Enriquecimiento con IA en Azure AI Search
En Azure AI Search, el enriquecimiento con IA hace referencia a la integración con los servicios de Azure AI para procesar el contenido que no se puede buscar en su forma sin procesar. Mediante el enriquecimiento, el análisis y la inferencia se usan para crear contenido y estructura que permiten búsquedas en los que antes no existía ninguno.
Dado que Búsqueda de Azure AI se usa para consultas de texto y vectores, el propósito del enriquecimiento con IA es mejorar la utilidad del contenido en escenarios relacionados con la búsqueda. El contenido sin procesar debe ser texto o imágenes (no se pueden enriquecer vectores), pero la salida de una canalización de enriquecimiento se puede vectorizar e indexar en un índice de vectores mediante capacidades como la capacidad de División de texto para la fragmentación y la capacidad AzureOpenAIEmbedding para la codificación. Para obtener más información sobre el uso de aptitudes en escenarios vectoriales, consulte Fragmentación e inserción de datos integrados.
El enriquecimiento con IA se basa en capacidades.
Las capacidades integradas usan los servicios de Azure AI. Aplican las siguientes transformaciones y procesamiento al contenido sin procesar:
- Traducción y detección de idioma para la búsqueda multilingüe
- Reconocimiento de entidades para extraer nombres de personas, lugares y otras entidades de grandes fragmentos de texto
- Extracción de frases clave para identificar y extraer términos importantes
- Reconocimiento óptico de caracteres (OCR) para reconocer texto impreso y manuscrito en archivos binarios
- Análisis de imágenes para describir el contenido de la imagen y generar las descripciones en forma de campos de texto en los que se pueden realizar búsquedas
Las aptitudes personalizadas ejecutan el código externo. Las aptitudes personalizadas se pueden usar para cualquier procesamiento personalizado que quiera incluir en la canalización.
El enriquecimiento con IA es una extensión de una canalización de indizador que se conecta a orígenes de datos de Azure. Una canalización de enriquecimiento tiene todos los componentes de una canalización de indexador (indexador, origen de datos, índice), además de un conjunto de aptitudes que especifica los pasos del enriquecimiento atómico.
En el diagrama siguiente se muestra la progresión del enriquecimiento con IA:
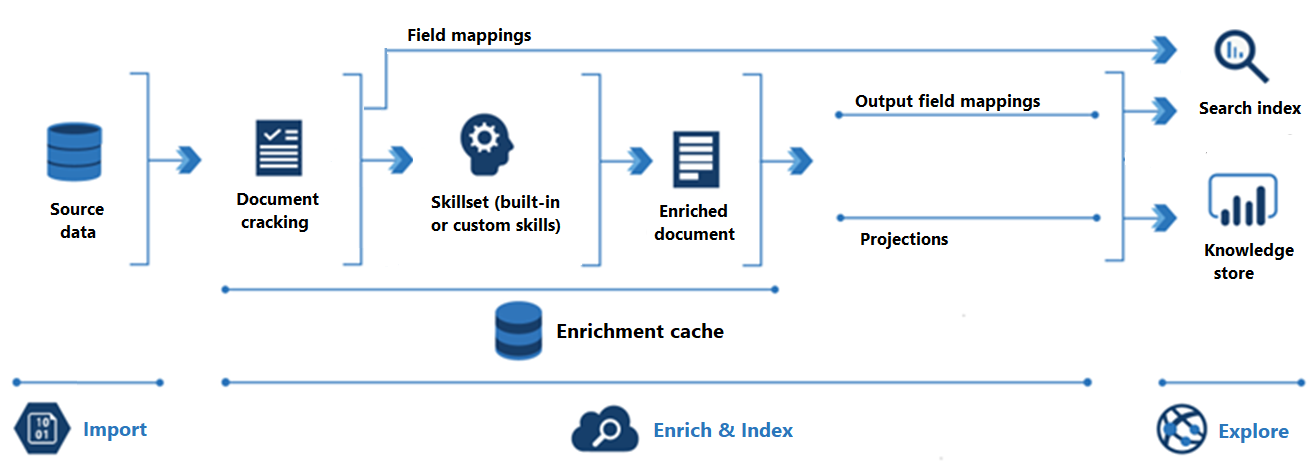
La importación es el primer paso. Aquí, el indexador se conecta a un origen de datos y extrae contenido (documentos) al servicio de búsqueda. Azure Blob Storage es el recurso más común que se usa en escenarios de enriquecimiento con IA, pero cualquier origen de datos compatible puede proporcionar contenido.
Enriquecer y crear índice cubre la mayoría de la canalización de enriquecimiento con IA:
El enriquecimiento se inicia cuando el indexador "descifra documentos" y extrae sus imágenes y texto. El tipo de procesamiento que se produce a continuación depende tanto de los datos como de las aptitudes que se hayan agregado a un conjunto de aptitudes. Si hay imágenes, se pueden reenviar a las aptitudes que realizan el procesamiento de imágenes. El contenido de texto se pone en cola para el procesamiento tanto de texto como de lenguaje natural. Internamente, las aptitudes crean un "documento enriquecido" que recopila las transformaciones a medida que se producen.
