Disponibilité de SAP HANA au sein d’une région Azure
Cet article décrit plusieurs scénarios de disponibilité pour SAP HANA au sein d’une région Azure. Azure dispose de plusieurs régions, réparties à travers le monde. Pour obtenir la liste des régions Azure, voir Régions Azure. Pour le déploiement de SAP HANA sur des machines virtuelles au sein d’une région Azure, Microsoft offre le déploiement d’une machine virtuelle unique avec une instance HANA. Pour une plus grande disponibilité, vous pouvez déployer deux machines virtuelles avec deux instances HANA en utilisant un groupe identique flexible avec FD=1, des zones de disponibilité ou un groupe à haute disponibilité qui utilise la réplication du système HANA pour la disponibilité.
Les régions Azure qui fournissent des zones de disponibilité se composent de plusieurs centres de données, chacun avec sa propre source d’alimentation, son propre système de refroidissement et sa propre infrastructure réseau. Le but de proposer différentes zones au sein d’une même région Azure est de vous permettre de déployer des applications sur deux ou trois zones de disponibilité disponibles. En distribuant le déploiement de votre application sur plusieurs zones, aucun problème de réseau ou d’alimentation affectant une infrastructure de zone de disponibilité Azure spécifique ne perturbe complètement les fonctionnalités de votre application dans la région Azure. Même s’il peut y avoir une baisse de capacité, par exemple la perte potentielle de machines virtuelles dans une zone, les machines virtuelles des zones restantes continuent de fonctionner sans interruption. Pour configurer deux instances HANA sur des machines virtuelles distinctes couvrant différentes zones, vous avez la possibilité de déployer des machines virtuelles en utilisant l’option de déploiement de groupe identique flexible avec FD=1 ou de zones de disponibilité.
Pour une plus grande disponibilité au sein d’une région, il est conseillé de déployer deux machines virtuelles avec deux instances HANA en utilisant un groupe à haute disponibilité. Un groupe à haute disponibilité Azure est une fonctionnalité de regroupement logique qui garantit que les ressources de machine virtuelle configurées dans un groupe à haute disponibilité sont isolées les unes des autres en cas de panne lorsqu’elles sont déployées dans un centre de données Azure. Azure veille à ce que les machines virtuelles que vous placez dans un groupe à haute disponibilité s’exécutent sur plusieurs serveurs physiques, racks de calcul, unités de stockage et commutateurs réseau. Dans certaines documentations Azure, cette configuration est considérée comme des placements dans différents Mise à jour et domaines d’erreur. En règle générale, ces placements se trouvent dans un centre de données Azure. En imaginant que des problèmes d’alimentation et de réseau affectent le centre de données que vous déployez, toutes vos capacités dans une région Azure seraient aussi affectées.
Le placement des centres de données représentant les zones de disponibilité Azure est un compromis entre une latence réseau entre des services déployés dans différentes zones et une distance spécifique entre des centres de données. Idéalement, les catastrophes naturelles n’affectent pas l’alimentation, le réseau et l’infrastructure de toutes vos zones de disponibilité dans cette région. Toutefois, comme nous l’avons déjà vu avec des catastrophes naturelles d’envergure, les zones de disponibilité peuvent ne pas fournir autant de disponibilité que vous le souhaitez au sein d’une région. Pensez à l’ouragan Maria qui a touché l’ile de Porto Rico le 20 septembre 2017. L’ouragan a entrainé une coupure de courant de la quasi-totalité de cette ile de 145 kilomètres.
Scénario de machine virtuelle unique
Dans un scénario de machine virtuelle unique, vous créez une machine virtuelle Azure pour l’instance SAP HANA. Vous utilisez le stockage Premium Azure pour héberger le disque du système d’exploitation et tous vos disques de données. Le contrat SLA de disponibilité de 99,9 % d’Azure et les contrats SLA d’autres composants Azure vous suffisent à réaliser vos contrats SLA de disponibilité pour vos clients. Dans ce scénario, vous n’avez pas besoin d’utiliser un groupe à haute disponibilité Azure pour les machines virtuelles qui exécutent la couche SGBD. Dans ce scénario, vous vous appuyez sur deux fonctionnalités :
- Redémarrage automatique des machines virtuelles Azure (aussi appelé réparation de services Azure)
- Redémarrage automatique de SAP HANA
Le redémarrage automatique de machine virtuelle Azure, ou Service Healing, est une fonctionnalité Azure qui fonctionne sur deux niveaux :
- L’hôte serveur Azure vérifie l’intégrité d’une machine virtuelle hébergée sur le serveur hôte.
