Canalizaciones y actividades en Azure Data Factory y Azure Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Importante
La compatibilidad con Estudio de Azure Machine Learning (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
Desde el 1 de diciembre de 2021, no se puede crear nuevos recursos de Estudio de Machine Learning (clásico) (área de trabajo y plan de servicio web). Hasta el 31 de agosto de 2024, podrá seguir usando los experimentos y servicios web existentes de Estudio de Machine Learning (clásico). Para más información, vea:
- Migración a Azure Machine Learning desde Estudio de Machine Learning (clásico)
- ¿Qué es Azure Machine Learning?
La documentación de Machine Learning Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
Este artículo ayuda a conocer las canalizaciones y actividades de Azure Data Factory y Azure Synapse Analytics y a usarlas para construir flujos de trabajo controlados por datos de un extremo para los escenarios de procesamiento de datos y movimiento de datos.
Información general
Una instancia de Data Factory o un área de trabajo de Synapse puede tener una o varias canalizaciones. Una canalización es una agrupación lógica de actividades que realizan una tarea. Por ejemplo, una canalización puede contener un conjunto de actividades que ingieren y limpian los datos de registro y, a continuación, inician un flujo de datos de asignación para analizar los datos de registro. La canalización permite administrar las actividades como un conjunto en lugar de hacerlo individualmente. Puede implementar y programar la canalización en lugar de las actividades de forma independiente.
Las actividades de una canalización definen las acciones que se van a realizar en los datos. Por ejemplo, puede utilizar una actividad de copia para copiar datos de SQL Server en una instancia de Azure Blob Storage. A continuación, use una actividad de flujo de datos o una actividad de cuaderno de Databricks para procesar y transformar datos de Blob Storage a un grupo de Azure Synapse Analytics sobre el que se crean las soluciones de informes de inteligencia empresarial.
Azure Data Factory y Azure Synapse Analytics tienen tres agrupaciones de actividades: actividades de movimiento de datos, actividades de transformación de datos y actividades de control. Una actividad puede tomar diversos conjuntos de datos, o ninguno, y generar uno o varios conjuntos de datos. En el siguiente diagrama se muestra la relación entre la canalización, la actividad y el conjunto de datos:

Un conjunto de datos de entrada representa la entrada para una actividad de la canalización y un conjunto de datos de salida representa la salida de la actividad. Los conjuntos de datos identifican datos en distintos almacenes de datos, como tablas, archivos, carpetas y documentos. Después de crear un conjunto de datos, puede usarlo con las actividades de una canalización. Por ejemplo, un conjunto de datos puede ser un conjunto de datos de entrada y salida de una actividad de copia o una actividad de HDInsightHive. Para obtener más información sobre los conjuntos de datos, vea el artículo Conjuntos de datos en Azure Data Factory.
Nota:
Hay un límite temporal predeterminado de 80 actividades como máximo por canalización, que incluye actividades internas para contenedores.
Actividades de movimiento de datos
Copiar actividad en Data Factory realiza una copia de los datos de un almacén de datos de origen a uno receptor. Data Factory admite los almacenes de datos que se muestran en la tabla de esta sección. Se pueden escribir datos desde cualquier origen en todos los tipos de receptores.
Para obtener más información, consulte el artículo Información general de la actividad de copia.
Haga clic en un almacén de datos para obtener información sobre cómo copiar datos a un almacén como origen o destino.
Nota
Si un conector está marcado como versión preliminar, puede probarlo y enviarnos sus comentarios. Si quiere tener una dependencia de los conectores de versión preliminar de la solución, póngase en contacto con el servicio de soporte técnico de Azure.
Actividades de transformación de datos
Azure Data Factory y Azure Synapse Analytics admiten las siguientes actividades de transformación que se pueden agregar tanto individualmente como encadenadas a otra actividad.
