Charger des données dans Azure Data Lake Storage Gen2 avec Azure Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Lake Storage Gen2 est un ensemble de fonctionnalités dédiées à l'analytique du Big Data et intégrées au service Stockage Blob Azure. Il vous permet d’interagir avec vos données selon les deux paradigmes que sont le système de fichiers et le stockage d’objets.
Azure Data Factory (ADF) est un service d’intégration de données informatiques complètement managé. Vous pouvez utiliser le service pour remplir le lac avec des données provenant d’un ensemble étendu de banques de données locales et cloud lors de la création de vos solutions d’analytique. Pour une liste détaillée des connecteurs pris en charge, consultez le tableau de Banques de données prises en charge.
Azure Data Factory offre une solution de déplacement des données managées qui est évolutive. En raison de l’architecture évolutive d’Azure Data Factory elle peut ingérer des données à un débit élevé. Pour en savoir plus, voir Performances de l’activité de copie.
Cet article vous explique comment utiliser l’outil de copie de données de Data Factory pour charger des données depuis le service ’Amazon Web Services S3 dans Azure Data Lake Store Gen2. Vous pouvez procéder de même pour copier des données à partir d’autres types de banques de données.
Conseil
Pour copier des données à partir d’Azure Data Lake Storage Gen1 dans Gen2, reportez-vous à cette procédure pas à pas spécifique.
Prérequis
- Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Compte de stockage Azure avec Data Lake Storage Gen2 activé : Si vous n’avez pas de compte de stockage, créez-en un.
- Compte AWS avec un compartiment S3 qui contient des données : Cet article explique comment copier des données à partir d’Amazon S3. Vous pouvez utiliser d’autres magasins de données en procédant de la même façon.
Créer une fabrique de données
Si vous n’avez pas encore créé votre fabrique de données, suivez les étapes de démarrage rapide : Créer une fabrique de données à l’aide du Portail Azure et Azure Data Factory Studio pour en créer une. Après la création, accédez à la fabrique de données dans le Portail Azure.

Sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio pour lancer l’application d’intégration de données dans un onglet distinct.
Charger des données dans Azure Data Lake Storage Gen2
Dans la page d’accueil d’Azure Data Factory, sélectionnez la vignette Ingérer pour lancer l’outil Copier des données.
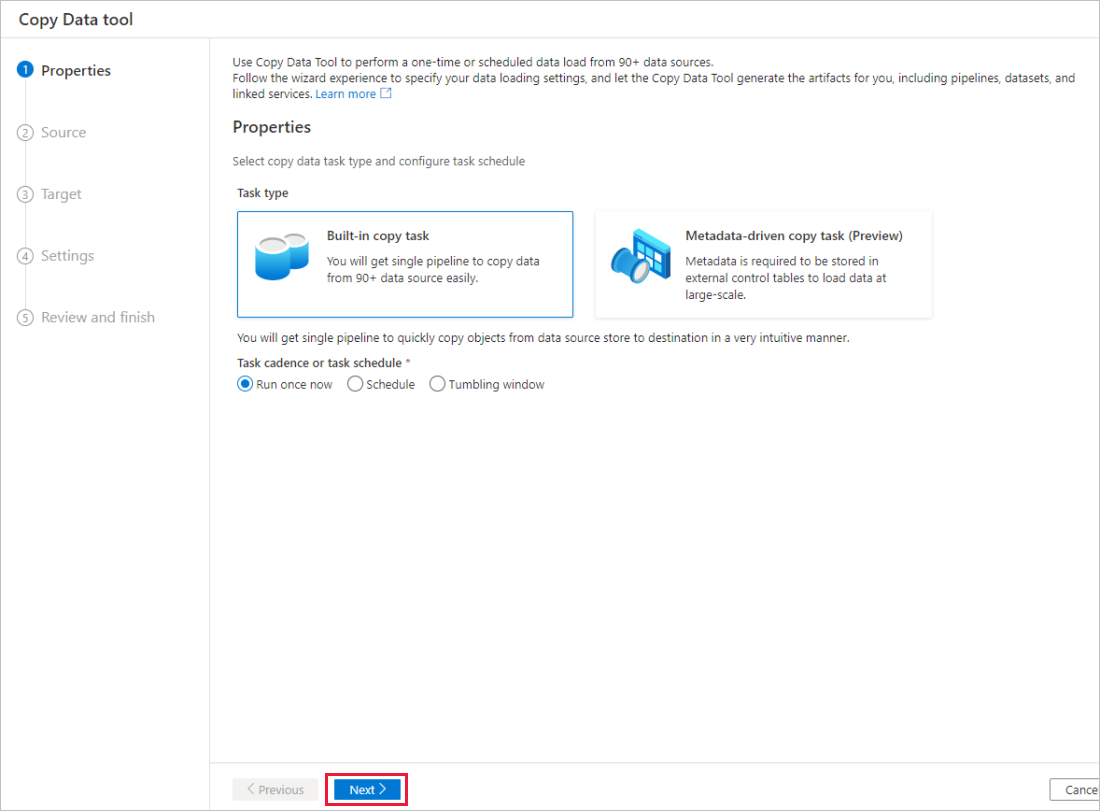
Dans la page Propriétés, choisissez Tâche de copie intégrée sous Type de tâche, et Exécuter une fois maintenant sous Cadence ou planification des tâches, puis sélectionnez Suivant.
