Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Important
La mise à l’échelle automatique Lakebase est en version bêta dans les régions suivantes : eastus2, westeurope, westus.
La version Autoscaling de Lakebase est la dernière de Lakebase, offrant l'autoscaling, la mise à l'échelle à zéro, la bifurcation et la restauration instantanée. Pour la comparaison des fonctionnalités avec Lakebase Provisioned, consultez le choix entre les versions.
Démarrez avec Lakebase Postgres en quelques minutes. Créez votre premier projet, connectez-vous à votre base de données et explorez les fonctionnalités clés, notamment l’intégration du catalogue Unity.
Créer votre premier projet
Ouvrez l’application Lakebase à partir du sélecteur d’applications.
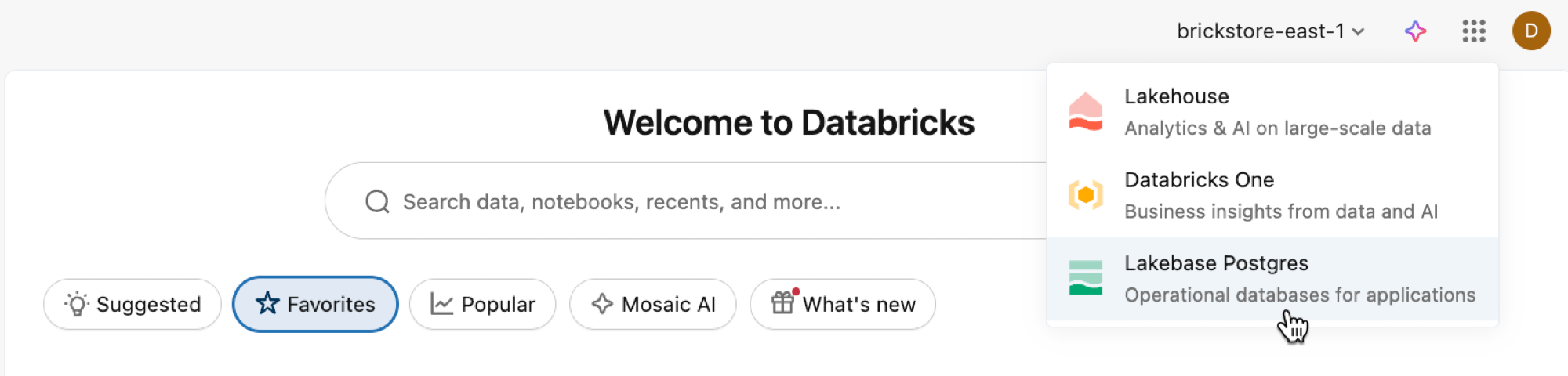
Sélectionnez Mise à l’échelle automatique pour accéder à l’interface utilisateur de mise à l’échelle automatique Lakebase.
Cliquez sur Nouveau projet. Donnez un nom à votre projet et sélectionnez votre version de Postgres. Votre projet est créé avec une branche unique production , une base de données par défaut databricks_postgres et des ressources de calcul configurées pour la branche.
