Copier des données de Drill à l’aide d’Azure Data Factory ou Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Important
Ce connecteur sera déconseillé le 31 décembre 2024. Nous vous recommandons de migrer vers le connecteur ODBC en installant un pilote avant cette date.
Cet article explique comment utiliser l'activité de copie dans le pipeline Azure Data Factory ou Synapse Analytics pour copier des données de Drill. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Fonctionnalités prises en charge
Ce connecteur Drill est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | ① ② |
| Activité de recherche | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Le service fournit un pilote intégré qui permet la connexion. Vous n’avez donc pas besoin d’installer manuellement un pilote à l’aide de ce connecteur.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Drill à l’aide de l’interface utilisateur
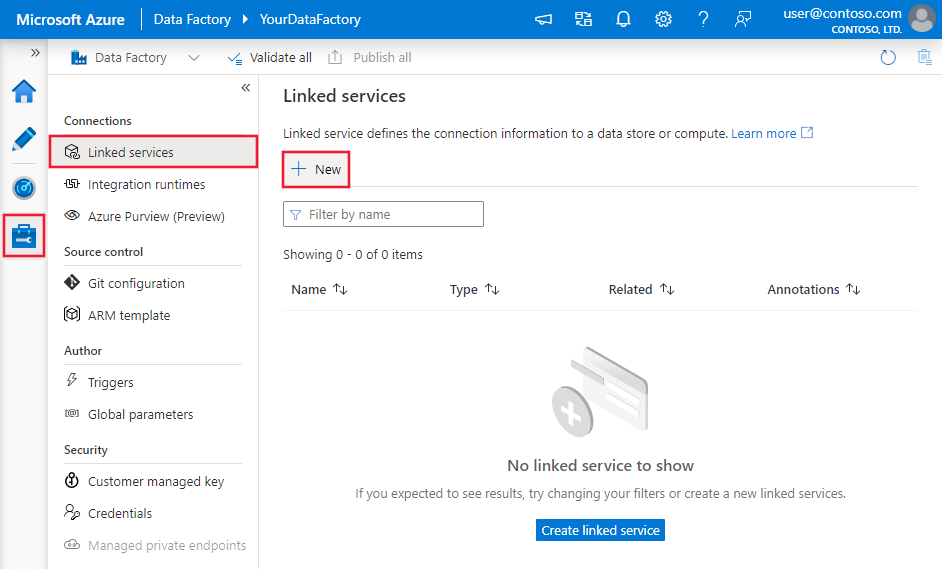
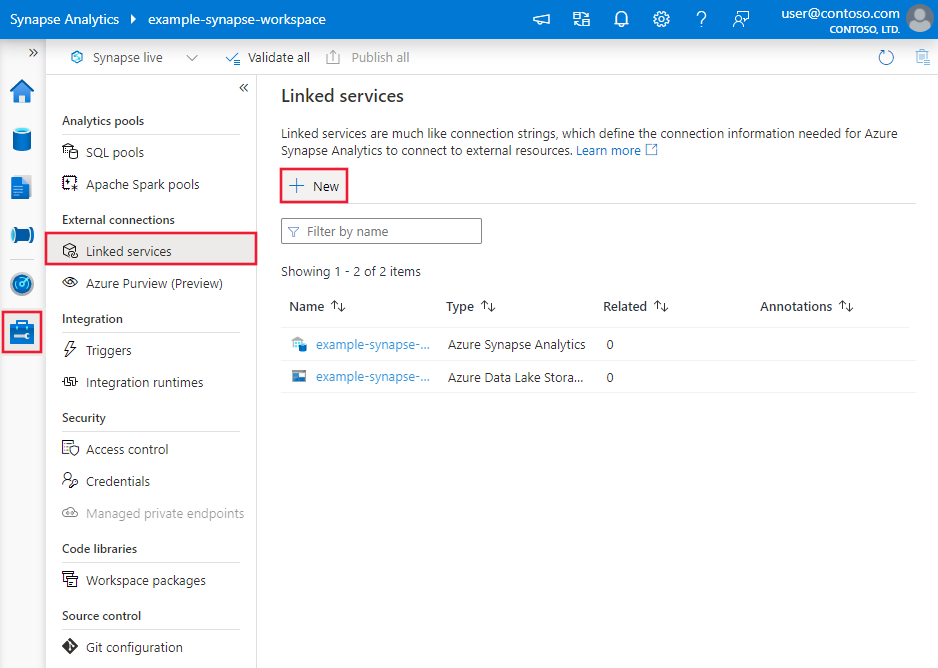
Utilisez les étapes suivantes pour créer un service lié à Drill dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Drill et sélectionnez le connecteur Drill.

Configurez les informations du service, testez la connexion et créez le nouveau service lié.

Informations de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques du connecteur Drill.
Propriétés du service lié
Les propriétés prises en charge pour le service lié Drill sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur Drill | Oui |
| connectionString | Une chaîne de connexion ODBC pour se connecter à Drill. Vous pouvez également définir un mot de passe dans Azure Key Vault et extraire la configuration pwd de la chaîne de connexion. Pour plus d’informations, reportez-vous aux exemples suivants et à l’article Stocker des informations d’identification dans Azure Key Vault. |
Oui |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "DrillLinkedService",
"properties": {
"type": "Drill",
"typeProperties": {
"connectionString": "ConnectionType=Direct;Host=<host>;Port=<port>;AuthenticationType=Plain;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : stockage du mot de passe dans Azure Key Vault
{
"name": "DrillLinkedService",
"properties": {
"type": "Drill",
"typeProperties": {
"connectionString": "ConnectionType=Direct;Host=<host>;Port=<port>;AuthenticationType=Plain;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Drill.
Pour copier des données depuis Drill, attribuez la valeur DrillTable à la propriété type du jeu de données. Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur DrillTable | Oui |
| schéma | Nom du schéma. | Non (si « query » dans la source de l’activité est spécifié) |
| table | Nom de la table. | Non (si « query » dans la source de l’activité est spécifié) |
| tableName | Nom de la table avec le schéma. Cette propriété est prise en charge pour la compatibilité descendante. Utilisez schema et table pour une nouvelle charge de travail. |
Non (si « query » dans la source de l’activité est spécifié) |
Exemple
{
"name": "DrillDataset",
"properties": {
"type": "DrillTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Drill linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source Drill.
DrillSource en tant que source
Pour copier des données de Drill, définissez le type de source dans l’activité de copie sur DrillSource. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur DrillSource | Oui |
| query | Utiliser la requête SQL personnalisée pour lire les données. Par exemple : "SELECT * FROM MyTable". |
Non (si « tableName » est spécifié dans dataset) |
Exemple :
"activities":[
{
"name": "CopyFromDrill",
"type": "Copy",
"inputs": [
{
"referenceName": "<Drill input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DrillSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Contenu connexe
Pour obtenir une liste des magasins de données pris en charge comme sources et récepteurs par l’activité de copie, consultez la section sur les magasins de données pris en charge.