Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Important
La mise à l’échelle automatique Lakebase est en version bêta dans les régions suivantes : eastus2, westeurope, westus.
Lakebase Autoscaling est la dernière version de Lakebase avec la mise à l’échelle automatique, la mise à l’échelle jusqu'à zéro, le branchement, et la restauration instantanée. Pour la comparaison des fonctionnalités avec Lakebase Provisioned, consultez le choix entre les versions.
Un projet est le conteneur de niveau supérieur pour vos ressources Lakebase, notamment les branches, les calculs, les bases de données et les rôles. Cette page explique comment créer des projets, comprendre leur structure, configurer des paramètres et gérer leur cycle de vie.
Si vous débutez avec Lakebase, commencez par commencer à créer votre premier projet.
Présentation des projets
Structure du projet
Comprendre la structure du projet Lakebase vous aide à organiser et à gérer efficacement vos ressources. Un projet est le conteneur de niveau supérieur pour vos bases de données, branches, calculs et ressources associées. Chaque projet inclut des paramètres pour les valeurs par défaut de calcul, la restauration des fenêtres et les mises à jour qui s’appliquent à toutes les branches du projet.
Au niveau supérieur, un projet contient une ou plusieurs branches. Dans un projet, vous pouvez créer des branches pour différents environnements tels que le développement, le test, la préproduction et la production. Chaque branche contient ses propres calculs, rôles et bases de données.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Branches
Les données résident dans des branches. Chaque projet Lakebase est créé avec une branche racine appelée production, qui ne peut pas être supprimée. Bien que vous puissiez créer des branches supplémentaires et désigner une autre branche comme branche par défaut, la branche racine ne peut pas être supprimée.
Vous pouvez créer des branches enfants à partir de n’importe quelle branche de votre projet. Lorsque vous créez une branche enfant, elle hérite de toutes les bases de données, rôles et données de sa branche parente au moment de la création. Les modifications suivantes dans la branche parente ne se propagent pas automatiquement à la branche enfant, ce qui permet le développement isolé, les tests ou l’expérience.
Chaque branche peut contenir plusieurs bases de données et rôles. En savoir plus : Gérer les branches
Calcule
Un calcul est une ressource de calcul virtualisée qui inclut des processeurs virtuels et de la mémoire pour l’exécution de Postgres. Lorsque vous créez un projet, un calcul R/W principal (en lecture-écriture) est créé pour la branche par défaut du projet. Chaque branche a une seule unité de calcul R/W principale. Pour vous connecter à une base de données qui réside sur une branche, vous devez vous connecter via le calcul R/W associé à la branche.
Outre le calcul principal de lecture/écriture (R/W), vous pouvez ajouter un ou plusieurs calculs de réplique en lecture seule pour n'importe quelle branche. Les réplicas en lecture vous permettent de décharger des charges de travail en lecture seule de votre instance principale pour des cas d’utilisation tels que la scalabilité horizontale en lecture, les requêtes de création de rapports et d’analyse, et l’accès en lecture seule pour les utilisateurs ou les applications. En savoir plus : Gérer les calculs, réplicas de lecture
Rôles
Les rôles sont des rôles PostgreSQL. Un rôle est requis pour créer et accéder à une base de données. Un rôle appartient à une branche. Lorsque vous créez un projet, un rôle Postgres est automatiquement créé pour votre identité Databricks (par exemple), user@databricks.comqui est le propriétaire de la base de données par défaut databricks_postgres . Tout rôle créé dans l’interface utilisateur Lakebase est créé avec databricks_superuser des privilèges. Il existe une limite de 500 rôles par branche. En savoir plus : Gérer les rôles
Bases de données
Une base de données est un conteneur pour les objets SQL tels que les schémas, les tables, les vues, les fonctions et les index. Dans Lakebase, une base de données appartient à une branche. La branche par défaut de votre projet est créée avec une base de données nommée databricks_postgres. Il existe une limite de 500 bases de données par branche. En savoir plus : Gérer les bases de données
Schémas
Toutes les bases de données de Lakebase sont créées avec un public schéma, qui est le comportement par défaut pour n’importe quelle instance Postgres standard. Les objets SQL sont créés dans le public schéma par défaut.
