Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Une fois que vous avez terminé l’étiquetage de vos énoncés, vous pouvez vous lancer dans l’entraînement d’un modèle. L’apprentissage est le processus par lequel le modèle apprend à partir de vos énoncés étiquetés.
Pour effectuer l’apprentissage d’un modèle, démarrez un travail d’apprentissage. Seuls les travaux terminés avec succès créent un modèle. Un travail d’apprentissage expire au bout de sept jours. Passé ce délai, il est impossible de récupérer les détails de ce travail. Si votre travail d’apprentissage s’est terminé avec succès et qu’un modèle a été créé, il ne sera pas affecté par l’expiration du travail. Vous ne pouvez exécuter qu’un seul travail d’apprentissage à la fois. Vous ne pouvez pas non plus lancer d’autres travaux au sein du même projet.
Les durées de formation peuvent être comprises entre quelques secondes, pour des projets simples, et quelques heures, lorsque vous atteignez la limite maximale des énoncés.
L’évaluation du modèle est déclenchée automatiquement une fois l’entraînement effectué. Le processus d’évaluation commence par utiliser le modèle formé pour exécuter des prédictions sur les énoncés du jeu de tests et compare les résultats prédits avec les étiquettes fournies (qui établit une base de référence de vérité).
Prérequis
- Un projet créé correctement avec un compte de stockage Blob Azure configuré
- Énoncés étiquetés
Équilibrer les données d’apprentissage
Concernant les données d’apprentissage, essayez de garder votre schéma bien équilibré. Le fait d’inclure de grandes quantités d’une intention et très peu d’autres intentions aboutit à un modèle biaisé en faveur d’intentions particulières.
Pour remédier à ce problème, vous devrez peut-être sous-échantillonner votre jeu d’apprentissage. Vous devrez peut-être aussi l’étendre. Pour sous-échantillonner, vous pouvez :
- Vous débarrasser de façon aléatoire d’un certain pourcentage des données d’apprentissage.
- Analyser le jeu de données et supprimer les entrées en double surreprésentées, ce qui est une méthode plus systématique.
Pour étendre le jeu d’apprentissage, dans Language Studio, sous l’onglet Étiquetage des données, sélectionnez Suggérer des énoncés. La compréhension du langage courant envoie un appel à Azure OpenAI pour générer des énoncés similaires.

Vous pouvez également rechercher des « modèles » involontaires dans le jeu d’apprentissage. Par exemple, regardez si le jeu d’apprentissage d’une intention particulière est en minuscules ou commence par une expression particulière. Dans ce cas, le modèle que vous entraînez peut apprendre ces biais involontaires dans le jeu d’apprentissage au lieu de pouvoir généraliser.
Nous vous recommandons d’introduire une diversité de casses et de ponctuations dans le jeu d’apprentissage. Si votre modèle est censé gérer les variations, veillez à disposer d’un jeu d’apprentissage qui reflète également cette diversité. Par exemple, incluez certains énoncés dans une casse conventionnelle et d’autres entièrement en minuscules.
Fractionnement des données
Avant d’entamer le processus d’apprentissage, les énoncés étiquetés de votre projet sont divisés en deux jeux : un jeu d’apprentissage et un jeu de test. Chacun d’eux a une fonction différente. Le jeu d’apprentissage est utilisé dans l’apprentissage du modèle. Il s’agit de l’ensemble à partir duquel le modèle apprend les énoncés étiquetés. Le jeu de test est un jeu témoin qui n’est pas présenté au modèle pendant l’apprentissage, mais uniquement lors de l’évaluation.
Après l’apprentissage du modèle, il est utilisé pour effectuer des prédictions à partir des énoncés du jeu de tests. Ces prédictions sont utilisées pour calculer les métriques d’évaluation. Nous vous recommandons de vérifier que toutes vos intentions et entités sont correctement représentées dans les jeux d’entraînement et de test.
La compréhension du langage courant prend en charge deux méthodes de fractionnement des données :
- Fractionnement automatique du jeu de test à partir des données d’apprentissage : le système fractionne les données étiquetées en un jeu d’apprentissage et un jeu de test, selon les pourcentages que vous avez choisis. Le pourcentage recommandé pour le fractionnement est de 80 % pour l’apprentissage et de 20 % pour les tests.
