Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Azure Synapse Link for Dataverse mahdollistaa Microsoft Dataverse -tietojen viennin Delta Lake -muodossa. Delta Lake on alkuperäinen Microsoft Fabric -muoto, jota käytetään myös monissa muissa työkaluissa, kuten Azure Databricksissa. Koska tiedot viedään Delta Lake -muodossa suoraan Dataversesta, erillistä Delta Lake -muuntoprosessia ei tarvita, mikä nopeuttaa merkityksellisten tietojen saantia. Tässä artikkelissa on tietoja tästä ominaisuudesta ja kerrotaan, miten voit suorittaa seuraavat tehtävät:
- Selittää Delta Laken ja Parquetin ja miksi tiedot on vietävä tässä muodossa.
- Vie Dataverse-tiedot Azure Synapse Analytics -työtilaan Delta Lake -muodossa Azure Synapse Linkin avulla.
- Seuraa Azure Synapse Linkiä ja tietojen muuntamista.
- Tarkastele tietoja lähteestä Azure Data Lake Storage Gen2.
- Tarkastele tietoja lähteestä Synapse Workspace.
- Tietojen tarkasteleminen Microsoft Fabricissa.
Mikä on Delta Lake?
Delta Lake on avoimen lähdekoodin projekti, jonka avulla voi rakentaa lakehouse-arkkitehtuuria data lake -teknologian päälle. Delta Lake tarjoaa ACID (yksittäisyys, johdonmukaisuus, eristys ja kestävyys) -tapahtumia ja skaalattavan metatietojen käsittelyn sekä yhdistää suoratoiston ja erätietojen käsittelyn olemassa oleviin data lake -toimintoihin. Azure Synapse Analytics on yhteensopiva Linux Foundation Delta Laken kanssa. Delta Laken nykyinen versio, joka sisältyy Azure Synapseen, sisältää kielituet seuraaville: Scala, PySpark, and .NET. Lisätietoja: Mikä on Delta Lake? Voit oppia myös Johdanto Delta-taulukoihin -videosta.
Apache Parquet on Delta Laken perusmuoto ja mahdollistaa tehokkaiden pakkaus- ja koodaustoimintojen hyödyntämisen, jotka ovat muodolle alkuperäisiä. Parquet-tiedostomuoto käyttää sarakesuuntaista pakkausta. Se on tehokas ja säästää tallennustilaa. Kyselyjen, jotka hakevat tiettyjä sarakearvoja, ei tarvitse lukea koko rivitietoja, mikä parantaa suorituskykyä. Siksi palvelinton SQL-klusteri tarvitsee vähemmän aikaa ja vähemmän tallennustilapyyntöjä tietojen lukemista varten.
Miksi käyttää Delta Lakea?
- Skaalautuvuus: Delta Lake on rakennettu avoimen lähdekoodin Apache-käyttöoikeuksien päälle, jotka on suunniteltu täyttämään toimialan standardit suuren mittakaavan tietojenkäsittelyn kuormille.
- Luotettavuus: Delta Lake tarjoaa ACID-tapahtumat varmistaen tietojen yhdenmukaisuuden ja luotettavuuden jopa silloin, kun tapahtuu virheitä tai yhtäaikaista käyttöä.
- Suorituskyky: Delta Lake hyödyntää Parquetin saraketallennusmuotoa tarjoten parempia pakkaus- ja koodaustekniikoita, jotka voivat johtaa parantuneeseen kyselyjen suorituskykyyn CSV-kyselytiedostoihin verrattuna.
- Kustannustehokas: Delta Lake -tiedostomuoto on korkeasti pakattu tietovarastointiteknologia, joka tarjoaa merkittäviä mahdollisuuksia tallennustilan säästämiseen yrityksille. Tämä muoto on suunniteltu optimoimaan tietojen käsittelyn ja mahdollisesti vähentämään käsiteltyjen tietojen kokonaismäärää tai tarvittavaa suoritusaikaa vaadittaessa tapahtuvalle laskennalle.
- Tietosuojan noudattaminen: Delta Lake yhdessä Azure Synapse Linkin kanssa tarjoaa työkaluja ja ominaisuuksia, kuten poistettavaksi merkitsemisen ja pysyvän poistamisen, noudattaakseen erilaisia tietosuojasäädöksiä, mukaan lukien yleinen tietosuoja-asetus (GDPR).