Dans la page Banque de données source, effectuez les étapes suivantes :
Sélectionnez + Nouvelle connexion. Sélectionnez Amazon S3 dans la galerie des connecteurs, puis sélectionnez Continuer.

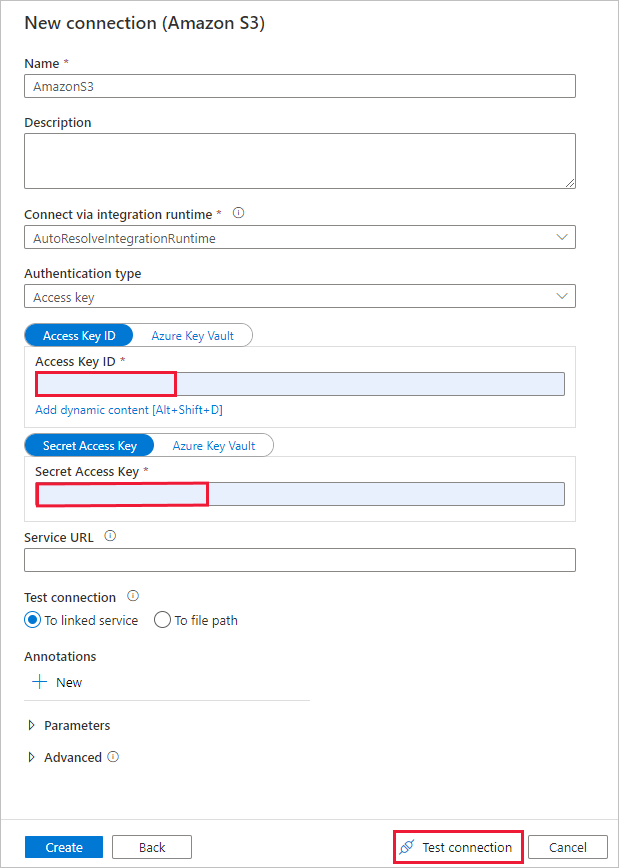
Dans la page Nouvelle connexion (Amazon S3) , procédez comme suit :
- Spécifiez la valeur du champ ID de clé d’accès.
- Spécifiez la valeur Clé d’accès secrète.
- Sélectionnez Tester la connexion pour valider les paramètres, puis sélectionnez Créer.
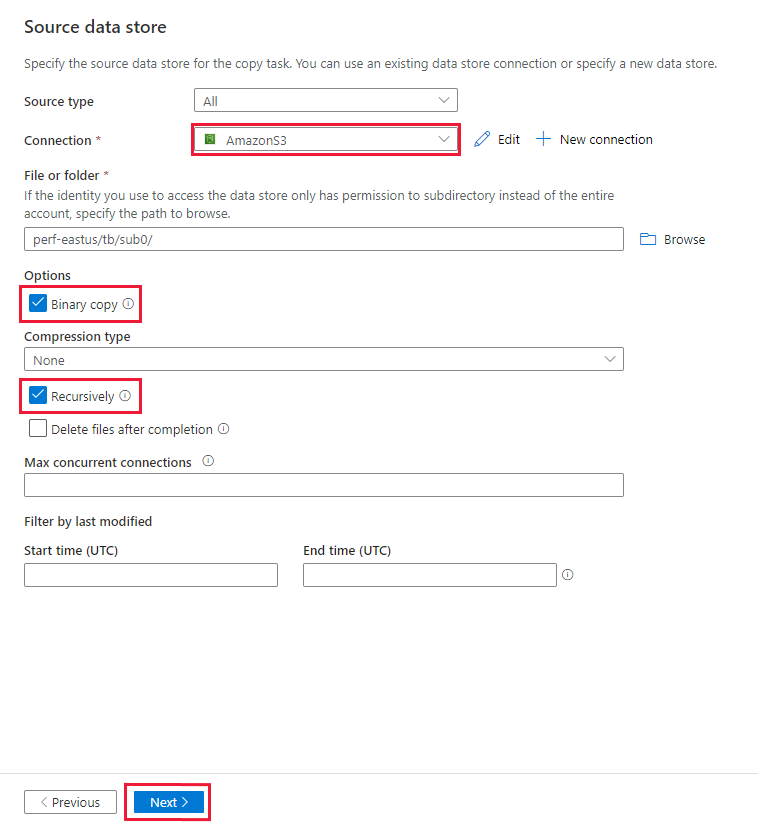
Sur la page Banque de données sources, assurez-vous que la connexion Amazon S3 nouvellement créée est sélectionnée dans le bloc Connexion.
Dans la section Fichier ou dossier, accédez au dossier ou au fichier que vous voulez copier. Sélectionnez le dossier ou le fichier, puis sélectionnez OK.
Spécifiez le comportement de copie en cochant les options Copier les fichiers de façon récursive et Copie binaire. Sélectionnez Suivant.
Dans la page Banque de données de destination, suivez les étapes suivantes.
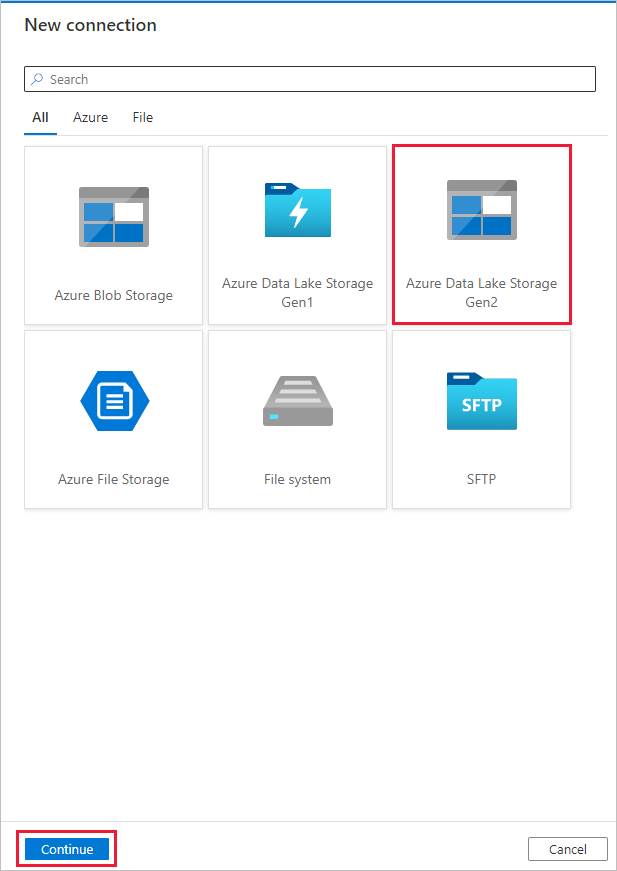
Sélectionnez + Nouvelle connexion, Azure Data Lake Storage Gen2, puis Continuer.
Dans la page Nouvelle connexion (Azure Data Lake Storage Gen2) , sélectionnez votre compte Data Lake Storage Gen2 dans la liste déroulante « Nom du compte de stockage », puis sélectionnez Créer pour créer la connexion.
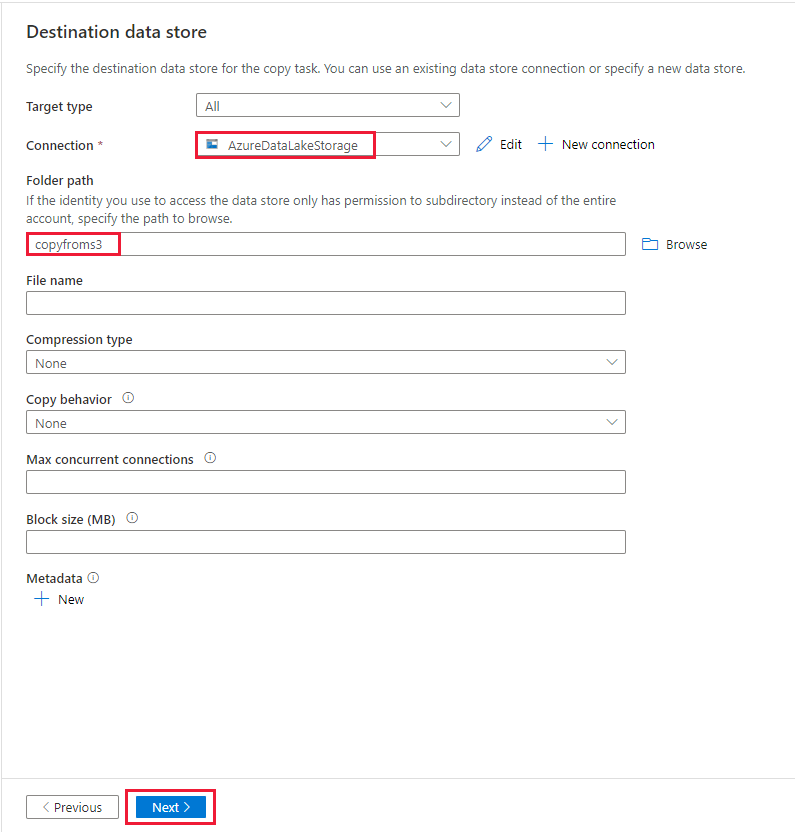
Dans la page Magasin de données de destination, sélectionnez la connexion nouvellement créée dans le bloc Connexion. Ensuite, sous Chemin d’accès du dossier, entrez copyfroms3 comme nom du dossier de sortie, puis sélectionnez Suivant. ADF crée le système de fichiers ADLS Gen2 et les sous-dossiers correspondants pendant la copie s’ils n’existent pas.
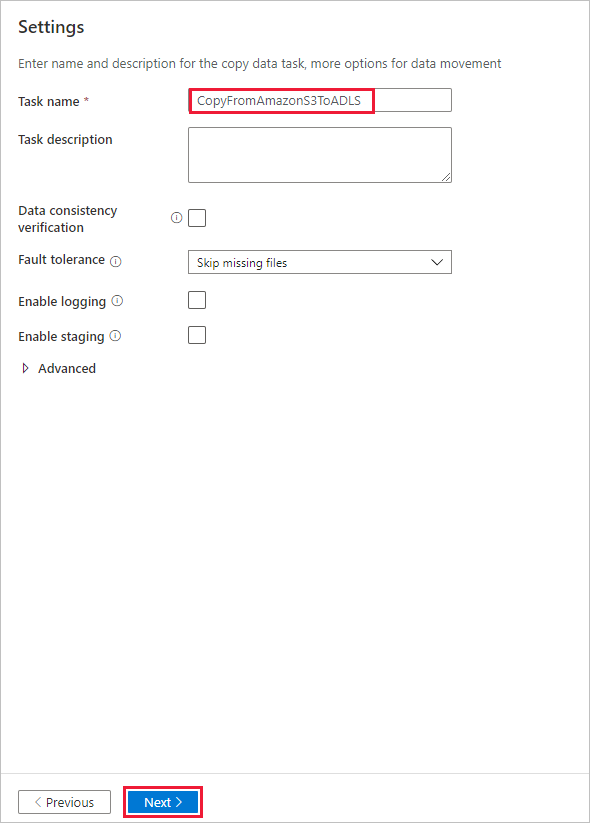
Dans la page Paramètres, spécifiez CopyFromAmazonS3ToADLS pour le champ Nom de tâche, puis sélectionnez Suivant pour utiliser les paramètres par défaut.
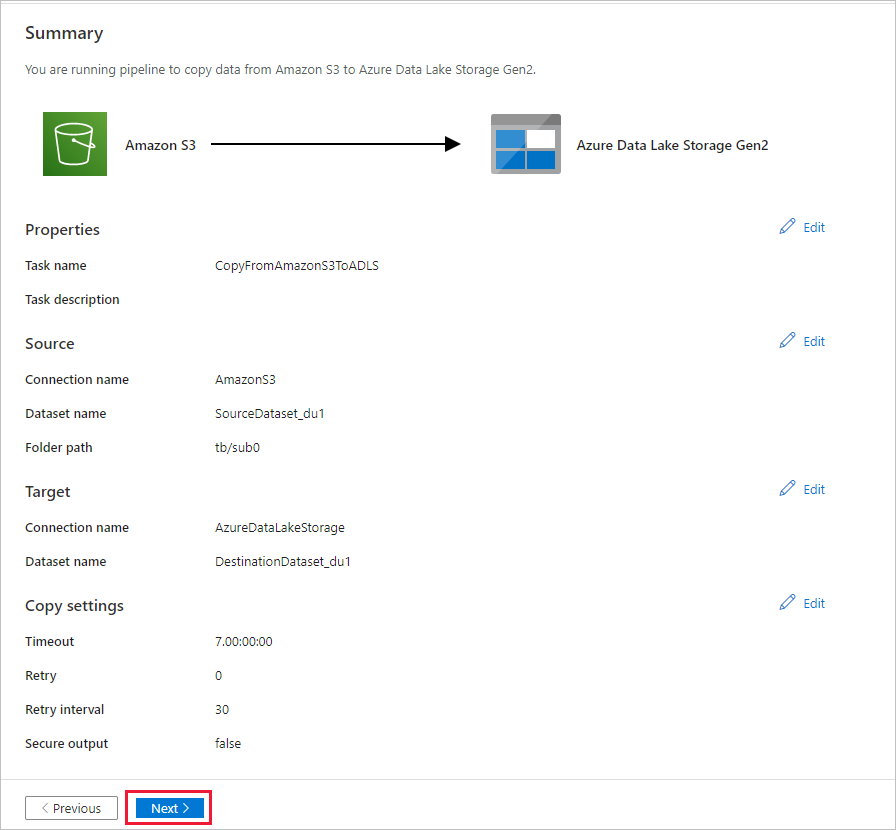
Dans la page Résumé, vérifiez les paramètres, puis cliquez sur Suivant.
Sur la page Déploiement, sélectionnez Surveiller pour surveiller le pipeline (tâche).
Lorsque l’exécution du pipeline se termine avec succès, vous voyez une exécution de pipeline qui est déclenchée par un déclencheur manuel. Vous pouvez utiliser les liens sous la colonne Nom du pipeline pour voir les détails de l’activité et réexécuter le pipeline.
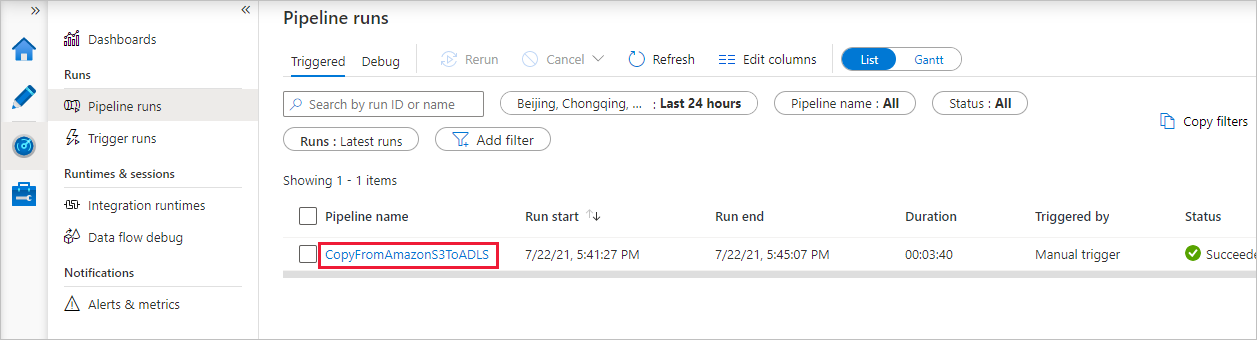
Pour voir les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien CopyFromAmazonS3ToADLS sous la colonne Nom du pipeline. Pour plus de détails sur l’opération de copie, sélectionnez le lien Détails (icône en forme de lunettes) dans la colonne Nom de l’activité. Vous pouvez suivre les informations détaillées comme le volume de données copiées à partir de la source dans le récepteur, le débit des données, les étapes d’exécution avec une durée correspondante et la configuration utilisée.
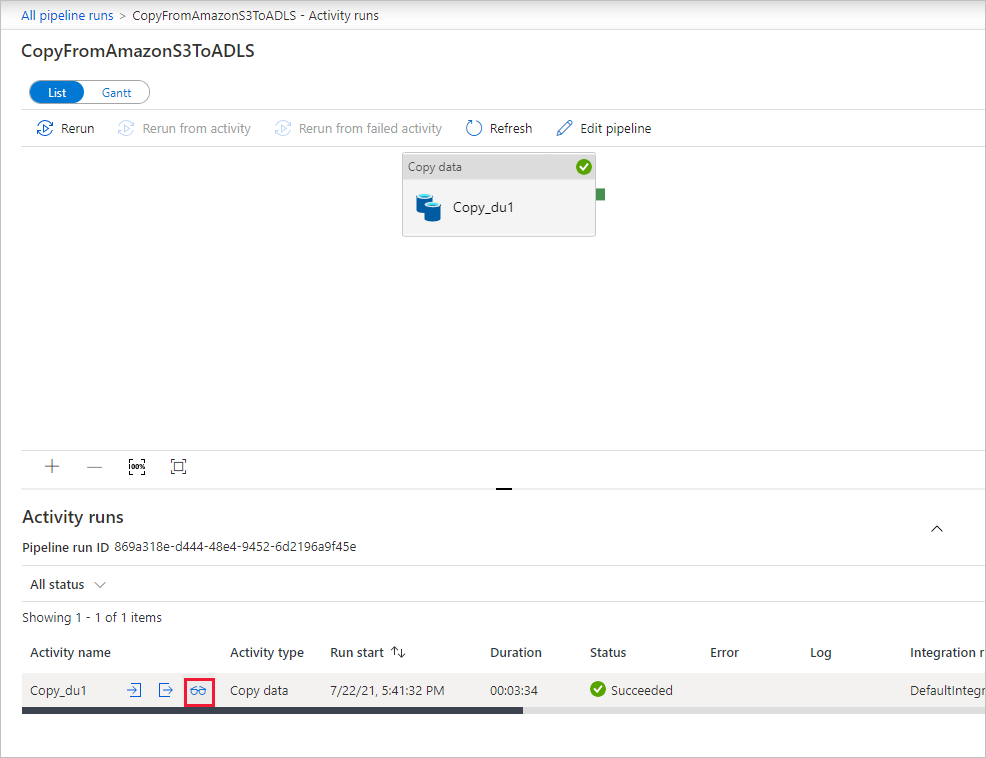
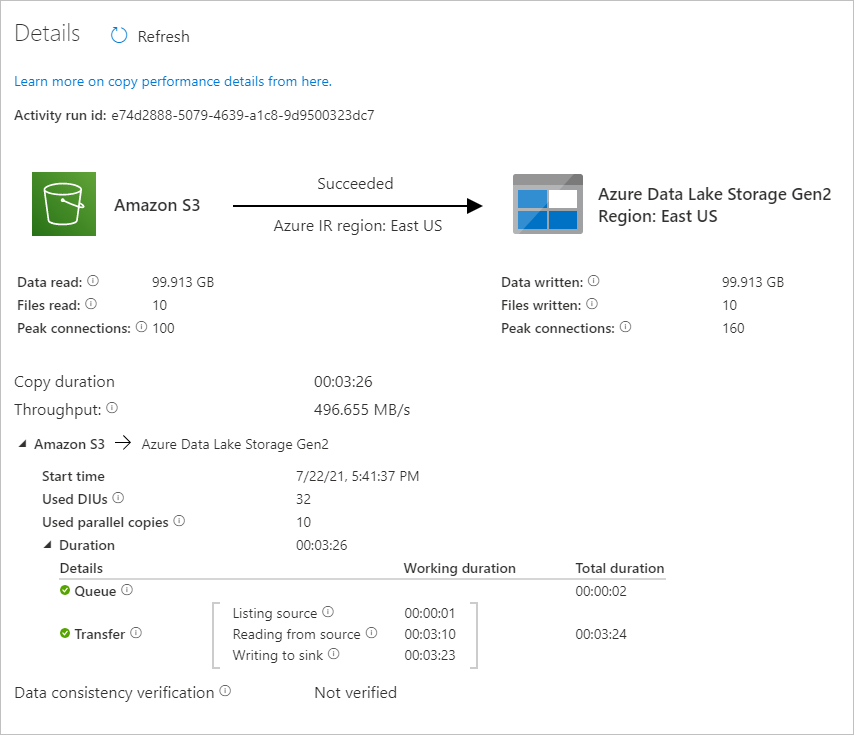
Sélectionnez Actualiser pour actualiser l’affichage. Sélectionnez Toutes les exécutions de pipelines en haut pour revenir à l’affichage « Exécutions de pipeline ».
Vérifiez que les données sont copiées dans votre compte Azure Data Lake Store Gen2 :