Notes
Si vous choisissez l’option Fractionnement automatique du jeu de test à partir des données d’apprentissage, seules les données attribuées au jeu d’apprentissage sont fractionnées selon les pourcentages fournis.
- Utiliser un fractionnement manuel des données d’apprentissage et de test : cette méthode permet aux utilisateurs de définir quels énoncés doivent appartenir à quel jeu. Cette étape est activée uniquement si vous avez ajouté des énoncés à votre jeu de test lors de l’étiquetage.
Modes d’entraînement
CLU prend en charge deux modes d’entraînement de modèles
L’entraînement standard utilise des algorithmes de Machine Learning rapides qui permettent d’entraîner vos modèles de manière relativement rapide. Cette option n’est actuellement disponible que pour l’anglais et est désactivée pour les projets qui n’utilisent pas l’Anglais (États-Unis) ou l’Anglais (Royaume-Uni) comme langue principale. Cette option d’entraînement est gratuite. L’entraînement standard vous permet d’ajouter des énoncés et de les tester rapidement sans frais. Les scores d’évaluation affichés doivent vous guider quant aux modifications à apporter à votre projet et aux énoncés supplémentaires à ajouter. Une fois que vous avez itéré plusieurs fois et apporté des améliorations incrémentielles, vous pouvez envisager d’utiliser l’entraînement avancé pour entraîner une autre version de votre modèle.
L’entraînement avancé utilise la dernière technologie de Machine Learning pour personnaliser les modèles avec vos données. Il est censé afficher de meilleurs scores de performances pour vos modèles et vous permet aussi d’utiliser les capacités multilingues de CLU. L’entraînement avancé est facturé différemment. Pour plus d’informations, consultez les informations tarifaires.
Servez-vous des scores d’évaluation pour guider vos décisions. Il peut arriver qu’un exemple spécifique soit prédit de manière incorrecte dans l’entraînement avancé, ce qui n’était pas le cas quand vous utilisiez le mode d’entraînement standard. Cependant, si les résultats globaux de l’évaluation sont meilleurs avec le mode avancé, il est recommandé d’utiliser votre modèle final. Si ce n’est pas le cas et que vous n’envisagez pas d’utiliser de capacités multilingues, vous pouvez continuer à utiliser le modèle entraîné avec le mode standard.
Notes
Attendez-vous à voir une différence de comportement dans les scores de confiance envers les intentions entre les modes d’entraînement, car chaque algorithme étalonne leurs scores différemment.
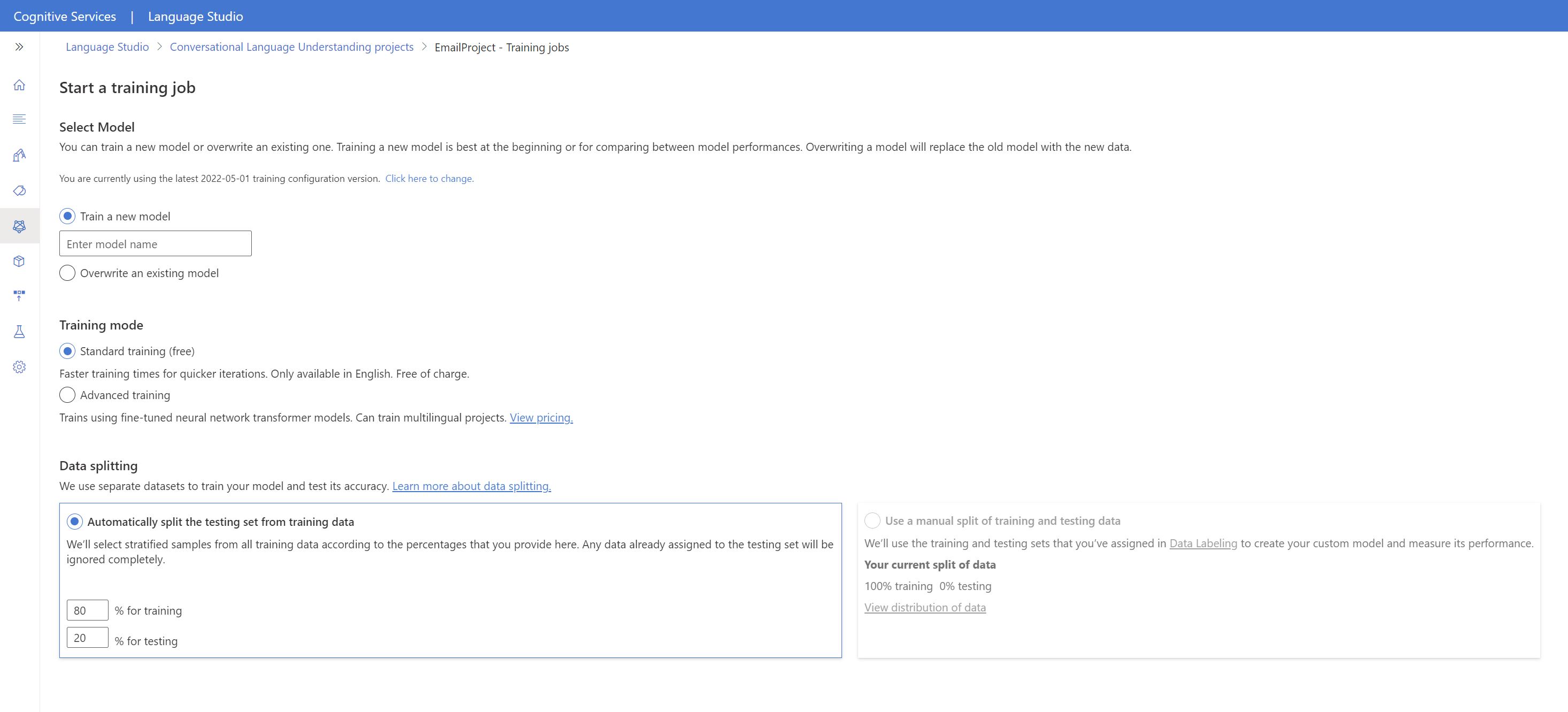
