Charge de travail SAP sur les machines virtuelles Azure - Scénarios pris en charge
Concevoir un architecture système SAP NetWeaver, Business One, Hybris ou S/4HANA dans Azure ouvre de nombreuses possibilités en matière d’architectures et d’outils à utiliser pour parvenir à un déploiement évolutif, efficace et hautement disponible. Bien qu’elles dépendent du système d’exploitation ou du SGBD utilisé, il existe des restrictions. De même, tous les scénarios pris en charge localement ne sont pas pris en charge de la même manière dans Azure. Ce document présente les configurations sans haute disponibilité prises en charge, ainsi que les configurations et architectures haute disponibilité utilisant exclusivement des machines virtuelles Azure.
Notes
Le service de grande instance HANA approche sa fin de vie et n’accepte plus de nouveaux clients. La fourniture d’unités pour les clients de grande instance HANA existants est toujours possible. Pour obtenir des alternatives, consultez les offres de machines virtuelles Azure certifiées HANA dans le répertoire de matériel HANA. Pour les scénarios qui étaient et sont toujours pris en charge pour les clients de grande instance HANA existants avec les Grandes instances HANA, consultez l’article Scénario pris en charge pour des grandes instances HANA.
Restrictions générales sur la plateforme
Azure dispose de différentes plateformes en plus des machines virtuelles Azure natives qui sont proposées en tant que service de première partie. Les Grandes instances HANA, qui approchent leur fin de vie, font partie de ces plateformes. Azure VMware Services est un autre de ces services de première partie. Azure VMware Services n’est généralement pas pris en charge par SAP pour l’hébergement de la charge de travail SAP. Consultez la note de support SAP #2138865 - Applications SAP sur VMware Cloud : produits et configurations de machine virtuelle pris en charge pour plus de détails sur la prise en charge de VMware sur différentes plateformes.
Outre le Active Directory local, Azure offre un service SaaS Active Directory géré avec Microsoft Entra Domain Services (ad traditionnel géré par Microsoft) et l’ID Microsoft Entra. Les composants SAP hébergés sur le système d’exploitation Windows utilisent souvent Windows Active Directory. Dans ce cas, active Directory traditionnel tel qu’il est hébergé localement, ou Microsoft Entra Domain Services (toujours en cours de test). Toutefois, ces composants SAP ne peuvent pas fonctionner avec l’ID Microsoft Entra natif. C’est pourquoi il existe encore des lacunes plus importantes dans les fonctionnalités entre Active Directory dans son formulaire local ou son formulaire SaaS (Microsoft Entra Domain Services) et l’ID Microsoft Entra natif. Cette dépendance est la raison pour laquelle les comptes Microsoft Entra ne sont pas pris en charge pour les applications basées sur SAP NetWeaver et S/4 HANA sur le système d’exploitation Windows. Des comptes Active Directory traditionnels doivent être utilisés dans de tels scénarios.
| Service AD | Applications prises en charge basées sur SAP NetWeaver et S/4 HANA sur le système d’exploitation Windows |
|---|---|
| Windows Active Directory local | Prise en charge |
| Microsoft Entra Domain Services | Prise en charge |
| Microsoft Entra ID | Non pris en charge |
Les éléments ci-dessus n’affectent pas l’utilisation des comptes Microsoft Entra pour les scénarios d’authentification unique (SSO) avec des applications SAP.
Configuration à deux niveaux
Une configuration SAP à deux niveaux est considérée comme étant constituée d’une couche combinée de SGBD SAP et d'application s'exécutant sur le même serveur ou unité de machine virtuelle. Le second niveau est considéré comme la couche d’interface utilisateur. Dans le cas d’une configuration à deux couches, le SGBD et la couche application SAP partagent les ressources de la machine virtuelle Azure. Dès lors, il vous faut configurer les différents composants de manière à ce qu’ils ne se disputent pas les ressources. Vous devez également veiller à ne pas sur-souscrire les ressources de la machine virtuelle. Une telle configuration n’offre pas de haute disponibilité, au-delà des contrats de niveau de service Azure des différents composants Azure impliqués.
Graphiquement, une telle configuration peut se présenter comme suit :
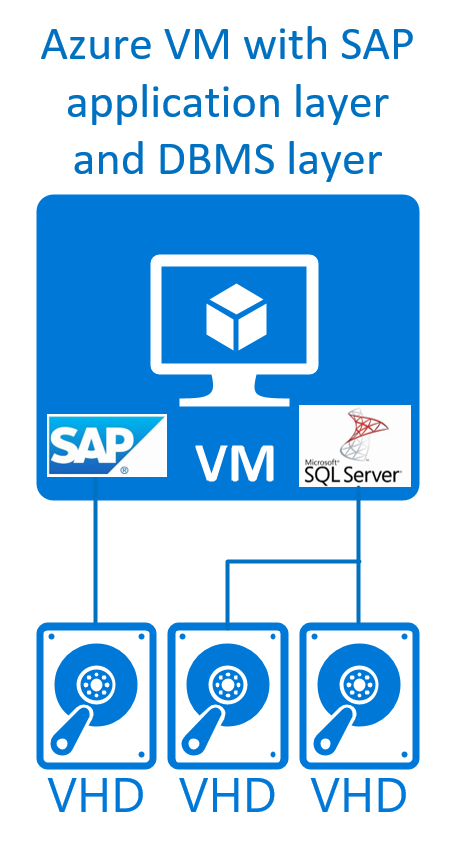
De telles configurations sont prises en charge avec Windows, Red Hat, SUSE et Oracle Linux pour les systèmes SGBD de SQL Server, Oracle, Db2, maxDB et SAP ASE pour les cas de production et de non-production. Quand SAP HANA est le SGBD, SAP prend en charge ce type de scénario, comme indiqué dans la note SAP #1953429. Jusqu’à présent, aucune des distributions Linux ne fournissait suffisamment de documentation sur la haute disponibilité pour configurer et exploiter un cluster Pacemaker dans ce type de configuration. Par conséquent, ce type de configuration est pris en charge sur Azure uniquement pour les cas autres que ceux de production qui ne nécessitent pas de cluster de basculement à haute disponibilité.
Pour toutes les combinaisons SE/SGBD prises en charge sur Azure, ce type de configuration est pris en charge. Toutefois, vous devez absolument définir la configuration du SGBD et des composants SAP de manière à ce qu’ils ne soient pas en concurrence pour l’utilisation des ressources de mémoire et de processeur, ce qui entraînerait le dépassement des ressources physiques disponibles. Cela doit se faire en limitant la mémoire que le SGBD est autorisé à allouer. Vous devez également limiter la mémoire étendue SAP sur les instances d’application. En outre, vous devez surveiller la consommation d’UC de la machine virtuelle pour vous assurer que les composants n’optimisent pas les ressources d’UC.