Para obtener más información, consulte el artículo sobre las actividades de transformación de datos.
| Actividad de transformación de datos | Entorno de procesos |
|---|---|
| Flujo de datos | Clústeres de Apache Spark administrados por Azure Data Factory |
| Función de Azure | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| de Hadoop | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Actividades de ML Studio (clásico): ejecución de lotes y recurso de actualización | Azure VM |
| Procedimiento almacenado | Azure SQL, Azure Synapse Analytics o SQL Server |
| U-SQL | Análisis con Azure Data Lake |
| Actividad personalizada | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Actividad de Jar en Databricks | Azure Databricks |
| Actividad de Python en Databricks | Azure Databricks |
| Actividad de Cuaderno de Synapse | Azure Synapse Analytics |
Actividades de flujo de control
Se admiten las siguientes actividades de flujo de control:
| Actividad de control | Descripción |
|---|---|
| Append Variable | Agrega un valor a una variable de matriz existente. |
| Execute Pipeline | La actividad Execute Pipeline permite que una canalización de Data Factory o Synapse invoque otra. |
| Filter | Aplicar una expresión de filtro a una matriz de entrada |
| For Each | La actividad ForEach define un flujo de control repetido en la canalización. Esta actividad se usa para iterar una colección y ejecuta las actividades especificadas en un bucle. La implementación del bucle de esta actividad es similar a la estructura del bucle ForEach de los lenguajes de programación. |
| Get Metadata (Obtener metadatos) | La actividad GetMetadata se puede usar para recuperar metadatos de cualquier dato en una canalización de Data Factory o Synapse. |
| Actividad If Condition | La condición If puede usarse para crear una rama basada en una condición que evalúa como true o false. La actividad de la condición IF proporciona la misma funcionalidad que proporciona una instrucción If en lenguajes de programación. Evalúa un conjunto de actividades cuando la condición se evalúa como true y otro conjunto de actividades cuando la condición se evalúa como false.. |
| Actividad Lookup | La actividad de búsqueda puede usarse para leer o buscar un registro, un nombre de tabla o un valor de cualquier origen externo. Además, las actividades posteriores pueden hacer referencia a esta salida. |
| Set Variable | Establece el valor de una variable existente. |
| Actividad Until | Implementa el bucle Do-Until, que es similar a la estructura de bucle Do-Until de los lenguajes de programación. Ejecuta un conjunto de actividades en un bucle hasta que la condición asociada a la actividad la evalúa como "true". Puede especificar un valor de tiempo de espera para la actividad Until. |
| Actividad de validación | Asegúrese de que una canalización solo continúa la ejecución si existe un conjunto datos de referencia, cumple los criterios especificados o se ha alcanzado el tiempo de espera. |
| Actividad Wait | Cuando use una actividad Wait en una canalización, esta espera durante el tiempo especificado antes de continuar con la ejecución de actividades sucesivas. |
| Actividad web | La actividad Web puede usarse para llamar a un punto de conexión REST personalizado desde una canalización. Puede pasar conjuntos de datos y servicios vinculados que la actividad consumirá y a los que tendrá acceso. |
| Actividad de webhook | Use la actividad de webhook para llamar a un punto de conexión y pasar una dirección URL de devolución de llamada. La ejecución de canalización espera a que la devolución de llamada se invoque antes de continuar con la siguiente actividad. |
Creación de una canalización con UI
Para crear una canalización, vaya a la pestaña Creador de Data Factory Studio (representada por el icono de lápiz), haga clic en el signo más, elija Canalización en el menú y, nuevamente, Canalización en el submenú.
