Sauvegardes automatisées pour bases de données Hyperscale
S’applique à :![]() Azure SQL Database
Azure SQL Database
Cet article explique la fonctionnalité de sauvegarde automatisée avec des bases de données Hyperscale dans Azure SQL Database.
Les bases de données Hyperscale dans utilisent une architecture unique avec des niveaux stockage et de calcul hautement évolutifs. Les sauvegardes Hyperscale sont basées sur des instantanés et sont presque instantanées. Les sauvegardes de fichier journal sont stockées à long terme dans un stockage Azure pendant la période de rétention des sauvegardes.
Une architecture Hyperscale ne nécessite pas la même chaîne de sauvegarde que les sauvegardes basées sur des fichiers utilisées dans SQL Server et d’autres niveaux SQL Database, mais répond toujours aux mêmes exigences en matière de RTO et de RPO. Le journal des transactions se comporte de la même façon et permet la même fonctionnalité de restauration à un point dans le temps. Dans Hyperscale, la fréquence de sauvegarde, les coûts de stockage, la planification, la redondance du stockage et les fonctionnalités de restauration diffèrent des autres bases de données dans Azure SQL Database.
Performances de sauvegarde et de restauration
La séparation du stockage et du calcul permet à Hyperscale de pousser les opérations de sauvegarde et restauration vers la couche de stockage afin d’éliminer la consommation de ressource sur des réplicas de calcul. Les sauvegardes de base de données n’affectent pas les performances des réplicas de calcul principal ou secondaire.
Les opérations de sauvegarde et de restauration pour les bases de données Hyperscale sont rapides, quelle que soit la taille des données, car elles utilisent des instantanés de stockage. La sauvegarde est pratiquement instantanée.
Vous pouvez restaurer une base de données à n’importe quel instant dans le passé s’inscrivant dans la période de rétention des sauvegardes :
- Restauration d’instantanés de fichiers applicables.
- Application de journaux des transactions pour rendre la base de données restaurée cohérente d’un point de vue transactionnel.
En tant que telle, la restauration n’est pas une opération tributaire de la taille des données qui reste identique. La restauration d’une base de données Hyperscale dans la même région Azure s’accomplit en quelques minutes au lieu de plusieurs heures ou jours, même pour des bases de données de plusieurs téraoctets.
La modification de la redondance du stockage lors d’une restauration peut entraîner des temps de restauration plus longs, car la restauration porte sur le dimensionnement des données et le temps sera donc proportionnel à la taille de la base de données.
La création d’une nouvelle base de données en restaurant une sauvegarde existante ou en copiant une base de données tire également parti de la séparation du calcul et du stockage dans Hyperscale. La création de copies à des fins de développement ou de test, même de bases de données de plusieurs téraoctets, est réalisable en quelques minutes dans la même région quand le même type de stockage est utilisé.
Rétention des sauvegardes
La durée de conservation par défaut des sauvegardes pour les bases de données Hyperscale est de 7 jours.
La rétention à court terme des sauvegardes comprises entre 1 et 35 jours et la fonctionnalité de rétention de sauvegarde à long terme (LTR) pour les bases de données Hyperscale est généralement disponible, à compter de septembre 2023. Pour plus d’informations, consultez Conservation à long terme - Azure SQL Database et Azure SQL Managed Instance.
Planification de la sauvegarde
Il n’existe pas de sauvegardes complètes, différentielles et de fichier journal traditionnelles pour les bases de données Hyperscale. Au lieu de cela, des captures instantanées de stockage de fichiers de données sont effectuées.
Les journaux des transactions générés sont conservés en l’état pendant la période de rétention configurée. Au moment de la restauration, les enregistrements de journal des transactions appropriés sont appliqués aux instantanés de stockage restaurés. Il en résulte une base de données cohérente d’un point de vue transactionnel, sans perte de données, à compter de l’instant dans le passé spécifié s’inscrivant dans la période de conservation.