Miten Delta Lake toimii Azure Synapse Lin for Dataversen kanssa?
Kun määrität Azure Synapse Link for Dataversen, voit ottaa käyttöön vie Delta Lakeen -ominaisuuden ja muodostaa yhteyden Synapse-työtilaan ja Spark-varantoon. Azure Synapse Link vie valitut Dataverse-taulukot CSV-muodossa määritetyin aikavälein ja käsittelee ne Delta Lake -muunnoksen Spark-työn kautta. Kun muuntoprosessi on valmis, CSV-tiedot poistetaan tallennustilan säästämiseksi. Lisäksi sarja ylläpitotöitä aikataulutetaan suoritettaviksi päivittäin. Lisäksi järjestelmä suorittaa automaattisesti tiivistys- ja alityöprosesseja datatiedostojen yhdistämiseksi ja puhdistamiseksi tallennustilan optimoimiseksi ja kyselyn suorituskyvyn parantamiseksi.
Tärkeää
- Jos olet päivittämässä CSV:stä Delta Lakeen aiemmin luotujen mukautettujen näkymien kanssa, on suositeltavaa päivittää komentosarja korvaamaan kaikki osioidut taulukot non_partitioned-taulukoilla. Voit tehdä tämän etsimällä
_partitioned-esiintymät ja korvaamalla ne tyhjällä merkkijonolla. - Dataverse-määritystä varten vain liittäminen on oletusarvoisesti käytössä, jotta CSV-tiedot voidaan viedä
appendonly-tilassa. Delta Lake -taulukossa on käytössä oleva päivitysrakenne, koska Delta Lake -muunnokseen liittyy säännöllinen yhdistämisprosessi. - Sinun on valmisteltava Spark-varanto (laskentaresurssit) omassa Azure-tilauksessasi Delta-muunnosta varten. Tätä spark-poolia käytetään säännöllisten Delta-muunnosten suorittamiseen valitsemasi aikavälin perusteella.
- Spark-varantojen luomisesta ei aiheudu kustannuksia. Kustannuksia syntyy vasta, kun Spark-työ suoritetaan kohteena olevassa Spark-varannossa ja Spark-esiintymä luodaan tarvittaessa. Nämä kustannukset liittyvät Azure Synapse workspace Sparkiin ja ne laskutetaan kuukausittain. Spark-laskennan käyttökustannus määräytyy lähinnä lisäävän päivityksen aikavälin ja tietomäärien mukaan. Lisätietoja: Azure Synapse Analytics:n hinnoittelu
- Sinun on luotava Spark-allas, jonka versio on 3.4. Jos käytät jo tätä ominaisuutta Spark-versiossa 3.3, sinun on päivitettävä nykyiset profiilisi paikan päällä. Lisätietoja: Paikallinen Apache Spark 3.4 ja Delta Lake 2.4
Huomautus
Azure Synapse Linkin tila Power Appsissa (make.powerapps.com) vastaa Delta Lake -muunnoksen tilaa:
-
Countnäyttää Delta Lake -taulukossa olevien tietueiden määrän. -
Last synchronized on-päivämäärä/aika vastaa viimeisimmän onnistuneen muunnoksen aikaleimaa. -
Sync statuson aktiivinen, kun tietojen synkronointi ja Delta Lake -muunto valmistuu; se myös ilmaisee, että tiedot ovat valmiita käytettäviksi.
edellytykset
- Dataverse: Sinulla on oltava Dataverse järjestelmänvalvojan käyttöoikeusrooli. Lisäksi taulukoissa, jotka haluat viedä Azure Synapse Linkin kautta, on oltava Muutosten seuranta -ominaisuus käytössä. Lisätietoja: Lisäasetukset
- Azure Data Lake Storage Gen2: Tarvitaan Azure Data Lake Storage Gen2 -tili sekä Omistaja- ja Säilön BLOB-tietojen osallistuja -roolit. Tallennustilin on otettava käyttöön hierarkkinen nimitila ja julkinen verkkoyhteys sekä alkuasennuksessa että muutossynkronoinnissa. Salli tallennustilin avaimeen pääsy on pakollinen vain alkuasennuksen yhteydessä.
