Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, usará cuadernos con el Entorno de ejecución de Spark para transformar y preparar los datos sin procesar en el lakehouse.
Requisitos previos
Si no tiene una instancia de Lakehouse que contenga datos, debe:
Preparar los datos
En los pasos anteriores del tutorial, tenemos datos sin procesar ingeridos desde el origen hasta la sección Archivos del almacén de lago. Ahora puede transformar esos datos y prepararlos para crear tablas delta.
Descargue los cuadernos de la carpeta Código fuente del tutorial de Lakehouse.
Abra el área de trabajo y seleccione Importar>bloc de notas>desde este equipo.
Seleccione Importar cuaderno en la sección Nuevo de la parte superior de la página de aterrizaje.
Seleccione Cargar en el panel Estado de importación que se abre en el lado derecho de la pantalla.
Seleccione todos los cuadernos que descargó en el primer paso de esta sección.
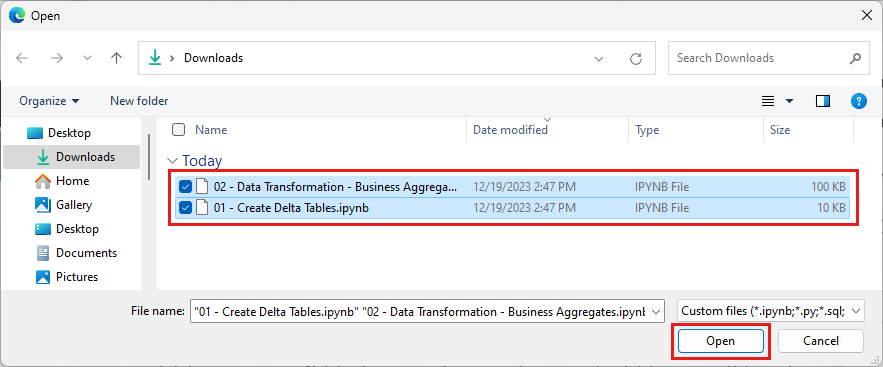
Seleccione Abrir. Una notificación que indica el estado de la importación aparece en la esquina superior derecha de la ventana del explorador.
Una vez que la importación se realiza correctamente, vaya a la vista de elementos del área de trabajo y ver los cuadernos recién importados. Seleccione el almacén de lago wwilakehouse para abrirlo.
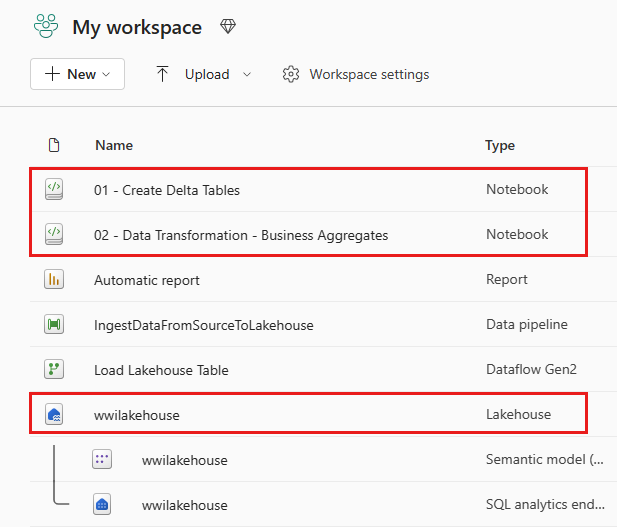
Una vez que se abra el almacén de lago wwilakehouse, seleccione Abrir cuaderno>Cuaderno existente en el menú de navegación superior.
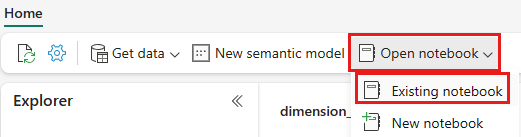
En la lista de cuadernos existentes, seleccione el cuaderno 01 - Crear tablas delta y seleccione Abrir.
En el cuaderno abierto en el Explorador del almacén de lago, verá que ya está vinculado al almacén de lago abierto.
