Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Important
La mise à l’échelle automatique Lakebase est en version bêta dans les régions suivantes : eastus2, westeurope, westus.
Lakebase Autoscaling est la dernière version de Lakebase avec calcul à mise à l’échelle automatique, mise à l’échelle jusqu'à zéro, création de branches, et restauration instantanée. Pour la comparaison des fonctionnalités avec Lakebase Provisioned, consultez le choix entre les versions.
Ce guide montre comment connecter des applications externes à la mise à l’échelle automatique Lakebase à l’aide de pilotes Postgres standard (psycopg, pgx, JDBC) avec la rotation des jetons OAuth. Vous utilisez le Kit de développement logiciel (SDK) Azure Databricks avec un principal de service et un pool de connexions qui appelle generate_database_credential() lors de l’ouverture de chaque nouvelle connexion. Vous obtenez donc un nouveau jeton (durée de vie de 60 minutes) chaque fois que vous vous connectez. Des exemples sont fournis pour Python, Java et Go. Pour faciliter la configuration avec la gestion automatique des informations d’identification, envisagez plutôt Azure Databricks Apps .
Ce que vous allez générer : Modèle de connexion qui utilise la rotation des jetons OAuth pour se connecter à la mise à l’échelle automatique Lakebase à partir d’une application externe, puis vérifiez que la connexion fonctionne.
Vous avez besoin du Kit de développement logiciel (SDK) Databricks (Python v0.89.0+, Java v0.73.0+ ou Go v0.109.0+). Exécutez les étapes suivantes dans l'ordre :
:::tip Autres langues Pour les langues sans support SDK Databricks (Node.js, Ruby, PHP, Elixir, Rust, etc.), voir Connecter une application externe à Lakebase en utilisant l'API. :::
Note
Étendue des jetons : Les jetons d’informations d’identification de base de données sont délimités à l’espace de travail. Pendant que le endpoint paramètre est requis, le jeton retourné peut accéder à n’importe quelle base de données ou projet dans l’espace de travail pour lequel le principal de service dispose des autorisations nécessaires.