Limites du projet
Lakebase Postgres applique les limites suivantes pour les projets :
| Resource | Limit |
|---|---|
| Nombre maximal de calculs actifs simultanément | 20 |
| Nombre maximal de branches par projet | 500 |
| Nombre maximal de rôles Postgres par branche | 500 |
| Nombre maximal de bases de données Postgres par branche | 500 |
| Taille maximale des données logiques par branche | 8 To |
| Nombre maximal de projets par espace de travail | 1 000 |
| Nombre maximal de branches protégées | 1 |
| Nombre maximal de branches racines | 3 |
| Nombre maximal de branches nonarchivées | 10 |
| Nombre maximal d’instantanés | 10 |
| Période de rétention maximale de l’historique | 35 jours |
| Échelle minimale à zéro instant | 60 secondes |
Limite de charges de calcul actives simultanément
La limite de calcul active simultanément limite le nombre de calculs pouvant s’exécuter en même temps pour empêcher l’épuisement des ressources. Cette limite protège contre les augmentations accidentelles de ressources, telles que le démarrage de nombreux points de terminaison de calcul à la fois. La limite par défaut est de 20 calculs actifs simultanément par projet.
Important: La branche par défaut est exemptée de cette limite, ce qui garantit qu’elle reste disponible à tout moment.
Lorsque vous dépassez la limite, des calculs supplémentaires au-delà de la limite restent suspendus et une erreur s’affiche lors de la tentative de connexion. Pour résoudre ce problème :
- Suspendez d’autres calculs actifs et réessayez.
- Si vous rencontrez souvent cette erreur, contactez le support Databricks pour demander une augmentation de limite.
Note
Les calculs avec mise à l’échelle à zéro sont automatiquement suspendus après une période d’inactivité, ce qui vous permet de rester dans la limite de calcul active simultanément.
Availability
Disponibilité du cloud et de la région
La mise à l’échelle automatique de Lakebase Postgres est disponible sur AWS et Azure.
Régions AWS :
-
us-east-1(USA Est - N. Virginie) -
us-east-2(USA Est - Ohio) -
eu-central-1(Europe - Francfort) -
eu-west-1(Europe - Irlande) -
eu-west-2(Europe - Londres) -
ap-south-1(Asie-Pacifique - Mumbai) -
ap-southeast-1(Asie-Pacifique - Singapour) -
ap-southeast-2(Asie-Pacifique - Sydney)
Régions Azure (bêta) :
-
eastus2(l'Est des USA 2) -
westeurope(Europe Ouest) -
westus(USA Ouest)
Votre projet Lakebase est créé dans votre région d’espace de travail Databricks.
Prise en charge des versions de Postgres
La mise à l’échelle automatique De Lakebase Postgres prend en charge Postgres 16 et Postgres 17.
Créer et gérer des projets
Créer un projet
Vous pouvez créer plusieurs projets dans Lakebase Postgres pour maintenir les applications ou les clients entièrement isolés, ce qui garantit une séparation propre des données et des ressources.
Pour créer un projet :
IU
- Cliquez sur le sélecteur d’applications dans le coin supérieur droit pour ouvrir l’application Lakebase.
- Cliquez sur Nouveau projet.
- Configurez les paramètres de votre projet :
-
Nom du projet : entrez un nom descriptif pour votre projet. Les modèles de nommage courants incluent l’affectation de noms d'après l'application (par exemple,
my-analytics-app) ou le client ou le locataire que le projet sert (par exemple,acme-corp-db). - Version de Postgres : sélectionnez la version postgres que vous souhaitez utiliser.
-
Nom du projet : entrez un nom descriptif pour votre projet. Les modèles de nommage courants incluent l’affectation de noms d'après l'application (par exemple,
Créer un projet - la boîte de dialogue affiche les options de configuration du projet.