Nota:
Fabric proporciona la funcionalidad de orden V para escribir archivos Delta Lake optimizados. El orden V a menudo mejora la compresión de tres a cuatro veces y hasta diez veces la aceleración del rendimiento en los archivos Delta Lake que no están optimizados. Spark en Fabric optimiza dinámicamente las particiones al generar archivos con un tamaño predeterminado de 128 MB. El tamaño del archivo de destino se puede cambiar según los requisitos de carga de trabajo mediante configuraciones.
Con la capacidad para optimizar escritura, el motor de Apache Spark reduce el número de archivos escritos y tiene como objetivo aumentar el tamaño de archivo individual de los datos escritos.
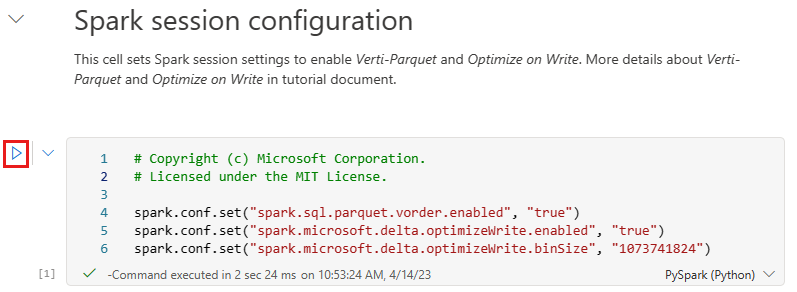
Antes de escribir datos como tablas Delta Lake en la sección Tablas del almacén de lago, use dos características de Fabric (orden V y Optimizar escritura) para la escritura de datos optimizada y para mejorar el rendimiento de lectura. Para habilitar estas características en la sesión, establezca estas configuraciones en la primera celda del cuaderno.
Para iniciar el cuaderno y ejecutar todas las celdas en secuencia, seleccione Ejecutar todo en la cinta superior (en Inicio). O bien, para ejecutar solo código desde una celda específica, seleccione el icono Ejecutar que aparece a la izquierda de la celda al mantener el puntero, o presione MAYÚS + ENTRAR en el teclado mientras el control está en la celda.
Al ejecutar una celda, no tiene que especificar los detalles del clúster o grupo de Spark subyacente, ya que Fabric los proporciona a través de un Grupo activo. Cada área de trabajo de Fabric incluye un grupo de Spark predeterminado, denominado Grupo activo. Esto significa que, al crear cuadernos, no tiene que preocuparse por especificar ninguna configuración de Spark ni detalles del clúster. Al ejecutar el primer comando de cuaderno, el grupo activo estará en funcionamiento en unos segundos. Y se establece la sesión de Spark y comienza a ejecutar el código. La ejecución de código posterior es casi instantánea en este cuaderno mientras la sesión de Spark esté activa.
A continuación, leerá datos sin procesar de la sección Archivos del almacén de lago y agregará más columnas para diferentes partes de fecha como parte de la transformación. Por último, use la API de Spark partitionBy para particionar los datos antes de escribirlos en formato de tabla delta en función de las columnas de elementos de datos recién creadas (Año y Trimestre).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Después de cargar las tablas de hechos, puede pasar a cargar datos para el resto de las dimensiones. En la celda siguiente se crea una función para leer datos sin procesar de la sección Archivos del almacén de lago para cada uno de los nombres de tabla pasados como parámetro. A continuación, se crea una lista de tablas de dimensiones. Por último, recorre en bucle la lista de tablas y crea una tabla delta para cada nombre de tabla que se lee del parámetro de entrada. Tenga en cuenta que el script elimina la columna denominada
Photoen este ejemplo porque la columna no se utiliza.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Para validar las tablas creadas, haga clic con el botón derecho y seleccione Actualizar en el almacén de lago wwilakehouse. Aparecen las tablas.
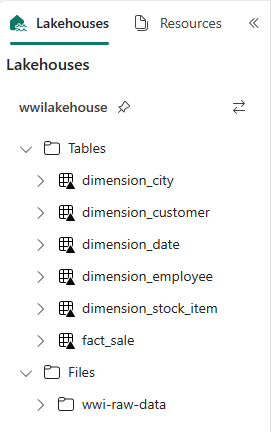
Vuelva a ir a la vista de elementos del área de trabajo y seleccione el almacén de lago wwilakehouse para abrirlo.
Ahora, abra el segundo cuaderno. En la vista de almacén de lago, seleccione Abrir cuaderno>Cuaderno existente en la cinta de opciones.