Fonctionnement
Le Kit de développement logiciel (SDK) Databricks simplifie l’authentification OAuth en gérant automatiquement la gestion des jetons d’espace de travail :
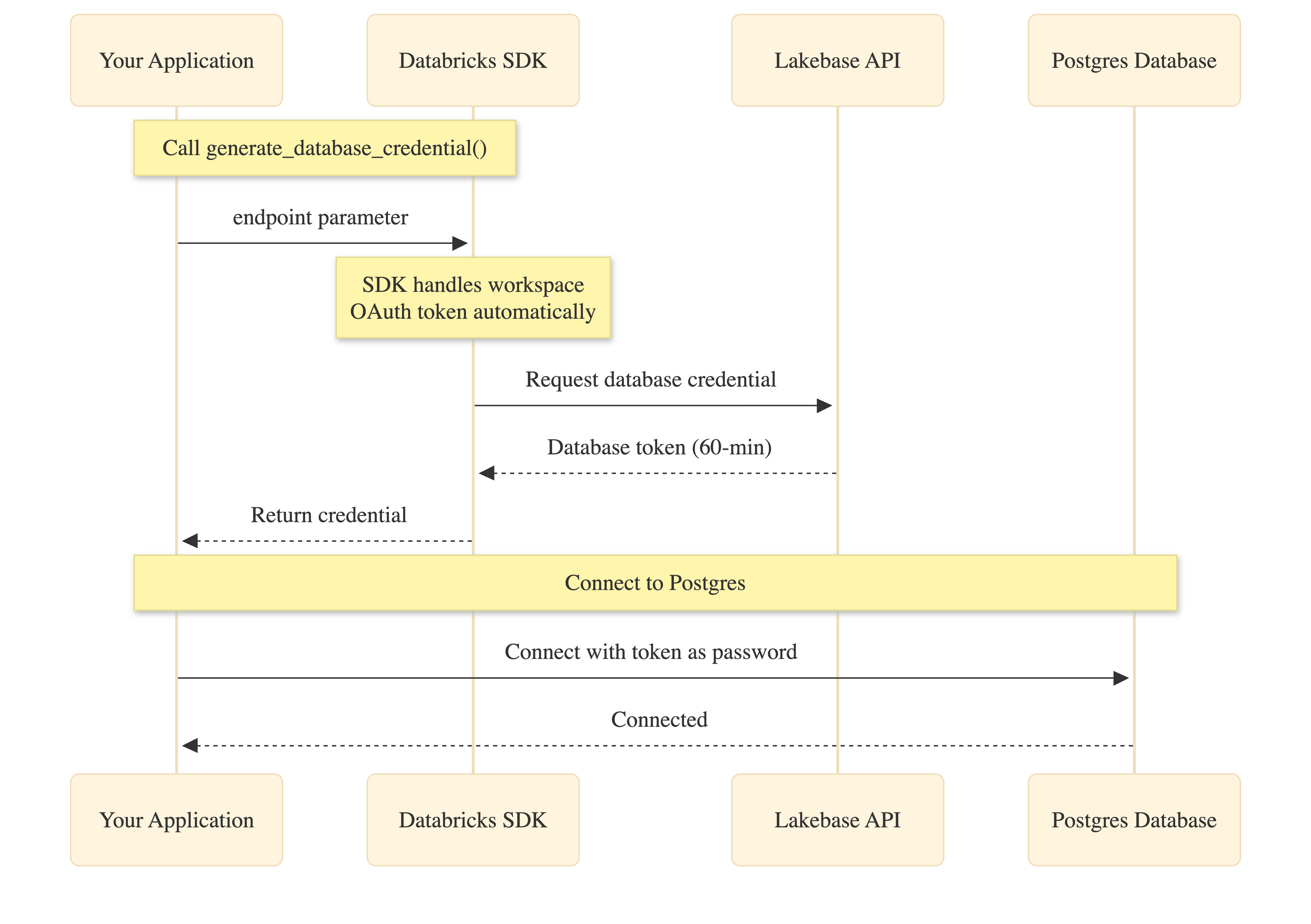
Votre application appelle generate_database_credential() avec le paramètre de point de terminaison. Le Kit de développement logiciel (SDK) obtient le jeton OAuth de l’espace de travail en interne (aucun code nécessaire), demande les informations d’identification de la base de données à partir de l’API Lakebase et le retourne à votre application. Vous utilisez ensuite ces informations d’identification comme mot de passe lors de la connexion à Postgres.
Le jeton OAuth de l’espace de travail et les informations d’identification de base de données expirent après 60 minutes. Les pools de connexions gèrent l’actualisation automatique en appelant generate_database_credential() lors de la création de connexions.
1. Créer un principal de service avec un secret OAuth
Créez un principal de service Azure Databricks avec un secret OAuth. Les détails complets sont dans Autoriser l’accès au principal du service. Pour créer une application externe, gardez à l’esprit :
- Configurez la durée de vie de votre secret à la durée que vous préférez, jusqu’à 730 jours. Cela définit la fréquence à laquelle vous devez actualiser le secret, qui est utilisé pour générer des informations d’identification de base de données via la rotation.
-
Activez « Accès à l’espace de travail » pour le principal de service (Paramètres → Identité et accès → principaux de service →
{name}onglet Configurations →). Il est nécessaire de générer de nouveaux identifiants de base de données. -
Notez l’ID client (un UUID). Vous l’utilisez lors de la création du rôle Postgres correspondant dans la configuration de votre application et pour
PGUSER.
