Copier et transformer des données dans Azure Cosmos DB for NoSQL à l’aide d’Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article indique comment utiliser l’activité de copie dans Azure Data Factory pour copier des données depuis et vers Azure Cosmos DB for NoSQL, et utiliser Data Flow pour transformer les données dans Azure Cosmos DB for NoSQL. Pour en savoir plus, lisez les articles d’introduction d’Azure Data Factory et d’Azure Synapse Analytics.
Notes
Ce connecteur prend uniquement en charge Azure Cosmos DB for NoSQL. Pour Azure Cosmos DB for MongoDB, reportez-vous à connecteur pour Azure Cosmos DB pour MongoDB. Les autres types d’API ne sont pas pris en charge actuellement.
Fonctionnalités prises en charge
Ce connecteur Azure Cosmos DB for NoSQL est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR | Point de terminaison privé managé |
|---|---|---|
| Activité de copie (source/récepteur) | ① ② | ✓ |
| Mappage de flux de données (source/récepteur) | ① | ✓ |
| Activité de recherche | ① ② | ✓ |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour l'activité de copie, ce connecteur Azure Cosmos DB for NoSQL prend en charge :
- Copier des données depuis et vers l0'API SQL d’Azure Cosmos DB for NoSQL à l’aide de la clé, du principal du service ou des identités gérées pour les authentifications des ressources Azure.
- Écrire dans Azure Cosmos DB comme insert ou upsert.
- Importer et exporter des documents JSON en l’état, ou copier des données depuis ou vers un jeu de données tabulaire. Les exemples incluent une base de données SQL et un fichier CSV. Pour copier des documents en l'état vers ou depuis des fichiers JSON ou une autre collection Azure Cosmos DB, consultez Importer et exporter des documents JSON.
Les pipelines Data Factory et Synapse s’intègrent à la bibliothèque d’exécuteur en bloc Azure Cosmos DB pour offrir les meilleures performances quand vous écrivez dans Azure Cosmos DB.
Conseil
La vidéo de la migration des données vous guide tout au long des étapes de la copie des données depuis le stockage Blob Azure vers Azure Cosmos DB. La vidéo décrit également les considérations de réglage des performances pour l’ingestion des données dans Azure Cosmos DB en général.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Azure Cosmos DB en utilisant l'interface utilisateur.