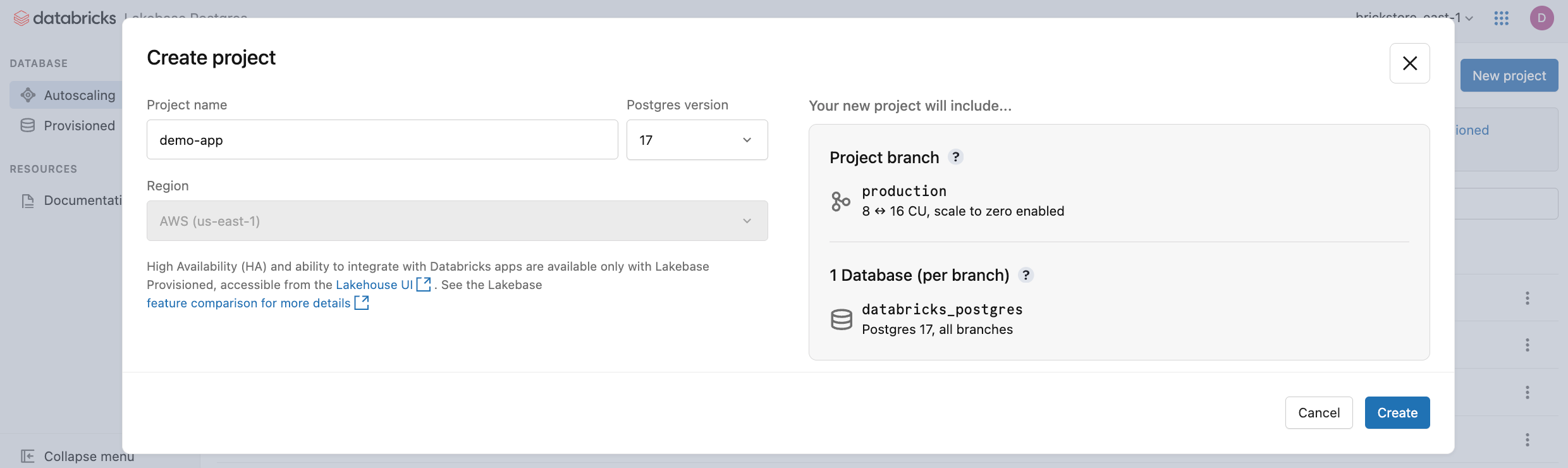
La région de votre projet Lakebase est définie sur votre région d’espace de travail Databricks et ne peut pas être modifiée.
Kit de développement logiciel (SDK) Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version="17"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
Kit de développement logiciel (SDK) Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
Interface de ligne de commande (CLI)
# Create a project with a custom project ID
databricks postgres create-project \
--project-id my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}'
friser
Créez un projet avec un ID de projet personnalisé. Le project_id paramètre de requête est spécifié et fait partie du nom de la ressource du projet (par exemple). projects/my-app
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": "17"
}
}' | jq
Il s’agit d’une opération longue. La réponse inclut un nom d’opération que vous pouvez utiliser pour vérifier l’état. L’opération se termine généralement en quelques secondes.
Le paramètre project_id est obligatoire.
Un nouveau projet inclut les ressources suivantes par défaut :
Une branche unique
production(la branche par défaut)Un calcul en lecture-écriture principal unique associé à la branche avec les paramètres par défaut suivants :
Branch Unités de calcul (CU) RAM Autoscaling Mise à l'échelle jusqu'à zéro production8 - 32 CU 16 à 64 Go Activé Désactivé Lorsque vous créez un projet, la branche
productionest créée avec un calcul dont la mise à l'échelle au zéro est désactivée par défaut, ce qui signifie que le calcul reste actif en permanence. Vous pouvez activer l’échelle à zéro pour ce calcul si nécessaire.Une base de données Postgres (nommée
databricks_postgres)Rôle Postgres pour votre identité Databricks (par exemple,
user@databricks.com)
Pour modifier les paramètres de calcul d’un projet existant, consultez Configurer les paramètres du projet. Pour modifier les paramètres de calcul par défaut pour les nouveaux projets, consultez Paramètres de calcul par défaut dans Configurer les paramètres du projet.
Obtenir les détails du projet
Récupérez les détails d’un projet spécifique.
IU
- Cliquez sur le sélecteur d’applications dans le coin supérieur droit pour ouvrir l’application Lakebase.
- Sélectionnez votre projet dans la liste des projets pour afficher ses détails.
Kit de développement logiciel (SDK) Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
Kit de développement logiciel (SDK) Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
Interface de ligne de commande (CLI)
# Get project details
databricks postgres get-project projects/my-project
friser
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
La réponse inclut :
-
name: Nom de la ressource (projects/my-project) -
status: Configuration du projet et état actuel (display_name, pg_version, état, etc.)
