Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce guide de démarrage rapide, vous utilisez l’outil Copier des données dans Azure Data Factory Studio pour créer un pipeline qui copie les données d’un dossier source dans Stockage Blob Azure vers un dossier cible.
Prérequis
Abonnement Azure
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Préparer les données sources dans le Stockage Blob Azure
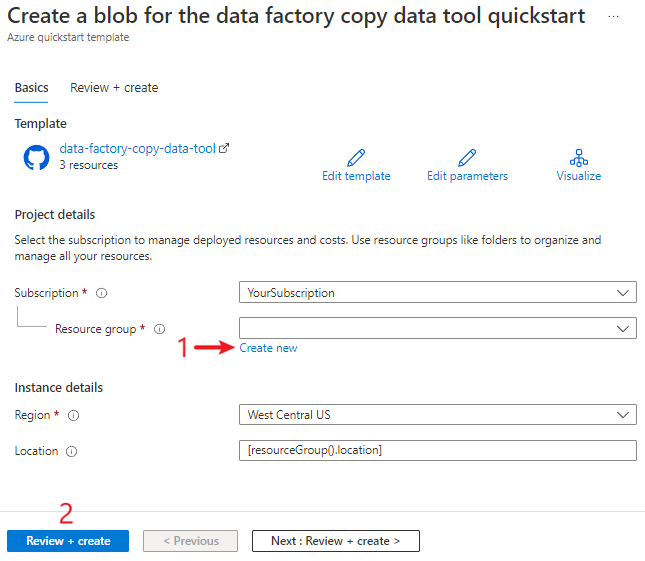
Pour préparer des données sources à l’aide d’un modèle :
Sélectionnez le bouton suivant.

Vous êtes dirigé vers la page de configuration pour déployer le modèle. Sur cette page :
Pour le groupe de ressources, sélectionnez Créer nouveau pour créer un groupe de ressources. Vous pouvez conserver toutes les autres valeurs avec leurs valeurs par défaut.
Sélectionnez Vérifier + créer, puis créer pour déployer les ressources.
Remarque
L’utilisateur qui déploie le modèle doit attribuer un rôle à une identité managée. Cette étape nécessite des autorisations qui peuvent être accordées via le rôle Propriétaire, Administrateur de l’accès utilisateur ou Opérateur d’identité managée.
Un nouveau compte Stockage Blob est créé dans le nouveau groupe de ressources. Le fichier moviesDB2.csv est stocké dans un dossier appelé entrée dans le Stockage Blob.
Créer une fabrique de données
Vous pouvez utiliser votre fabrique de données existante ou en créer une nouvelle comme décrit dans le guide de démarrage rapide : Créer une fabrique de données.
Utiliser l’outil Copier des données pour copier des données
L’outil Copier des données comporte cinq pages qui vous guident tout au long de la tâche de copie de données. Pour démarrer l’outil :
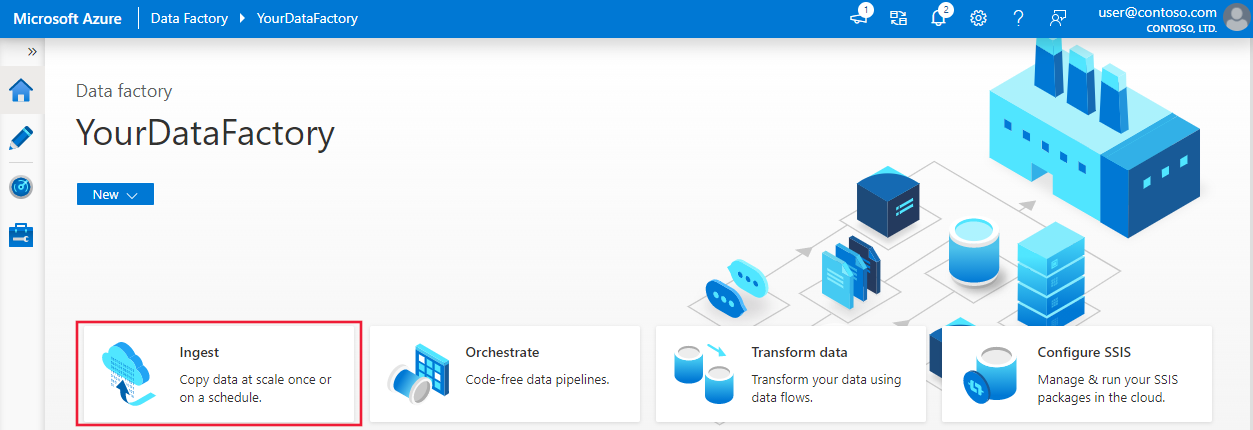
Dans Azure Data Factory Studio, accédez à votre fabrique de données.