Suivez les étapes suivantes pour créer un service lié à Azure Cosmos DB dans l'interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Azure Cosmos DB for NoSQL et sélectionnez le connecteur Azure Cosmos DB for NoSQL.
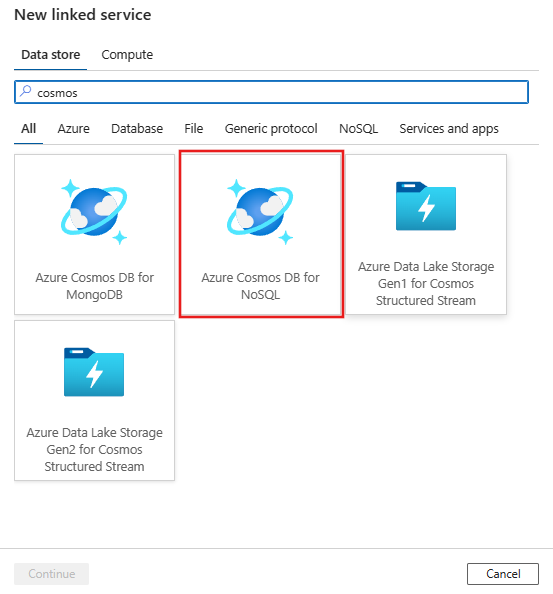
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
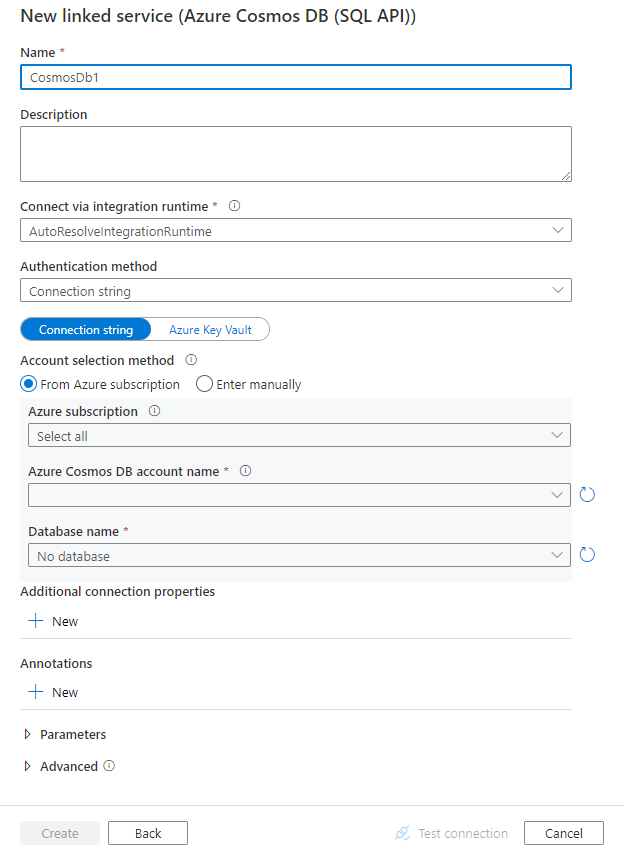
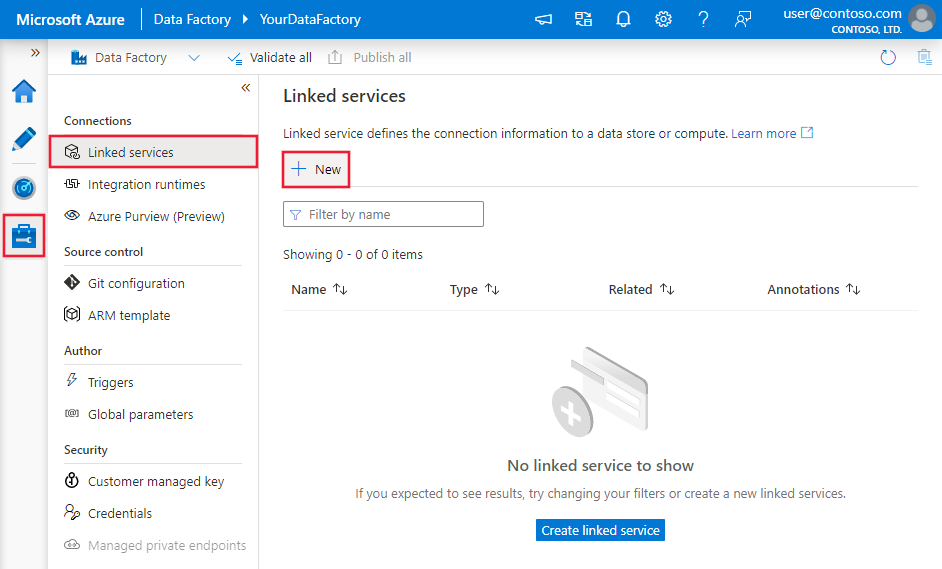
Informations de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisables pour définir les entités propres à Azure Cosmos DB for NoSQL.
Propriétés du service lié
Le connecteur Azure Cosmos DB for NoSQL prend en charge les types d’authentification suivants. Consultez les sections correspondantes pour plus d’informations :
- Authentification par clé
- Authentification d’un principal du service
- Authentification d’identité managée affectée par le système
- Authentification d’identité managée affectée par l’utilisateur
Authentification par clé
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur CosmosDb. | Oui |
| connectionString | Spécifiez les informations requises pour se connecter à la base de données Azure Cosmos DB. Remarque : Vous devez spécifier les informations de base de données dans la chaîne de connexion, comme indiqué dans les exemples ci-dessous. Vous pouvez également définir une clé de compte dans Azure Key Vault et extraire la configuration accountKey de la chaîne de connexion. Pour plus d’informations, reportez-vous aux exemples suivants et à l’article Stocker des informations d’identification dans Azure Key Vault. |
Oui |
| connectVia | Runtime d’intégration à utiliser pour la connexion au magasin de données. Vous pouvez utiliser Azure Integration Runtime ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. Si cette propriété n’est pas spécifiée, Azure Integration Runtime par défaut est utilisé. | Non |
Exemple
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : stockage de la clé de compte dans Azure Key Vault
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;Database=<Database>",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’un principal du service
Notes
Actuellement, l’authentification du principal du service n’est pas prise en charge dans le flux de données.