Remarque : Le spec champ n’est pas rempli pour les GET opérations. Toutes les propriétés de ressource sont retournées dans le status champ.
Répertorier les projets
Répertoriez tous les projets de votre espace de travail.
IU
- Cliquez sur le sélecteur d’applications dans le coin supérieur droit pour ouvrir l’application Lakebase.
- La liste des projets affiche tous les projets auquel vous avez accès.
Kit de développement logiciel (SDK) Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
Kit de développement logiciel (SDK) Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
Interface de ligne de commande (CLI)
# List all projects
databricks postgres list-projects
friser
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Format de réponse :
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": "17",
"state": "READY"
}
}
]
}
Configurer les paramètres du projet
Après avoir créé un projet, vous pouvez modifier différents paramètres à partir du tableau de bord du projet en accédant à Paramètres :
Paramètres généraux
Vous pouvez mettre à jour le nom du projet. L’ID de projet ne peut pas être modifié.
IU
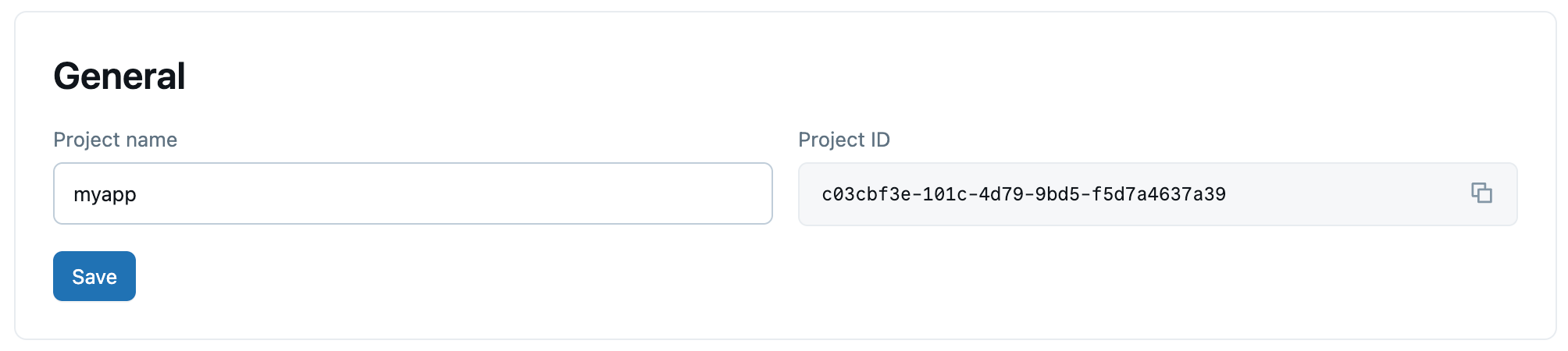
Interface de ligne de commande (CLI)
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
friser
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
