de destino. - FlattenHierarchy: todos los archivos de la carpeta de origen están en el primer nivel de la carpeta de destino. Los archivos de destino tienen nombres generados automáticamente. - MergeFiles: combina todos los archivos de la carpeta de origen en un archivo. Si se especifica el nombre del archivo, el nombre de archivo combinado es el nombre especificado. De lo contrario, es un nombre de archivo generado automáticamente. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Ejemplos de filtros de carpetas y archivos
Esta sección describe el comportamiento resultante de la ruta de acceso de la carpeta y el nombre de archivo con los filtros de carácter comodín.
| folderPath | fileName | recursive | Resultado de estructura de carpeta de origen y filtro (se recuperan los archivos en negrita) |
|---|---|---|---|
Folder* |
(vacío, usar el valor predeterminado) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(vacío, usar el valor predeterminado) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Ejemplos de lista de archivos
En esta sección se describe el comportamiento resultante de usar la ruta de acceso de la lista de archivos en el origen de la actividad de copia.
Suponga que tiene la siguiente estructura de carpetas de origen y quiere copiar los archivos en negrita:
| Estructura de origen de ejemplo | Contenido de FileListToCopy.txt | Configuración de canalizaciones |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadatos FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
En el conjunto de datos: - Ruta de acceso a la carpeta: root/FolderAEn origen de la actividad de copia: - Ruta de acceso de la lista de archivos: root/Metadata/FileListToCopy.txt La ruta de acceso de la lista de archivos apunta a un archivo de texto en el mismo almacén de datos. Incluye una lista de archivos que desea copiar. Cada línea contiene la ruta de acceso relativa al archivo en función de la ruta de acceso raíz configurada en el conjunto de datos. |
Ejemplos de recursive y copyBehavior
En esta sección se describe el comportamiento resultante de la operación de copia para diferentes combinaciones de valores recursive y copyBehavior.
| recursive | copyBehavior | Estructura de carpetas de origen | Destino resultante |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la misma estructura que el origen: Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5. |
| true | flattenHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la estructura siguiente: Folder1 nombre de archivo generado automáticamente para File1 nombre de archivo generado automáticamente para File2 nombre de archivo generado automáticamente para File3 nombre de archivo generado automáticamente para File4 nombre de archivo generado automáticamente para File5 |
| true | mergeFiles | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la estructura siguiente: Folder1 El contenido de File1 + File2 + File3 + File4 + File 5 se combina en un archivo con un nombre generado automáticamente |
| false | preserveHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la estructura siguiente: Folder1 Archivo1 Archivo2 No se selecciona la subcarpeta Subfolder1, que contiene los archivos File3, File4 y File5. |
| false | flattenHierarchy | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la estructura siguiente: Folder1 nombre de archivo generado automáticamente para File1 nombre de archivo generado automáticamente para File2 No se selecciona la subcarpeta Subfolder1, que contiene los archivos File3, File4 y File5. |
| false | mergeFiles | Folder1 Archivo1 Archivo2 Subfolder1 File3 File4 File5 |
La carpeta de destino Folder1 se crea con la estructura siguiente: Folder1 El contenido de File1 + File2 se combina en un archivo con un nombre de archivo generado automáticamente. nombre de archivo generado automáticamente para File1 No se selecciona la subcarpeta Subfolder1, que contiene los archivos File3, File4 y File5. |
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte la actividad GetMetadata.
Propiedades de la actividad de eliminación
Para información detallada sobre las propiedades, consulte Actividad de eliminación.
Modelos heredados
Nota
Estos modelos siguen siendo compatibles con versiones anteriores. Se recomienda usar de ahora en adelante el nuevo modelo que se menciona en las secciones anteriores; además, la interfaz de usuario de creación ha pasado a generar el nuevo modelo.