Pour l’authentification de principal de service, effectuez les étapes suivantes.
Inscrire une application à l’aide de la plateforme d’identités Microsoft. Pour savoir comment, regardez Démarrage rapide : Inscrire une application à l’aide de la plateforme d’identités Microsoft. Prenez note des valeurs suivantes qui vous permettent de définir le service lié :
- ID de l'application
- Clé de l'application
- ID client
Accordez l’autorisation nécessaire au principal de service. Pour obtenir des exemples sur le fonctionnement des autorisations dans Azure Cosmos DB, consultez Listes de contrôle d’accès sur les fichiers et répertoires. Plus spécifiquement, créez une définition de rôle et attribuez le rôle au principal de service par le biais de l’ID d’objet du principal de service.
Ces propriétés sont prises en charge pour le service lié :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur CosmosDb. | Oui |
| accountEndpoint | Spécifiez l’URL du point de terminaison du compte pour l’instance Azure Cosmos DB. | Oui |
| database | Spécifiez le nom de la base de données. | Oui |
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalCredentialType | Type d’informations d’identification à utiliser pour l’authentification de principal du service. Les valeurs autorisées sont ServicePrincipalKey et ServicePrincipalCert. | Oui |
| servicePrincipalCredential | Informations d’identification du principal du service. Quand vous utilisez ServicePrincipalKey comme type d’informations d’identification, spécifiez la clé de l’application. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. Lorsque vous utilisez ServicePrincipalCert comme informations d’identification, référencez un certificat dans Azure Key Vault et vérifiez que le type de contenu du certificat est PKCS #12. |
Oui |
| tenant | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) dans lesquels se trouve votre application. Récupérez-les en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| azureCloudType | Pour l’authentification du principal de service, spécifiez le type d’environnement cloud Azure auquel votre application Microsoft Entra est inscrite. Les valeurs autorisées sont AzurePublic, AzureChina, AzureUsGovernment et AzureGermany. Par défaut, l’environnement cloud du service est utilisé. |
Non |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Exemple : utilisation de l’authentification de la clé du principal de service
Vous pouvez également stocker la clé du principal du service dans Azure Key Vault.
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : utilisation de l’authentification par certificat du principal du service
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’identité managée affectée par le système
Remarque
Actuellement, l’authentification par identité managée affectée par le système est prise en charge dans les flux de données par le biais de propriétés avancées au format JSON.
Une fabrique de données ou un pipeline Synapse peut être associé à une identité managée affectée par le système pour les ressources Azure, qui représente cette instance de service spécifique. Vous pouvez utiliser directement cette identité managée pour l’authentification Azure Cosmos DB, ce qui revient à utiliser votre propre principal de service. Cela permet à la ressource désignée d’accéder aux données et de copier les données depuis ou vers votre instance Azure Cosmos DB.
Pour utiliser l’authentification d’identités managées affectées par le système pour les ressources Azure, suivez les étapes ci-après.
Récupérez les informations d’identité managée affectée par le système en copiant la valeur de l’ID d’objet d’identité managée générée en même temps que votre service.
Accordez à l’identité managée affectée par le système une autorisation appropriée. Pour obtenir des exemples sur le fonctionnement des autorisations dans Azure Cosmos DB, consultez Listes de contrôle d’accès sur les fichiers et répertoires. Plus précisément, créez une définition de rôle, puis attribuez le rôle à l’identité managée affectée par le système.
Ces propriétés sont prises en charge pour le service lié :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur CosmosDb. | Oui |
| accountEndpoint | Spécifiez l’URL du point de terminaison du compte pour l’instance Azure Cosmos DB. | Oui |
| database | Spécifiez le nom de la base de données. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
| subscriptionId | Spécifier l’ID d’abonnement pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
| tenantId | Spécifier l’ID de locataire pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
| resourceGroup | Spécifier le nom du groupe de ressources pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
Exemple :
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’identité managée affectée par l’utilisateur
Remarque
Actuellement, l’authentification par identité managée affectée par l’utilisateur est prise en charge dans les flux de données à l’aide de propriétés avancées au format JSON.