2. Créer un rôle Postgres pour le principal de service
L’interface utilisateur Lakebase prend uniquement en charge les rôles basés sur un mot de passe. Créez un rôle OAuth dans l’éditeur SQL Lakebase à l’aide de l’ID client de l’étape 1 (et non le nom d'affichage ; le nom du rôle est sensible à la casse) :
-- Enable the auth extension (if not already enabled)
CREATE EXTENSION IF NOT EXISTS databricks_auth;
-- Create OAuth role using the service principal client ID
SELECT databricks_create_role('{client-id}', 'SERVICE_PRINCIPAL');
-- Grant database permissions
GRANT CONNECT ON DATABASE databricks_postgres TO "{client-id}";
GRANT USAGE ON SCHEMA public TO "{client-id}";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "{client-id}";
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "{client-id}";
Remplacez {client-id} par votre ID client du principal de service. Consultez Créer des rôles OAuth.
3. Obtenir les détails de la connexion
À partir de votre projet dans la console Lakebase, cliquez sur Se connecter, sélectionnez la branche et le point de terminaison, puis notez l’hôte, la base de données (généralement databricks_postgres) et le nom du point de terminaison (format : projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>).
Vous pouvez également utiliser l’interface CLI :
databricks postgres list-endpoints projects/<project-id>/branches/<branch-id>
Voir les chaînes de connexion pour plus de détails.
4. Définir des variables d’environnement
Définissez ces variables d’environnement avant d’exécuter votre application :
# Databricks workspace authentication
export DATABRICKS_HOST="https://your-workspace.databricks.com"
export DATABRICKS_CLIENT_ID="<service-principal-client-id>"
export DATABRICKS_CLIENT_SECRET="<your-oauth-secret>"
# Lakebase connection details (from step 3)
export ENDPOINT_NAME="projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>"
export PGHOST="<endpoint-id>.database.<region>.databricks.com"
export PGDATABASE="databricks_postgres"
export PGUSER="<service-principal-client-id>" # Same UUID as step 1
export PGPORT="5432"
export PGSSLMODE="require" # Python only
5. Ajouter du code de connexion
Python
Cet exemple utilise psycopg3 avec une classe de connexion personnalisée qui génère un nouveau jeton lorsque le pool crée chaque nouvelle connexion.
import os
from databricks.sdk import WorkspaceClient
import psycopg
from psycopg_pool import ConnectionPool
# Initialize Databricks SDK
workspace_client = None
def _get_workspace_client():
"""Get or create the workspace client for OAuth."""
global workspace_client
if workspace_client is None:
workspace_client = WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
client_id=os.environ["DATABRICKS_CLIENT_ID"],
client_secret=os.environ["DATABRICKS_CLIENT_SECRET"],
)
return workspace_client
def _get_endpoint_name():
"""Get endpoint name from environment."""
name = os.environ.get("ENDPOINT_NAME")
if not name:
raise ValueError(
"ENDPOINT_NAME must be set (format: projects/<id>/branches/<id>/endpoints/<id>)"
)
return name
class OAuthConnection(psycopg.Connection):
"""Custom connection class that generates a fresh OAuth token per connection."""
@classmethod
def connect(cls, conninfo="", **kwargs):
endpoint_name = _get_endpoint_name()
client = _get_workspace_client()
# Generate database credential (tokens are workspace-scoped)
credential = client.postgres.generate_database_credential(
endpoint=endpoint_name
)
kwargs["password"] = credential.token
return super().connect(conninfo, **kwargs)
# Create connection pool with OAuth token rotation
def get_connection_pool():
"""Get or create the connection pool."""
database = os.environ["PGDATABASE"]
user = os.environ["PGUSER"]
host = os.environ["PGHOST"]
port = os.environ.get("PGPORT", "5432")
sslmode = os.environ.get("PGSSLMODE", "require")
conninfo = f"dbname={database} user={user} host={host} port={port} sslmode={sslmode}"
return ConnectionPool(
conninfo=conninfo,
connection_class=OAuthConnection,
min_size=1,
max_size=10,
open=True,
)
# Use the pool in your application
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Dépendances :databricks-sdk>=0.89.0, psycopg[binary,pool]>=3.1.0
Go
Cet exemple utilise pgxpool avec un rappel BeforeConnect qui génère un nouveau jeton pour chaque nouvelle connexion.