Notes
Pour les systèmes SAP de production, nous recommandons plus de haute disponibilité et d'éventuelles configurations de récupération d’urgence, comme décrit plus loin dans ce document.
Configuration à trois niveaux
Dans de telles configurations, vous séparez la couche d’application SAP et la couche SGBD en différentes machines virtuelles. Vous procédez généralement ainsi pour les plus grands systèmes et pour des raisons de flexibilité sur les ressources de la couche d’application SAP. Dans la plus simple configuration, il n’y a pas de haute disponibilité, au-delà des contrats de niveau de service Azure des différents composants Azure impliqués.
La représentation graphique se présente comme suit :
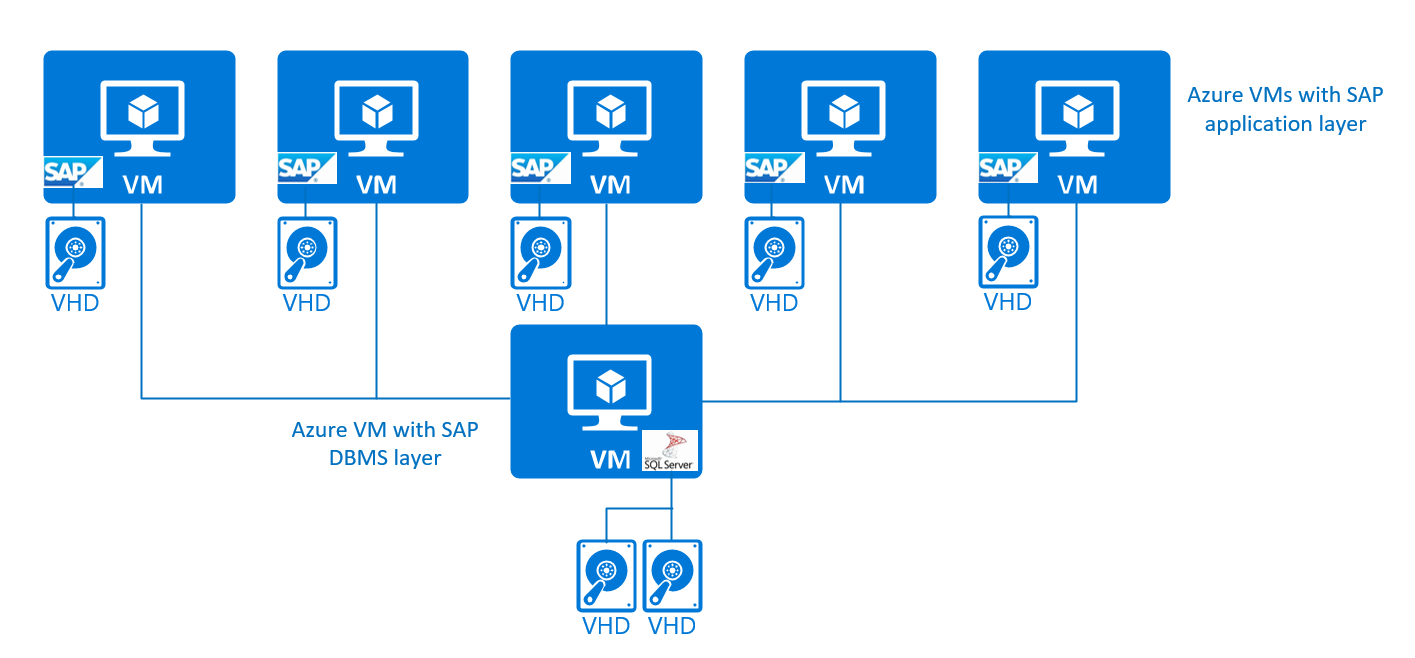
Ce type de configuration est pris en charge sur Windows, Red Hat, SUSE et Oracle Linux pour les systèmes SGBD de SQL Server, Oracle, DB2, SAP HANA, maxDB et SAP ASE pour les cas de production et de non-production. Dans un souci de simplification, nous n’avons pas fait la distinction entre les services centraux SAP et les instances de dialogue SAP dans la couche d’application SAP. Dans cette configuration simple à trois niveaux, aucune protection haute disponibilité n’est disponible pour les services centraux SAP.
Notes
Pour les systèmes SAP de production, nous recommandons plus de haute disponibilité et d'éventuelles configurations de récupération d’urgence, comme décrit plus loin dans ce document.
Plusieurs instances SGBD par machine virtuelle
Dans ce type de configuration, vous hébergez plusieurs instances SGBD par machine virtuelle Azure. Et ce, pour avoir moins de systèmes d’exploitation à gérer et réduire les coûts, par exemple. Vous pouvez également avoir plus de flexibilité et d’efficacité en partageant les ressources d’une plus grande machine virtuelle ou unité de grande instance HANA entre plusieurs instances SGBD. Jusqu’à présent, ces configurations portaient principalement sur les systèmes de non-production.
Une telle configuration peut se présenter comme suit :
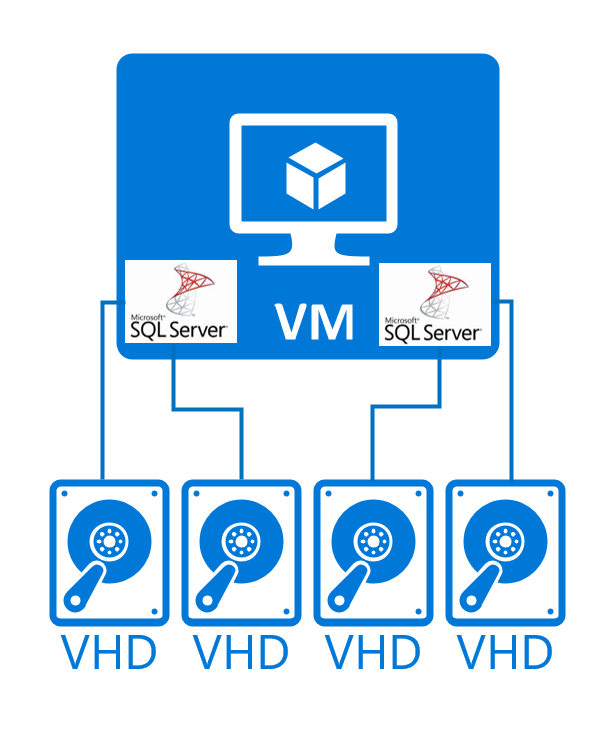
Ce type de déploiement SGBD est pris en charge pour :
- SQL Server sur Windows
- IBM Db2. Pour plus d'informations, consultez l'article Instances multiples (Linux, UNIX)
- Pour Oracle. Pour plus d’informations, consultez note de support SAP n° 1778431 et notes SAP associées
- Pour SAP HANA, instances multiples sur une machine virtuelle, appels SAP, cette méthode de déploiement MCOS est prise en charge. Pour plus d’informations, consultez l’article SAP Systèmes SAP HANA multiples sur un hôte (MCOS)
En exécutant plusieurs instances de base de données sur un seul hôte, vous devez vous assurer que les différentes instances ne sont pas en concurrence en termes de ressources et, par conséquent, dépasser les limites de ressources physiques de la machine virtuelle. Cela se vérifie notamment lorsqu'il vous faut limiter la mémoire que chaque utilisateur partageant la machine virtuelle peut allouer. Cela peut également se vérifier pour les ressources d’UC que les différentes instances de base de données peuvent consommer. Tous les systèmes de base de données mentionnés ont des configurations qui permettent de limiter l’allocation de mémoire et les ressources de processeur au niveau de l’instance. Pour que cette configuration soit prise en charge pour les machines virtuelles Azure, vous devez séparer les disques ou volumes que vous utilisez pour les données et les fichiers journaux/de restauration des bases de données gérées par les différentes instances. En d’autres termes, les données ou les fichiers journaux/de restauration des bases de données gérées par différentes instances SGBD ne sont pas censés partager les mêmes disques ou volumes.