Une fabrique de données ou un pipeline Synapse peut être associé à une identité managée affectée par l’utilisateur, qui représente cette instance de service spécifique. Vous pouvez utiliser directement cette identité managée pour l’authentification Azure Cosmos DB, ce qui revient à utiliser votre propre principal de service. Cela permet à la ressource désignée d’accéder aux données et de copier les données depuis ou vers votre instance Azure Cosmos DB.
Pour utiliser l’authentification d’identités managées affectées par l’utilisateur pour les ressources Azure, suivez les étapes ci-après.
Créez une ou plusieurs identités managées affectées par l’utilisateur, puis octroyez-leur les autorisations appropriées. Pour obtenir des exemples sur le fonctionnement des autorisations dans Azure Cosmos DB, consultez Listes de contrôle d’accès sur les fichiers et répertoires. Plus précisément, créez une définition de rôle, puis attribuez le rôle à l’identité managée affectée par l’utilisateur.
Attribuez une ou plusieurs identités managées affectées par l’utilisateur à votre fabrique de données et créez des informations d’identification pour chaque identité managée affectée par l’utilisateur.
Ces propriétés sont prises en charge pour le service lié :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur CosmosDb. | Oui |
| accountEndpoint | Spécifiez l’URL du point de terminaison du compte pour l’instance Azure Cosmos DB. | Oui |
| database | Spécifiez le nom de la base de données. | Oui |
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
| subscriptionId | Spécifier l’ID d’abonnement pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
| tenantId | Spécifier l’ID de locataire pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
| resourceGroup | Spécifier le nom du groupe de ressources pour l’instance Azure Cosmos DB | Non pour l’activité de copie, Oui pour le flux de données de mappage |
Exemple :
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez Jeux de données et services liés.
Les propriétés prises en charge pour le jeu de données Azure Cosmos DB for SQL sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur CosmosDbSqlApiCollection. | Oui |
| collectionName | Nom de la collection de documents Azure Cosmos DB. | Oui |
Si vous utilisez un jeu de données de type « DocumentDbCollection », il est toujours pris en charge tel quel pour la compatibilité descendante dans l’activité de copie et de recherche, mais il n'est pas pris en charge pour le flux de données. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Exemple
{
"name": "CosmosDbSQLAPIDataset",
"properties": {
"type": "CosmosDbSqlApiCollection",
"linkedServiceName":{
"referenceName": "<Azure Cosmos DB linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"collectionName": "<collection name>"
}
}
}
Propriétés de l’activité de copie
Cette section fournit la liste des propriétés prises en charge par Azure Cosmos DB for NoSQL en tant que source et récepteur. Pour obtenir la liste complète des sections et des propriétés permettant de définir des activités, consultez Pipelines.
Azure Cosmos DB for NoSQL comme source
Pour copier des données à partir d’Azure Cosmos DB for NoSQL, affectez la valeur DocumentDbCollectionSource au type source dans l’activité de copie.
Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur CosmosDbSqlApiSource. | Oui |
| query | Spécifiez la requête Azure Cosmos DB pour lire les données. Exemple : SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\" |
Aucune À défaut de spécification, cette instruction SQL est exécutée : select <columns defined in structure> from mycollection |
| preferredRegions | Liste des régions préférées auxquelles se connecter lors de la récupération des données d’Azure Cosmos DB. | Non |
| pageSize | nombre de documents par page du résultat de la requête. La valeur par défaut est « -1 », qui utilise la page dynamique côté service jusqu’à 1000. | Non |
| detectDatetime | Indique s'il faut détecter la date/heure à partir des valeurs de chaîne dans les documents. Valeurs autorisées : true (par défaut) et false. | Non |
Si vous utilisez une source de type « DocumentDbCollectionSource », elle est toujours prise en charge telle quelle pour une compatibilité descendante. Nous vous suggérons d'utiliser le nouveau modèle à l'avenir, qui offre des fonctionnalités plus riches pour copier les données à partir d’Azure Cosmos DB.