package main
import (
"context"
"fmt"
"log"
"os"
"time"
"github.com/databricks/databricks-sdk-go"
"github.com/databricks/databricks-sdk-go/service/postgres"
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgxpool"
)
func createConnectionPool(ctx context.Context) (*pgxpool.Pool, error) {
// Initialize Databricks workspace client
w, err := databricks.NewWorkspaceClient(&databricks.Config{
Host: os.Getenv("DATABRICKS_HOST"),
ClientID: os.Getenv("DATABRICKS_CLIENT_ID"),
ClientSecret: os.Getenv("DATABRICKS_CLIENT_SECRET"),
})
if err != nil {
return nil, err
}
// Build connection string
connStr := fmt.Sprintf("host=%s port=%s dbname=%s user=%s sslmode=require",
os.Getenv("PGHOST"),
os.Getenv("PGPORT"),
os.Getenv("PGDATABASE"),
os.Getenv("PGUSER"))
config, err := pgxpool.ParseConfig(connStr)
if err != nil {
return nil, err
}
// Configure pool
config.MaxConns = 10
config.MinConns = 1
config.MaxConnLifetime = 45 * time.Minute
config.MaxConnIdleTime = 15 * time.Minute
// Generate fresh token for each new connection
config.BeforeConnect = func(ctx context.Context, connConfig *pgx.ConnConfig) error {
credential, err := w.Postgres.GenerateDatabaseCredential(ctx,
postgres.GenerateDatabaseCredentialRequest{
Endpoint: os.Getenv("ENDPOINT_NAME"),
})
if err != nil {
return err
}
connConfig.Password = credential.Token
return nil
}
return pgxpool.NewWithConfig(ctx, config)
}
func main() {
ctx := context.Background()
pool, err := createConnectionPool(ctx)
if err != nil {
log.Fatal(err)
}
defer pool.Close()
var user, database string
err = pool.QueryRow(ctx, "SELECT current_user, current_database()").Scan(&user, &database)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Connected as: %s to database: %s\n", user, database)
}
Dépendances: Kit de développement logiciel (SDK) Databricks pour Go v0.109.0 + (github.com/databricks/databricks-sdk-go), pilote pgx (github.com/jackc/pgx/v5)
Note: Le BeforeConnect rappel garantit de nouveaux jetons OAuth pour chaque nouvelle connexion, en gérant la rotation automatique des jetons pour les applications de longue durée.
Java
Cet exemple utilise JDBC avec HikariCP et une Source de données personnalisée qui génère un nouveau jeton lorsque le pool crée chaque nouvelle connexion.
import java.sql.*;
import javax.sql.DataSource;
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.core.DatabricksConfig;
import com.databricks.sdk.service.postgres.*;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class LakebaseConnection {
private static WorkspaceClient workspaceClient() {
String host = System.getenv("DATABRICKS_HOST");
String clientId = System.getenv("DATABRICKS_CLIENT_ID");
String clientSecret = System.getenv("DATABRICKS_CLIENT_SECRET");
return new WorkspaceClient(new DatabricksConfig()
.setHost(host)
.setClientId(clientId)
.setClientSecret(clientSecret));
}
private static DataSource createDataSource() {
WorkspaceClient w = workspaceClient();
String endpointName = System.getenv("ENDPOINT_NAME");
String host = System.getenv("PGHOST");
String database = System.getenv("PGDATABASE");
String user = System.getenv("PGUSER");
String port = System.getenv().getOrDefault("PGPORT", "5432");
String jdbcUrl = "jdbc:postgresql://" + host + ":" + port +
"/" + database + "?sslmode=require";
// DataSource that returns a new connection with a fresh token (tokens are workspace-scoped)
DataSource tokenDataSource = new DataSource() {
@Override
public Connection getConnection() throws SQLException {
DatabaseCredential cred = w.postgres().generateDatabaseCredential(
new GenerateDatabaseCredentialRequest().setEndpoint(endpointName)
);
return DriverManager.getConnection(jdbcUrl, user, cred.getToken());
}
@Override
public Connection getConnection(String u, String p) {
throw new UnsupportedOperationException();
}
// ... other DataSource methods (getLogWriter, etc.)
