What is a data lake?
A data lake is a storage repository that holds a large amount of data in its native, raw format. Data lake stores are optimized for scaling their size to terabytes and petabytes of data. The data typically comes from multiple diverse sources and can include structured, semi-structured, or unstructured data. A data lake helps you store everything in its original, untransformed state. This method differs from a traditional data warehouse, which transforms and processes data at the time of ingestion.
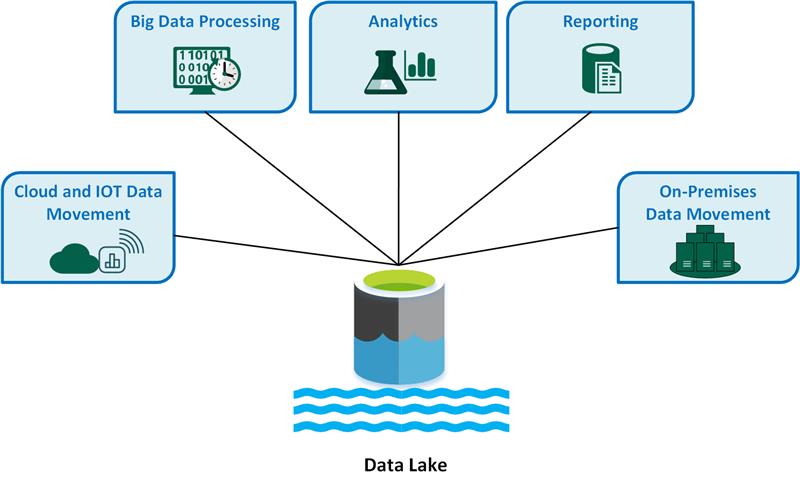
Key data lake use cases include:
- Cloud and Internet of Things (IoT) data movement.
- Big data processing.
- Analytics.
- Reporting.
- On-premises data movement.
Consider the following advantages of a data lake:
A data lake never deletes data because it stores data in its raw format. This feature is especially useful in a big data environment because you might not know in advance what insights you can get from the data.
Users can explore the data and create their own queries.
A data lake might be faster than traditional extract, transform, load (ETL) tools.
A data lake is more flexible than a data warehouse because it can store unstructured and semi-structured data.
A complete data lake solution consists of both storage and processing. Data lake storage is designed for fault tolerance, infinite scalability, and high-throughput ingestion of various shapes and sizes of data. Data lake processing involves one or more processing engines that can incorporate these goals and can operate on data that's stored in a data lake at scale.
When you should use a data lake
We recommend that you use a data lake for data exploration, data analytics, and machine learning.
A data lake can act as the data source for a data warehouse. When you use this method, the data lake ingests raw data and then transforms it into a structured queryable format. Typically, this transformation uses an extract, load, transform (ELT) pipeline in which the data is ingested and transformed in place. Relational source data might go directly into the data warehouse via an ETL process and skip the data lake.
You can use data lake stores in event streaming or IoT scenarios because data lakes can persist large amounts of relational and nonrelational data without transformation or schema definition. Data lakes can handle high volumes of small writes at low latency and are optimized for massive throughput.
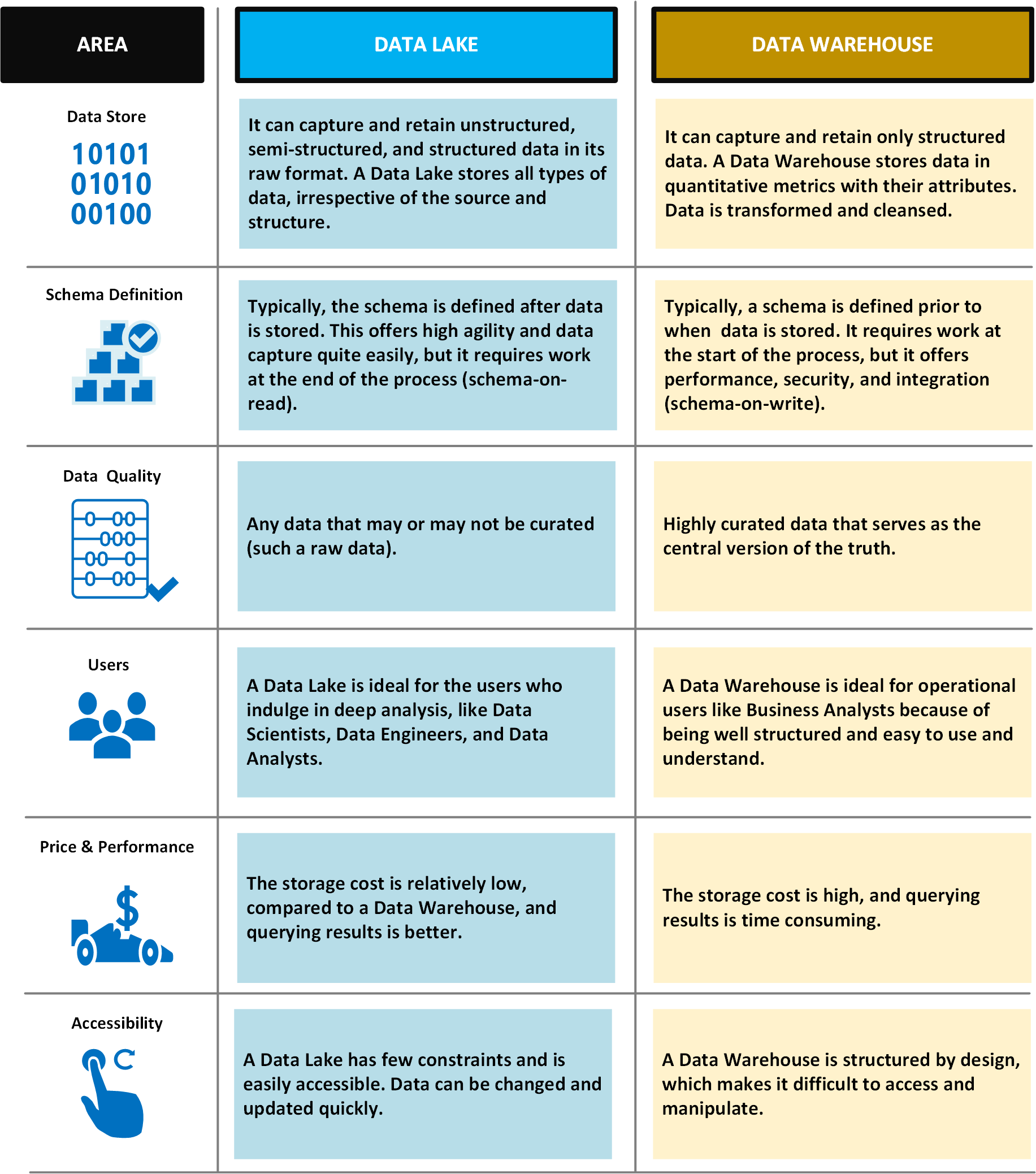