Exemple
"activities":[
{
"name": "CopyFromCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cosmos DB for NoSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CosmosDbSqlApiSource",
"query": "SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\"",
"preferredRegions": [
"East US"
]
},
"sink": {
"type": "<sink type>"
}
}
}
]
Lorsque vous copiez des données à partir d’Azure Cosmos DB, à moins que vous ne souhaitiez exporter des documents JSON en l'état, la meilleure pratique consiste à spécifier le mappage dans l'activité de copie. Le service respecte le mappage que vous avez spécifié sur l'activité. Si une ligne ne contient pas de valeur pour une colonne, une valeur nulle est fournie pour cette colonne. Si vous ne spécifiez aucun mappage, le service déduit le schéma par rapport à la première ligne des données. Si la première ligne ne contient pas le schéma complet, certaines colonnes ne seront pas incluses dans le résultat de l’opération d’activité.
Azure Cosmos DB for NoSQL comme récepteur
Pour copier des données vers Azure Cosmos DB for NoSQL, affectez la valeur DocumentDbCollectionSink au type récepteur dans l’activité de copie.
Les propriétés suivantes sont prises en charge dans la section sink de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur d’activité de copie doit être définie sur CosmosDbSqlApiSink. | Oui |
| writeBehavior | Décrit comment écrire des données dans Azure Cosmos DB. Les valeurs autorisées sont insert et upsert. Le comportement de la valeur upsert consiste à remplacer le document si un document portant le même identificateur existe déjà ; sinon, le document est inséré. Remarque : Le service génère automatiquement un ID pour un document si aucun ID n’est spécifié ni dans le document d’origine ni par le mappage de colonnes. Cela signifie que vous devez vérifier que votre document comporte un ID afin qu’upsert fonctionne comme prévu. |
Non (la valeur par défaut est insert) |
| writeBatchSize | Le service utilise la bibliothèque d’exécuteur en bloc Azure Cosmos DB pour écrire les données dans Azure Cosmos DB. La propriété writeBatchSize contrôle la taille des documents fournis par le service à la bibliothèque. Vous pouvez essayer d’augmenter la valeur de writeBatchSize pour améliorer les performances et diminuer la valeur si la taille de votre document est grande (voir les conseils ci-dessous). | Non (la valeur par défaut est 10 000) |
| disableMetricsCollection | Le service collecte des métriques telles que les unités de requête Azure Cosmos DB pour effectuer des suggestions et optimiser les performances de copie. Si ce comportement vous préoccupe, spécifiez true pour le désactiver. |
Non (la valeur par défaut est false) |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Aucune |
Conseil
Pour importer des documents JSON en l'état, consultez la section Importer ou exporter des documents JSON. Pour copier à partir de données au format tabulaire, consultez Migrer de la base de données relationnelle vers Azure Cosmos DB.
Conseil
Azure Cosmos DB limite la taille des demandes uniques à 2 Mo. La formule est la suivante : taille de la demande = taille de document unique * taille d’écriture Batch. Si vous rencontrez le message d’erreur « La taille de la demande est trop grande », réduisez la valeur de writeBatchSize dans la configuration du récepteur de copie.
Si vous utilisez une source de type « DocumentDbCollectionSink », elle est toujours prise en charge telle quelle pour une compatibilité descendante. Nous vous suggérons d'utiliser le nouveau modèle à l'avenir, qui offre des fonctionnalités plus riches pour copier les données à partir d’Azure Cosmos DB.
Exemple
"activities":[
{
"name": "CopyToCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "CosmosDbSqlApiSink",
"writeBehavior": "upsert"
}
}
}
]
Mappage de schéma
Pour copier des données d'Azure Cosmos DB vers un récepteur tabulaire ou inversement, consultez Mise en correspondance du schéma.
Propriétés du mappage de flux de données
Lors de la transformation de données dans le flux de données de mappage, vous pouvez lire et écrire dans des collections d’Azure Cosmos DB. Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage.