Surveiller la consommation de stockage de sauvegarde
Dans Hyperscale, les métriques Azure Monitor rendent compte des informations de consommation suivantes :
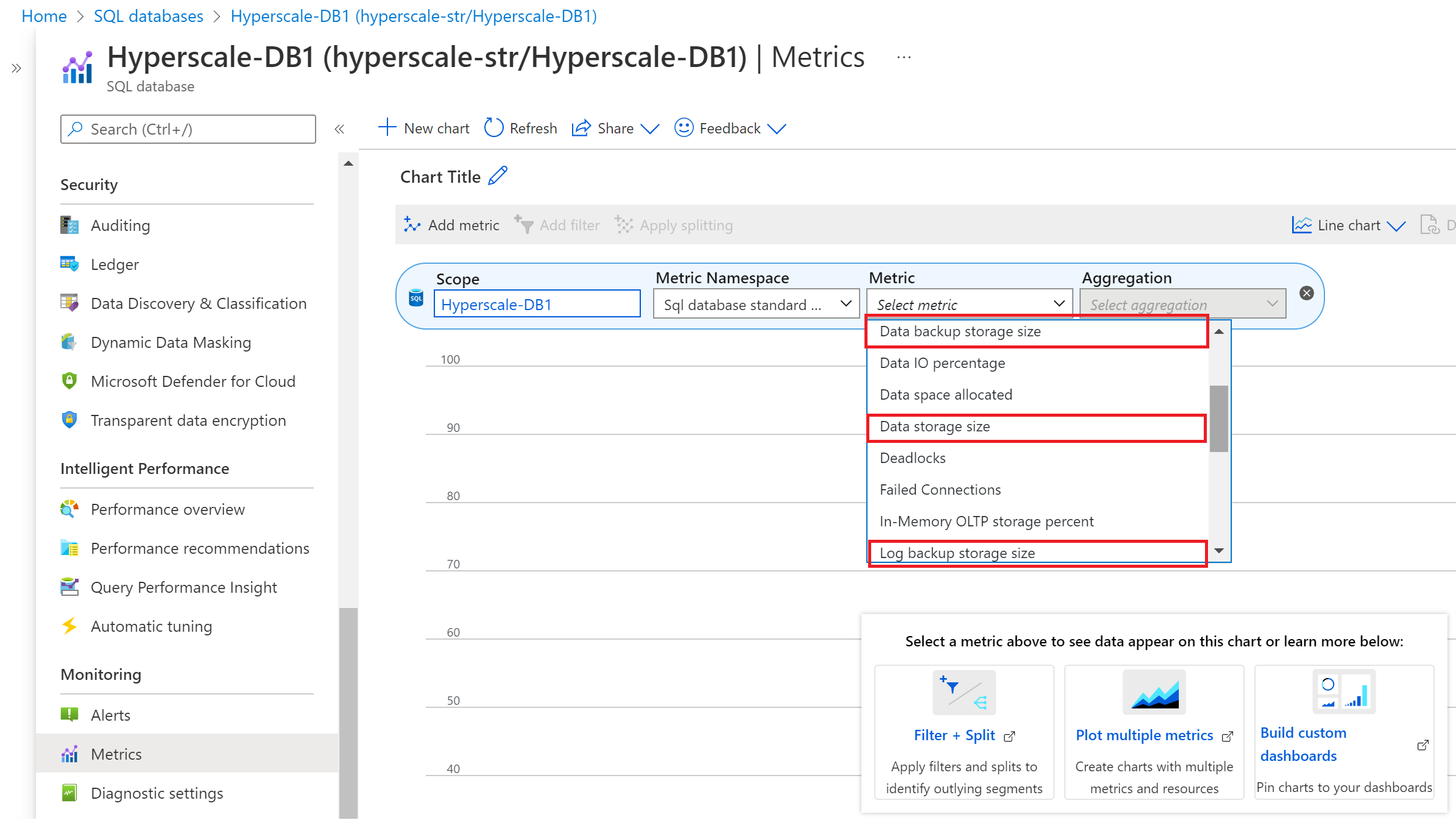
- Taille de stockage de sauvegarde de données (taille de sauvegarde d’instantané)
- Taille de stockage de données (taille de base de données allouée)
- Taille de stockage de sauvegarde de fichier journal (taille de sauvegarde de fichier journal des transactions)
Pour afficher les métriques de sauvegarde et de stockage des données dans le portail Azure, procédez comme suit :
- Accédez à la base de données Hyperscale pour laquelle vous souhaitez surveiller les métriques de sauvegarde et de stockage des données.