Sélectionnez la vignette Ingérer .
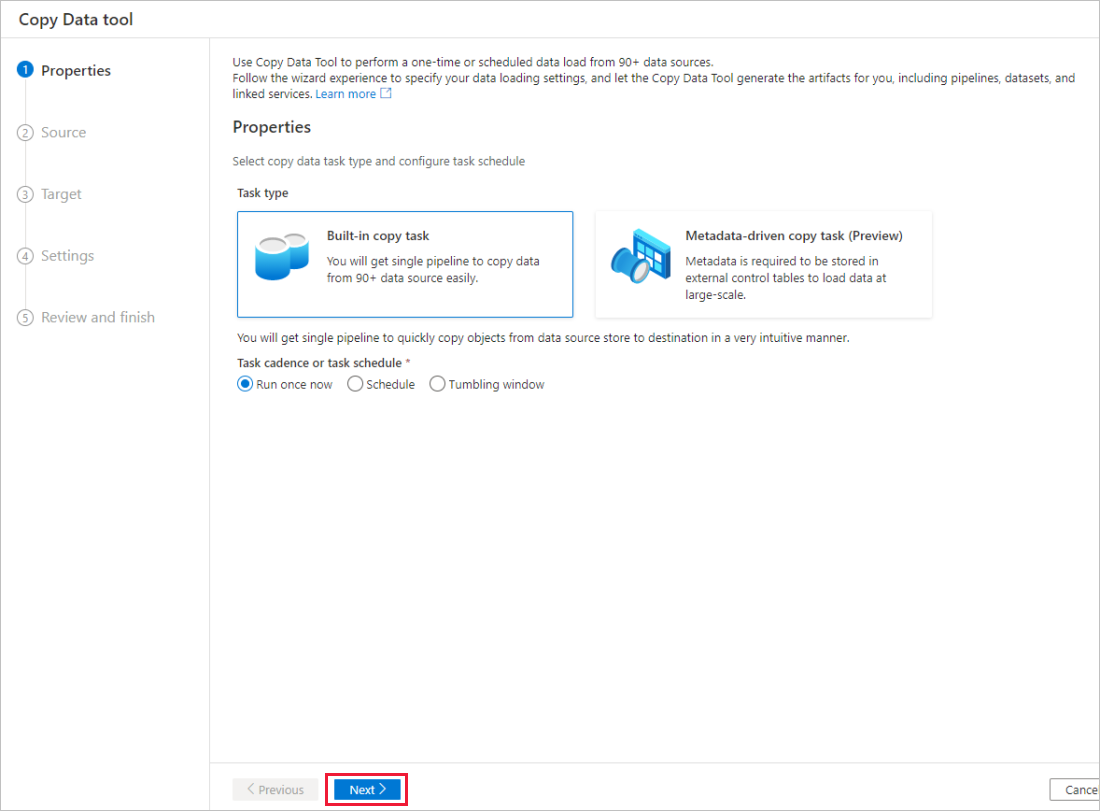
Étape 1 : Sélectionner le type de tâche
Dans la page Propriétés de l’outil Copier des données, choisissez tâche de copie intégrée sous Type de tâche.
Cliquez sur Suivant.
Étape 2 : Configurer la source
Dans la page Source de l’outil Copier des données, sélectionnez + Créer une connexion pour ajouter une connexion.
Sélectionnez le type de service lié à créer pour la connexion source. (L’exemple de ce guide de démarrage rapide utilise Stockage Blob Azure.) Ensuite, sélectionnez Continuer.