Notes
Pour les systèmes SAP de production, nous recommandons plus de haute disponibilité et d'éventuelles configurations de récupération d’urgence, comme décrit plus loin dans ce document. Les machines virtuelles dotées de plusieurs instances SGBD ne sont pas prises en charge avec les configurations haute disponibilité décrites ultérieurement dans ce document.
Instances de dialogue SAP multiples dans une machine virtuelle
Dans de nombreux cas, plusieurs instances de dialogue sont déployées sur des serveurs nus, voire sur des machines virtuelles s’exécutant dans des clouds privés. Ces configurations ont été conçues pour adapter certaines instances de dialogue SAP à plusieurs charges de travail, fonctionnalités métier ou types de charges de travail. Le fait de ne pas isoler ces instances dans des machines virtuelles distinctes était lié à la maintenance et au fonctionnement du système d’exploitation. En outre, dans de nombreux cas, cela relève des coûts mensuels de fonctionnement et d'administration demandés par l'hébergeur ou l'opérateur de la machine virtuelle. Dans Azure, il est possible d’héberger plusieurs instances de dialogue SAP dans une même machine virtuelle, à des fins de production et de non-production, sur les systèmes d’exploitation Windows, Red Hat, SUSE et Oracle Linux. Le paramètre de noyau SAP PHYS_MEMSIZE, disponible sur les noyaux Linux Windows et modernes, doit être défini si plusieurs instances SAP Application Server s’exécutent sur une même machine virtuelle. Il est également conseillé de limiter l’expansion de la mémoire étendue SAP sur les systèmes d’exploitation, comme sur Windows où la croissance automatique de la mémoire étendue SAP est implémentée. Cela peut se faire à l'aide du paramètre de profil SAP em/max_size_MB.
Une configuration à trois niveaux où plusieurs instances de dialogue SAP sont exécutées dans des machines virtuelles Azure peut se présenter comme suit :
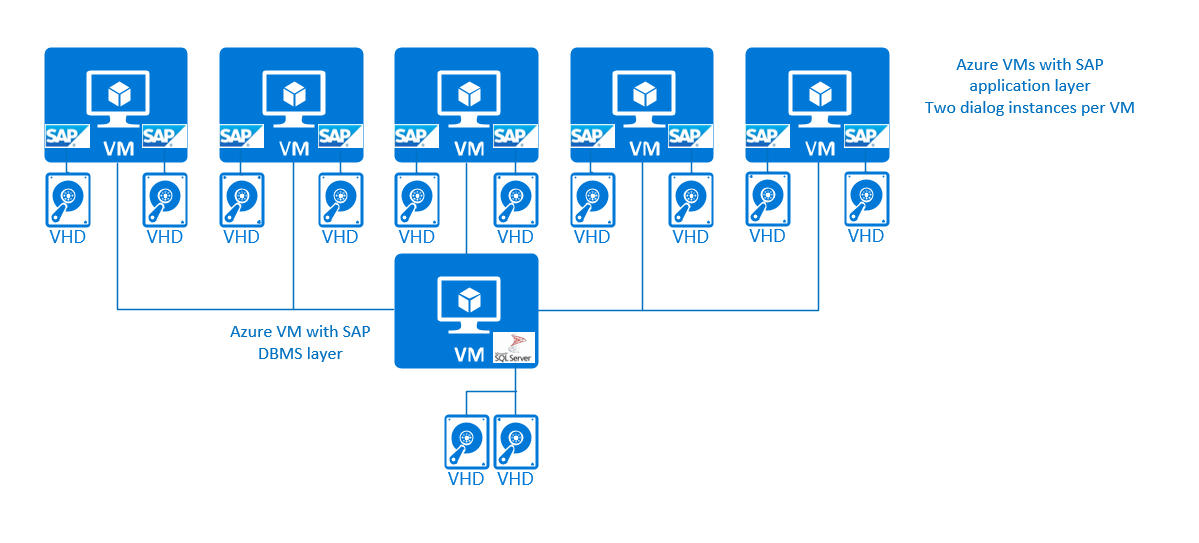
Dans un souci de simplification, nous n’avons pas fait la distinction entre les services centraux SAP et les instances de dialogue SAP dans la couche d’application SAP. Dans cette configuration simple à trois niveaux, aucune protection haute disponibilité n’est disponible pour les services centraux SAP. En ce qui concerne les systèmes de production, il est conseillé de protéger les services centraux SAP. Pour plus d'informations sur les configurations multi-SID liées aux instances de services centraux SAP et la haute disponibilité de telles configurations multi-SID, consultez les sections ultérieures de ce document.
Protection haute disponibilité pour la couche SGBD SAP
Lors du déploiement de systèmes de production SAP, vous devez prendre en compte le type de serveur de secours des configurations haute disponibilité. En particulier avec SAP HANA, où les données doivent être chargées en mémoire à des fins de performances optimales et d’extensibilité, le service de réparation Azure n’étant pas une mesure idéale en termes de haute disponibilité.
En général, Microsoft ne prend en charge que les configurations haute disponibilité et les packages logiciels décrits dans les scénarios de charge de travail SAP. Vous pouvez consulter la même instruction dans la note SAP n° 1928533. Microsoft ne fournit pas de prise en charge pour les autres frameworks logiciels tiers à haute disponibilité qui ne sont pas documentés par Microsoft avec la charge de travail SAP. Dans ce cas, le fournisseur tiers de l’infrastructure haute disponibilité est le tiers de prise en charge pour la configuration haute disponibilité que vous devez contacter en tant que client. Les exceptions seront mentionnées dans cet article.
En règle générale, Microsoft prend en charge un ensemble limité de configurations haute disponibilité sur les machines virtuelles Azure ou les unités de grandes instances HANA.
