Seguridad en Azure AI Search
En Azure, confiabilidad significa resistencia y disponibilidad si hay una interrupción o degradación del servicio. En Azure AI Search, la confiabilidad se puede lograr dentro de un único servicio o a través de varios servicios de búsqueda en regiones independientes.
Implementa un único servicio de búsqueda y que escale verticalmente para lograr una alta disponibilidad. Puedes agregar varias réplicas para controlar cargas de trabajo de consulta y indexación superiores. Si el servicio de búsqueda admite zonas de disponibilidad, las réplicas se aprovisionan automáticamente en diferentes centros de datos físicos para una resistencia adicional.
Implementar varios servicios de búsqueda en diferentes regiones geográficas. Todas las cargas de trabajo de búsqueda están totalmente contenidas en un único servicio que se ejecuta en una sola región geográfica, pero en un escenario de varios servicios, tiene opciones para sincronizar contenido para que sea el mismo en todos los servicios. También se puede configurar una solución de equilibrio de carga para redistribuir solicitudes o conmutar por error si hay una interrupción del servicio.
Para la continuidad empresarial y la recuperación de desastres en un nivel regional, se planea una topología entre regiones, que consta de varios servicios de búsqueda que tienen una configuración y contenido idénticos. El código o script personalizado proporciona el mecanismo de conmutación por error a un servicio de búsqueda alternativo si de repente uno deja de estar disponible.
Alta disponibilidad
En Azure AI Search, las réplicas son copias del índice. Un servicio de búsqueda se encarga de al menos una réplica y puede tener hasta 12. Añadir réplicas permite que Azure AI Search realice tareas de reinicio y mantenimiento de la máquina en una réplica, mientras que la ejecución de consultas continúa en otras.
Para cada servicio de búsqueda individual, Microsoft garantiza al menos un 99,9 % de disponibilidad para las configuraciones que cumplen estos criterios:
Dos réplicas para alta disponibilidad de cargas de trabajo de solo lectura (consultas)
Tres o más réplicas para lograr alta disponibilidad de las cargas de trabajo de lectura-escritura (consultas e indexación)
El sistema tiene mecanismos internos para supervisar el estado de la réplica y la integridad de las particiones. Si pones a disposición una combinación específica de réplicas y particiones, el sistema garantiza ese nivel de capacidad para el servicio.
No se proporciona ningún acuerdo de nivel de servicio para el nivel Gratis. Para más información, consulte SLA para Búsqueda de Azure AI.
Compatibilidad de zonas de disponibilidad
Availability Zones es una capacidad de la plataforma de Azure que divide los centros de datos de una región en grupos de ubicaciones físicas distintos para proporcionar alta disponibilidad, dentro de la misma región. En Azure AI Search, las réplicas individuales son las unidades de asignación de zona. Un servicio de búsqueda se ejecuta dentro de una región; sus réplicas se ejecutan en diferentes centros de datos físicos (o zonas) dentro de esa región.
Las zonas de disponibilidad se usan al agregar dos o más réplicas al servicio de búsqueda. Cada réplica se coloca en una zona de disponibilidad distinta dentro de la región. Si tiene más réplicas que zonas de disponibilidad en cada región de servicio de búsqueda, las réplicas se distribuirán entre esas zonas lo más uniformemente posible. No hay ninguna acción específica que se deba hacer, excepto crear un servicio de búsqueda en una región que proporciona zonas de disponibilidad y, a continuación, configurar el servicio para que use varias réplicas.
Requisitos previos
- El nivel de servicio debe ser Estándar o superior.
- La región del servicio debe estar en una región que tenga zonas disponibles (enumeradas en la sección siguiente).
- La configuración debe incluir varias réplicas: dos para cargas de trabajo de consulta de solo lectura y tres para cargas de trabajo de lectura y escritura que incluyan la indexación.