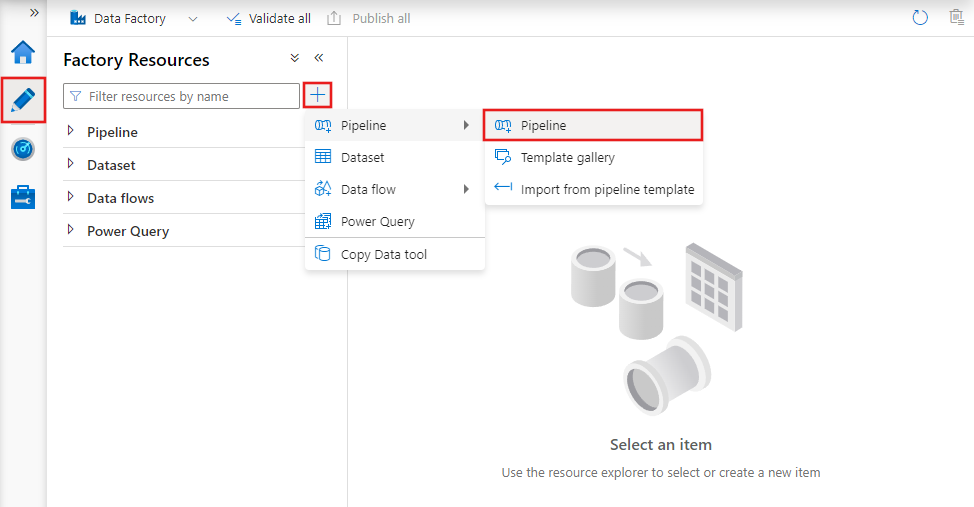
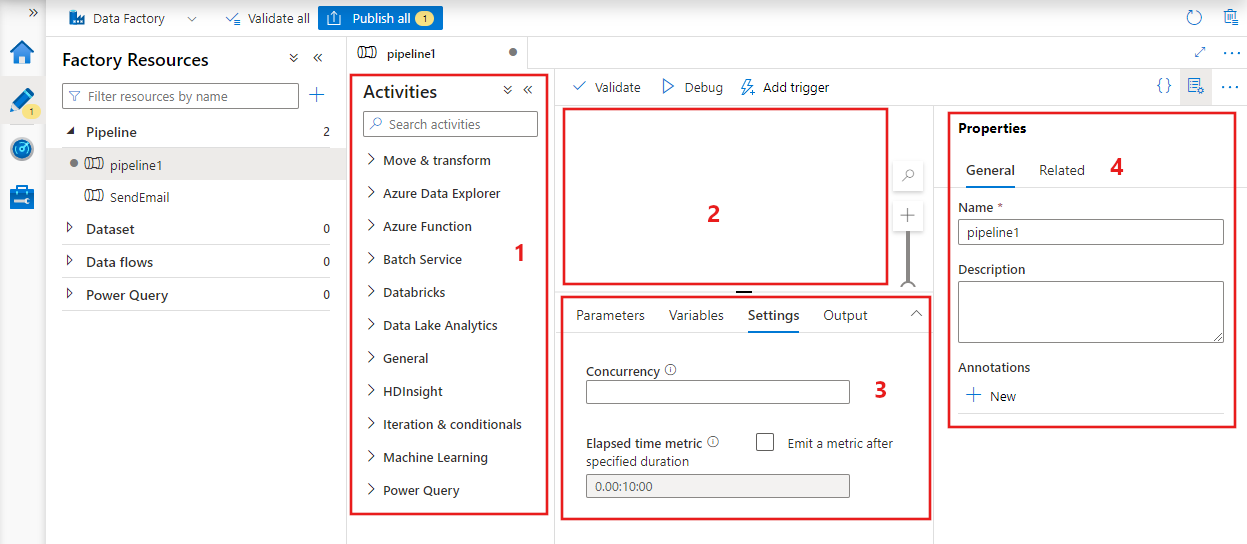
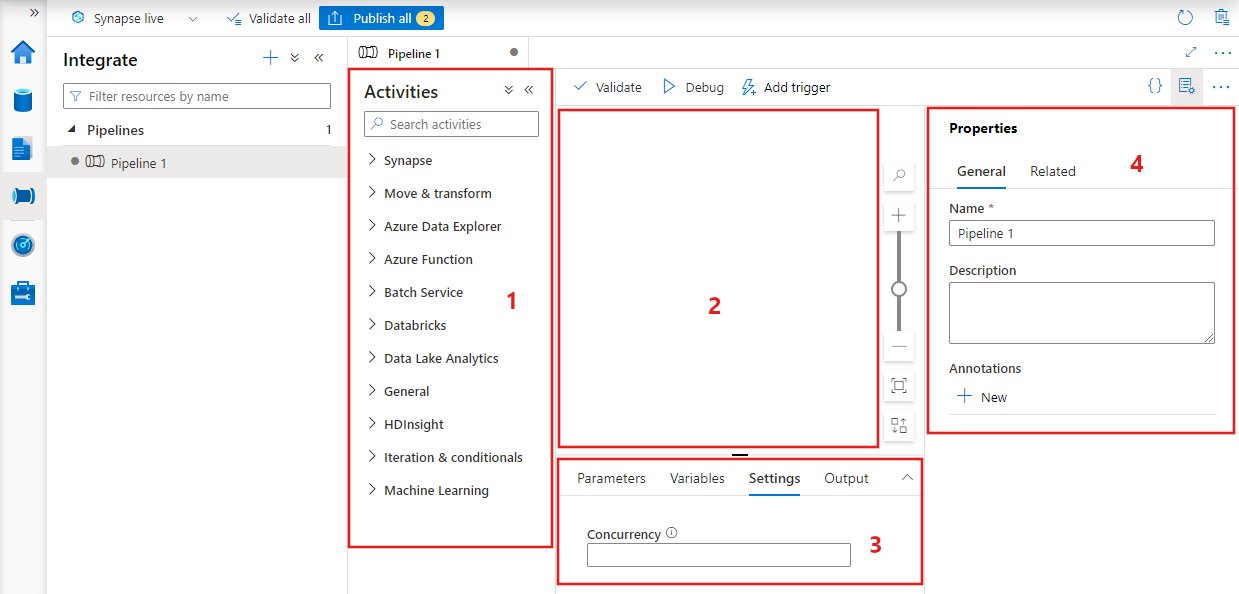
Data Factory mostrará el editor de canalizaciones, en el que puede encontrar:
- Todas las actividades que se pueden usar dentro de la canalización.
- El lienzo del editor de canalizaciones, en el que aparecerán las actividades cuando se agreguen a la canalización.
- El panel de configuraciones de la canalización, incluidos los parámetros, las variables, la configuración general y la salida.
- El panel de propiedades de la canalización, en el que se pueden configurar el nombre de la canalización, la descripción opcional y las anotaciones. Este panel también mostrará los elementos relacionados con la canalización dentro de la factoría de datos.
JSON de canalización
Aquí encontrará cómo se define una canalización en formato JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Etiqueta | Descripción | Type | Obligatorios |
|---|---|---|---|
| name | Nombre de la canalización. Especifique un nombre que represente la acción que realizará la canalización.
|
Cadena | Sí |
| description | Especifique el texto que describe para qué se usa la canalización. | String | No |
| activities | La sección activities puede contener una o más actividades definidas. Consulte la sección JSON de actividades para obtener más información sobre el elemento JSON de actividades. | Array | Sí |
| parámetros | La sección parámetros puede tener uno o varios de los parámetros definidos dentro de la canalización, lo que hace que la canalización sea flexible para su reutilización. | List | No |
| simultaneidad | Número máximo de ejecuciones simultáneas que puede tener la canalización. De forma predeterminada, no hay ningún máximo. Si se alcanza el límite de simultaneidad, las ejecuciones de canalización adicionales se ponen en cola hasta que se completan las anteriores. | Number | No |
| annotations | Lista de etiquetas asociadas a la canalización | Array | No |
Actividad de JSON
La sección activities puede contener una o más actividades definidas. Existen dos tipos principales de actividades: Actividades de ejecución y de control.
Actividades de ejecución
Las actividades de ejecución incluyen las actividades de movimiento de datos y de transformación de datos. Tienen la siguiente estructura de nivel superior:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
En la tabla siguiente se describen las propiedades en la definición JSON de la actividad:
| Etiqueta | Descripción | Obligatorio |
|---|---|---|
| name | Nombre de la actividad. Especifique un nombre que represente la acción que realizará la actividad.