Pour les machines virtuelles Azure, les configurations haute disponibilité suivantes sont prises en charge au niveau SGBD :
- Réplication du système SAP HANA basé sur Linux Pacemaker sur SUSE et Red Hat. Consultez les articles détaillés :
- Configurations n+m scale-out SAP HANA utilisant Azure NetApp Files sur SUSE et Red Hat. Les détails sont répertoriés dans ces articles :
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur SUSE Linux Enterprise Server}
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur Red Hat Enterprise Linux
- Cluster de basculement SQL Server basé sur Windows Scale-Out File Services. En matière de systèmes de production, il est recommandé d'utiliser SQL Server Always On plutôt que le clustering. SQL Server Always On offre une meilleure disponibilité avec un stockage distinct. Les détails sont décrits dans cet article :
- SQL Server Always On est pris en charge avec le système d’exploitation Windows pour SQL Server sur Azure. Il s’agit de la configuration recommandée par défaut pour les instances SQL Server de production sur Azure. Les détails sont décrits dans ces articles :
- Oracle Data Guard pour Windows et Oracle Linux. Vous trouverez plus d’informations pour Oracle Linux dans cet article :
- La documentation détaillée IBM Db2 HADR sur SUSE et RHEL pour SUSE et RHEL à l’aide de Pacemaker est fournie ici :
- Configuration SAP ASE et SAP maxDB, comme indiqué dans les documents suivants :
- Les scénarios de haute disponibilité des grandes instances HANA sont détaillés dans :
Important
Pour aucun des scénarios décrits ci-dessus, nous prenons en charge les configurations de plusieurs instances SGBD dans une machine virtuelle. Ainsi, dans chaque cas, une seule instance de base de données peut être déployée par machine virtuelle et protégée à l'aide des méthodes de haute disponibilité décrites. Actuellement, la protection de plusieurs instances SGBD sous le même cluster de basculement Windows ou Pacemaker n'est PAS prise en charge. En outre, Oracle Data Guard est pris en charge pour une seule instance par cas de déploiement de machine virtuelle.
Différents systèmes de base de données autorisent l’hébergement de plusieurs bases de données sous une seule instance SGBD. Comme dans le cas de SAP HANA, plusieurs bases de données peuvent être hébergées dans plusieurs conteneurs de base de données. Dans les cas où ces configurations à plusieurs bases de données fonctionnent dans une ressource de cluster de basculement, ces configurations sont prises en charge. Les configurations qui ne sont pas prises en charge sont les cas où plusieurs ressources de cluster seraient nécessaires. Comme pour les configurations dans lesquelles vous définiriez plusieurs groupes de disponibilité SQL Server sous une seule instance de SQL Server.
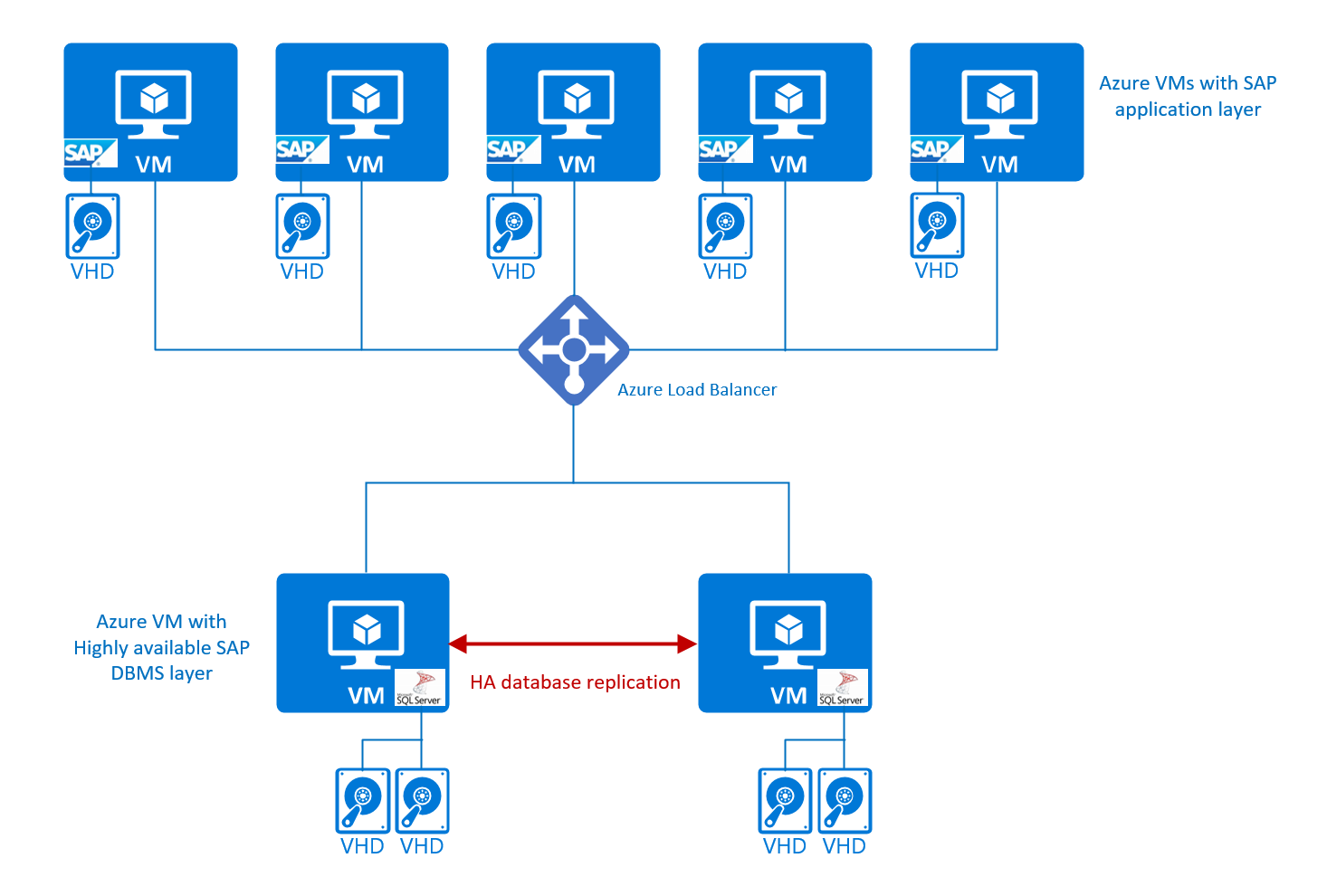
En fonction du SGBD et/ou des systèmes d’exploitation, des composants comme Azure Load Balancer peuvent s'avérer nécessaire dans le cadre de l’architecture de la solution.