El contenido enriquecido se genera durante la ejecución del conjunto de aptitudes y es temporal a menos que lo guarde. Puede habilitar una caché de enriquecimiento para conservar documentos y salidas de aptitudes descifrados para su reutilización posterior durante futuras ejecuciones del conjunto de aptitudes.
Para obtener contenido en un índice de búsqueda, el indexador debe tener información de asignación para enviar contenido enriquecido al campo de destino. Las asignaciones de campos (explícitas o implícitas) establecen la ruta de acceso de datos de origen a un índice de búsqueda. Las asignaciones de campos de salida establecen la ruta de acceso de datos de los documentos enriquecidos a un índice.
La indexación es el proceso en el que se ingiere contenido sin procesar y enriquecido en las estructuras de datos físicas de un índice de búsqueda (sus archivos y carpetas). El análisis léxico y la tokenización se producen en este paso.
La exploración es el último paso. La salida siempre es un índice de búsqueda que se puede consultar desde una aplicación cliente. Opcionalmente, la salida puede ser un almacén de conocimiento que conste de blobs y tablas en Azure Storage a los que se accede a través de herramientas de exploración de datos o procesos de bajada. Si va a crear un almacén de conocimiento, las proyecciones determinan la ruta de acceso de datos para el contenido enriquecido. El mismo contenido enriquecido puede aparecer tanto en índices como en almacenes de conocimiento.
Cuándo usar el enriquecimiento con IA
El enriquecimiento es útil si su contenido sin procesar es texto no estructurado, contenido de imagen o contenido que requiere detección y traducción de idiomas. La aplicación de inteligencia artificial a través de las aptitudes integradas puede desbloquear este contenido para la búsqueda de texto completo y las aplicaciones de ciencia de datos.
También puede crear aptitudes personalizadas para proporcionar procesamiento externo. El código de terceros, interno o de código abierto se puede integrar en la canalización como una aptitud personalizada. Los modelos de clasificación que identifican las características destacadas de varios tipos de documento se encuentran en esta categoría, pero se puede usar cualquier paquete externo que agregue valor al contenido.
Casos de uso de las aptitudes integradas
Las aptitudes integradas se basan en las API de los servicios de Azure AI: Computer Vision de Azure AI y Servicio de lenguaje. A menos que su entrada de contenido sea pequeña, espere adjuntar un recurso facturable de servicios de Azure AI para ejecutar cargas de trabajo mayores.
Los conjuntos de aptitudes que se ensamblan mediante aptitudes integradas son apropiados para los siguientes escenarios de la aplicación:
Las aptitudes de procesamiento de imágenes incluyen reconocimiento óptico de caracteres (OCR) e identificación de características visuales, como detección facial, interpretación de imágenes, reconocimiento de imágenes (personas famosas y puntos de referencia) o atributos como la orientación de la imagen. Estas aptitudes crean representaciones de texto del contenido de la imagen para la búsqueda de texto completo en Azure AI Search.
La traducción automática la proporciona la aptitud de traducción de texto, que a menudo se empareja con la detección de idioma para las soluciones multilingües.
El procesamiento de lenguaje natural analiza fragmentos de texto. Las aptitudes de esta categoría incluyen Reconocimiento de entidades, Detección de sentimiento (incluida la minería de opiniones) y Detección de información de identificación personal. Con estas aptitudes, un texto no estructurado se asigna como campos en los que se pueden realizar búsquedas y aplicar filtros en un índice.
Casos de uso de las aptitudes personalizadas
Las aptitudes personalizadas ejecutan código externo que usted proporciona y que se encapsula en la interfaz web de aptitudes personalizadas. Puede encontrar varios ejemplos de aptitudes personalizadas en el repositorio azure-search-power-skills de GitHub.
Las aptitudes personalizadas no siempre son complejas. Por ejemplo, si tiene un paquete existente que proporciona la coincidencia de patrones o un modelo de clasificación de documentos, puede ajustarlo en una aptitud personalizada.
Almacenamiento de la salida
En Azure AI Search, un indizador guarda el resultado que crea. En una sola ejecución de un indexador se pueden crear hasta tres estructuras de datos que contengan salida enriquecida e indexada.