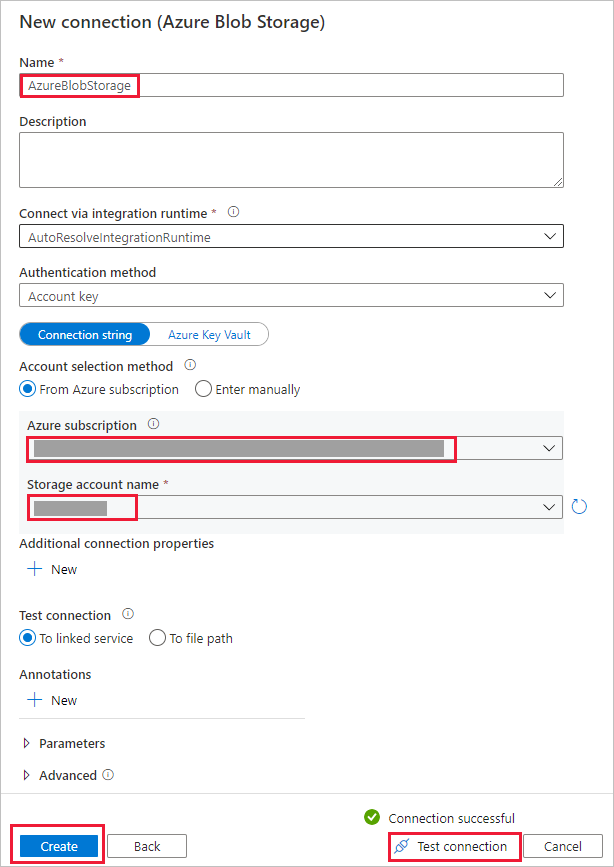
Dans la boîte de dialogue Nouvelle connexion (Stockage Blob Azure) :
- Pour Nom, spécifiez un nom pour votre connexion.
- Sous Méthode de sélection de compte, sélectionnez À partir d’un abonnement Azure.
- Dans la liste des abonnements Azure , sélectionnez votre abonnement Azure.
- Dans la liste des noms du compte de stockage , sélectionnez votre compte de stockage.
- Sélectionnez Tester la connexion et vérifiez que la connexion réussit.
- Cliquez sur Créer.
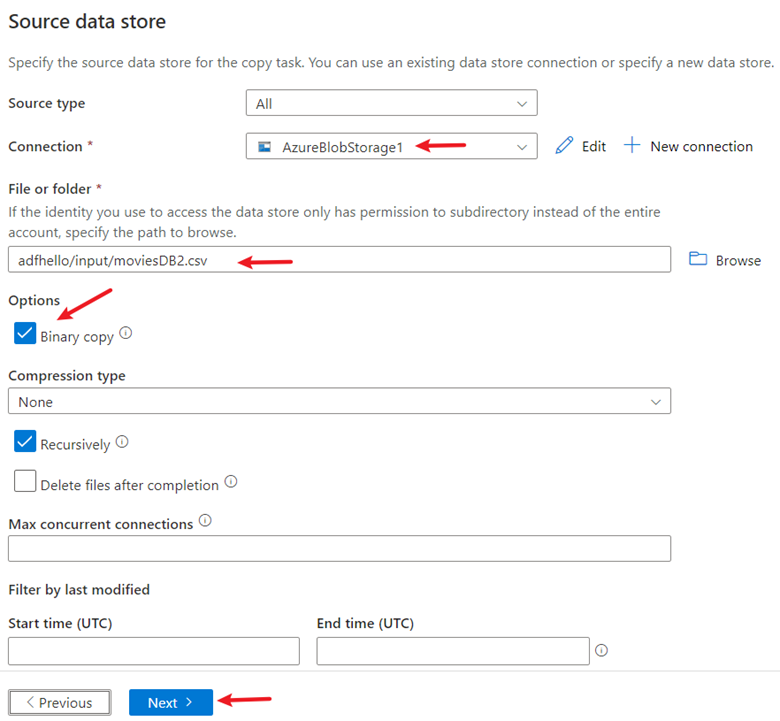
Sous Stockage des données source :
- Pour Connexion, sélectionnez la connexion nouvellement créée.
- Dans la section Fichier ou dossier , sélectionnez Parcourir pour accéder au dossier adftutorial/input . Sélectionnez le fichier moviesDB2.csv , puis sélectionnez OK.
- Cochez la case Copier binaire pour copier le fichier tel qu’il se trouve.
- Cliquez sur Suivant.
Étape 3 : Configurer la destination
Dans la page Cible de l’outil Copier des données, pour Connexion, sélectionnez la connexion AzureBlobStorage que vous avez créée.
Dans la section Chemin du dossier, entrez adftutorial/output.