The following table compares data lakes and data warehouses.
Challenges
Large volumes of data: The management of vast amounts of raw and unstructured data can be complex and resource-intensive, so you need robust infrastructure and tools.
Potential bottlenecks: Data processing can introduce delays and inefficiencies, especially when you have high volumes of data and diverse data types.
Data corruption risks: Improper data validation and monitoring introduces a risk of data corruption, which can compromise the integrity of the data lake.
Quality control problems: Proper data quality is a challenge because of the variety of data sources and formats. You must implement stringent data governance practices.
Performance problems: Query performance can degrade as the data lake grows, so you must optimize storage and processing strategies.
Technology choices
When you build a comprehensive data lake solution on Azure, consider the following technologies:
Azure Data Lake Storage combines Azure Blob Storage with data lake capabilities, which provides Apache Hadoop-compatible access, hierarchical namespace capabilities, and enhanced security for efficient big data analytics.
Azure Databricks is a unified platform that you can use to process, store, analyze, and monetize data. It supports ETL processes, dashboards, security, data exploration, machine learning, and generative AI.
Azure Synapse Analytics is a unified service that you can use to ingest, explore, prepare, manage, and serve data for immediate business intelligence and machine learning needs. It integrates deeply with Azure data lakes so that you can query and analyze large datasets efficiently.
Azure Data Factory is a cloud-based data integration service that you can use to create data-driven workflows to then orchestrate and automate data movement and transformation.
Microsoft Fabric is a comprehensive data platform that unifies data engineering, data science, data warehousing, real-time analytics, and business intelligence into a single solution.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Avijit Prasad | Cloud Consultant
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- What is OneLake?
- Introduction to Data Lake Storage
- Azure Data Lake Analytics documentation
- Training: Introduction to Data Lake Storage
- Integration of Hadoop and Azure Data Lake Storage
- Connect to Data Lake Storage and Blob Storage
- Load data into Data Lake Storage with Azure Data Factory