Il s’agit d’une opération longue. La réponse inclut un nom d’opération que vous pouvez utiliser pour vérifier l’état.
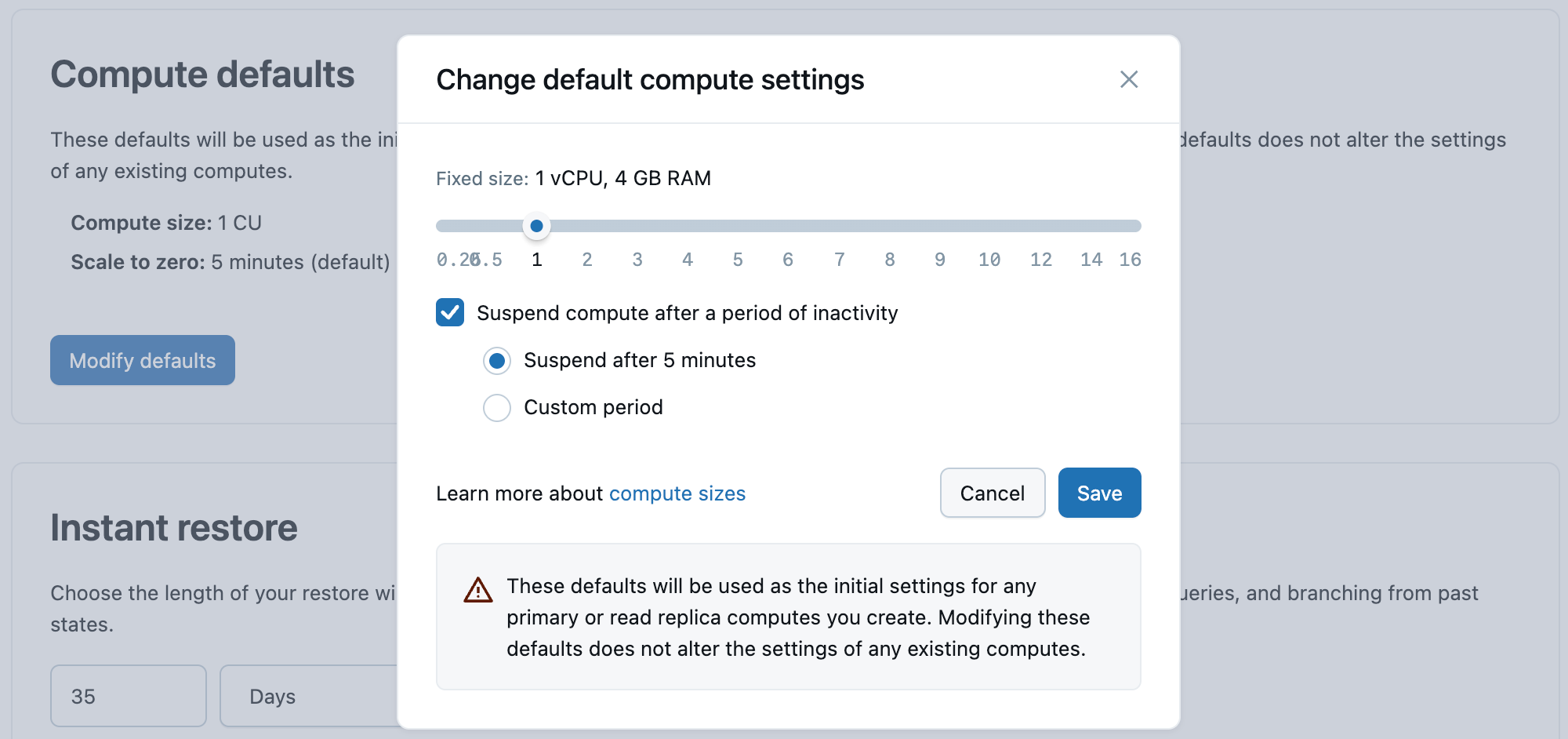
Valeurs par défaut de calcul
Définissez les paramètres initiaux pour les calculs principaux, notamment :
- Taille de calcul (mesurée en unités de calcul)
- Réduction à zéro du délai d'expiration (la valeur par défaut est de 5 minutes)
Ces paramètres sont utilisés lorsque vous créez de nouveaux calculs principaux.
Note
Pour modifier les paramètres d’un calcul existant, consultez Gérer les calculs.
Lakebase Postgres prend en charge les tailles de calcul comprises entre 0,5 CU et 112 CU. La mise à l’échelle automatique est disponible pour les calculs jusqu’à 32 CU (0,5, puis incréments entiers : 1, 2, 3... 16, puis 24, 28, 32). Les unités de calcul à taille fixe plus grandes sont disponibles de 36 CU à 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112). Chaque unité de calcul (CU) fournit 2 Go de RAM.
Note
Lakebase Provisioned vs Autoscaling : Dans Lakebase Provisioned, chaque unité de calcul a alloué environ 16 Go de RAM. Dans la mise à l’échelle automatique Lakebase, chaque CU alloue 2 Go de RAM. Cette modification fournit des options de mise à l’échelle plus granulaires et un contrôle des coûts.