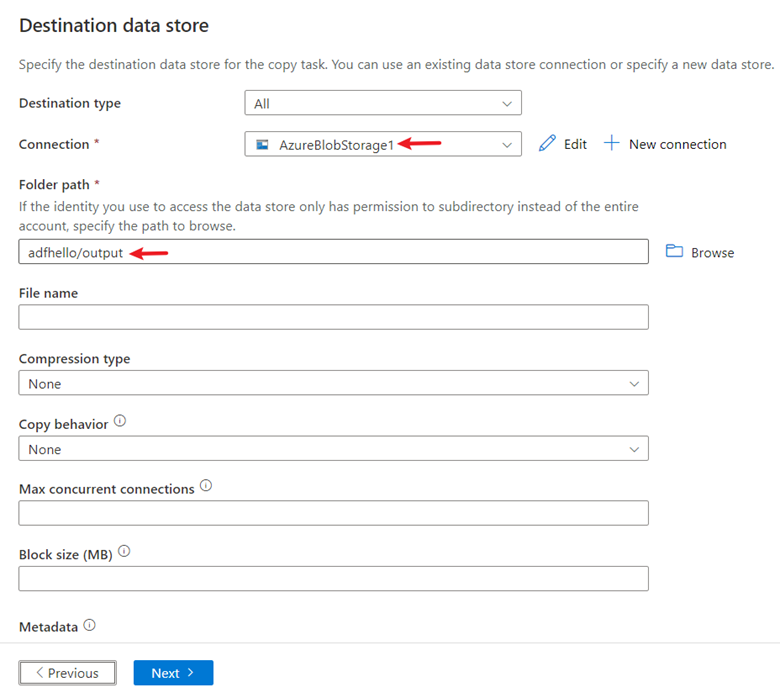
Laissez les autres paramètres par défaut. Cliquez sur Suivant.
Étape 4 : Entrer un nom et une description pour le pipeline
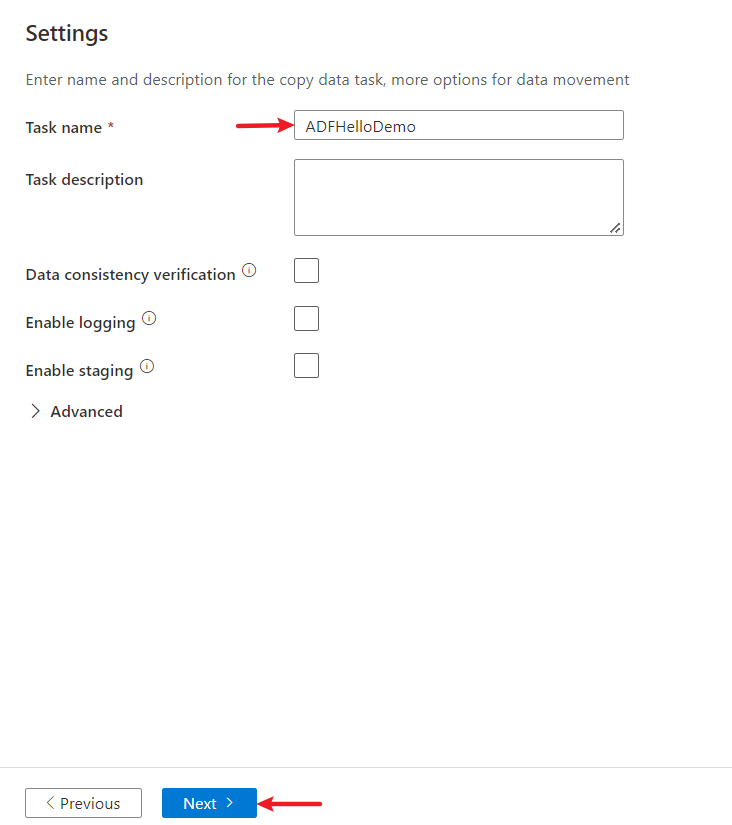
Dans la page Paramètres de l’outil Copier des données, spécifiez un nom pour le pipeline et sa description.
Sélectionnez Suivant pour utiliser d’autres configurations par défaut.
Étape 5 : Passer en revue les paramètres et déployer
Dans la page Révision et fin , passez en revue tous les paramètres.
Cliquez sur Suivant.
La page Déploiement complète indique si le déploiement réussit.