};
// Wrap in HikariCP for connection pooling
HikariConfig config = new HikariConfig();
config.setDataSource(tokenDataSource);
config.setMaximumPoolSize(10);
config.setMinimumIdle(1);
// Recycle connections before 60-min token expiry
config.setMaxLifetime(45 * 60 * 1000L);
return new HikariDataSource(config);
}
public static void main(String[] args) throws SQLException {
DataSource pool = createDataSource();
try (Connection conn = pool.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT current_user, current_database()")) {
if (rs.next()) {
System.out.println("User: " + rs.getString(1));
System.out.println("Database: " + rs.getString(2));
}
}
}
}
Dépendances: Kit de développement logiciel (SDK) Databricks pour Java v0.73.0 (com.databricks:databricks-sdk-java), pilote JDBC PostgreSQL (org.postgresql:postgresql), HikariCP (com.zaxxer:HikariCP)
6. Exécuter et vérifier la connexion
Python
Installer les dépendances :
pip install databricks-sdk psycopg[binary,pool]
Exécuter:
# Save all the code from step 5 (above) as db.py, then run:
from db import get_connection_pool
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Sortie attendue :
('c00f575e-d706-4f6b-b62c-e7a14850571b', 'databricks_postgres')
Si current_user correspond à l'ID client de votre principal de service de l'étape 1, la rotation des jetons OAuth fonctionne.
Java
Note: Cela suppose que vous disposez d’un projet Maven avec les dépendances de l’exemple Java ci-dessus dans votre pom.xml.
Installer les dépendances :
mvn install
Exécuter:
mvn exec:java -Dexec.mainClass="com.example.LakebaseConnection"
Sortie attendue :
User: c00f575e-d706-4f6b-b62c-e7a14850571b
Database: databricks_postgres
Si l’utilisateur correspond à votre ID client du principal de service de l’étape 1, la rotation des jetons OAuth fonctionne.
Go
Installer les dépendances :
go mod init myapp
go get github.com/databricks/databricks-sdk-go
go get github.com/jackc/pgx/v5
Exécuter:
go run main.go
Sortie attendue :
Connected as: c00f575e-d706-4f6b-b62c-e7a14850571b to database: databricks_postgres
Si l’utilisateur correspond à votre ID client du principal de service de l’étape 1, la rotation des jetons OAuth fonctionne.
Note : La première connexion après une période d'inactivité peut être plus longue car le système de mise à l'échelle automatique de Lakebase initie le calcul à partir de zéro.
Résolution des problèmes
| Erreur | Réparer |
|---|---|
| « L’API est désactivée pour les utilisateurs sans droit d’accès à l’espace de travail » | Activez « Accès à l’espace de travail » pour le principal de service (étape 1). |
| « Le rôle n’existe pas » ou l’authentification échoue | Créez le rôle OAuth via SQL (étape 2), et non l’interface utilisateur. |
| « Connexion refusée » ou « Point de terminaison introuvable » | Utilisez le format ENDPOINT_NAMEprojects/<id>/branches/<id>/endpoints/<id>. L'ID du point de terminaison se trouve dans l'hôte. |
| « Utilisateur non valide » ou « Utilisateur introuvable » | Définissez PGUSER sur l’ID client du principal de service (UUID), et non sur le nom d’affichage. |