Tailles représentatives :
| Unités de calcul | RAM |
|---|---|
| 0.5 CU | 1 Go |
| 1 unité de capacité | 2 Go |
| 4 Unités de calcul | 8 Go |
| 16 unités de calcul | 32 Go |
| 32 Unités de calcul | 64 Go |
| 64 unités de calcul (CU) | 128 Go |
| 112 CU | 224 Go |
- Pour activer la mise à l’échelle automatique, définissez une plage de tailles de calcul à l’aide du curseur. La mise à l’échelle automatique ajuste dynamiquement les ressources de calcul en fonction de la demande de charge de travail. En savoir plus : Mise à l’échelle automatique
- Ajustez le paramètre de mise à l’échelle à zéro pour augmenter ou diminuer la durée de calcul inactive avant qu’un calcul ne soit suspendu. Vous pouvez également désactiver la mise à l’échelle à zéro pour un calcul toujours actif. En savoir plus : Réduire à zéro
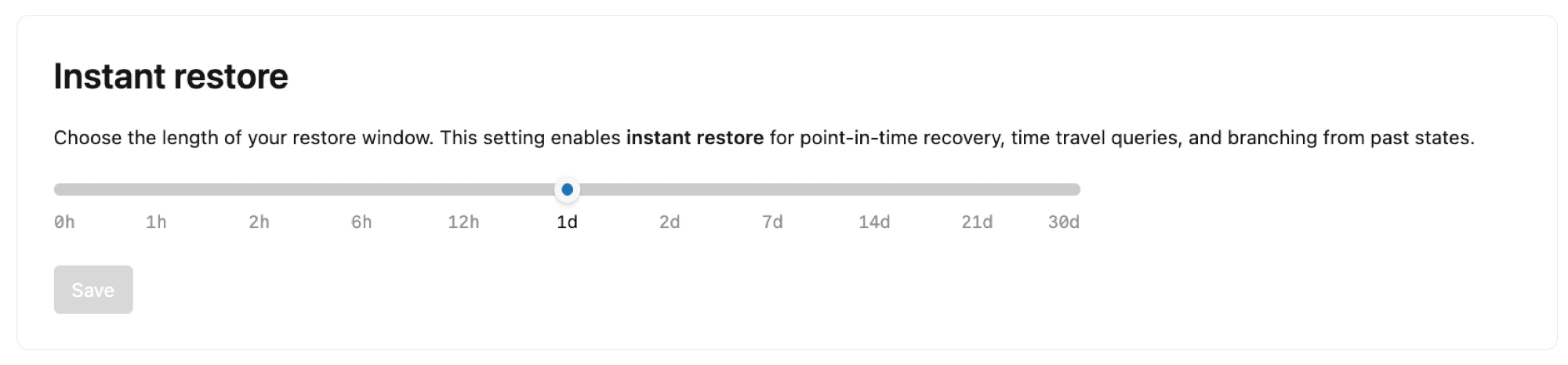
Restauration instantanée
Configurez la longueur de la fenêtre de restauration pour votre projet. Par défaut, Lakebase conserve un historique des modifications apportées aux branches racines de votre projet, ce qui permet une restauration à un point dans le temps pour récupérer des données perdues, interroger des données à un moment donné pour examiner les problèmes de données et créer une branche à partir d’états passés pour les flux de travail de développement.
Vous pouvez définir la fenêtre de restauration de 2 jours à 35 jours. Notez que :
- L’extension de la fenêtre de restauration augmente votre stockage
- Le paramètre de fenêtre de restauration affecte toutes les branches de votre projet
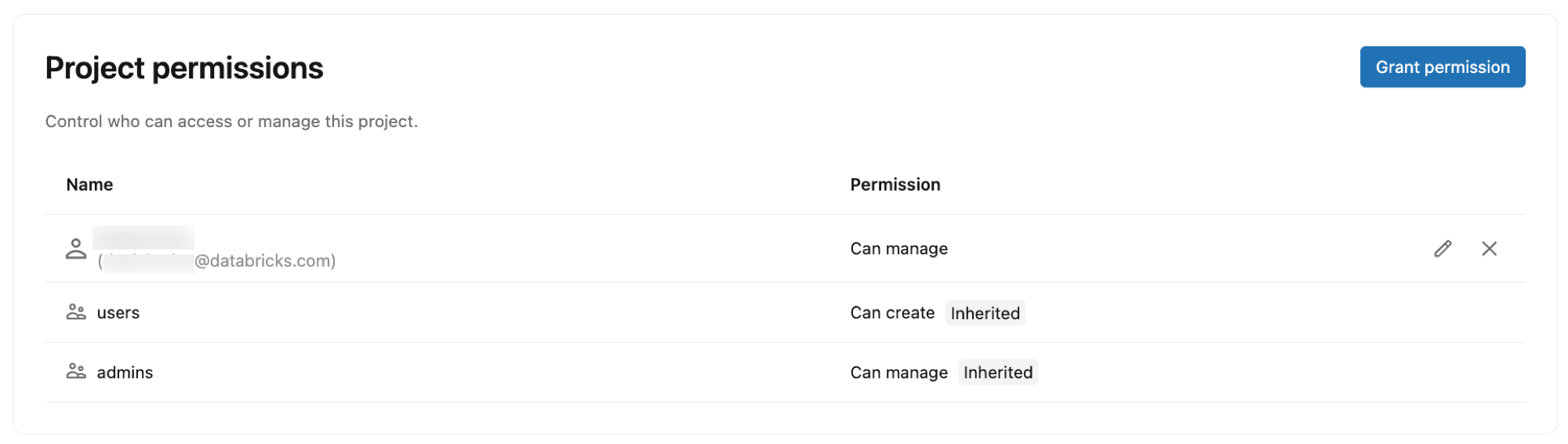
Autorisations de projet
Contrôlez qui peut accéder et gérer votre projet Lakebase en accordant des autorisations aux identités, groupes et principaux de service Azure Databricks. Les autorisations de projet déterminent les actions que les utilisateurs peuvent effectuer dans le projet, telles que la création de branches, la gestion des calculs et l’affichage des détails de connexion.