- Le contrôleur de structure Azure surveille l’intégrité et la disponibilité du serveur hôte.
Une fonctionnalité d’analyse de l’intégrité surveille l’intégrité de chaque machine virtuelle hébergée sur un serveur hôte Azure. Si une machine virtuelle passe en état défaillant, un redémarrage peut être initié par l’agent hôte Azure qui vérifie l’intégrité de la machine virtuelle. Le contrôleur de structure vérifie l’intégrité de l’hôte en vérifiant les nombreux paramètres qui peuvent indiquer des problèmes avec le matériel hôte. Il vérifie également l’accessibilité de l’hôte via le réseau. Une indication de problèmes avec l’hôte peut entraîner les événements suivants :
- Si l’hôte signale un état défaillant, un redémarrage de l’hôte et des machines virtuelles exécutées sur l’hôte est déclenché.
- Si l’hôte n’est pas dans un état sain après un redémarrage réussi, un redéploiement des machines virtuelles qui se trouvaient à l’origine sur le nœud devenu non sain sur un serveur hôte sain est lancé. Dans ce cas, l’hôte d’origine est marqué comme défaillant. Il ne sera pas utilisé pour des déploiements ultérieurs jusqu'à ce qu’il soit effacé ou remplacé.
- Si l’hôte non sain rencontre des problèmes pendant le processus de redémarrage, un redémarrage immédiat des machines virtuelles sur un hôte sain est déclenché.
Avec la surveillance d’hôte et de machine virtuelle fournie par Azure, les machines virtuelles Azure qui subissent des problèmes d’hôte sont automatiquement redémarrées sur un hôte Azure intègre.
Important
La réparation des services Azure ne redémarre pas les machines virtuelles Linux où le système d’exploitation invité est affecté par une alerte sur le noyau. Les paramètres par défaut des versions de Linux couramment utilisées n’autorisent pas redémarrer automatiquement les machines virtuelles ou le serveur contenant un noyau Linux en alerte. Le paramétrage par défaut prévoit au contraire de maintenir le système d’exploitation dans un état d’alerte du noyau pour pouvoir y attacher un débogueur du noyau et procéder à des analyses. Azure suit ce comportement en ne redémarrant pas automatiquement une machine virtuelle dont le système d’exploitation invité est dans cet état. Nous partons de l’hypothèse que de tels événements sont extrêmement rares. Vous pouvez remplacer le comportement par défaut pour permettre un redémarrage de la machine virtuelle. Pour modifier le comportement par défaut, activez le paramètre « kernel.panic » dans /etc/sysctl.conf. La durée pour ce paramètre est en secondes. Les valeurs recommandées courantes sont d’attendre 20 à 30 secondes avant de déclencher le redémarrage via ce paramètre. Pour plus d'informations, consultez sysctl.conf.
La deuxième fonctionnalité sur laquelle vous pouvez vous appuyer dans un tel scénario est le redémarrage automatique du service HANA qui s’exécute dans une machine virtuelle après qu’elle ait été redémarrée. Vous pouvez configurer le redémarrage automatique de service HANA via les services de surveillance des différents services HANA.
Vous pouvez améliorer ce scénario de machine virtuelle unique en ajoutant un nœud de basculement froid à une configuration SAP HANA. Dans la documentation de SAP HANA, cette configuration est appelée Basculement automatique d’hôtes. Cette configuration peut s’avérer utile dans une situation de déploiement local, où le matériel de serveur est limité et où vous dédiez un seul nœud de serveur comme nœud de basculement automatique d’hôtes pour un ensemble d’hôtes de production. Dans Azure par contre, où l’infrastructure sous-jacente fournit un serveur cible sain pour un redémarrage réussi d’une machine virtuelle, le déploiement du basculement automatique d’hôtes de SAP HANA n’est pas utile. La présence de la réparation de services Azure fait qu’il n’existe aucune architecture de référence qui prévoit un nœud de secours pour le basculement automatique d’hôtes SAP HANA.