Regiones admitidas
La compatibilidad con zonas de disponibilidad depende de la infraestructura y el almacenamiento. Actualmente, la siguiente zona no tiene almacenamiento suficiente y no proporciona una zona de disponibilidad para Búsqueda de Azure AI:
- Japón Occidental
De lo contrario, se admiten zonas de disponibilidad para la Búsqueda de Azure AI en las siguientes regiones:
| Region | Fecha de lanzamiento |
|---|---|
| Este de Australia | 30 de enero de 2021 o posterior |
| Sur de Brasil | 2 de mayo de 2021 o posterior |
| Centro de Canadá | 30 de enero de 2021 o posterior |
| Centro de la India | 20 de enero de 2022 o posterior |
| Centro de EE. UU. | 4 de diciembre de 2020 o posterior |
| Norte de China 3 | 7 de septiembre de 2022 o posterior |
| Este de Asia | 13 de enero de 2022 o posterior |
| Este de EE. UU. | 27 de enero de 2021 o posterior |
| Este de EE. UU. 2 | 30 de enero de 2021 o posterior |
| Centro de Francia | 23 de octubre de 2020 o posterior |
| Centro-oeste de Alemania | 3 de mayo de 2021 o posterior |
| Centro de Israel | 1 de abril de 2024 o después |
| Norte de Italia | 1 de abril de 2024 o después |
| Japón Oriental | 30 de enero de 2021 o posterior |
| Centro de Corea del Sur | 20 de enero de 2022 o posterior |
| Norte de Europa | 28 de enero de 2021 o posterior |
| Este de Noruega | 20 de enero de 2022 o posterior |
| Centro de Catar | 25 de agosto de 2022 o posterior |
| Norte de Sudáfrica | 7 de septiembre de 2022 o posterior |
| Centro-sur de EE. UU. | 30 de abril de 2021 o posterior |
| Sudeste de Asia | 31 de enero de 2021 o posterior |
| Centro de Suecia | 21 de enero de 2022 o posterior |
| Norte de Suiza | 7 de septiembre de 2022 o posterior |
| Norte de Emiratos Árabes Unidos | 9 de septiembre de 2022 o posterior |
| Sur de Reino Unido | 30 de enero de 2021 o posterior |
| US Gov - Virginia | 30 de abril de 2021 o posterior |
| Oeste de Europa | 29 de enero de 2021 o posterior |
| Oeste de EE. UU. 2 | 30 de enero de 2021 o posterior |
| Oeste de EE. UU. 3 | 2 de junio de 2021 o posterior |
Nota:
Las zonas de disponibilidad no cambian los términos del Acuerdo de Nivel de Servicio. Todavía necesita tres o más réplicas para lograr la alta disponibilidad de las consultas.
Varios servicios en regiones geográficas independientes
La redundancia del servicio es necesaria si los requisitos operativos incluyen:
Requisitos de continuidad empresarial y recuperación ante desastres (BCDR). Azure AI Search no proporciona conmutación por error instantánea si se produce una interrupción del servicio.
Rendimiento rápido para una aplicación distribuida globalmente. Si las solicitudes de consulta e indexación proceden de todo el mundo, los usuarios más cercanos al centro de datos del host tendrán un rendimiento más rápido. Crear servicios adicionales en regiones cercanas a estos usuarios puede igualar el rendimiento de todos los usuarios.
Si se necesitan dos servicios de búsqueda más, crearlos en regiones diferentes puede cumplir los requisitos de la aplicación para la continuidad y la recuperación, así como tiempos de respuesta más rápidos para una base de usuarios global.
Azure AI Search no proporciona actualmente ningún método automatizado para la replicación de índices de búsqueda entre regiones geográficas, pero hay algunas técnicas que permiten simplificar la implementación y administración de este proceso. Estas técnicas se describen en las siguientes secciones.