|
Sí |
| description | Texto que describe para qué se usa la actividad. | Sí |
| type | Tipo de la actividad. Consulte las secciones Actividades de movimiento de datos, Actividades de transformación de datos y Actividades de control para ver los diferentes tipos de actividades. | Sí |
| linkedServiceName | Nombre del servicio vinculado utilizado por la actividad. Una actividad puede requerir que especifique el servicio vinculado que enlaza con el entorno de procesos necesario. |
Sí para la actividad de HDInsight, la actividad de puntuación por lotes de Estudio de ML (clásico) y la actividad de procedimiento almacenado. No para todos los demás |
| typeProperties | Las propiedades en la sección typeProperties dependen de cada tipo de actividad. Para ver las propiedades de tipo de una actividad, haga clic en vínculos a la actividad de la sección anterior. | No |
| policy | Directivas que afectan al comportamiento en tiempo de ejecución de la actividad. Esta propiedad incluye un comportamiento de tiempo de espera y reintento. Si no se especifica, se usan los valores predeterminados. Para obtener más información, consulte la sección Directiva de actividades. | No |
| dependsOn | Esta propiedad se utiliza para definir las dependencias de actividad, y cómo las actividades siguientes dependen de actividades anteriores. Para obtener más información, consulte Dependencia de actividades. | No |
Directiva de actividades
Las directivas afectan al comportamiento en tiempo de ejecución de una actividad, lo que proporciona las opciones de configuración. Las directivas de actividades solo están disponibles para las actividades de ejecución.
Definición de directiva de actividades de JSON
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Nombre JSON | Descripción | Valores permitidos | Obligatorio |
|---|---|---|---|
| timeout | Especifica el tiempo de espera para que se ejecute la actividad. | TimeSpan | No. El tiempo de espera predeterminado es de 12 horas, como mínimo 10 minutos. |
| retry | Número máximo de reintentos | Entero | No. El valor predeterminado es 0. |
| retryIntervalInSeconds | El retraso entre reintentos, en segundos. | Entero | No. El valor predeterminado es 30 segundos. |
| secureOutput | Cuando se establece en true, la salida de la actividad se considera segura y no se registra para la supervisión. | Boolean | No. El valor predeterminado es False. |
Actividad de control
Las actividades de control tienen la siguiente estructura de nivel superior:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Etiqueta | Descripción | Obligatorio |
|---|---|---|
| name | Nombre de la actividad. Especifique un nombre que represente la acción que realizará la actividad.
|
Sí |
| description | Texto que describe para qué se usa la actividad. | Sí |
| type | Tipo de la actividad. Consulte las secciones Actividades de movimiento de datos, Actividades de transformación de datos y Actividades de control para ver los diferentes tipos de actividades. | Sí |
| typeProperties | Las propiedades en la sección typeProperties dependen de cada tipo de actividad. Para ver las propiedades de tipo de una actividad, haga clic en vínculos a la actividad de la sección anterior. | No |
| dependsOn | Esta propiedad se utiliza para definir las dependencias de actividad, y cómo las actividades siguientes dependen de actividades anteriores. Para obtener más información, consulte Dependencia de actividades. | No |
Dependencia de actividades
La dependencia de actividades define cómo las actividades siguientes dependen de las actividades anteriores, lo que determina la condición de si se debe continuar ejecutando la tarea siguiente. Una actividad puede depender de una o varias actividades anteriores con distintas condiciones de dependencia.
Las distintas condiciones de dependencia son: Correcto, Error, Omitido, Completado.
Por ejemplo, si una canalización tiene la actividad A -> actividad B, los distintos escenarios que pueden ocurrir son:
- La actividad B tiene una condición de dependencia en la actividad A con correcto: la actividad B solo se ejecuta si la actividad A tiene un estado final correcto.
- La actividad B tiene una condición de dependencia en la actividad A con error: la actividad B solo se ejecuta si la actividad A tiene un estado final de error.
- La actividad B tiene una condición de dependencia en la actividad A con completado: la actividad B se ejecuta si la actividad A tiene un estado final correcto o de error.
- La actividad B tiene una condición de dependencia de la actividad A con omitido: la actividad B se ejecuta si la actividad A tiene un estado final de omitido. La omisión se produce en el escenario de la actividad X -> actividad Y -> actividad Z, donde cada actividad se ejecuta solo si la actividad anterior se realiza correctamente. Si se produce un error en la actividad X, la actividad Y tiene un estado de "Omitido" porque nunca se ejecuta. De forma similar, la actividad Z también tiene un estado de "Omitido".