Cas spécial des configurations de scale-out SAP HANA dans Azure
Les architectures de haute disponibilité basées sur le nœud de secours ou la réplication du système HANA sont disponibles dans les documents suivants. Dans les cas où la haute disponibilité des nœuds de secours ou de la réplication du système HANA n’est pas utilisée dans les configurations de scale-out de SAP HANA, vous pouvez compter sur les fonctionnalités de réparation de services des machines virtuelles Azure et sur le redémarrage automatique de l’instance SAP HANA une fois que la machine virtuelle redevient opérationnelle.
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
Scénarios de disponibilité pour deux machines virtuelles différentes
Pour garantir la disponibilité du système HANA dans une région spécifique, vous avez la possibilité de configurer deux machines virtuelles dans les zones de disponibilité de la région ou au sein de la région. Pour atteindre cet objectif, vous pouvez configurer les machines virtuelles en utilisant l’option de déploiement de groupe identique flexible, de zones de disponibilité ou de groupe à haute disponibilité. L’installation de base dans Azure ressemble à ceci :
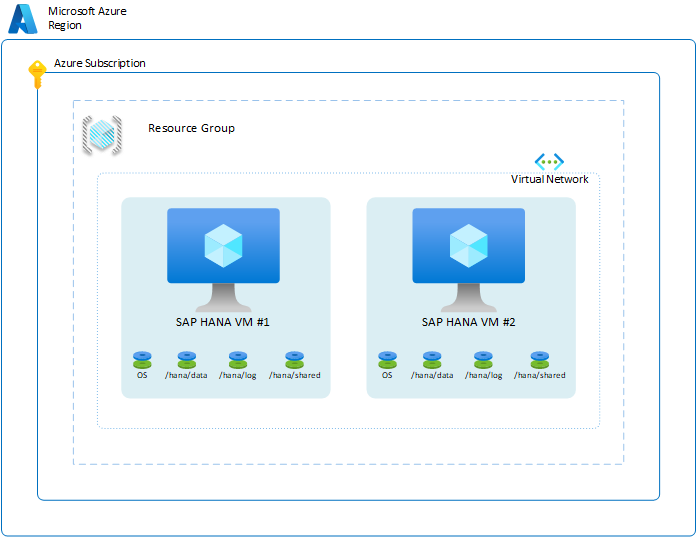
Pour illustrer les différents scénarios de disponibilité SAP HANA, quelques-unes des couches sont omises dans le diagramme. Le diagramme montre uniquement les couches qui décrivent les machines virtuelles, les hôtes, les groupes à haute disponibilité et les régions Azure. Des instances de Azure Virtual Network, des groupes de ressources et des abonnements ne jouent pas un rôle dans les scénarios décrits dans cette section.
Répliquer des sauvegardes vers une seconde machine virtuelle
L’une des configurations les plus rudimentaires consiste à utiliser des sauvegardes. En particulier, vous pouvez avoir des sauvegardes des journaux des transactions depuis une machine virtuelle vers une autre machine virtuelle Azure. Vous pouvez choisir le type de stockage Azure. Dans cette configuration, vous êtes chargé de scripter la copie des sauvegardes planifiées qui sont effectuées dans la première machine virtuelle sur la seconde. Si vous devez utiliser les instances de la seconde machine virtuelle, vous devez restaurer les sauvegardes complètes différentielles/incrémentielles et de fichier journal à l’endroit requis.