- Dans la section Surveillance, sélectionnez la page Métriques.
- Dans la liste déroulante Métrique, sélectionnez les métriques Stockage des sauvegardes de données, Taille de stockage des données et Stockage des sauvegardes de fichiers journaux avec une règle d’agrégation appropriée.
Réduire la consommation du stockage de sauvegarde
Pour une base de données Hyperscale, la consommation du stockage de sauvegarde dépend de la période de conservation, du choix de la région, de la redondance du stockage de sauvegarde et du type de la charge de travail. Envisagez les diverses techniques d’ajustement suivantes pour réduire votre consommation de stockage de sauvegarde pour une base de données Hyperscale :
- Réduisez la période de rétention des sauvegardes au minimum compte tenu de vos besoins.
- N’effectuez pas d’opérations d’écriture volumineuses (comme la maintenance d’index) plus fréquemment que nécessaire. Pour connaître les recommandations relatives à la maintenance des index, consultez Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources.
- Pour les opérations de chargement de données volumineuses, nous vous conseillons d’utiliser la compression des données.
- Utilisez la base de données
tempdbau lieu de tables permanentes dans votre logique d’application pour stocker les résultats et/ou les données temporaires. - Utilisez le stockage de sauvegarde localement redondant ou redondant interzone lorsque la fonctionnalité de géorestauration est inutile (par exemple, les environnements de développement/test).
Coûts du stockage de sauvegarde
Le coût de stockage de sauvegarde Hyperscale dépend de la région et de la redondance du stockage de sauvegarde choisies. Cela dépend également du type de charge de travail.
Les charges de travail intenses en écriture sont davantage susceptibles de modifier fréquemment les pages de données, ce qui entraîne des captures instantanées de stockage plus volumineuses. Ces charges de travail génèrent également des journaux des transactions plus volumineux, contribuant aux coûts de sauvegarde globaux. Le stockage de sauvegarde est facturé sur la base des gigaoctets consommés par mois. La quantité de stockage de sauvegarde égale à la taille de la base de données est fournie sans frais supplémentaires. Pour plus d’informations sur les tarifs, consultez la page Tarification d’Azure SQL Database.
Pour Hyperscale, le stockage de sauvegarde facturable est calculé de la façon suivante :
Total billable backup storage size = (data backup storage size + log backup storage size)
La taille du stockage de données n’est pas incluse dans la sauvegarde facturable car elle est déjà facturée en tant que stockage de base de données alloué.
Les bases de données Hyperscale supprimées entraînent des coûts de sauvegarde liés à la capacité d’effectuer une récupération à un point dans le temps avant la suppression. Pour une base de données Hyperscale supprimée, le stockage de sauvegarde facturable est calculé de la façon suivante :
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
La taille du stockage de données est incluse dans la formule, car le stockage de base de données alloué n’est pas facturé séparément pour une base de données supprimée. Pour une base de données supprimée, les données sont stockées après suppression pour permettre leur récupération pendant la période de conservation de sauvegarde configurée.
Le stockage de sauvegarde facturable pour une base de données supprimée diminue progressivement au fil du temps après sa suppression. Il passe à zéro quand les sauvegardes ne sont plus conservées, et la récupération n’est plus possible. S’il s’agit d’une suppression définitive et que vous n’avez plus besoin de sauvegardes, vous pouvez optimiser les coûts en réduisant la rétention avant de supprimer la base de données.