Types d’autorisations :
- CAN CREATE : afficher et créer des ressources de projet
- CAN USE : afficher et utiliser des ressources de projet (liste, affichage, connexion et effectuer certaines opérations de branche) sans créer ou supprimer des projets ou des branches
- CAN MANAGE : Contrôle total sur la configuration et les ressources du projet
Autorisations par défaut :
Lorsque vous créez un projet, les autorisations suivantes sont automatiquement attribuées :
- Propriétaire du projet (utilisateur qui a créé le projet) : CAN MANAGE (contrôle total)
- Utilisateurs de l’espace de travail : CAN CREATE (peut afficher et créer des projets)
- Administrateurs d’espace de travail : CAN MANAGE (contrôle total)
Pour accorder l’accès à d’autres utilisateurs, consultez Gérer les autorisations de projet.
Note
Les autorisations de projet et l’accès à la base de données sont séparés
Les autorisations de projet contrôlent les actions de plateforme Lakebase, tandis que l’accès à la base de données est contrôlé par les rôles Postgres et leurs autorisations associées. Consultez Créer des rôles Postgres et Gérer les autorisations de base de données.
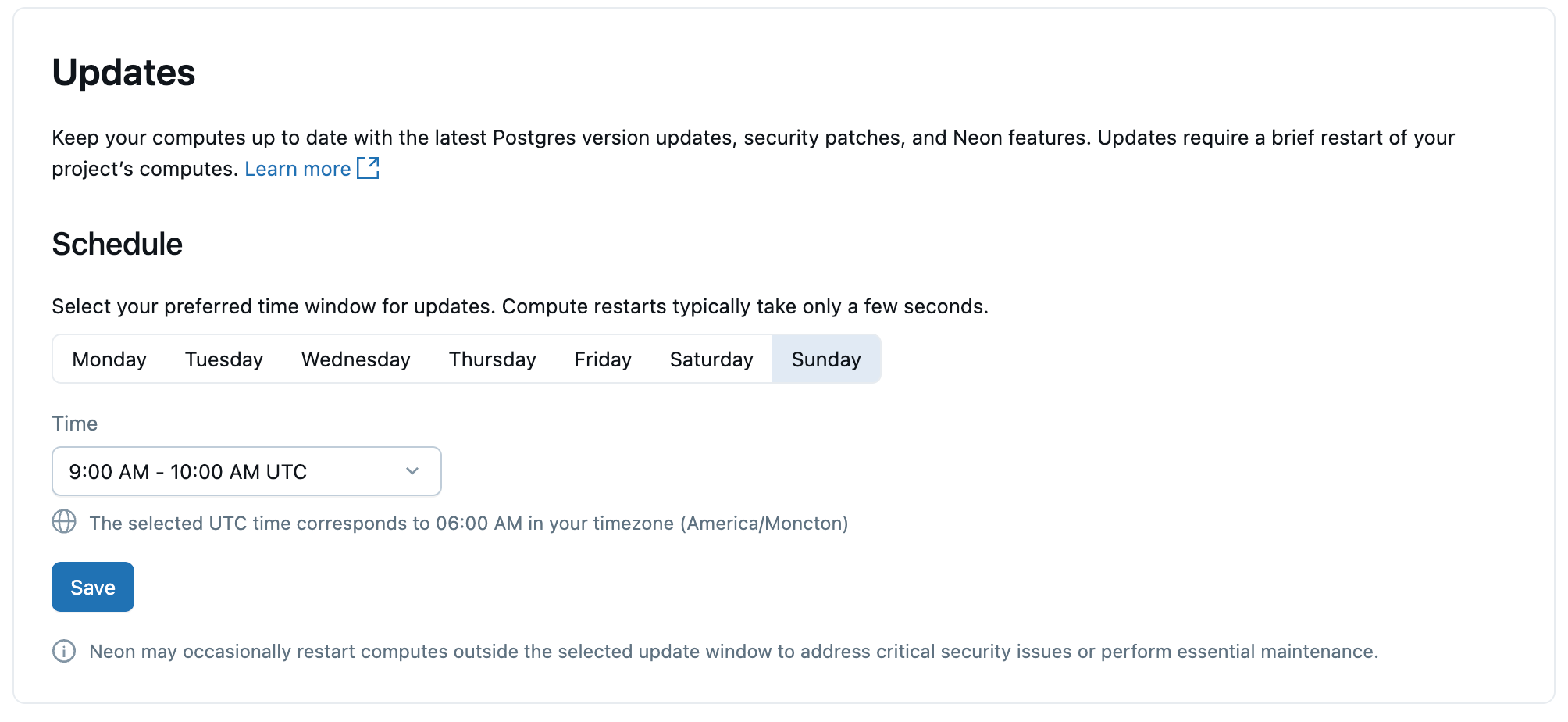
Mises à jour
Pour maintenir vos calculs Lakebase et vos instances Postgres à jour, Lakebase applique automatiquement les mises à jour planifiées qui incluent les mises à niveau de version mineures de Postgres, les correctifs de sécurité et les fonctionnalités de plateforme. Les mises à jour sont appliquées aux calculs au sein de votre projet et nécessitent un bref redémarrage du calcul qui prend quelques secondes.
Les mises à jour sont appliquées automatiquement, mais vous pouvez définir une journée et une heure préférées pour les mises à jour. Les redémarrages se produisent dans votre fenêtre de temps sélectionnée.
Pour plus d’informations sur les mises à jour, consultez Gérer les mises à jour.
Supprimer un projet