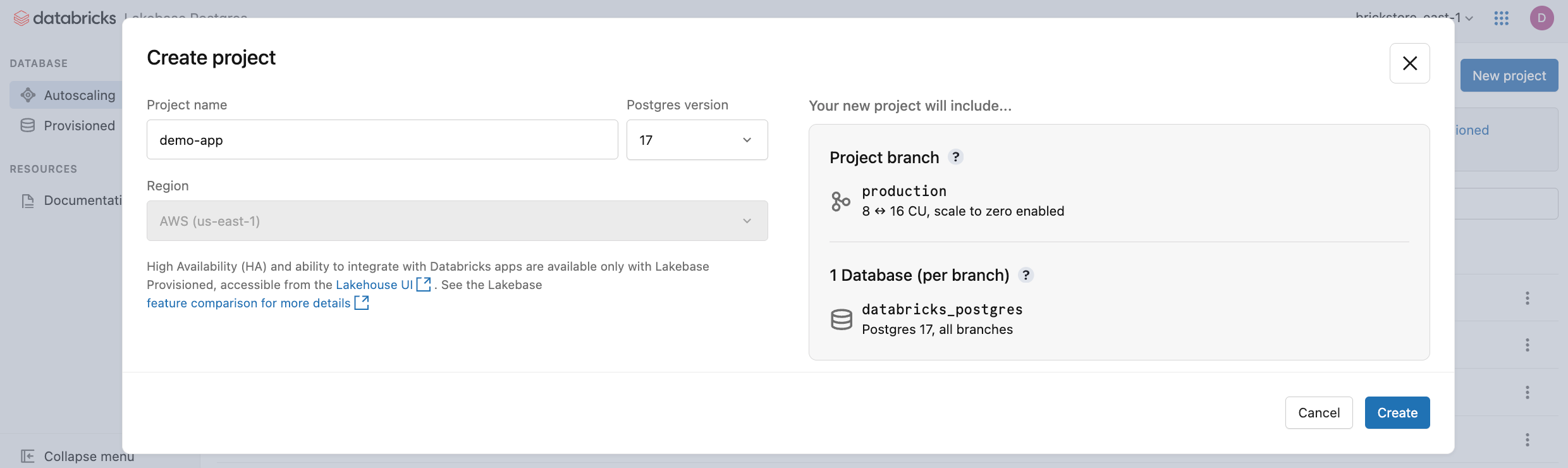
Il peut falloir quelques instants pour que votre ordinateur s'active. Le calcul de la production branche est toujours activé par défaut (la mise à l’échelle à zéro est désactivée), mais vous pouvez configurer ce paramètre si nécessaire.
La région de votre projet est automatiquement définie sur votre région d’espace de travail. Pour obtenir des options de configuration détaillées, consultez Créer un projet.
Connectez-vous à votre base de données
Dans votre projet, sélectionnez la branche de production , puis cliquez sur Se connecter. Vous pouvez vous connecter à l’aide de votre identité Databricks avec l’authentification OAuth ou créer un rôle de mot de passe Postgres natif. Les chaînes de connexion fonctionnent avec des clients Postgres standard tels que psql, pgAdmin ou n’importe quel outil compatible Postgres.
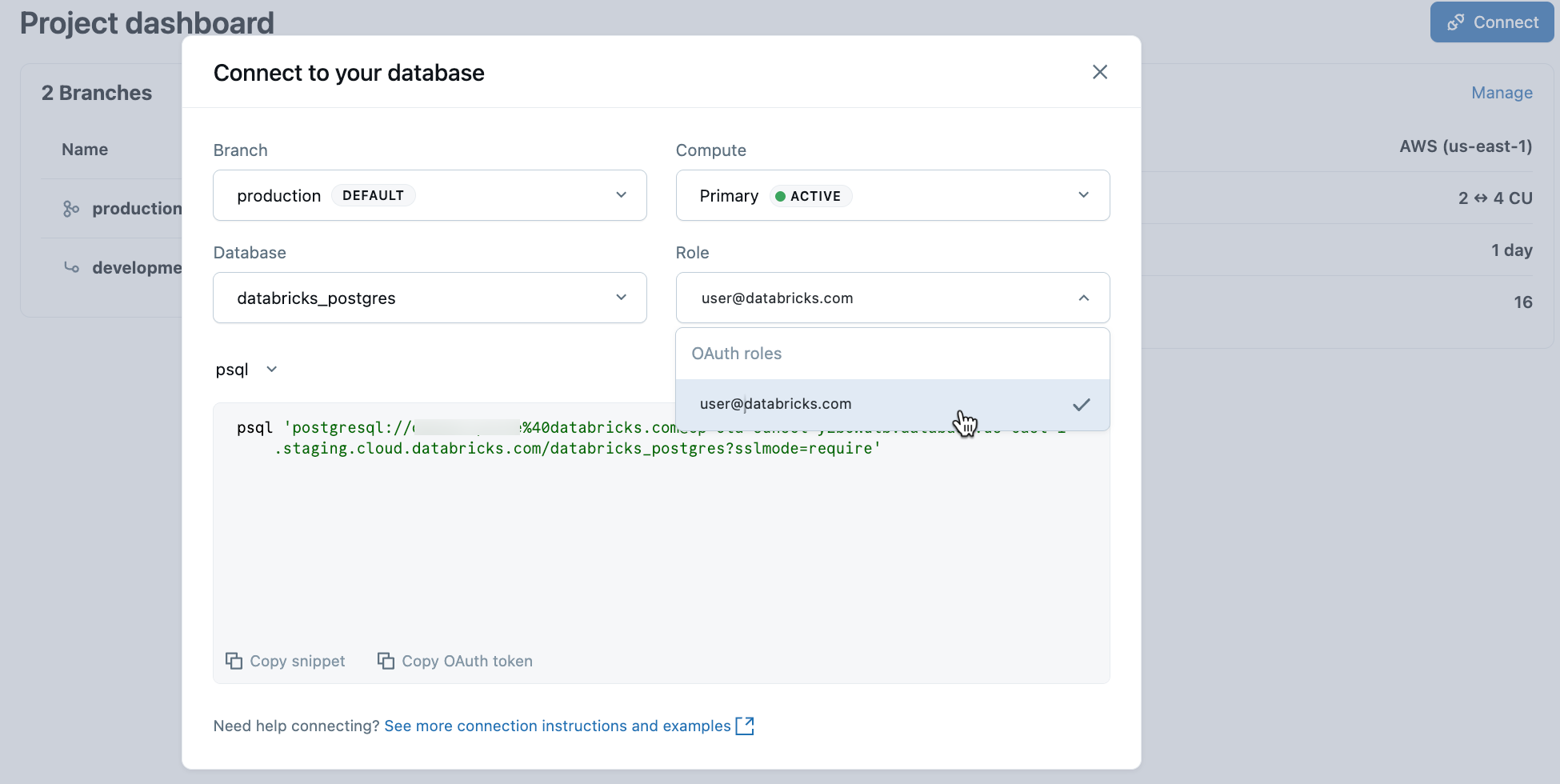
Lorsque vous créez un projet, un rôle Postgres pour votre identité Databricks (par exemple) user@databricks.comest créé automatiquement. Ce rôle possède la base de données par défaut databricks_postgres et est membre de databricks_superuser, ce qui lui donne de larges privilèges pour gérer les objets de base de données.
Pour vous connecter à l’aide de votre identité Databricks avec OAuth, copiez l’extrait psql de connexion à partir de la boîte de dialogue de connexion.
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Après avoir entré la psql commande de connexion dans votre terminal, vous êtes invité à fournir un jeton OAuth. Obtenez votre jeton en cliquant sur l’option Copier le jeton OAuth dans la boîte de dialogue de connexion.
Pour plus d’informations sur la connexion et les options d’authentification, consultez Démarrage rapide.
Créer votre première table
L’éditeur SQL Lakebase est préchargé avec l’exemple SQL pour vous aider à commencer. Dans votre projet, sélectionnez la branche de production , ouvrez l’éditeur SQL et exécutez les instructions fournies pour créer une table et insérer des playing_with_lakebase exemples de données. Vous pouvez également utiliser l’Éditeur de tables pour la gestion des données visuelles ou vous connecter à des clients Postgres externes.