L’architecture ressemble à ceci :
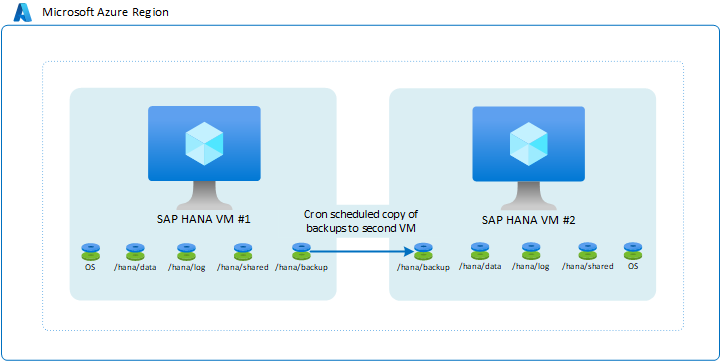
Cette configuration n’est pas bien adaptée pour réaliser de très bons temps d’objectif de point de récupération (RPO) et d’objectif de délai de récupération (RTO). Les temps de RTO, plus particulièrement, souffriraient en raison du besoin de restaurer entièrement toute la base de données à l’aide des sauvegardes copiées. Toutefois, cette configuration est utile pour récupérer d’une suppression de données involontaire sur les instances principales. Avec cette configuration, vous êtes en mesure de restaurer à un certain point dans le temps, d’extraire les données et d’importer les données supprimées dans votre instance principale en tout temps. Ainsi, il est peut-être logique d’utiliser une méthode de copie de sauvegarde avec d’autres fonctionnalités de haute disponibilité.
Pendant la copie des sauvegardes, vous serez peut-être en mesure d’utiliser une machine virtuelle plus petite autre que la machine virtuelle principale qui exécute l’instance SAP HANA. Gardez à l’esprit que vous pouvez attacher un plus petit nombre de disques durs virtuels sur les machines virtuelles plus petites. Pour plus d’information sur les limites des types de machines virtuelles individuelles, consultez Tailles des machines virtuelles Linux dans Azure.
Réplication de système SAP HANA sans basculement automatique
Les scénarios décrits dans cette section utilisent la réplication du système SAP HANA. Pour obtenir la documentation de SAP, consultez Réplication du système. Les scénarios sans basculement automatique ne sont pas courants pour les configurations au sein d’une seule région Azure. Une configuration sans basculement automatique, même si elle vous évite de configurer Pacemaker, vous oblige de procéder à une surveillance et un basculement manuels. Cela prend du temps et de l’énergie, c’est pourquoi la plupart des clients utilisent plutôt la réparation des services Azure. Il existe quelques cas extrêmes où cette configuration peut être utile en termes de scénarios d’échec. Ou, dans certains cas, un client peut souhaiter plus d’efficacité.
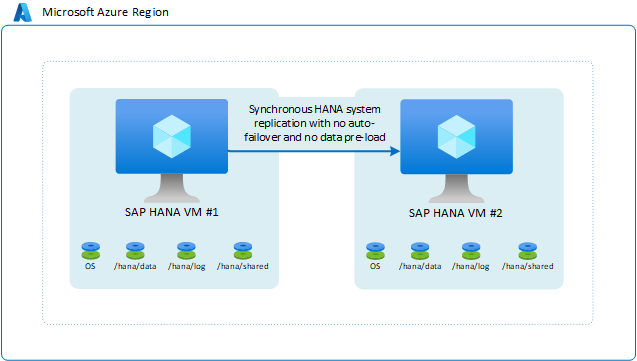
Réplication de système SAP HANA sans basculement automatique ni données pré-chargées
Dans ce scénario, vous utilisez la réplication du système SAP HANA pour déplacer des données de façon synchrone pour atteindre un RPO à 0. En revanche, vous disposez d’un RTO suffisamment long pour ne pas avoir besoin du basculement ou du préchargement des données dans le cache d’instance HANA. Dans ce cas, il est possible de réaliser des économies plus importantes dans votre configuration en effectuant les actions suivantes :
- Exécuter une autre instance SAP HANA dans la deuxième machine virtuelle. L’instance SAP HANA dans la deuxième machine virtuelle utilise une grande partie de la mémoire de la machine virtuelle. Dans le cas d’un basculement vers la deuxième machine virtuelle, vous devez arrêter l’instance SAP HANA en cours d’exécution qui charge les données dans la deuxième machine virtuelle, afin que les données répliquées puissent être chargées dans le cache de l’instance HANA ciblée dans la deuxième machine virtuelle.