El objetivo de un conjunto de servicios de búsqueda distribuido geográficamente es tener dos o más índices disponibles en dos o más regiones, en las que un usuario se enruta al servicio Azure AI Search que proporciona la latencia más baja:
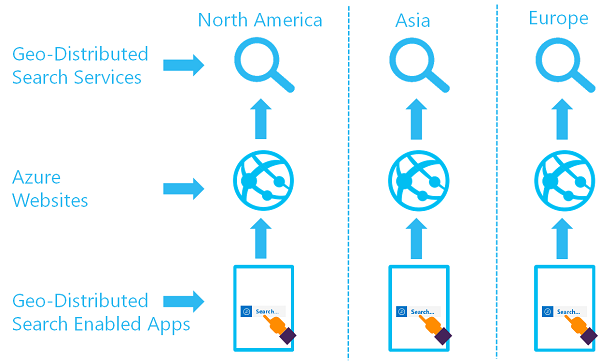
Puede implementar esta arquitectura mediante la creación de varios servicios y el diseño de una estrategia para la sincronización de datos. Opcionalmente, puede incluir un recurso como Azure Traffic Manager para las solicitudes de enrutamiento.
Sugerencia
Para recibir ayuda para implementar varios servicios de búsqueda en varias regiones, consulta este ejemplo de Bicep en GitHub que implementa una solución de búsqueda multirregional totalmente configurada. El ejemplo proporciona dos opciones para la sincronización de índices y la redirección de solicitudes mediante Traffic Manager.
Sincronizar datos en varios dispositivos
Hay dos opciones para mantener sincronizados dos o más servicios de búsqueda distintos:
- Extraer las actualizaciones de contenido en un índice de búsqueda mediante un indexador.
- Insertar contenido en un índice mediante la API de Agregar o actualizar documentos (REST) o una API equivalente de Azure SDK.
Para configurar cualquiera de las opciones, se recomienda usar el script de Bicep de ejemplo en el repositorio azure-search-multiple-region modificado en las regiones y las estrategias de indexación.
Opción 1: uso de indexadores para la actualización de contenido en varios servicios
Si ya utiliza un indexador en un servicio, puede configurar un segundo indexador en un segundo servicio para que use el mismo objeto de origen de datos, de modo que extraería datos de la misma ubicación. Cada servicio de cada región tiene su propio indexador y un índice de destino (el índice de búsqueda no se comparte, lo que significa que cada índice tiene su propia copia de los datos), pero cada indexador hace referencia al mismo origen de datos.
Este es un objeto visual de alto nivel del aspecto que podría tener esa arquitectura.
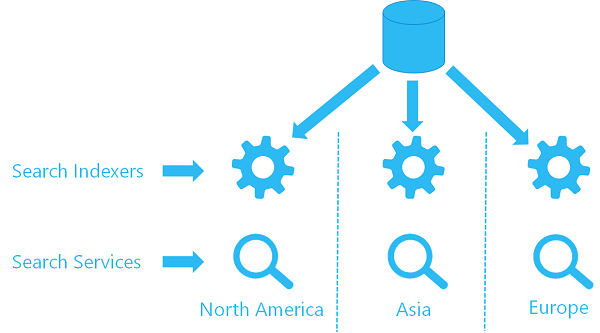
Opción 2: uso de las API REST para insertar actualizaciones de contenido en varios servicios
Si se usa la API de REST de Azure AI Search para insertar contenido en el índice de búsqueda y se quieren mantener sincronizados los distintos servicios de búsqueda, se tienen que insertar los cambios en todos los servicios de búsqueda cada vez que se necesite una actualización. En el código, asegúrese de controlar los casos en los que una actualización en un servicio de búsqueda produce un error, pero se ejecuta correctamente en otros servicios de búsqueda.
Conmutar por error o redirigir solicitudes de consulta
Si es necesaria una redundancia en el nivel de solicitud, Azure proporciona varias opciones de equilibrio de carga :
- Azure Traffic Manager permite enrutar solicitudes a diversos sitios web de diferente geográfica atendidos por distintos servicios de búsqueda.