| Almacén de datos | Obligatorio | Location | Descripción |
|---|---|---|---|
| índice en el que se pueden realizar búsquedas | Obligatorio | Servicio de búsqueda | Se usa para la búsqueda de texto completo y otros formularios de consulta. La especificación de un índice es un requisito del indexador. El contenido del índice se rellena a partir de salidas de la aptitud, además de los campos de origen que se asignan directamente a los campos del índice. |
| almacén de conocimiento | Opcional | Azure Storage | Se usa para aplicaciones de nivel inferior, como la minería de conocimiento o ciencia de datos. Los almacenes de conocimiento se definen dentro de conjuntos de aptitudes. Su definición determina si los documentos enriquecidos se proyectan como tablas u objetos (archivos o blobs) en Azure Storage. |
| caché de enriquecimiento | Opcional | Azure Storage | Se usa para almacenar en caché enriquecimientos, con el fin de reutilizarlos en ejecuciones posteriores del conjunto de aptitudes. La caché almacena contenido importado y sin procesar (documentos descifrados). También almacena los documentos enriquecidos creados durante la ejecución del conjunto de aptitudes. El almacenamiento en caché es útil si se usan el análisis de imágenes o el OCR, y se desea ahorrar el tiempo y los gastos derivados de tener que procesar de nuevo los archivos de imagen. |
Los índices y los almacenes de conocimiento son totalmente independientes entre sí. Aunque debe adjuntar un índice para satisfacer los requisitos del indexador, si su único objetivo es un almacén de conocimiento, puede omitir el índice una vez rellenado.
Exploración del contenido
Tras definir y cargar un índice de búsqueda o un almacén de conocimiento, puede explorar sus datos.
Realización de consultas en un índice de búsqueda
Ejecute consultas para acceder al contenido enriquecido generado por la canalización. El índice es similar a cualquier otro que pueda crear para Azure AI Search: puede complementar análisis de texto con analizadores personalizados, invocar consultas de búsqueda aproximada, agregar filtros o experimentar con perfiles de puntuación para ajustar la pertinencia de la búsqueda.
Uso de herramientas de exploración de datos en un almacén de conocimiento
En Azure Storage, un almacén de conocimiento puede asumir las siguientes formas: un contenedor de blobs de un documento JSON, un contenedor de blobs de objetos de imagen o tablas en Table Storage. Puede usar Explorador de Storage, Power BI o cualquier aplicación que se conecte a Azure Storage para acceder al contenido.
Un contenedor de blobs captura documentos enriquecidos en su totalidad, lo que resulta útil si va a crear una fuente en otros procesos.
Una tabla es útil si necesita segmentos de documentos enriquecidos o si desea incluir o excluir partes específicas de la salida. Para el análisis en Power BI, las tablas son el origen de datos recomendado para la exploración y visualización de datos en Power BI.
Disponibilidad y precios
El enriquecimiento está disponible en las regiones que tienen servicios de Azure AI. Puede comprobar la disponibilidad del enriquecimiento en la página de lista de regiones.
La facturación sigue un modelo de precios de pago por uso. Los costos del uso de aptitudes integradas se pasan cuando se especifica una clave de servicios de Azure AI de varias regiones en el conjunto de aptitudes. También hay costos asociados con la extracción de imágenes, según la medición de Azure AI Search. Sin embargo, la extracción de texto y las aptitudes de utilidad no son facturables. Para más información, consulte Modo de cobro por Azure AI Search.
Lista de comprobación: un flujo de trabajo típico
Una canalización de enriquecimiento consta de indexadores que tienen conjuntos de aptitudes. Después de la indexación, puede consultar un índice para validar los resultados.
Comience con un subconjunto de datos en un origen de datos admitido. El diseño del indexador y del conjunto de aptitudes es un proceso iterativo. El trabajo va más rápido con un pequeño conjunto de datos representativo.
Cree un origen de datos que especifique una conexión con sus datos.
Cree un conjunto de aptitudes. A menos que el proyecto sea pequeño, debe asociar un recurso de varios servicios de Azure AI. Si va a crear un almacén de conocimiento, defínalo en el conjunto de aptitudes.
Cree un esquema de índice que defina un índice de búsqueda.
Cree un indexador y ejecútelo para reunir todos los componentes anteriores. Este paso recupera los datos, ejecuta el conjunto de aptitudes y carga el índice.
Un indexador también es el lugar en el que se especifican las asignaciones de campos y las asignaciones de campos de salida que configuran la ruta de acceso de datos en un índice de búsqueda.
Opcionalmente, habilite el almacenamiento en caché del enriquecimiento en la configuración del indexador. Este paso le permite volver a utilizar más adelante los enriquecimientos existentes.
Ejecute consultas para evaluar los resultados o iniciar una sesión de depuración para trabajar con cualquier problema del conjunto de aptitudes.
Para repetir cualquiera de los pasos anteriores, restablezca el indexador antes de ejecutarlo. También puede eliminar y volver a crear los objetos en cada ejecución (recomendado si usa el nivel Gratis). Si ha habilitado el almacenamiento en caché, el indizador extraerá datos de la caché si los datos no se han modificado en el origen y si sus modificaciones en la canalización no invalidan la caché.
Pasos siguientes
- Inicio rápido: Creación de un conjunto de aptitudes para el enriquecimiento con IA
- Tutorial: Información sobre las API de REST de enriquecimiento con IA
- Conceptos de conjunto de aptitudes
- Conceptos del almacén de conocimiento
- Creación de un conjunto de aptitudes
- Creación de un almacén de conocimiento