Notes
Le mode Azure Cosmos DB serverless n’est pas pris en charge dans le flux de données de mappage.
Transformation de la source
Les paramètres spécifiques à Azure Cosmos DB sont disponibles dans l'onglet Options de la source de la transformation de la source.
Inclure les colonnes système : si ce paramètre est activé, id, _ts et d’autres colonnes système seront englobées dans vos métadonnées de flux de données d’Azure Cosmos DB. Lors de la mise à jour de collections, il est important de l’inclure, afin de pouvoir récupérer l’ID de ligne existant.
Taille de la page : nombre de documents par page du résultat de la requête. La valeur par défaut est « -1 », qui utilise la page dynamique du service jusqu’à 1 000.
Débit :définissez une valeur facultative du nombre de RU que vous souhaitez appliquer à votre collection Azure Cosmos DB pour chaque exécution de ce flux de données pendant l’opération de lecture. La valeur minimale est 400.
Régions préférées : choisissez les régions de lecture privilégiées pour ce processus.
Flux de modification : si ce paramètre est activé, vous obtiendrez automatiquement des données à partir du flux de modification Azure Cosmos DB, qui est un enregistrement persistant des modifications apportées à un conteneur dans l’ordre dans lequel elles se sont produites depuis la dernière exécution. Lorsque vous activez ce paramètre, n’activez pas les deux options Déduire les types de colonnes dérivés et Autoriser la dérive de schéma à la fois. Pour plus d’informations, consultez Flux de modification Azure Cosmos DB.
Commencer depuis le début : Si ce paramètre est activé, vous obtiendrez le chargement initial des données complètes d’instantané lors de la première exécution, suivi de la capture des données modifiées lors des prochaines exécutions. S’il est désactivé, le chargement initial sera ignoré lors de la première exécution, suivi de la capture des données modifiées lors des prochaines exécutions. Ce paramètre est aligné avec celui du même nom dans Référence Azure Cosmos DB. Pour plus d’informations, consultez Flux de modification Azure Cosmos DB.
Transformation du récepteur
Les paramètres spécifiques à Azure Cosmos DB sont disponibles dans l'onglet Paramètres de la transformation du récepteur.
Méthode de mise à jour : détermine les opérations autorisées sur la destination de votre base de données. Par défaut, seules les insertions sont autorisées. Pour mettre à jour, effectuer un upsert ou supprimer des lignes, une transformation alter-row est requise afin de baliser les lignes relatives à ces actions. Pour les mises à jour, les opérations upsert et les suppressions, une ou plusieurs colonnes clés doivent être définies pour déterminer la ligne à modifier.
Action relative à la collection : détermine si la collection de destination doit être recréée avant l'écriture.
- Aucune : aucune action ne sera effectuée sur la collection.
- Recréer : la collection sera supprimée et recréée.
Taille du lot : entier représentant le nombre d'objets en cours d'écriture dans la collection Azure Cosmos DB au sein de chaque lot. En général, la taille de lot par défaut est suffisante pour commencer. Pour affiner cette valeur, notez que :
- Azure Cosmos DB limite la taille des demandes uniques à 2 Mo. La formule est la suivante : Taille de la demande = Taille d'un seul document x Taille du lot. Si vous rencontrez le message d'erreur « La taille de la demande est trop importante », réduisez la valeur de la taille du lot.
- Plus la taille du lot est importante, meilleur est le débit que le service peut atteindre. Vous devez aussi vous assurer d'allouer suffisamment d'unités de requête pour optimiser votre charge de travail.
Clé de partition : Entrez une chaîne qui représente la clé de partition de votre collection. Exemple : /movies/title
Débit : définissez une valeur facultative du nombre de RU que vous souhaitez appliquer à votre collection Azure Cosmos DB pour chaque exécution de ce flux de données. La valeur minimale est 400.
Budget du débit d'écriture : Entier représentant les unités de requête que vous souhaitez allouer pour cette opération d'écriture de flux de données, par rapport au débit total alloué à la collection.
Remarque
Pour limiter l’utilisation des UR, réglez le paramètre Cosmos DB Throughput(autoscale) sur Manual.