Notamment pour maxDB, la configuration de stockage doit être différente. Avec maxDB, les données et fichiers journaux doivent être situés sur le stockage partagé pour les configurations haute disponibilité. Seulement pour maxDB, le stockage partagé est pris en charge pour la haute disponibilité. Pour tous les autres SGBD, les piles de stockage distinctes par nœud sont les seules configurations de disque prises en charge.
D’autres infrastructures haute disponibilité existent et s'exécutent également sur Microsoft Azure. Cela étant, Microsoft n’a pas testé ces infrastructures. Pour créer votre configuration à haute disponibilité avec ces frameworks, vous devez collaborer avec le fournisseur de ce logiciel afin de :
- Développement d'une architecture de déploiement
- Déploiement de l’architecture
- Prise en charge de l’architecture
Important
La Place de marché Microsoft Azure propose diverses appliances logicielles qui fournissent des solutions de stockage en plus du stockage Azure natif. Ces appliances logicielles peuvent être utilisées pour créer des partages NFS susceptibles d'être utilisés dans les déploiements scale-out SAP HANA où un nœud de secours est requis. Pour différentes raisons, aucune de ces appliances logicielles de stockage n’est prise en charge pour les déploiements SGBD par Microsoft et SAP sur Azure. À ce stade, les déploiements de SGBD sur des partages SMB ne sont pas pris en charge. Les déploiements de SGBD sur des partages NFS se limitent aux partages NFS 4.1 sur Azure NetApp Files.
Haute disponibilité pour services centraux SAP
Les services centraux SAP constituent un second point de défaillance unique de votre configuration SAP. Dès lors, il vous faut également protéger ces processus de services centraux. L’offre prise en charge et documentée pour les charges de travail SAP se présente comme suit :
- Serveur de cluster de basculement utilisant Windows Scale-out File Services pour sapmnt et le répertoire global transport. Les détails sont décrits dans l’article :
- Serveur de cluster de basculement Windows utilisant le partage SMB basé sur Azure NetApp Files pour sapmnt et le répertoire global transport. Les détails sont répertoriés dans l’article :
- Serveur de cluster de basculement Windows basé sur SIOS
Datakeeper. Bien qu'elle soit documentée par Microsoft, vous devez vous rapprocher de SIOS à des fins de support si vous utilisez cette solution. Les détails sont décrits dans l’article : - Pacemaker sur système d'exploitation SUSE avec création d'un partage NFS haute disponibilité utilisant deux machines virtuelles SUSE et
drdbpour la réplication de fichiers. Les détails sont documentés dans l’article - Système d’exploitation Pacemaker SUSE avec utilisation de partages NFS fournis par Azure NetApp Files. Les détails sont documentés dans
- Pacemaker sur système d’exploitation Red Hat avec partage NFS hébergé sur un cluster
glusterfs. Vous trouverez des détails dans les articles - Pacemaker sur système d’exploitation Red Hat avec partage NFS hébergé sur Azure NetApp Files. Les détails sont décrits dans l’article
Parmi les solutions répertoriées, il vous faut disposer d’un support auprès de SIOS pour prendre en charge le produit Datakeeper et vous rapprocher directement de SIOS en cas de problème. Selon votre licence Windows, Red Hat et/ou SUSE, vous pouvez être tenu de disposer d'un contrat de support auprès de votre fournisseur de système d’exploitation afin de pleinement bénéficier de la prise en charge des configurations haute disponibilité répertoriées.
La configuration peut également se présenter comme suit :
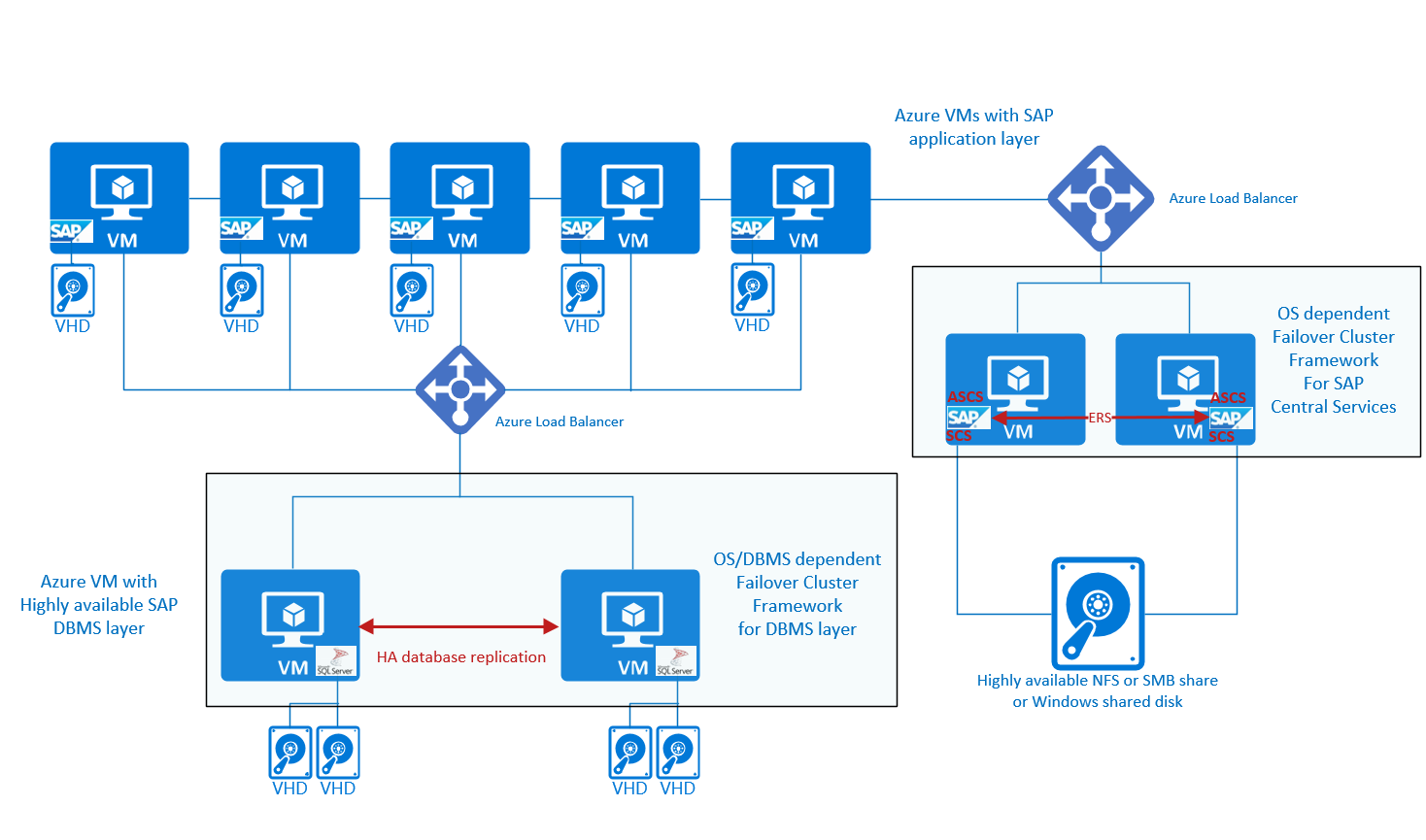
À droite du graphique, les services centraux SAP haute disponibilité s'affichent. En plus d’avoir les services centraux SAP protégés avec un framework de cluster de basculement pouvant basculer dans des scénarios d’échec, vous devez avoir un partage NFS ou SMB à haute disponibilité, ou un disque partagé Windows pour que le sapmnt et le répertoire de transport global soient disponibles même s’il n’y a qu’une seule machine virtuelle. D’autres solutions, comme le serveur de cluster de basculement Windows et Pacemaker, ont besoin d’un équilibreur de charge Azure pour diriger ou rediriger le trafic vers un nœud sain.