Surveiller les résultats en cours d’exécution
Une fois que vous avez terminé de copier les données, vous pouvez surveiller le pipeline que vous avez créé :
Dans la page Déploiement terminée , sélectionnez Surveiller.
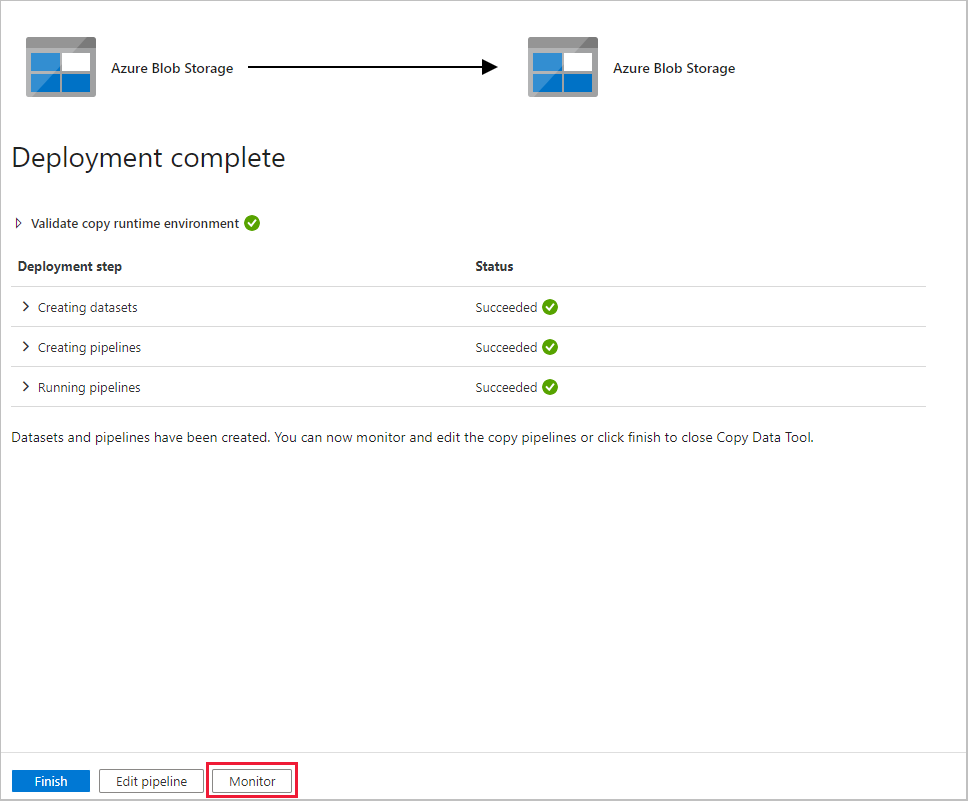
L’application bascule vers l’onglet Moniteur , qui affiche l’état du pipeline. Sélectionnez Actualiser pour actualiser la liste des pipelines. Sélectionnez le lien sous Nom du pipeline pour afficher les détails de l’exécution de l’activité ou réexécuter le pipeline.
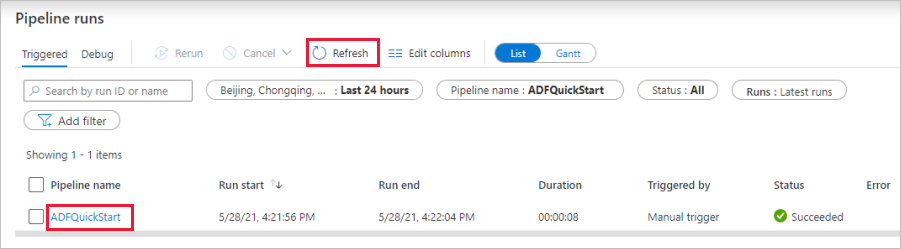
Dans la page qui affiche les détails de l’exécution de l’activité, sélectionnez le lien Détails (icône De lunettes) dans la colonne Nom de l’activité pour plus d’informations sur l’opération de copie. Pour plus d’informations sur les propriétés, consultez l’article de vue d’ensemble sur l’activité de copie.
Contenu connexe
Le pipeline de cet exemple copie les données d’un emplacement vers un autre emplacement dans le stockage Blob Azure. Pour en savoir plus sur l’utilisation de Data Factory dans d’autres scénarios, consultez le tutoriel suivant :