- Synapse-työtila: Sinulla on oltava Synapse-työtila, Omistaja-rooli käyttöoikeuksien hallinnassa (IAM) ja Synapse-järjestelmänvalvojan käyttöoikeusrooli Synapse Studiossa. Synapse-työtilan on oltava samalla alueella kuin Azure Data Lake Storage Gen2 -tilisi. Tallennustili on lisättävä linkitettynä palveluna Synapse Studioon. Jos haluat luoda Synapse-työtilan, siirry kohtaan Synapse-työtilan luominen.
- Apache Spark -varanto yhdistetyssä Azure Synapse workspacessa Apache Spark -versiolla 3.4 käyttää tätä suositeltua Spark-varantokokoonpanoa. Lisätietoja Spark-varannon luomisesta on kohdassa Uuden Apache Spark -varannon luominen.
- Microsoft Dynamics 365:n minimiversiovaatimus tämän toiminnon käyttöä varten on 9.2.22082. Lisätietoja: Ennakkojulkaisujen tilaaminen
Suositeltu Spark-varannon määritys
Tätä määritystä voidaan pitää käynnistysvaiheena keskimääräistä käyttöä varten.
- Solmun koko: pieni (4 vCorea / 32 Gt)
- Automaattinen skaalaus: Käytössä
- Solmujen määrä: 3–10 (tai tarvittaessa 20. 1Lisätietoja on jäljempänä.)
- Automaattinen pysäyttäminen: Käytössä
- Käyttämättömien minuuttien määrä: 5
- Apache Spark: 3.4
- Suorittajien dynaaminen määrittäminen: Käytössä
- Suorittajien oletusmäärä: 1–9
Tärkeää
- Käytä Spark-varantoa yksinomaan Delta Lake -keskustelutoiminnossa Dataversen Synapse Linkin kanssa. Jotta luotettavuus ja suorituskyky olisi mahdollisimman hyvä, vältä muiden Spark-tehtävien suorittamista samalla Spark-varannolla.
- Sinun on ehkä lisättävä Spark-poolin solmujen määrää, jos odotat, että käsiteltäviä rivejä on paljon. Jos Spark-poolin koko ei riitä, Delta-muunnostyöt saattavat epäonnistua
- Järjestelmä käyttää samaa Spark-poolia yötyön suorittamiseen, joka tiivistää Delta-tiedostoja järvessä klo 23–6 paikallista aikaa. Järjestelmä määrittää Dataverse-ympäristön sijainnin perusteella työ suorittamisen yöllä. Et voi määrittää tiettyä aikaikkunaa. Tämä vaihtoehto pienentää Delta-tiedostojen kokoa yhdistämällä tiedostoja, joita kutsutaan tiivistykseksi. Harvoissa tapauksissa tämä työ saattaa häiritä lisäävää konversiotyötä. Solmujen määräksi voidaan määrittää 20, jos näitä virheitä esiintyy.
- Sinua veloitetaan vain tosiasiallisesti käytetyistä Spark-varantosolmuista. Solmujen määrän lisääminen ei välttämättä johda suurempiin maksuihin.
Yhdistä Dataverse Synapse workspaceen ja vie tiedot Delta Lake -muodossa
Kirjaudu Power Appsiin ja valitse haluamasi ympäristö.
Valitse vasemmassa siirtymisruudussa Azure Synapse Link. Jos nimikettä ei ole sivupaneelissa, valitse ... Lisää ja valitse sitten haluamasi nimike.
Valitse komentopalkissa +Uusi linkki
Valitse Muodosta yhteys Azure Synapse Analytics workspaceen ja valitse sitten Tilaus, Resurssiryhmä ja Työtilan nimi.
Valitse Käytä Spark-varantoa käsittelyyn ja valitse sitten esiluodut Spark-varanto ja Tallennustilatili.