Dans la liste qui s’affiche, le système d’exploitation Oracle Linux n’est pas mentionné. Oracle Linux ne prend pas en charge Pacemaker en tant qu’infrastructure de cluster. Si vous souhaitez déployer votre système SAP sur Oracle Linux et devez disposer d’une infrastructure haute disponibilité pour Oracle Linux, il vous faut collaborer avec des fournisseurs tiers. L’un des fournisseurs est SIOS et sa Protection Suite pour Linux prise en charge par SAP sur Azure. Pour plus d’informations, consultez la note SAP n° 1662610 - Détails de prise en charge pour SIOS Protection Suite pour Linux.
Stockage pris en charge avec les scénarios de services centraux SAP répertoriés ci-dessus
Dans la mesure où seul un sous-ensemble de types de stockage Azure offre des partages NFS ou SMB haute disponibilité de qualité à des fins d’utilisation dans nos scénarios de cluster de services centraux SAP, voici une liste des types de stockage pris en charge.
- Le serveur de cluster de basculement Windows avec Windows Scale-out File Server peut être déployé sur tous les types de stockage Azure natifs, à l’exception d'Azure NetApp Files. Toutefois, il est recommandé d’utiliser Stockage Premium en raison de meilleurs contrats de niveau de service en matière de débit et d’IOPS.
- Le serveur de cluster de basculement Windows avec SMB sur Azure NetApp Files est pris en charge sur Azure NetApp Files. Les partages SMB hébergés sur les services de fichiers Azure Premium sont également pris en charge pour ce scénario. Azure Standard Files n’est pas pris en charge
- Le serveur de cluster de basculement Windows avec disque partagé Windows basé sur SIOS
Datakeeperpeut être déployé sur tous les types de stockage Azure natifs, à l’exception d'Azure NetApp Files. Toutefois, il est recommandé d’utiliser Stockage Premium en raison de meilleurs contrats de niveau de service en matière de débit et d’IOPS. - SUSE ou Red Hat Pacemaker avec partages NFS sur Azure NetApp Files est pris en charge.
- SUSE ou Red Hat Pacemaker utilisant des partages NFS sur Azure Premium Files à l’aide de LRS ou de ZRS pris en charge. Azure Standard Files n’est pas pris en charge
- SUSE Pacemaker avec configuration
drdbentre deux machines virtuelles est pris en charge à l’aide des types de stockage Azure natifs, à l’exception d'Azure NetApp Files. Toutefois, nous vous recommandons d’utiliser l’un des services internes avec Azure Premium Files ou Azure NetApp Files. - Red Hat Pacemaker avec
glusterfspour fournir un partage NFS est pris en charge à l’aide des types de stockage Azure natifs, à l’exception d'Azure NetApp Files. Toutefois, nous vous recommandons d’utiliser l’un des services internes avec Azure Premium Files ou Azure NetApp Files.
Important
La Place de marché Microsoft Azure propose diverses appliances logicielles qui fournissent des solutions de stockage en plus du stockage Azure natif. Ces appliances logicielles de stockage permettent de créer des partages SMB ou NFS, qui peuvent théoriquement être utilisés dans les services centraux SAP de cluster de basculement. Ces solutions ne sont pas directement prises en charge pour la charge de travail SAP par Microsoft. Si vous décidez d’utiliser une telle solution pour créer votre partage NFS ou SMB, la prise en charge de la configuration des services centraux SAP doit être fournie par le tiers propriétaire du logiciel dans l’appliance logicielle de stockage.
Clusters de basculement des services centraux SAP multi-SID
Pour réduire le nombre de machines virtuelles nécessaires dans les grands paysages SAP, SAP permet d’exécuter des instances des services centraux SAP de plusieurs systèmes SAP différents dans une configuration de cluster de basculement. Il peut s’agir de cas où vous disposez de 30 systèmes de production NetWeaver ou S/4HANA, voire plus. Sans clustering multi-SID, ces configurations nécessiteraient un minimum de 60 machines virtuelles dans 30 configurations de cluster de basculement Windows ou Pacemaker, voire plus. Le déploiement de plusieurs services centraux SAP sur deux nœuds dans une configuration de cluster de basculement permet de réduire considérablement le nombre de machines virtuelles. Cela étant, le déploiement de plusieurs instances de services centraux SAP sur une seule configuration de cluster à deux nœuds présente également quelques inconvénients. Les problèmes liés à une machine virtuelle unique dans la configuration du cluster s’appliquent à plusieurs systèmes SAP. La maintenance du système d’exploitation invité qui s’exécute dans la configuration de cluster requiert plus de coordination car plusieurs systèmes SAP de production sont affectés. Les outils tels que SAP LaMa ne prennent pas en charge le clustering multi-SID dans leur processus de clonage de système.