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Importer et exporter des documents JSON
À l’aide de ce connecteur Azure Cosmos DB for NoSQL, vous pouvez facilement :
- Copier des documents entre deux collections Azure Cosmos DB en l’état.
- Importer des documents JSON de différentes sources dans Azure Cosmos DB, notamment depuis le Stockage Blob Azure, Azure Data Lake Store et d’autres magasins de données basés sur des fichiers pris en charge par le service.
- Exporter des documents JSON d’une collection Azure Cosmos DB vers différentes banques basées sur des fichiers.
Pour obtenir une copie indépendante du schéma :
- Lors de l’utilisation de l’outil de copie de données, sélectionnez l’option Exporter en l’état dans des fichiers JSON ou une collection Azure Cosmos DB.
- Lors de l’utilisation de la création d’activité, choisissez le format JSON avec le magasin de fichiers correspondant à la source ou au récepteur.
Migrer de la base de données relationnelle vers Azure Cosmos DB
Lors de la migration d'une base de données relationnelle (par exemple, SQL Server) vers Azure Cosmos DB, l'activité de copie peut facilement mapper des données tabulaires de la source pour aplatir les documents JSON dans Azure Cosmos DB. Dans certains cas, vous souhaiterez peut-être reconcevoir le modèle de données afin de l’optimiser pour les cas d’usage NoSQL, conformément à Modélisation des données dans Azure Cosmos DB, par exemple pour dénormaliser les données en incorporant tous les sous-éléments associés dans un document JSON. Reportez-vous alors à cet article. Celui-ci contient une procédure pas à pas décrivant comment y parvenir à l’aide de l’activité de copie (Copy).
Azure Cosmos DB - Flux de modification
Azure Data Factory peut récupérer des données à partir d’un flux de modification Azure Cosmos DB en l’activant dans la transformation source de flux de données de mappage. Avec cette option de connecteur, vous pouvez lire des flux de modification et appliquer des transformations avant de charger les données transformées dans les jeux de données de destination de votre choix. Vous n’avez pas besoin d’utiliser de fonctions Azure pour lire le flux de modification puis écrire des transformations personnalisées. Vous pouvez utiliser cette option pour déplacer des données d’un conteneur à un autre, préparer des vues de documents pilotées par flux de modification pour un usage précis, ou automatiser la sauvegarde ou la récupération de conteneurs en fonction du flux de modification, et activer de nombreux autres cas d’usage à l’aide de la fonctionnalité glisser-déplacer d’Azure Data Factory.
Veillez à ne pas changer le nom du pipeline et de l’activité, afin que le point de contrôle puisse être enregistré par ADF pour que vous puissiez obtenir automatiquement les données modifiées à partir de la dernière exécution. Si vous changez le nom de votre pipeline ou de votre activité, le point de contrôle est réinitialisé, ce qui vous oblige à recommencer depuis le début ou à récupérer les prochaines modifications lors de la prochaine exécution.
Lorsque vous déboguez le pipeline, cette fonctionnalité fonctionne de la même façon. Sachez que le point de contrôle est réinitialisé lorsque vous actualisez votre navigateur lors de l’exécution du débogage. Une fois que vous êtes satisfait du résultat du pipeline de l’exécution du débogage, vous pouvez publier et déclencher le pipeline. Au moment où vous déclenchez pour la première fois votre pipeline publié, il redémarre automatiquement à partir du début ou obtient les modifications à partir de ce moment-là.
Dans la section de monitoring, vous avez toujours la possibilité de réexécuter un pipeline. Dans ce cas, les données modifiées sont toujours capturées à partir du point de contrôle précédent de votre exécution de pipeline sélectionnée.
En outre, le magasin analytique Azure Cosmos DB prend désormais en charge la capture des changements de données (CDC) pour l’API Azure Cosmos DB pour NoSQL et l’API Azure Cosmos DB pour Mongo DB (préversion publique). Le magasin analytique Azure Cosmos DB vous permet de consommer efficacement un flux incrémentiel et continu de données (insérées, mises à jour et supprimées) modifiées.
Contenu connexe
Pour obtenir la liste des magasins de données pris en charge par l'activité Copy en tant que sources et récepteurs, consultez Magasins de données pris en charge.