Ejemplo: La actividad 2 depende de que la actividad 1 se realice correctamente
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Canalización de copia de ejemplo
En la canalización de ejemplo siguiente, hay una actividad del tipo Copy in the actividades . En este ejemplo, la actividad de copia copia datos de Azure Blob Storage a una base de datos de Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Tenga en cuenta los siguientes puntos:
- En la sección de actividades, solo hay una actividad con type establecido en Copy.
- La entrada de la actividad está establecida en InputDataset, mientras que la salida está establecida en OutputDataset. Vea el artículo Conjuntos de datos para definir conjuntos de datos en JSON.
- En la sección typeProperties, BlobSource se especifica como el tipo de origen y SqlSink como el tipo de receptor. En la sección Actividades de movimiento de datos, haga clic en el almacén de datos que quiere usar como origen o receptor para obtener más información sobre cómo mover datos con ese almacén de datos como origen o destino.
Para obtener un tutorial completo de creación de esta canalización, consulte Inicio rápido: Creación de una instancia de Azure Data Factory con PowerShell.
Canalización de transformación de ejemplo
En la canalización de ejemplo siguiente, hay una actividad del tipo HDInsightHive in the actividades . En este ejemplo, el actividad de HDInsight Hive transforma los datos de Azure Blob Storage mediante la ejecución de un archivo de script de Hive en un clúster de Azure HDInsight Hadoop.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Tenga en cuenta los siguientes puntos:
- En la sección de actividades, solo hay una actividad con type establecido en HDInsightHive.
- El archivo de script de Hive, partitionweblogs.hql, se almacena en la cuenta de Azure Storage (especificada por la propiedad scriptLinkedService, llamada AzureStorageLinkedService) y en una carpeta de script en el contenedor
adfgetstarted. - La sección
definesse usa para especificar la configuración de runtime n que se pasa al script de Hive como valores de configuración de Hive (por ejemplo, ${hiveconf:inputtable},${hiveconf:partitionedtable}).
La sección typeProperties es diferente para cada actividad de transformación. Para obtener información sobre las propiedades de tipo compatibles con una actividad de transformación, haga clic en la actividad de transformación en Actividades de transformación de datos.
Para obtener un tutorial completo de creación de esta canalización, consulte Tutorial: transform data using Spark (Transformación de datos con Spark).
Varias actividades en una canalización
Las dos canalizaciones de ejemplo anteriores solo tienen una actividad, pero se pueden tener más de una actividad en una canalización. Si tiene varias actividades en una canalización y las actividades siguientes no son dependientes de actividades anteriores, las actividades se pueden ejecutar en paralelo.
Puede encadenar dos actividades con la dependencia de actividades, que define cómo las actividades siguientes dependen de las actividades anteriores, lo que determina la condición de si se debe continuar ejecutando la tarea siguiente. Una actividad puede depender de una o más actividades anteriores con distintas condiciones de dependencia.
Programación de canalizaciones
Las canalizaciones se programan mediante desencadenadores. Hay diferentes tipos de desencadenadores (desencadenador Scheduler, que permite que las canalizaciones se desencadenen según una programación de reloj, así como el desencadenador manual, que desencadena canalizaciones a petición). Para obtener más información sobre los desencadenadores, consulte el artículo Ejecución y desencadenadores de canalización.
Para hacer que el desencadenador dé inicio a una ejecución de canalización, debe incluir una referencia de canalización de la canalización en particular en la definición del desencadenador. Las canalizaciones y los desencadenadores tienen una relación "de n a m". Varios desencadenadores pueden dar comienzo a una única canalización y el mismo desencadenador puede iniciar varias canalizaciones. Una vez definido el desencadenador, debe iniciar el desencadenador para que comience a desencadenar la canalización. Para obtener más información sobre los desencadenadores, consulte el artículo Ejecución y desencadenadores de canalización.
Por ejemplo, digamos que tiene un desencadenador programado denominado "Trigger A", y que quiere iniciar la canalización, "MyCopyPipeline". Defina el desencadenador, tal como se muestra en el ejemplo siguiente:
Definición de TriggerA
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}