Sur Azure, une configuration de cluster multi-SID est prise en charge pour le système d’exploitation Windows avec ENSA1 et ENSA2. Il est déconseillé de combiner la précédente architecture Enqueue Replication Service (ENSA1) avec la nouvelle architecture (ENSA2) sur un cluster multi-SID. Les détails relatifs à une tel architecture sont fournis dans ces articles :
- Haute disponibilité multi-SID pour une instance SAP ASCS/SCS avec le clustering de basculement Windows Server et un disque partagé sur Azure
- Haute disponibilité multi-SID pour une instance SAP ASCS/SCS avec le clustering de basculement Windows Server et le partage de fichiers sur Azure
Pour SUSE, un cluster multi-SID basé sur Pacemaker est également pris en charge. Actuellement, la configuration est prise en charge pour :
- Un maximum de cinq instances SAP ASCS/SCS
- La précédente architecture Enqueue Replication Server (ENSA1)
- Les configurations de cluster Pacemaker à deux nœuds
La configuration est documentée dans Guide de haute disponibilité multi-SID pour SAP NetWeaver sur les machines virtuelles Azure sur SUSE Linux Enterprise Server pour les applications SAP
Un cluster multi-SID avec Enqueue Replication Server se présente schématiquement comme suit
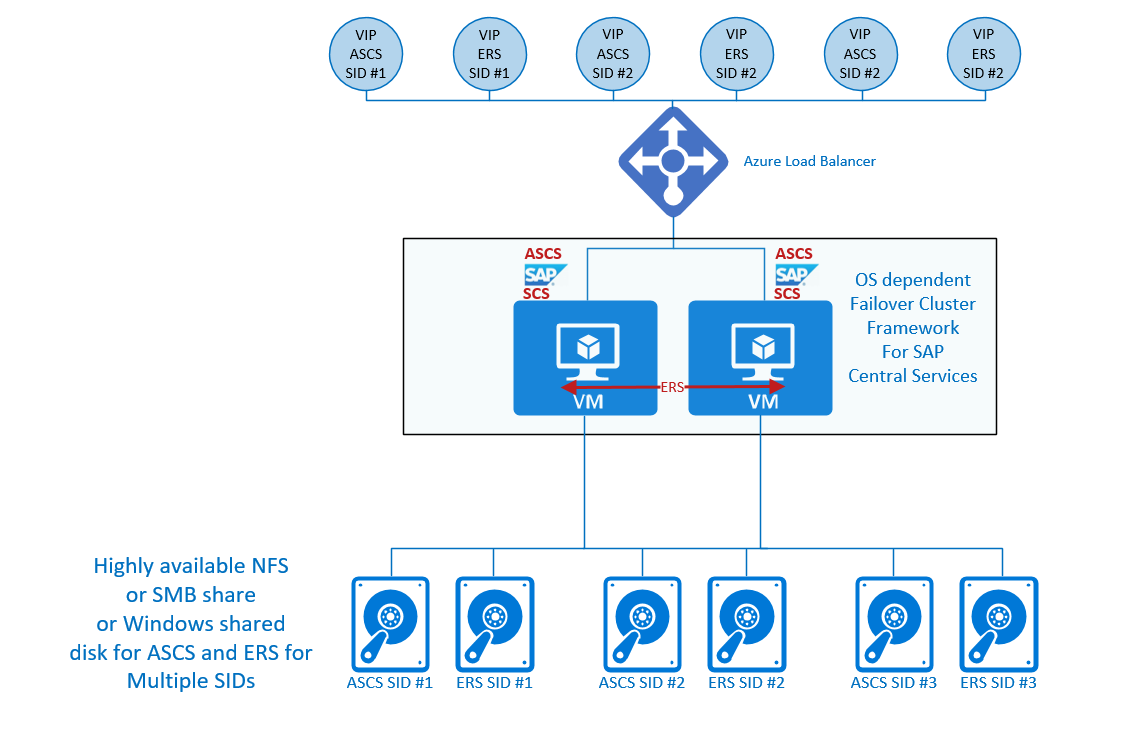
Scénarios de scale-out SAP HANA
Les scénarios de scale-out SAP HANA sont pris en charge pour un sous-ensemble des machines virtuelles Azure certifiées HANA listées dans le répertoire matériel SAP HANA. Toutes les machines virtuelles accompagnées de « oui » dans la colonne « clustering » peuvent être utilisées à des fins de scale-out OLAP ou S/4HANA. Les configurations sans nœud de secours sont prises en charge avec les types de Stockage Azure :
- Stockage Premium Azure v1, y compris l’accélérateur d’écriture Azure pour le volume /hana/log
- Stockage Premium Azure v2
- Disque Ultra
- Azure NetApp Files
Les configurations scale-out SAP HANA pour OLAP ou S/4HANA sans nœud de secours sont uniquement prises en charge avec partages NFS hébergés sur Azure NetApp Files.
Pour plus d’informations sur les configurations de stockage exactes avec ou sans nœud de secours, consultez les articles suivants :
- Configurations du stockage des machines virtuelles SAP HANA Azure
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur SUSE Linux Enterprise Server
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur Red Hat Enterprise Linux
- Note de support SAP n° 2080991
Scénario de récupération d'urgence
Plusieurs scénarios de récupération d’urgence sont pris en charge. Nous entendons par architectures de récupération d’urgence les architectures amenées à compenser la déconnexion d’une région Azure complète. Ainsi, la cible de récupération d'urgence doit se trouver dans une région Azure différente pour exécuter votre paysage SAP. Nous séparons les méthodes et configurations en couche SGBD et couche non-SGBD.
Couche SGBD
Pour la couche SGBD, les configurations utilisant les mécanismes de réplication natifs SGBD, comme Always On, Oracle Data Guard, Db2 HADR, SAP ASE Always on ou HANA System Replication sont pris en charge. Dès lors, il est impératif que le flux de réplication soit asynchrone plutôt que synchrone, comme dans les scénarios haute disponibilité classiques déployés dans une seule région Azure. Un exemple type de configuration de récupération d’urgence SGBD prise en charge est décrit dans l’article Disponibilité de SAP HANA dans l’ensemble des régions Azure. Le deuxième graphique de cette section décrit un scénario avec HANA à titre d'exemple. Les principales bases de données prises en charge pour les applications SAP peuvent toutes être déployées dans un tel scénario.
L’utilisation d’une machine virtuelle plus petite comme instance cible dans la région de récupération d’urgence est prise en charge, car cette machine virtuelle ne se heurte pas à tout le trafic de charge de travail. Ce faisant, vous devez garder à l’esprit les points suivants :
- Les types de machines virtuelles plus petites n’autorisent pas autant de disques
- Les machines virtuelles plus petites ont moins de débit réseau et de stockage
- Le redimensionnement entre familles VM peut poser un problème quand les différentes machines virtuelles sont collectées dans un groupe à haute disponibilité Azure ou quand le redimensionnement doit se produire entre des familles VM des séries M et Mv2
- Consommation d’UC et de mémoire de l’instance de base de données capable de recevoir le flux de modifications avec un délai minimal, et ressources d'UC et de mémoire suffisantes pour appliquer ces modifications aux données avec un délai minimal
Vous trouverez plus d’informations sur les limites des différentes tailles de machines virtuelles sur la page Tailles des machines virtuelles.
Une autre méthode prise en charge à des fins de déploiement d'une cible de récupération d'urgence consiste à installer une seconde instance SGBD exécutant une instance SGBD non-production d’une instance SAP non-production. Cela peut s'avérer plus complexe car vous devez déterminer la mémoire, les ressources d'UC, la bande passante réseau et la bande passante de stockage nécessaires pour les instances cibles spécifiques censées fonctionner en tant qu’instance principale dans le scénario de récupération d’urgence. En particulier dans HANA, il vous est vivement recommandé de configurer l’instance fonctionnant en tant que cible de récupération d’urgence sur un hôte partagé de manière à ce que les données ne soient pas préchargées dans l’instance cible de récupération d’urgence.