La suppression d’un projet est une action permanente qui supprime également les calculs, branches, bases de données, rôles et données qui appartiennent au projet.
Important
Cette opération est irréversible. Soyez prudent lors de la suppression d’un projet, car cela supprime toutes les branches et données associées.
Avant de supprimer
Databricks recommande de supprimer tous les catalogues de catalogue Unity associés et les tables synchronisées avant de supprimer le projet. Sinon, la tentative d’affichage des catalogues ou l’exécution de requêtes SQL qui les référencent entraînent des erreurs.
Si vous n’êtes pas le propriétaire des tables ou catalogues, vous devez réaffecter la propriété à vous-même avant la suppression.
Note
Dans la mise à l’échelle automatique Lakebase, toute identité Databricks ayant accès à l’espace de travail où le projet a été créé peut supprimer des projets.
Supprimer un projet
Pour supprimer un projet :
IU
- Accédez aux paramètres de votre projet dans l’application Lakebase.
- Dans la section Supprimer le projet , cliquez sur Supprimer et entrez le nom du projet pour confirmer la suppression.
Kit de développement logiciel (SDK) Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name}")
Il s’agit d’une opération longue. Le projet et toutes ses ressources (branches, points de terminaison, bases de données, rôles, données) seront supprimées.
Kit de développement logiciel (SDK) Java
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Il s’agit d’une opération longue. Le projet et toutes ses ressources (branches, points de terminaison, bases de données, rôles, données) seront supprimées.
Interface de ligne de commande (CLI)
# Delete a project
databricks postgres delete-project projects/my-project
Cette commande retourne immédiatement. Le projet et toutes ses ressources seront supprimés.
friser
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Il s’agit d’une opération longue. La réponse inclut un nom d’opération que vous pouvez utiliser pour vérifier l’état de suppression.