- Utilisez une taille de machine virtuelle réduite pour la deuxième machine virtuelle. Si un basculement se produit, vous disposez d’une étape supplémentaire avant le basculement manuel. Dans cette étape, vous redimensionnez la machine virtuelle à la taille de la machine virtuelle source.
Le scénario ressemble à ceci :
Remarque
Même si vous n’utilisez pas le préchargement de données dans la cible de réplication du système HANA, vous avez besoin d’au moins 64 Go de mémoire. Vous avez également besoin de suffisamment de mémoire en plus des 64 Go pour conserver les données de stockage de lignes dans la mémoire de l’instance cible.
Réplication de système SAP HANA sans basculement automatique et avec des données pré-chargées
Dans ce scénario, les données répliquées vers l’instance HANA dans la deuxième machine virtuelle sont préchargées. Cela élimine les deux avantages de l’absence de préchargement des données. Dans ce cas, vous ne pouvez pas exécuter d’autres systèmes SAP HANA sur la deuxième machine virtuelle, Vous ne pouvez pas utiliser une taille de machine virtuelle réduite. Par conséquent, les clients implémentent rarement ce scénario.
Réplication de système SAP HANA avec basculement automatique
Dans la configuration de disponibilité standard, qui est la plus courante au sein d’une région Azure, deux machines virtuelles Azure exécutant Linux avec des packages HA disposent d’un cluster de basculement défini. Le cluster Linux HA est basé sur l’infrastructure Pacemaker utilisant SLES ou RHEL avec fencing device SLES ou RHEL comme exemple.
Côté SAP HANA, le mode de réplication utilisé est synchronisé et un basculement automatique est configuré. Dans la deuxième machine virtuelle, l’instance SAP HANA agit comme un nœud de serveur de secours. Le nœud de serveur de secours reçoit un flux de données synchrone d’enregistrements de modification depuis l’instance de SAP HANA principale. Tandis que les transactions sont acceptées par l’application au nœud HANA principal, ce dernier attend la confirmation de réception de l’enregistrement de la part du nœud SAP HANA secondaire avant de confirmer la réception à l’application. SAP HANA dispose de deux modes de réplication synchrone différents. Pour en savoir plus et pour connaître les différences entre les deux modes de réplication synchrone, consultez l’article SAP Modes de réplication pour la réplication de système SAP HANA.
La configuration générale ressemble à ceci :
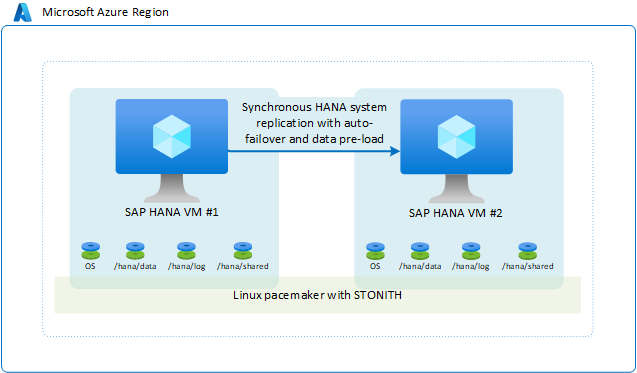
Vous pouvez choisir cette solution parce qu’elle vous permet d’obtenir un objectif RPO égal à 0 et un objectif RTO bas. Configurez la connectivité du client SAP HANA de façon à ce que les clients SAP HANA utilisent l’adresse IP virtuelle pour se connecter à la configuration de réplication de système HANA. Cette configuration évite de reconfigurer l’application en cas de basculement sur le nœud secondaire. Dans ce scénario, les références SKU de machine virtuelle Azure pour les machines virtuelles principales et secondaires doivent être identiques.
Étapes suivantes
Pour obtenir des instructions sur la mise en place de ces configurations dans Azure, consultez :
- Installer la réplication de système SAP HANA sur des machines virtuelles Azure
- Haute disponibilité de SAP HANA sur des machines virtuelles Azure
Pour plus d’informations sur la disponibilité SAP HANA dans l’ensemble des régions Azure, consultez :