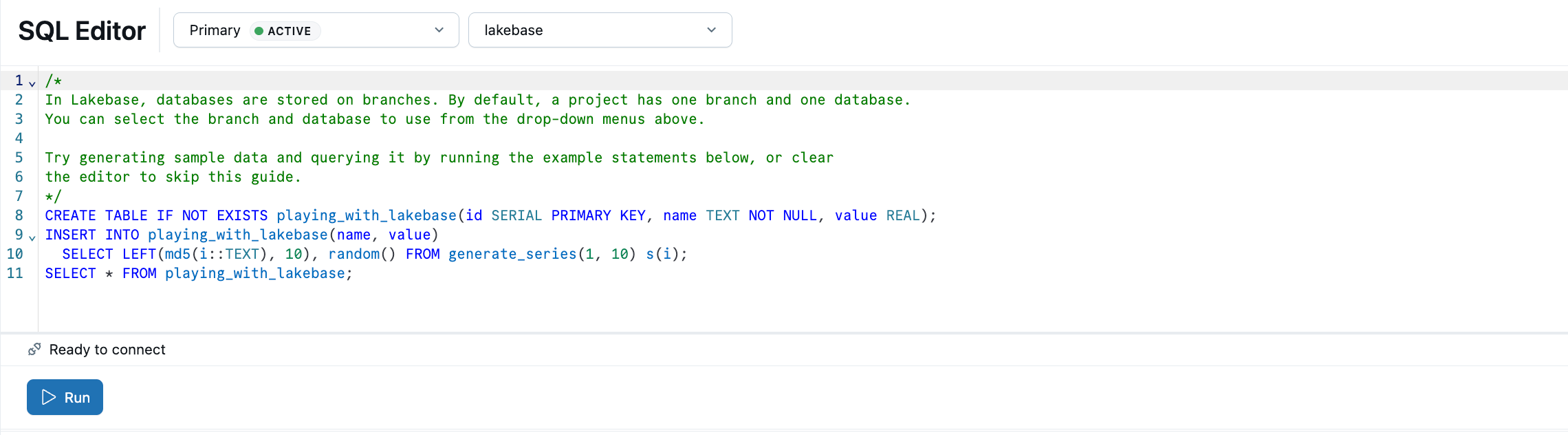
En savoir plus sur les options d’interrogation : Éditeur SQL | Éditeur de tables | clients Postgres
S’inscrire dans le catalogue Unity
Maintenant que vous avez créé une table sur votre branche de production, nous allons inscrire la base de données dans le catalogue Unity pour pouvoir interroger ces données à partir de l’éditeur SQL Databricks.
- Utilisez le sélecteur d’applications pour accéder à Lakehouse.
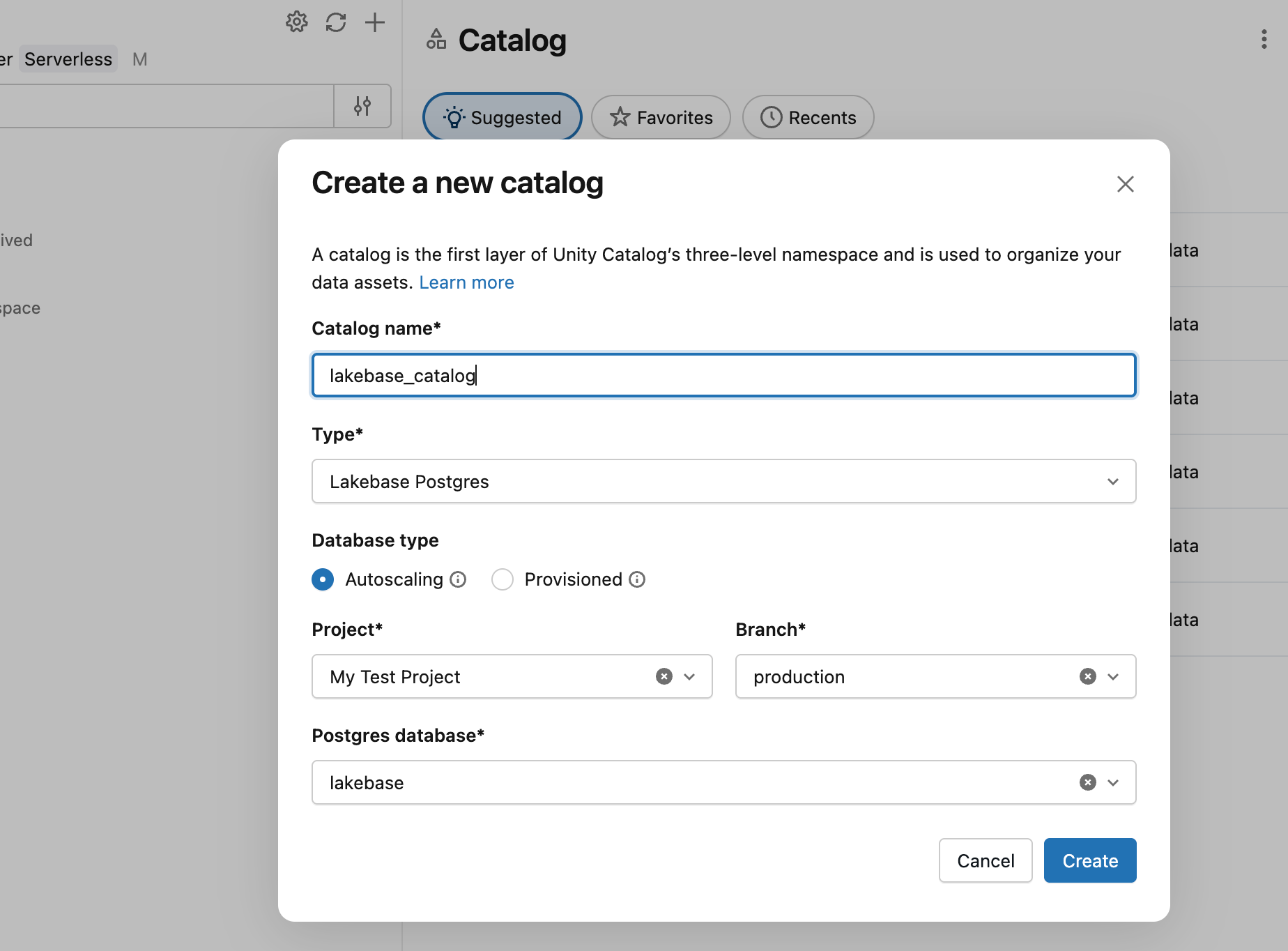
- Dans l’Explorateur de catalogues, cliquez sur l’icône plus et créez un catalogue.
- Entrez un nom de catalogue (par exemple,
lakebase_catalog). - Sélectionnez Lakebase Postgres comme type de catalogue et activez l’option de mise à l’échelle automatique .
- Sélectionnez votre projet, la
productionbranche et ladatabricks_postgresbase de données. - Cliquez sur Créer.
Vous pouvez maintenant interroger la playing_with_lakebase table que vous venez de créer à partir de l’éditeur SQL Databricks à l’aide d’un entrepôt SQL :
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Cela permet des requêtes fédérées qui joignent vos données transactionnelles Lakebase à l’analytique lakehouse. Pour plus d’informations, consultez Inscrire dans le catalogue Unity.
Synchroniser des données avec ETL inverse
Vous venez de voir comment rendre les données Lakebase interrogeables dans le catalogue Unity. Lakebase fonctionne également dans l'autre sens : en intégrant des données analytiques organisées depuis Unity Catalog dans votre base de données Lakebase. Cela est utile lorsque vous avez enrichi des données, des fonctionnalités ML ou des métriques agrégées calculées dans votre lakehouse qui doivent être traitées par des applications avec des requêtes transactionnelles à faible latence.
Tout d’abord, créez une table dans le catalogue Unity qui représente des données analytiques. Ouvrez un entrepôt SQL ou un notebook et exécutez :
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Synchronisez maintenant cette table avec votre base de données Lakebase :
- Dans l'Explorateur de catalogue Lakehouse, naviguez vers main>default>user_segments.
- Cliquez sur Créer une>table synchronisée.
- Configurez la synchronisation :
-
Nom de la table : Entrée
user_segments_synced. - Type de base de données : Sélectionnez Lakebase Serverless (mise à l’échelle automatique).
- Mode de synchronisation : choisissez l’instantané pour une synchronisation de données ponctuelle.