- Application Gateway permite equilibrar la carga entre los servidores de una región en la capa de aplicación.
- Azure Front Door permite optimizar el enrutamiento global del tráfico web y proporcionar conmutación por error global.
Algunos puntos que se deben tener en cuenta al evaluar las opciones de equilibrio de carga:
Search es un servicio back-end que acepta solicitudes de consulta e indexación de un cliente.
Las solicitudes del cliente a un servicio de búsqueda deben autenticarse. Para acceder a las operaciones de búsqueda, el autor de la llamada debe tener permisos basados en roles o proporcionar una clave de API en la solicitud.
Los puntos de conexión de servicio se alcanzan a través de una conexión a Internet pública de forma predeterminada. Si se configura un punto de conexión privado para las conexiones de cliente que se originan desde dentro de una red virtual, se debe usar la puerta de enlace de aplicación.
Azure AI Search acepta solicitudes dirigidas al punto de conexión
<your-search-service-name>.search.windows.net. Si llegas al mismo punto de conexión mediante un nombre DNS diferente en el encabezado de host, como un CNAME, se rechaza la solicitud.
Azure AI Search proporciona un ejemplo de implementación de varias regiones que usa Azure Traffic Manager para el redireccionamiento de solicitudes si se produce un error en el punto de conexión principal. Esta solución es útil cuando se enruta a un cliente habilitado para búsqueda que solo llama a un servicio de búsqueda en la misma región.
Azure Traffic Manager se usa principalmente para enrutar el tráfico de red entre distintos puntos de conexión en función de métodos de enrutamiento específicos (como prioridad, rendimiento o ubicación geográfica). Actúa en el nivel DNS para dirigir las solicitudes entrantes al punto de conexión adecuado. Si un punto de conexión que Traffic Manager está atendiendo comienza a rechazar las solicitudes, el tráfico se enruta a otro punto de conexión.
Traffic Manager no proporciona un punto de conexión para una conexión directa a Azure AI Search, lo que significa que no se puede colocar un servicio de búsqueda directamente detrás de Traffic Manager. En su lugar, la suposición es que las solicitudes fluyen al Traffic Manager, luego a un cliente web habilitado para búsqueda y, por último, a un servicio de búsqueda en el back-end. El cliente y el servicio se encuentran en la misma región. Si un servicio de búsqueda deja de funcionar, el cliente de búsqueda comienza a generar errores y Traffic Manager redirige al cliente restante.
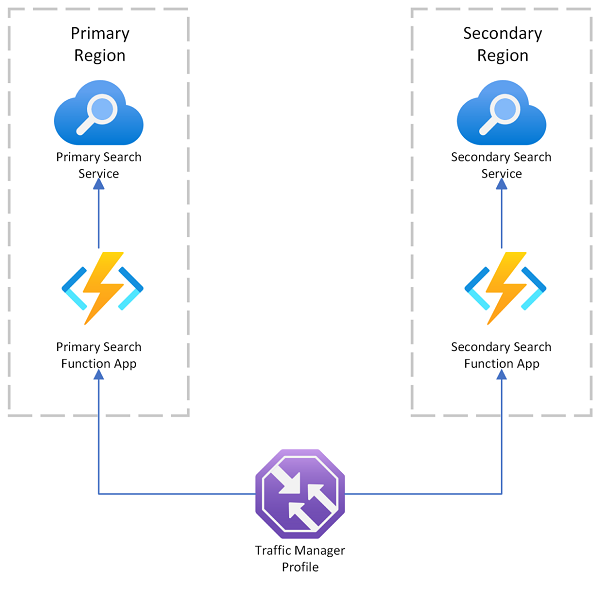
Residencia de datos en una implementación de varias regiones
Al implementar varios servicios de búsqueda en varias regiones geográficas, el contenido se almacena en la región que eligió para cada servicio de búsqueda.