Surveiller les coûts de sauvegarde
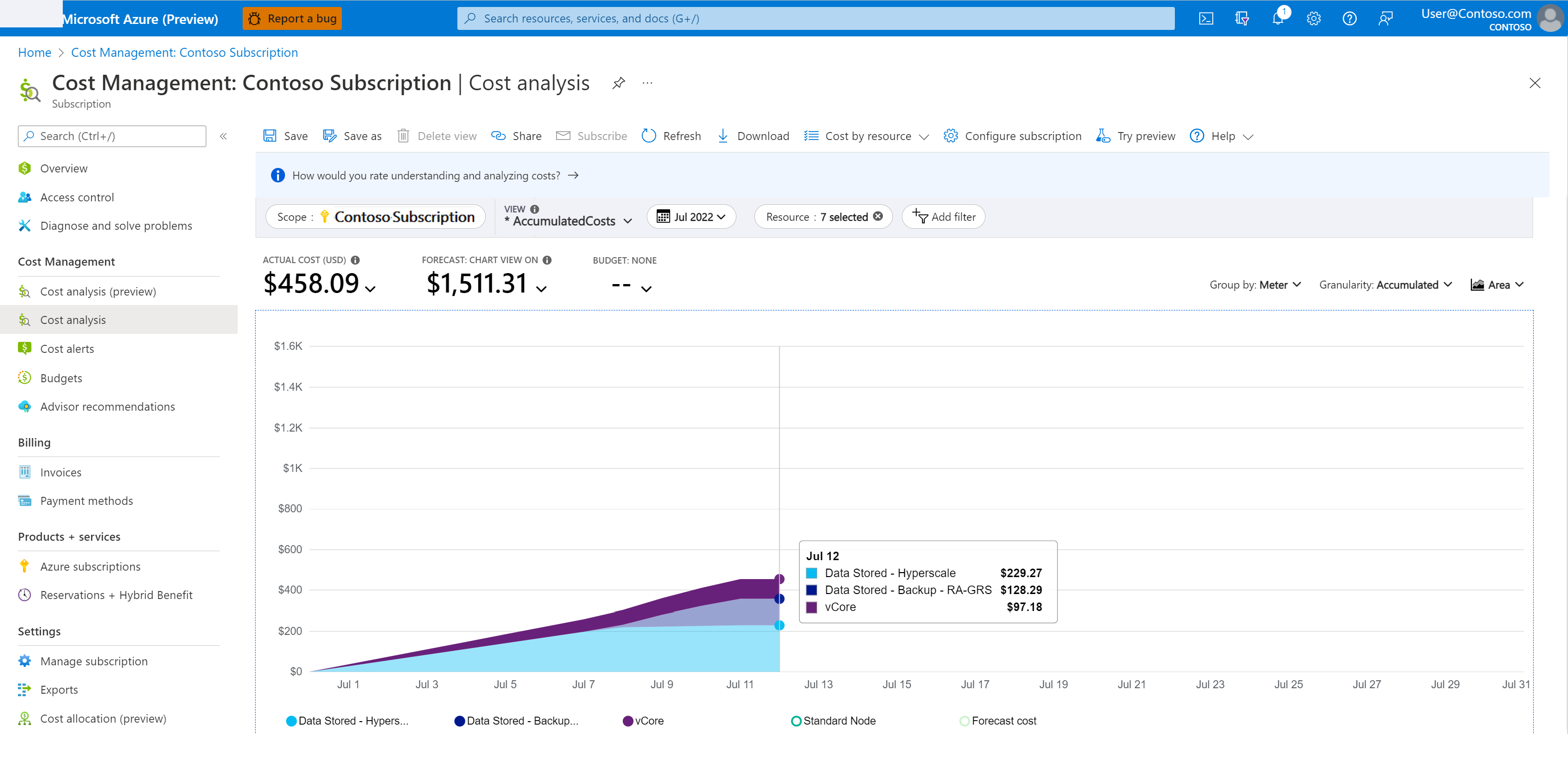
Pour comprendre les coûts de stockage de sauvegarde :
Dans le portail Azure, accédez à Cost Management + Billing.
Sélectionnez Gestion des coûts>Analyse des coûts.
Pour Portée, sélectionnez l’abonnement souhaité.
Filtrez la période et le service qui vous intéressent en procédant comme suit :
- Ajoutez un filtre pour Nom du service.
- Choisissez sql-database dans la liste déroulante.
- Ajoutez un autre filtre pour Compteur.
- Pour surveiller les coûts de sauvegarde en lien avec la restauration à un instant dans le passé, dans la liste déroulante, sélectionnez Données stockées - Sauvegarde - RA.
La capture d’écran suivante donne un exemple d’analyse des coûts.
Redondance du stockage de données et de sauvegarde
Hyperscale prend en charge la redondance de stockage configurable. Lors de la création d’une base de données Hyperscale, vous pouvez choisir votre type de stockage préféré : RA-GZRS (stockage géo-redondant interzone avec accès en lecture), RA-GRS (stockage géo-redondant avec accès en lecture), ZRS (stockage redondant interzone) ou LRS (stockage localement redondant).