Effectuer l'apprentissage du modèle
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Effectuer l’apprentissage du modèle.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Entraîner un nouveau modèle, puis entrez le nom d’un nouveau modèle dans la zone de texte. Sinon, pour remplacer un modèle existant par un modèle entraîné sur les nouvelles données, sélectionnez Remplacer un modèle existant, puis sélectionnez un modèle existant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.
Sélectionnez le mode d’entraînement. Vous pouvez choisir l’Entraînement standard pour un entraînement plus rapide, mais il n’est disponible que pour l’anglais. Vous pouvez aussi opter pour l’Entraînement avancé, qui est pris en charge pour d’autres langues et les projets multilingues, mais les temps d’entraînement sont plus longs. Apprenez-en davantage sur les modes d’apprentissage.
Sélectionnez une méthode de fractionnement des données. Vous pouvez choisir l’option Fractionnement automatique du jeu de test à partir des données d’entraînement. Dans ce cas, le système fractionne vos énoncés en jeux d’apprentissage et de test, selon les pourcentages spécifiés. Vous pouvez aussi Utiliser un fractionnement manuel des données d’entraînement et de test. Cette option est activée uniquement si vous avez ajouté des énoncés à votre jeu de test pendant l’étiquetage de vos énoncés.
Sélectionner le bouton Train (Entraîner).
Sélectionnez l’ID du travail d’entraînement dans la liste. Un volet latéral s’affichera, dans lequel vous pourrez consulter la progression de l’entraînement, l’état du travail et d’autres détails concernant ce travail.
Notes
- Seuls les emplois de formation achevés avec succès génèrent des modèles.
- L’entraînement peut prendre entre quelques minutes et quelques heures, selon le nombre d’énoncés.
- Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas lancer d’autres travaux d’entraînement dans le même projet tant que le travail en cours d’exécution n’est pas terminé.
- Le machine learning utilisé pour entraîner les modèles est régulièrement mis à jour. Pour effectuer l’apprentissage sur une version de configuration précédente, sélectionnez Cliquez ici pour modifier à partir de la page Démarrer un travail d’apprentissage, puis choisissez une version précédente.

Annuler un travail d’apprentissage
Pour annuler un travail d’entraînement dans Language Studio
- Dans la page Entraîner un modèle, sélectionnez le travail d’entraînement à annuler, puis sélectionnez Annuler dans le menu supérieur.