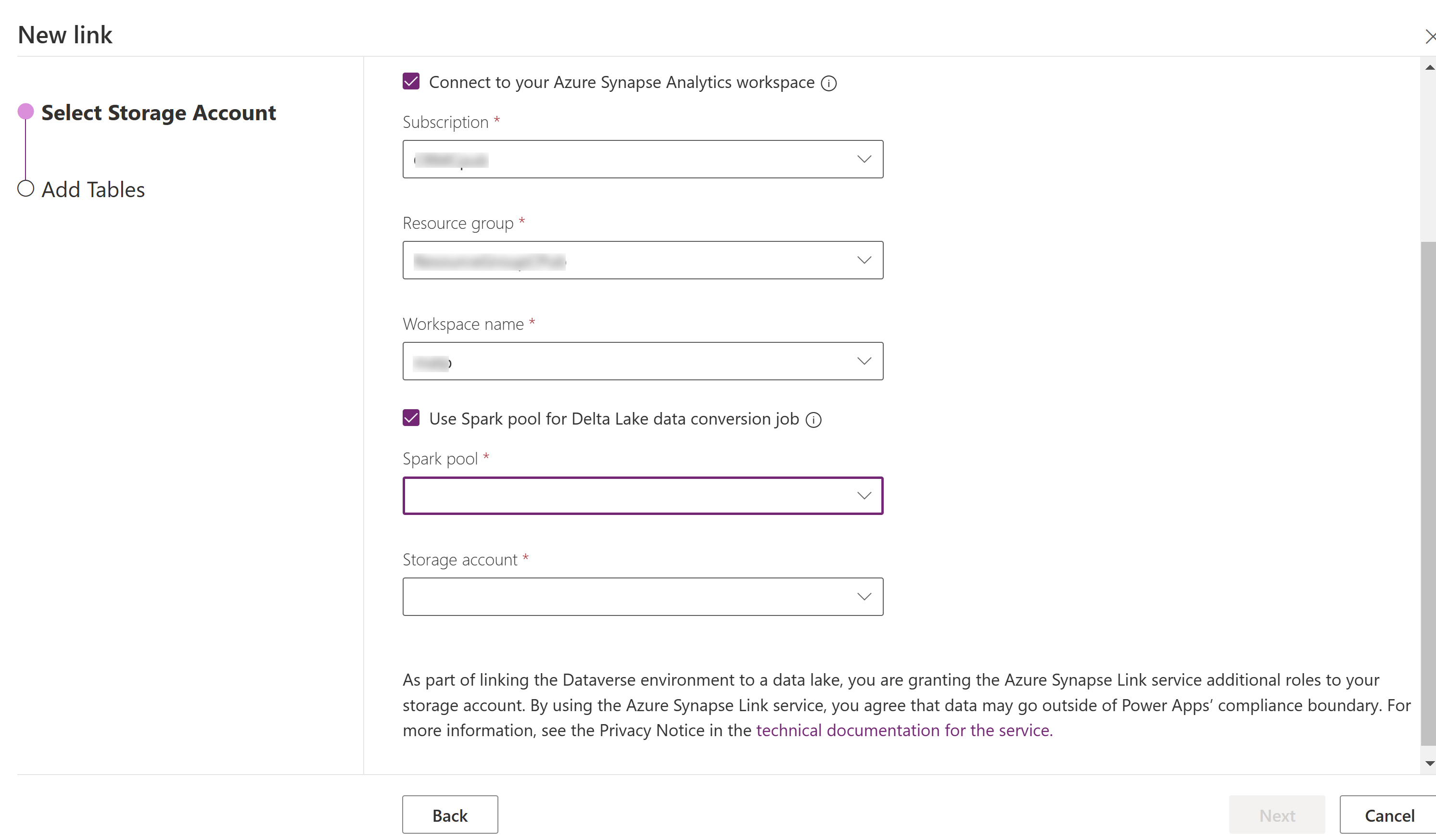
Valitse Seuraava.
Lisää vietävät taulukot ja valitse sitten Lisäasetukset.
Valitse halutessasi Näytä määritysten lisäasetukset ja syötä minuutteina aikaväli sille, kuinka usein inkrementaaliset päivitykset suoritetaan.
Valitse Tallenna.
Seuraa Azure Synapse Linkiä ja tietojen muuntamista
- Valitse haluamasi Azure Synapse Link ja valitse sitten Siirry Azure Synapse Analytics -työtilaan komentopalkista.