En la lista de cuadernos existentes, seleccione el cuaderno 02 - Transformación de datos: empresa para abrirlo.
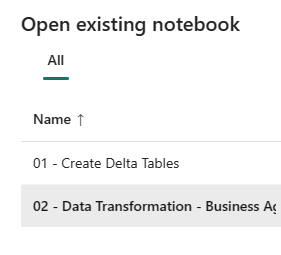
En el cuaderno abierto en el Explorador del almacén de lago, verá que ya está vinculado al almacén de lago abierto.
Una organización podría tener ingenieros de datos que trabajen con Scala/Python y otros ingenieros de datos que trabajen con SQL (Spark SQL o T-SQL), todos trabajando en la misma copia de los datos. Fabric permite que estos diferentes grupos, con una experiencia y preferencia variadas, trabajen y colaboren. Los dos enfoques diferentes transforman y generan agregados empresariales. Puede elegir el adecuado para usted o mezclar y combinar estos enfoques en función de sus preferencias sin poner en peligro el rendimiento:
Enfoque 1: use PySpark para combinar y agregar datos para generar agregados empresariales. Este enfoque es preferible para alguien con experiencia en programación (Python o PySpark).
Enfoque 2: use Spark SQL para combinar y agregar datos para generar agregados empresariales. Este enfoque es preferible para alguien con experiencia en SQL y que está realizando la transición a Spark.
Enfoque 1 (sale_by_date_city): use PySpark para combinar y agregar datos para generar agregados empresariales. Con el código siguiente, se crean tres dataframes de Spark diferentes, cada uno de las cuales hace referencia a una tabla delta existente. A continuación, puede combinar estas tablas mediante los dataframes, “agrupar por” para generar la agregación, cambiar el nombre de algunas de las columnas y, por último, escribirla como una tabla delta en la sección Tablas del almacén de lago para conservar los datos.
En esta celda, creará tres dataframes de Spark diferentes, cada uno de las cuales hace referencia a una tabla delta existente.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Agregue el código siguiente a la misma celda para combinar estas tablas mediante los dataframes creados antes. Use "Agrupar por" para generar la agregación, cambiar el nombre de algunas de las columnas y, por último, escribirla como una tabla Delta en la sección Tablas del almacén de lago de datos.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Enfoque 2 (sale_by_date_employee): use Spark SQL para combinar y agregar datos para generar agregados empresariales. Con el código siguiente, se crea una vista temporal de Spark mediante la combinación de tres tablas, se “agrupa por” para generar la agregación y se cambia el nombre de algunas de las columnas. Por último, leerá la vista temporal de Spark y la escribirá como una tabla delta en la sección Tablas del almacén de lago para conservarlo con los datos.
En esta celda, creará una vista temporal de Spark mediante la combinación de tres tablas, “agrupará por” para generar una agregación y cambiará el nombre de algunas de las columnas.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCEn esta celda, leerá de la vista temporal de Spark creada en la celda anterior y, por último, la escribirá como una tabla delta en la sección Tablas del almacén de lago.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Para validar las tablas creadas, haga clic con el botón derecho y seleccione Actualizar en el almacén de lago wwilakehouse. Aparecen las tablas agregadas.
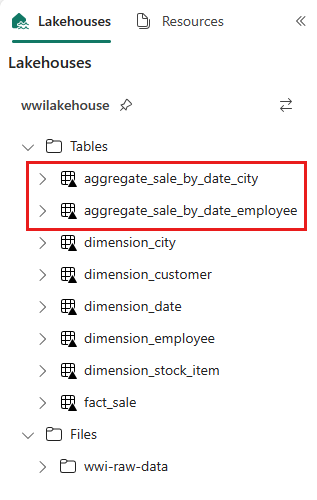







Los dos enfoques producen un resultado similar. Puede elegir en enfoque que se adapte mejor a su experiencia y a sus preferencias, para minimizar la necesidad de aprender una nueva tecnología o poner en peligro el rendimiento.
También puede notar que está escribiendo datos como archivos Delta Lake. La característica automática de detección y registro de tablas de Fabric los recoge y registra en la tienda de metadatos. No es necesario llamar a las instrucciones CREATE TABLE explícitamente para crear tablas que se usarán con SQL.