Modelo de conjunto de datos heredado
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en: FileShare | Sí |
| folderPath | Ruta de acceso a la carpeta. Se admiten filtros con caracteres comodín. Los caracteres comodín permitidos son: * (coincide con cero o más caracteres) y ? (coincide con cero o carácter individual); use ^ para el escape si el nombre real de la carpeta tiene un carácter comodín o este carácter de escape dentro. Ejemplos: rootfolder/subcarpeta/ver más en Ejemplos de definiciones de servicio vinculado y conjunto de datos y Ejemplos de filtros de carpetas y archivos. |
No |
| fileName | Filtro de nombre o de carácter comodín para los archivos de la ruta "folderPath" especificada. Si no especifica ningún valor para esta propiedad, el conjunto de datos apunta a todos los archivos de la carpeta. Para filtrar, los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter).- Ejemplo 1: "fileName": "*.csv"- Ejemplo 2: "fileName": "???20180427.txt"Use ^ como escape si el nombre de archivo real contiene un comodín o este carácter de escape.Cuando fileName no se especifica para un conjunto de datos de salida y preserveHierarchy no se determina en el receptor de la actividad, la actividad de copia generará automáticamente el nombre de archivo con el siguiente patrón: "Data.[GUID del identificador de la ejecución de actividad].[GUID si FlattenHierarchy].[formato, si está configurado].[compresión, si está configurada] "; por ejemplo, "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Si realiza una copia desde el origen tabular usando el nombre de la tabla en vez de la consulta, el patrón de nomenclatura es " [nombre de tabla].[formato].[compresión, si está configurada] "; por ejemplo, "miTabla.csv". |
No |
| modifiedDatetimeStart | Filtro de archivos basado en el atributo: Última modificación. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato de YYYY-MM-DDTHH:mm:ssZ. Tenga en cuenta que el rendimiento general del movimiento de datos se verá afectado si habilita esta configuración cuando quiera filtrar archivos de grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene el valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora. |
No |
| modifiedDatetimeEnd | Filtro de archivos basado en el atributo: Última modificación. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart, y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato "2018-12-01T05:00:00Z". Tenga en cuenta que el rendimiento general del movimiento de datos se verá afectado si habilita esta configuración cuando quiera filtrar archivos de grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene el valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene el valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea inferior al valor de fecha y hora. |
No |
| format | Si desea copiar los archivos tal cual entre los almacenes basados en archivos (copia binaria), omita la sección de formato en las definiciones de los conjuntos de datos de entrada y salida. Si quiere analizar o generar archivos con un formato concreto, se admiten los siguientes tipos de formato de archivo: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Establezca la propiedad type de formato en uno de los siguientes valores. Para más información, consulte las secciones Formato de texto, Formato Json, Formato Avro, Formato Orc y Formato Parquet. |
No (solo para el escenario de copia binaria) |
| compression | Especifique el tipo y el nivel de compresión de los datos. Para más información, consulte el artículo sobre códecs de compresión y formatos de archivo compatibles. Estos son los tipos que se admiten: GZip, Deflate, BZip2 y ZipDeflate. Estos son los niveles que se admiten: Optimal y Fastest. |
No |
Sugerencia
Para copiar todos los archivos en una carpeta, especifique solo folderPath.
Para copiar un único archivo con un nombre determinado, especifique folderPath con el elemento de carpeta y fileName con el nombre de archivo.
Para copiar un subconjunto de archivos en una carpeta, especifique folderPath con el elemento de carpeta y fileName con el filtro de comodín.
Nota
Si estaba usando la propiedad "fileFilter" para el filtro de archivos, esta todavía se admite como está, aunque se le sugiere que use la nueva funcionalidad de filtro agregada a "fileName" de ahora en adelante.
Ejemplo:
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origen de actividad de copia heredada
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en: FileSystemSource | Sí |
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Tenga en cuenta que cuando recursiva se establece en true y el receptor está en el almacén basado en archivos, no se copian o crean carpetas vacías o subcarpetas en el receptor. Los valores permitidos son: True (valor predeterminado) y False |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modelo de receptor de actividad de copia heredada
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en: FileSystemSink | Sí |
| copyBehavior | Define el comportamiento de copia cuando el origen son archivos del almacén de datos basados en archivos. Los valores permitidos son: - PreserveHierarchy (valor predeterminado): conserva la jerarquía de archivos en la carpeta de destino. La ruta de acceso relativa del archivo de origen que apunta a la carpeta de origen es idéntica a la ruta de acceso relativa del archivo de destino que apunta a la carpeta de destino. - FlattenHierarchy: todos los archivos de la carpeta de origen están en el primer nivel de la carpeta de destino. Los nombres de archivo de destino se generan automáticamente. - MergeFiles: combina todos los archivos de la carpeta de origen en un archivo. No se realiza ninguna desduplicación de registros durante la combinación. Si se especifica el nombre de archivo, el nombre de archivo combinado sería el nombre especificado; de lo contrario, sería el nombre de archivo generado automáticamente. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.