- Valitse Valvonta>Apache Spark -sovellukset. Lisätietoja: Synapse Studion käyttäminen Apache Spark -sovellusten valvomista varten
Tarkastele tietoja Synapse workspacesta
- Valitse haluamasi Azure Synapse Link ja valitse sitten Siirry Azure Synapse Analytics -työtilaan komentopalkista.
- Laajenna Lake Databases vasemmassa ruudussa, valitse dataverse-environmentNameorganizationUniqueName ja laajenna sitten Taulukot. Kaikki Parquet-taulukot on lueteltu, ja ne ovat käytettävissä analyysissä, jossa on nimeämiskäytäntö DataverseTableName.(Non_partitioned Table).
Huomautus
Taulukkoja, joiden nimeämiskäytäntö on _partitioned, ei saa käyttää. Kun muodoksi valitaan Delta parquet, taulukkoja, joiden nimeämiskäytäntö on _partition, käytetään valmistelutaulukoina ja poistetaan, kun järjestelmä on käyttänyt ne.
Tarkastele tietoja lähteestä Azure Data Lake Storage Gen2
- Valitse haluamasi Azure Synapse Link ja valitse sitten komentoriviltä Siirry Azure Data Lakeen.
- Valitse Säilöt kohteen Tietovarasto alta.
- Valitse *dataverse- *environmentName-organizationUniqueName. Kaikki Parquet-tiedostot on tallennettu deltalake-kansioon.
Paikallinen Apache Spark 3.4 ja Delta Lake 2.4 -päivitys
Apache Sparkin Synapse-suorituspalvelun elinkaarikäytännön mukaisesti Apache Spark 3.3:n Azure Synapse -suorituspalvelu poistetaan käytöstä 31. maaliskuuta 2025 alkaen. Tuen päättymispäivän jälkeen käytöstä poistetut suoritusajat eivät ole käytettävissä uusissa Spark-pooleissa ja Spark 3.3 -poolien olemassa olevia työnkulkuja ei suoriteta, kun metatiedot jäävät tilapäisesti Synapse-työtilaan. Lisätietoja: Apache Spark 3.3:n Azure Synapse -suorituspalvelu (EOSA).
Tietojen suorittamisen jatkaminen aiemmin luoduilla Synapse Link -profiileilla edellyttää, että Synapse Link -profiilit päivitetään käyttämään Spark 3.4 -varantoja. Tämä tehdään paikallisella päivitysprosessilla.
Suoran päivityksen edellytykset
- Aiemmin luotu Azure Synapse Link for Dataverse Delta Lake -profiili, joka toimii Synapse Spark -versiossa 3.3.
- Luo uusi Synapse Spark -pooli Sparkin version 3.4 avulla käyttämällä samaa tai korkeampaa solmujen laitteistomääritystä samassa Synapse-työtilassa. Lisätietoja Spark-varannon luomisesta on kohdassa Uuden Apache Spark -varannon luominen. Tämä Spark-varanto on luotava erillään nykyisestä 3.3-varannosta – Spark 3.3 -varantoa ei siis poisteta eikä samannimistä Spark 34 -varantoa luoda
Paikallinen päivitys Spark 3.4 -versioon
- Kirjaudu sisään Power Appsiin ja valitse haluamasi ympäristö.
- Valitse vasemmassa siirtymisruudussa Azure Synapse Link. Jos nimikettä ei ole vasemmassa siirtymisruudussa, valitse ... Lisää ja valitse sitten haluamasi nimike.
- Avaa Azure Synapse Link -profiili ja valitse sitten Päivitä Apache Spark -versioon 3.4 Delta Lake -versiolla 2.4.
- Valitse luettelosta käytettävissä oleva Spark-pooli ja valitse sitten Päivitä.
Huomautus
- Spark-poolin päivitys tapahtuu vain, kun uusi Delta Lake -tallennustilan muunnos Spark-työ käynnistetään. Varmista, että sinulla on vähintään yksi tietomuutos Päivitä-kohdan valinnan jälkeen.
- Voit poistaa vanhemman Spark 3.3 -poolin varmistettuasi, että Delta-muunnostyöt käyttävät uutta poolia.