Notes
L’utilisation d'Azure Site Recovery n’a pas été testée dans le cadre de déploiements SGBD avec charge de travail SAP. Dès lors et à ce stade, elle n’est pas prise en charge pour la couche SGBD des systèmes SAP. Les autres méthodes de réplication par Microsoft et SAP non répertoriées ne sont pas prises en charge. L’utilisation de logiciels tiers à des fins de réplication de la couche SGBD des systèmes SAP entre différentes régions Azure doit être prise en charge par le fournisseur du logiciel, et n’est pas prise en charge par le biais des canaux de support Microsoft et SAP.
Couche non-SGBD
Pour la couche application SAP, et les éventuels partages ou emplacements de stockage qui sont nécessaires, les deux principaux scénarios sont utilisés par les clients :
- Les cibles de récupération d’urgence de la deuxième région Azure ne sont pas utilisées à des fins de production ou de non-production. Dans ce scénario, les machines virtuelles fonctionnant en tant que cibles de récupération d’urgence ne sont pas idéalement déployées et l'image, de même que les modifications apportées aux images de la couche d'application SAP de production, sont répliquées dans la région de récupération d’urgence. Azure Site Recovery permet d'effectuer une telle tâche. Azure Site Recovery prend en charge les scénarios de réplication Azure vers Azure tels que celui-ci.
- Les cibles de récupération d’urgence sont des machines virtuelles utilisées par des systèmes de non-production. L’intégralité du paysage SAP est répartie entre deux régions Azure différentes, les systèmes de production généralement situés dans une région et les systèmes de non-production dans une autre. Dans de nombreux déploiements clients, le client dispose d’un système de non production qui équivaut à un système de production. Le client dispose d'instances d’application de production préinstallées sur les systèmes de non-production de la couche d'application. En cas de basculement, les instances de non-production sont arrêtées, les noms virtuels des machines virtuelles de production sont déplacés vers les machines virtuelles de non-production (après attribution de nouvelles adresses IP dans DNS) et les instances de production préinstallées sont démarrées
Clusters des services centraux SAP
Les clusters des services centraux SAP utilisant des disques partagés (Windows), des partages SMB (Windows) ou des partages NFS sont un peu plus difficiles à répliquer. Pour Windows, Windows Storage Replication est une solution possible. Pour Linux, rsync est une solution viable. La réplication inter-région d’Azure NetApp Files est également une solution viable.
Scénarios non pris en charge
Il existe une liste de scénarios non pris en charge pour la charge de travail SAP sur les architectures Azure. Non pris en charge signifie que SAP et Microsoft ne peuvent pas prendre en charge ces configurations et que vous devez consulter le tiers ayant éventuellement fourni les logiciels pour établir ce type d’architectures. Deux des catégories sont les suivantes :
- Appliances logicielles de stockage : il existe plusieurs appliances logicielles de stockage sur le marché. Certains fournisseurs proposent une documentation relative à l’utilisation de ces appliances logicielles de stockage sur Azure en lien avec les logiciels SAP. La prise en charge des configurations ou des déploiements impliquant ce type d’appliances logicielles de stockage doit être assurée par le fournisseur de ces appliances. Cela est aussi documenté dans la note de support SAP n° 2015553
- Infrastructures haute disponibilité : Seuls Pacemaker et le cluster de basculement Windows Server sont pris en charge pour la charge de travail SAP sur Azure. Comme indiqué précédemment, la solution de SIOS
Datakeeperest décrite et documentée par Microsoft. Cela étant, les composants de la SIOSDatakeeperdoivent être pris en charge par le fournisseur qui met à disposition ces composants. SAP a également répertorié d’autres infrastructures haute disponibilité certifiées dans diverses notes SAP. Plusieurs d’entre elles ont aussi été certifiées par le fournisseur tiers pour Azure. Toutefois, la prise en charge des configurations utilisant ces produits doit être assurée par le fournisseur du produit. Les différents fournisseurs ont une intégration différente dans les processus de prise en charge SAP. Il vous appartient de vérifier le processus de prise en charge d’un fournisseur spécifique avant de choisir d’utiliser son produit dans des configurations SAP déployées sur Azure. - Les clusters de disques partagés dont les fichiers de base de données résident sur les disques partagés ne sont pas pris en charge, à l’exception de maxDB. Pour toutes les autres bases de données, la solution prise en charge consiste à disposer d’emplacements de stockage distincts plutôt que d’un partage SMB ou NFS ou d’un disque partagé pour configurer des scénarios haute disponibilité.
D’autres scénarios ne sont pas pris en charge, notamment :
- Scénarios de déploiement présentant une plus grande latence réseau entre la couche application SAP et la couche SGBD SAP comme dans NetWeaver, S/4HANA et, par exemple,
Hybris. Cela inclut les éléments suivants :- Déploiement de l’un des niveaux localement, tandis que l’autre niveau est déployé dans Azure
- Déploiement du niveau d'application SAP d’un système dans une région Azure différente de celle du niveau SGBD
- Déploiement d’une couche dans des centres de donnés colocalisés dans Azure et de l’autre couche dans Azure, sauf si ce type de modèle d’architecture est fourni par un service Azure natif
- Déploiement d’appliances virtuelles réseau entre le niveau d'application SAP et la couche SGBD
- Utilisation du stockage hébergé dans des centres de données colocalisés dans le centre de données Azure pour la couche SGBD SAP ou le répertoire de transport global SAP
- Déploiement des deux couches avec deux fournisseurs de cloud différents. Par exemple, le déploiement du niveau SGBD dans Oracle Cloud Infrastructure et le niveau d'application dans Azure
- Configurations de cluster Pacemaker HANA multi-instance
- Configurations de cluster Windows avec disques partagés via SOFS ou SMB sur ANF pour les bases de données SAP prises en charge sur Windows. Nous recommandons plutôt le recours à la réplication haute disponibilité native des bases de données spécifiques et aux piles de stockage distinctes.
- Déploiement de bases de données SAP prises en charge sur Linux avec des fichiers de base de données situés dans des partages NFS en plus d’ANF, à l’exception de SAP HANA, d’Oracle sur Oracle Linux et de Db2 sur Suse et Red Hat
- Déploiement du SGBD Oracle sur tout système d’exploitation invité autre que Windows et Oracle Linux. Voir aussi Note de support SAP n° 2039619
Scénario(s) que nous n’avons pas testés et sur lesquels nous n’avons pas encore d’expérience, notamment :
- Azure Site Recovery répliquant des machines virtuelles de couche SGBD. Par conséquent, nous vous recommandons d’utiliser la fonctionnalité de réplication de base de données asynchrone native pour configurer la reprise d’activité
Étapes suivantes
Découvrez les étapes suivantes dans Planification et implémentation de machines virtuelles Azure pour SAP NetWeaver
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour