Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
À l’aide de Copilot Studio, vous pouvez améliorer vos agents avec des connaissances spécifiques au domaine alimentées par les mêmes sources de données approuvées et familières que vous créez via des connecteurs Power Platform.
Lorsque vous chargez du contenu externe à partir de votre appareil, OneDrive ou SharePoint, vous pouvez enrichir vos agents avec des connaissances contextuelles adaptées à votre entreprise. Microsoft Dataverse stocke ces fichiers en toute sécurité et les traite automatiquement en index sémantiques et en incorporations vectorielles. Cette configuration permet à vos assistants de générer des réponses plus précises, ancrées sur les informations que vous fournissez.
Les fichiers chargés dans Copilot Studio utilisent Microsoft Dataverse pour ingérer des fichiers bruts et créer des index et des incorporations vectorielles. Ces index et inclusions aident à fournir des réponses de qualité à vos agents. Vous pouvez charger ces fichiers à partir de votre ordinateur ou en vous connectant à OneDrive ou SharePoint.
Lorsque vous téléchargez des fichiers comme sources de connaissances, vous enrichissez vos agents avec des données supplémentaires, augmentez les connaissances du modèle de langage et ancrez l’agent dans des informations spécifiques que vous fournissez. Vous pouvez charger différents fichiers, que le système indexe sémantiquement en tant qu’incorporations vectorielles, puis les utilise comme connaissances pour les agents. Vous pouvez partager ces connaissances appliquées aux agents avec les utilisateurs, qu'ils soient authentifiés ou non, de l'agent.
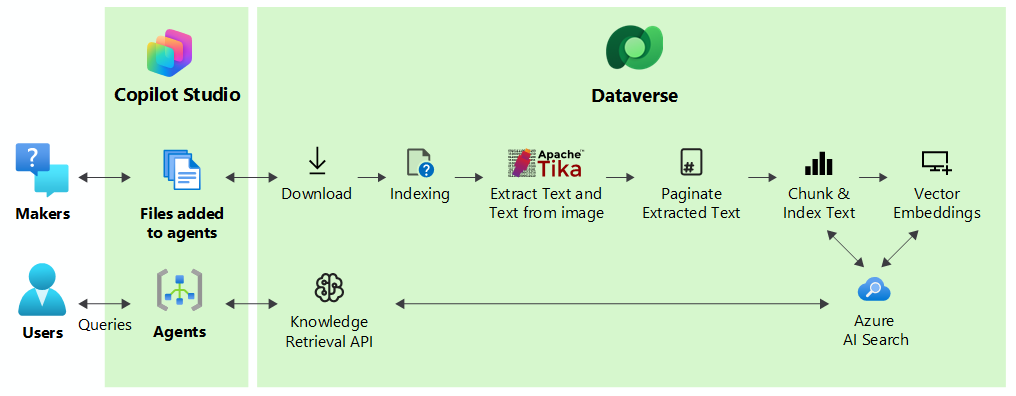
Pour améliorer les réponses d’un agent, le système téléchargeait les fichiers en pièces pour un traitement plus rapide et les indexait vectoriellement pour fournir des correspondances sémantiques avec la requête de l’utilisateur. Le système stocke les fichiers de manière sécurisée dans Dataverse. Lorsqu’un utilisateur interroge un agent, Copilot Studio trouve les blocs les plus pertinents qui correspondent à l’intention de la requête utilisateur et retourne les résultats à l’utilisateur.
De même, Dataverse ingère des fichiers OneDrive et SharePoint à l’aide des options de chargement de fichiers. Il ingère également du contenu non structuré, tel que des articles de base de connaissances de Salesforce, ServiceNow, Confluence et Zendesk, afin de fournir de meilleurs résultats sémantiques pour l’agent.
Note
En savoir plus sur Utiliser l’interpréteur de code pour analyser des données structurées.
Connecteurs Power Platform pour les données non structurées
Les connecteurs Power Platform suivants fonctionnent avec des sources de données non structurées :
OneDrive
Utilisez l’option Charger des fichiers > OneDrive avec une interface de sélecteur de fichiers pour choisir les fichiers et dossiers à inclure. Une fois sélectionnés, le système récupère les éléments dans Dataverse et les indexe pour utilisation. Les dossiers que vous ajoutez incluent tous les fichiers et sous-dossiers supportés dans ce dossier jusqu’à la limite totale de fichiers.
SharePoint
Utilisez l’option Charger des fichiers > SharePoint pour sélectionner des fichiers et des dossiers via une interface de sélecteur de fichiers. Après avoir sélectionné ces éléments, le connecteur les récupère dans Dataverse et les indexe pour une utilisation. Lorsque vous ajoutez des dossiers, vous incluez tous les fichiers et sous-dossiers pris en charge dans ce dossier jusqu’à la limite totale des fichiers. Actuellement, le connecteur ne prend pas en charge les pages.
Note
Lorsque vous utilisez SharePoint comme source de connaissances, Copilot Studio récupère du contenu via l’indexation de recherche SharePoint, et non en lisant directement des vues de liste telles que AllItems.aspx. Les éléments SharePoint récemment ajoutés ou mis à jour peuvent ne pas être disponibles pour l’agent tant que l’indexation de recherche n’est pas terminée. Vérifiez que l’agent dispose des autorisations requises, telles que Sites.Read.All et Files.Read.All, et que le contenu est stocké dans les formats de fichiers pris en charge.
Salesforce
Le connecteur Salesforce pour les données non structurées prend en charge la récupération des bases de connaissances qui contiennent des articles de connaissances. Sélectionnez une base de connaissances et le connecteur indexe tous les articles de cette base de connaissances. Vous ne pouvez pas sélectionner des articles ou des sujets individuels. Lors de l’interrogation de données, vous ne pouvez pas spécifier un article ou une base de connaissances spécifique. La liste des connaissances affiche un seul objet pour tous les objets de la base de connaissances que vous sélectionnez lors de la création de la source.
ServiceNow
Le connecteur ServiceNow pour les données non structurées prend en charge la récupération des bases de connaissances qui contiennent des articles de connaissances. Les bases de connaissances contiennent des articles. Sélectionnez une base de connaissances et le connecteur indexe tous les articles de cette base de connaissances. Vous ne pouvez pas sélectionner des articles individuels. Lors de l’interrogation de données, vous ne pouvez pas spécifier une base de connaissances, un dossier ou un article individuel. La liste des connaissances affiche un seul objet pour tous les objets de la base de connaissances que vous sélectionnez lors de la création de la source.
Confluence
Le connecteur Confluence pour les données non structurées prend en charge la récupération des espaces qui contiennent des pages. Le connecteur prend également en charge les sous-dossiers. Vous ne pouvez pas sélectionner des pages individuelles. Lors de la requête des données, vous ne pouvez pas spécifier une page. La liste des connaissances affiche un seul objet pour toutes les pages de l’espace.
Zendesk
Le connecteur Zendesk pour les données non structurées prend en charge la récupération de la base de connaissances qui contient des articles de connaissances. Vous ne pouvez pas sélectionner des articles, catégories ou sections individuelles. Lors de la requête de données, vous ne pouvez pas spécifier un article, une catégorie ou une section. La liste des connaissances affiche un objet unique pour tous les articles de la base de connaissances.
Sécurité
Lorsqu’un utilisateur interroge un agent qui utilise une source Power Platform Connector, le système effectue des vérifications d’autorisation.
Accès au connecteur
Lorsque vous utilisez pour la première fois une source basée sur un connecteur, le système vous invite à sélectionner un connecteur Power Platform existant ou à en ajouter un. Ce processus garantit que vous partagez uniquement des données avec des fabricants disposant des autorisations appropriées pour accéder à la source de données.
Accès au contenu
Lorsqu’un utilisateur effectue une requête, le système utilise ses informations de connexion pour vérifier la source des données et vérifier qu’il a la permission de voir le contenu. Même si le système stocke localement les chunks et les indexes dans Dataverse, il effectue une vérification en temps réel des requêtes pour s’assurer que l’utilisateur actuel a accès aux données avant de fournir un résumé ou une réponse.
Note
- Le système ne retourne pas les résultats aux utilisateurs s’ils n’ont pas l’autorisation pour des ensembles spécifiques de fichiers ou d’articles de base de connaissances. À la place, ils reçoivent un message standard indiquant « aucun résultat n’a pu être trouvé ». Si les utilisateurs estiment qu’il doit y avoir des résultats pour cette source, ils doivent travailler avec leurs administrateurs pour s’assurer qu’ils disposent des autorisations sur les données qu’ils cherchent à atteindre. L’utilisateur doit lui être attribué un rôle de sécurité Dataverse approprié, comme le rôle d’Utilisateur de base.
- Le système ne stocke pas localement les informations sur les autorisations de contenu. Il effectue toutes les vérifications d’autorisation en direct avec la source pour s’assurer qu’elles sont les plus up-todates.
Fréquence d’actualisation des fichiers et de synchronisation
Une tâche de synchronisation planifiée conserve les fichiers connectés de OneDrive et de SharePoint, et les articles de connaissances non structurés sont actualisés. Ce travail s’exécute automatiquement en arrière-plan, en actualisant le contenu des fichiers et en réindexant les modifications pour fournir des résultats précis en réponse aux requêtes. Les actualisations gèrent non seulement les modifications apportées au contenu, mais vérifient également que tout contenu supprimé de la source n’apparaît plus dans les réponses aux requêtes. Actuellement, vous ne pouvez pas déclencher manuellement une actualisation.
Pour plus d'informations sur la synchronisation de la fréquence de rafraîchissement, consultez les limites des sources de données non structurées de Copilot Studio.
Gestionnaire de licences
Toutes les demandes impliquant des connaissances sont facturées selon les tarifs de messagerie de réponses génératives de Microsoft Copilot. Pour plus d’informations, voir Tarifs de facturation et gestion.
Si les sources de connaissances nécessitent l’ingestion de données, le stockage des données et les index correspondants pour récupérer ces données sont soumis aux droits de stockage du client. Pour plus d’informations sur la recherche en langage naturel Dataverse, voir Améliorer les expériences alimentées par IA avec la recherche Dataverse.
Limites et limitations
Lorsque vous activez pour la première fois le support des données non structurées, Dataverse peut prendre entre 5 et 30 minutes à configurer et indexer avant de traiter les fichiers ajoutés. La durée dépend de la taille de l’environnement Dataverse actuel.
Chaque agent peut avoir un maximum de 500 objets de connaissances. Ces objets peuvent être des fichiers, des dossiers, des articles de connaissance, des sites web ou d’autres sources.
À ce stade, un agent ne peut utiliser que cinq sources différentes à la fois. Par exemple, SharePoint, Dataverse, OneDrive ou d’autres sources.
Pour plus d’informations sur les limites et restrictions spécifiques pour les sources de données non structurées prises en charge, consultez les limites des sources de connaissances de données non structurées de Copilot Studio.
Note
Les agents de Copilot Studio nécessitent une recherche Dataverse pour utiliser cette source de connaissances. Si vous ne pouvez pas ajouter un fichier compatible Dataverse à un agent, demandez à votre administrateur d’activer la recherche Dataverse dans votre environnement. Pour plus d’informations sur la recherche Dataverse et sur la façon de la gérer, consultez La recherche Dataverse et configurez la recherche Dataverse pour votre environnement.
Pour accéder OneDrive et SharePoint contenu stocké dans Dataverse, les utilisateurs doivent disposer d’au moins une licence utilisateur de base pour Power Apps ou Dynamics 365. De plus, les permissions utilisateur de base doivent également inclure des permissions de lecture pour les tables et entités suivantes :
- Assemblage de plug-in
- Type de module
- Message du Kit de développement logiciel (SDK
- Étape de traitement des messages du SDK
- Image de l’étape de traitement des messages du Kit de développement logiciel (SDK)
Vous pouvez configurer ces autorisations dans le Centre d’administration Power Platform ou dans le Centre d’administration Dynamics 365.
FAQ
Quelle est la différence entre les deux options SharePoint dans Ajouter des connaissances ?
Dans la boîte de dialogue Add knowledge, vous voyez deux options SharePoint.

L’option SharePoint dans la section de chargement de fichiers (1) consiste à charger des fichiers ou dossiers individuels SharePoint dans votre agent. Cette option charge une copie du fichier de SharePoint vers Dataverse et conserve une relation synchrone pour maintenir le fichier à jour. Pendant les requêtes, SharePoint est accessible pour valider les autorisations utilisateur pour le contenu. Les fichiers stockés Dataverse consomment le stockage des données, mais fournissent une fonctionnalité de recherche sémantique de document complet et prennent en charge le texte dans des images pour certains types de documents tels que des fichiers PDF.
Utilisez l’option 1 lorsque vous souhaitez synchroniser rapidement et non les fichiers statiques chargés sur Dataverse. Il est automatiquement mis à jour lorsque les fichiers sources sont modifiés.
L’autre option SharePoint (2) fournit l’intégration complète SharePoint dans Copilot Studio à l’aide du connecteur SharePoint. Utilisez cette option lorsque vous avez besoin de fonctionnalités complètes de connecteur SharePoint, de configurations d’authentification personnalisées ou d’options de requête avancées.
Différences d’exécution
| Scénario | Option 1 : chargement de fichiers | Option 2 : Connecteur SharePoint |
|---|---|---|
| Stockage de contenu | Copié dans Dataverse à partir de SharePoint | Réside dans SharePoint |
| Fonctionnalité de recherche | Recherche un index sémantique Dataverse généré à partir de vecteurs incorporés du contenu ingéré copié à partir de SharePoint | Interroge directement l’infrastructure de recherche SharePoint |
| Actualisation du contenu | Le contenu est synchronisé toutes les quatre à six heures, en fonction de l’achèvement de l’ingestion | En temps réel et reflète le contenu disponible le plus récent |
| Listes SharePoint | Pris en charge | Non prise en charge |
| Consommation de stockage Dataverse | Oui, pour les fichiers copiés et les index de recherche | No |
| Filtres de requête avancés | Non disponible | Filtrer par titre, auteur, modifié par date de modification |
Utilisation des options
Utilisez l’option 1 dans les situations suivantes :
- Vous avez besoin de la prise en charge des listes SharePoint
- L’agent utilise uniquement un ensemble spécifique de fichiers ou de dossiers
- Vous souhaitez une recherche sémantique de haute qualité optimisée par des incorporations vectorielles
- Un intervalle d’actualisation du contenu de quatre à six heures suffit
Utilisez l’option 2 dans les situations suivantes :
- Aucun retard dans la synchronisation de contenu, tel qu’un wiki fréquemment mis à jour ou un site d’annonce
- Éviter la consommation de Dataverse, notamment pour les grandes bibliothèques de documents
- Utilisation de filtres de requête avancés, tels que le filtrage en fonction de l’auteur, de la date de modification ou du titre
Note
Les deux options nécessitent l’authentification de l’utilisateur. Les utilisateurs peuvent se connecter avant que l’agent récupère les résultats à partir du contenu SharePoint. En savoir plus sur le temps de synchronisation et les limites de fichiers dans les limites des sources de connaissance de données non structurées de Copilot Studio.
Pourquoi l’icône SharePoint n’est-elle pas affichée dans la section Charger des fichiers de la boîte de dialogue Ajouter des connaissances ?
Il y a un léger délai après l’installation d’une solution jusqu’à ce qu’elle apparaisse dans toutes les organisations existantes. Pour lancer une mise à jour manuelle, procédez comme suit :
Connectez-vous au centre d’administration Power Platform en utilisant les identifiants administrateurs.
Dans la barre latérale, sélectionnez Gérer.
Dans la liste des produits, sélectionnez Dynamics 365 Apps.
Recherchez poweraiextensions.
Sélectionnez les trois points (... ) pour Microsoft Dynamics 365 - PowerAIExtensions et sélectionnez Install.
Dans le menu déroulant, sélectionnez votre environnement, puis sélectionnez Installer.
Une fois l’installation terminée, ouvrez Power Apps dans une nouvelle fenêtre.
Dans le volet de gauche, sélectionnez Solutions.
Sélectionnez Détails.
Vérifiez que la version de PowerAIExtensions Solution Anchor est définie sur 1.01.688 ou version ultérieure.
Que se passe-t-il si j’ajoute plus de 500 objets de connaissances à mon assistant ?
Vous ne pouvez pas ajouter plus d’objets à moins de supprimer d’abord les objets précédents.
Chaque agent a-t-il son propre index de la source de connaissances ?
Dataverse stocke des sources de connaissances pour être utilisées dans l’environnement où vous les créez. Si plusieurs agents utilisent le même dossier SharePoint, tous les agents utilisent une seule instance de ce dossier.
Que se passe-t-il si j’ajoute un dossier SharePoint ou OneDrive qui dépasse le nombre maximal de fichiers, de dossiers et de sous-dossiers ?
Copilot Studio récupère et indexe jusqu’au nombre maximal de fichiers, de dossiers et de sous-dossiers. Il ne traite pas les éléments restants et n’indique pas quels éléments sont ou ne sont pas traités.
L’un des fichiers que j’ai ajoutés apparaît dans le cadre de la source de connaissances, mais je ne peux pas obtenir de réponses. Pourquoi ?
Ce problème peut être lié à l’une des raisons suivantes :
- La page Connaissances ne signale pas le fichier ou le dossier en tant que Prêt.
- Le nom de fichier inclut un caractère non pris en charge (spécifiquement pour les fichiers SharePoint).
- Le fichier a un paramètre de confidentialité confidentiel ou hautement confidentiel, ou a une protection par mot de passe.
- Le type de fichier n’est pas pris en charge.
- Le fichier ou le dossier provient du site OneDrive ou SharePoint d’un autre utilisateur et l’utilisateur ne l’a pas partagé avec vous.
- Le fichier est un fichier de base de connaissances et votre compte n’a pas les autorisations requises pour afficher le contenu dans le système source.