Búsqueda de Azure AI no almacena datos fuera de la región especificada sin tu autorización. La autorización está implícita cuando estas características se escriben en un recurso de Azure Storage: caché de enriquecimiento, sesión de depuración y almacén de conocimiento. En todos los casos, la cuenta de almacenamiento es la que se proporciona, en la región que tu elijas.
Nota:
Si la cuenta de almacenamiento y el servicio de búsqueda están en la misma región, el tráfico de red entre ambos utiliza una dirección IP privada y transcurre por la red troncal de Microsoft. Al utilizarse direcciones IP privadas, no puede configurar firewalls de IP ni un punto de conexión privado para la seguridad de red. En su lugar, utilice la excepción de servicio de confianza como alternativa cuando ambos servicios estén en la misma región.
Acerca de las interrupciones del servicio y los eventos catastróficos
Como se indica en el SLA, Microsoft garantiza un alto nivel de disponibilidad de las solicitudes de consulta de índices cuando una instancia de servicio de Búsqueda de Azure AI se configura con dos o más réplicas, y de las solicitudes de actualización de índices cuando una instancia de servicio de Búsqueda de Azure AI se configura con tres o más réplicas. Sin embargo, no hay ningún mecanismo integrado para la recuperación ante desastres. Si se requiere continuidad del servicio en caso de un error catastrófico que quede fuera del control de Microsoft, se recomienda aprovisionar un segundo servicio adicional en otra región e implementar una estrategia de replicación geográfica para asegurarse de que los índices sean totalmente redundantes en todos los servicios.
Los clientes que usen indexadores para rellenar y actualizar índices pueden controlar la recuperación ante desastres mediante indexadores geográficos que recuperan datos del mismo origen de datos. Dos servicios en regiones diferentes, donde cada uno ejecuta un indizador, pueden indexar desde el mismo origen de datos para lograr redundancia geográfica. Si se indexa desde orígenes de datos que también tienen redundancia geográfica, hay que tener en cuenta que los indexadores de Azure AI Search solo pueden realizar una indexación incremental (fusión de actualizaciones a partir de documentos nuevos, modificados o eliminados) desde las réplicas principales. En un evento de conmutación por error, debes asegurarte de que el indizador apunte de nuevo a la nueva réplica principal.
Si no utiliza indexadores, usaría el código de la aplicación para enviar objetos y datos a distintos servicios de búsqueda en paralelo. Para más información, consulte Sincronizar datos entre varios servicios.
Alternativas de copia de seguridad y restauración
Una estrategia de continuidad empresarial para la capa de datos incluye normalmente un paso de restauración a partir de la copia de seguridad. Dado que Azure AI Search no es una solución de almacenamiento de datos principal, Microsoft no proporciona un mecanismo formal de restaurar y crear copias de seguridad de autoservicio. Sin embargo, puede usar el ejemplo de código index-backup-restore de este repositorio de ejemplo .NET de Azure AI Search para realizar la copia de seguridad de una definición de índice y una instantánea en una serie de archivos JSON y, después, usar esos archivos para restaurar el índice, en caso de que sea necesario. Esta herramienta también se puede usar para mover índices entre niveles de servicio.
De lo contrario, el código de aplicación que se usa para crear y rellenar un índice es la opción de restauración de facto si elimina por error un índice. Para volver a generar un índice, elimínelo (si existe), vuelva a crear el índice en el servicio y cárguelo de nuevo recuperando los datos del almacén de datos principal.
Contenido relacionado
- Para más información acerca de los planes de tarifa y los límites de los servicios de cada uno de ellos, consulte Límites de servicio.
- Consulte Planear la capacidad para obtener información acerca de las combinaciones de particiones y réplicas.
- Consulte Caso práctico: Usar Cognitive Search para admitir escenarios complejos de inteligencia artificial para obtener una guía de configuración.