- Sélectionnez votre projet, la branche de production et la
databricks_postgresbase de données.
-
Nom de la table : Entrée
- Cliquez sur Créer.
Une fois la synchronisation terminée, la table apparaît dans votre base de données Lakebase. Le processus de synchronisation crée un default schéma dans Postgres pour qu’il corresponde au schéma du catalogue Unity.main.default.user_segments_synceddefault.user_segments_synced Revenez à Lakebase à l’aide du sélecteur d’applications et interrogez-le dans l’éditeur SQL Lakebase :
SELECT * FROM "default"."user_segments_synced" WHERE "engagement" = 'high';
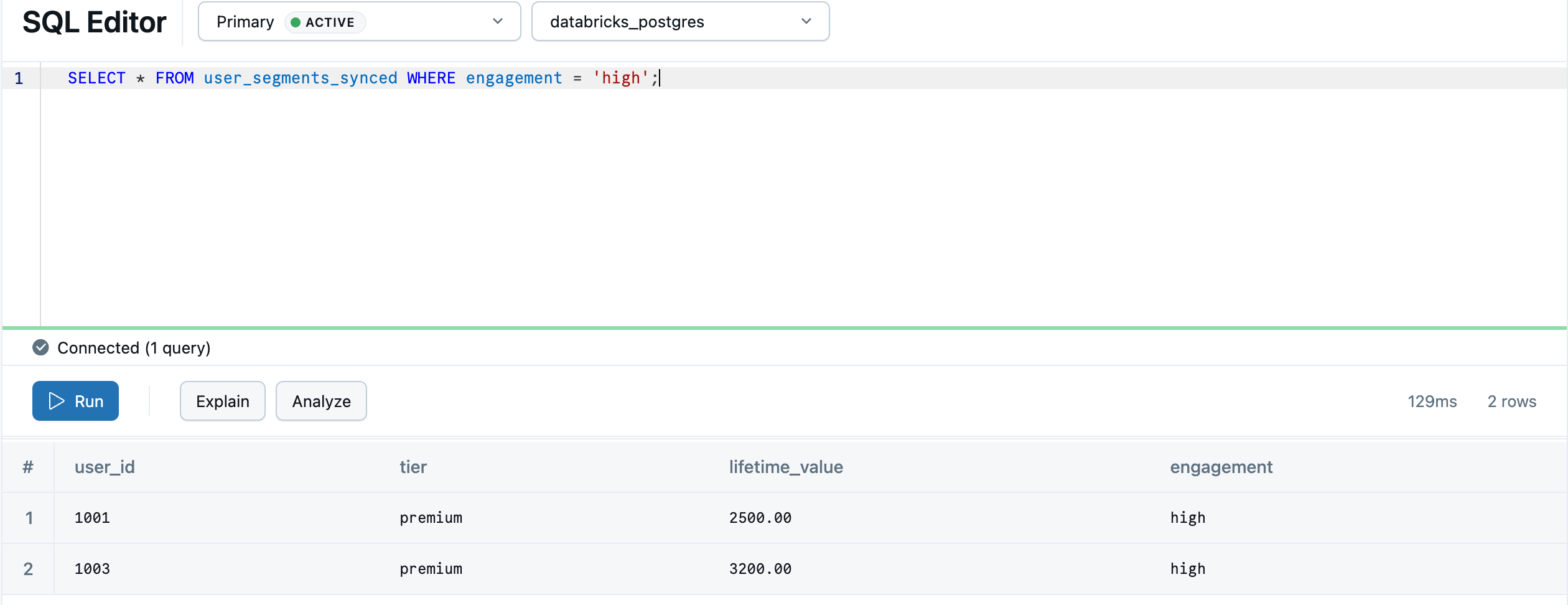
Vos analyses 'lakehouse' sont désormais disponibles pour une consultation en temps réel dans votre base de données transactionnelle. Pour la synchronisation continue, les configurations avancées et les mappages de types de données, consultez ETL inverse.