- Stockage redondant interzone : copie vos sauvegardes de façon synchrone dans trois zones de disponibilité Azure au sein de la région primaire. semblable au stockage redondant interzone (ZRS). Par ailleurs, il copie ensuite vos données de façon asynchrone vers un emplacement physique unique dans la région secondaire associée. Le ZRS n’est actuellement disponible que dans certaines régions.
Pour savoir comment les sauvegardes sont répliquées pour d’autres types de stockage, consultez Redondance du stockage de sauvegarde.
Étant donné que Hyperscale utilise des captures instantanées de stockage pour les sauvegardes, les données et les sauvegardes partagent le même compte de stockage. Par conséquent, la redondance du stockage de sauvegarde sélectionnée s’applique aux données et aux sauvegardes.
Remarque
Lorsque vous créez une base de données Hyperscale, considérez attentivement la redondance du stockage de sauvegarde, car vous ne pouvez la définir que lors de la création de la base de données. Vous ne pourrez plus modifier ce paramètre après l’approvisionnement de la ressource.
Utilisez une géoréplication active afin de mettre à jour les paramètres de redondance du stockage de sauvegarde pour une base de données Hyperscale existante, moyennant un minimum de temps d’arrêt. Vous pouvez également utiliser une copie de base de données.
Avertissement
- La géo-restauration est désactivée dès qu’une base de données est mise à jour pour utiliser un stockage localement redondant ou redondant interzone.
- Actuellement, le stockage redondant interzone n’est disponible que dans certaines régions.
- Actuellement, le stockage géo-redondant interzone n’est disponible que dans certaines régions.
Restaurer une base de données Hyperscale dans une autre région
Il se peut que vous deviez restaurer votre base de données Hyperscale dans une région différente de la région actuelle. Des raisons courantes sont une opération ou un exercice de récupération d’urgence, ou un déménagement. La première méthode consiste à effectuer une géo-restauration de la base de données. La procédure à suivre est la même que celle utilisée pour restaurer n’importe quelle base de données dans Azure SQL Database dans une région différente :
- Créez un serveur dans la région cible si vous n'y disposez pas encore d'un serveur approprié. Ce serveur doit appartenir au même abonnement que le serveur (source) d’origine.
- Suivez les instructions de la section géo-restauration sur la page consacrée à la restauration d’une base de données dans Azure SQL Database à partir de sauvegardes automatiques.
Remarque
Étant donné que la source et la cible se trouvent dans des régions distinctes, la base de données ne peut pas partager de stockage d’instantanés avec la base de données source comme c’est le cas dans le cadre de restaurations non géographiques. Les restaurations non géographiques se terminent rapidement, quelle que soit la taille de la base de données.
Dans le cas d’une géorestauration d’une base de données Hyperscale, il s’agit d’une opération tributaire de la taille des données, même si la cible se trouve dans la région jumelée du stockage géorépliqué. Par conséquent, une géo-restauration prend beaucoup plus de temps qu’une restauration à un instant dans le passé dans la même région.
Si la cible se trouve dans la région jumelée, le transfert de données se fera à l’intérieur d’une région. Ce transfert sera beaucoup plus rapide qu’un transfert de données inter-régions. Mais il s’agit toujours d’une opération tributaire de la taille de données.
Si vous préférez, vous pouvez copier la base de données dans une autre région. Utilisez cette méthode si la géo-restauration n’est pas disponible, car elle n’est pas prise en charge avec le type de redondance de stockage sélectionné. Pour plus d’informations, consultez Copie de base de données pour Hyperscale.
Contenu connexe
Les sauvegardes de base de données sont une partie essentielle de toute stratégie de continuité d’activité ou de récupération d’urgence, dans la mesure où elles protègent vos données des corruptions et des suppressions accidentelles.
- Vue d’ensemble de la continuité de l’activité avec la base de données Azure SQL
- Guide pratique pour gérer la conservation à long terme des sauvegardes Azure SQL Database
- Restaurer une base de données à partir d’une sauvegarde dans Azure SQL Database
- Utiliser PowerShell pour restaurer une base de données à un point antérieur dans le temps