Créer une requête de texte intégral dans la Recherche Azure AI
Si vous créez une requête pour la recherche en texte intégral, cet article décrit les étapes de configuration de la demande. Il introduit également une structure de requête et explique comment les attributs de champ et les analyseurs linguistiques peuvent affecter les résultats des requêtes.
Prérequis
Un Index de recherche avec des champs de chaîne attribués comme pouvant faire l’objet d’une recherche.
Des autorisations de lecture sur le service de recherche. Pour l’accès en lecture, ajoutez une clé API de requête sur la demande ou accordez à l’appelant des autorisations de Lecteur de données d’index de recherche.
Exemple de demande de requête de texte intégral
Dans la Recherche Azure AI, une requête est une demande en lecture seule sur la collection de documents d’un seul index de recherche, avec des paramètres qui informent l’exécution de la requête et forment la réponse.
Une requête de texte intégral est spécifiée dans un paramètre search et se compose de termes, d’expressions entre guillemets et d’opérateurs. Les autres paramètres servent à définir davantage la demande.
L'appelAPI REST POST Recherche suivant illustre une demande de requête à l’aide des paramètres mentionnés.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": 10,
"count": true
}
Points clés
searchfournit le critère de correspondance, généralement des termes ou expressions, avec ou sans opérateurs. Tout champ attribué en tant que champ avec possibilité de recherche dans le schéma d’index peut être utilisé avec ce paramètre.queryTypedéfinit l’analyseur : simple, complet. L’analyseur de requête simple par défaut est optimal pour la recherche en texte intégral. L’analyseur de requête Lucene complet convient pour les constructions de requête avancées comme les expressions régulières, la recherche de proximité, la recherche approximative et la recherche par caractères génériques. Ce paramètre peut également être défini sur sémantique pour classement sémantique pour la modélisation sémantique avancée sur la réponse de requête.searchModespécifie si les correspondances sont basées sur tous les critères (favorise la précision) ou sur n’importe quel critère (favorise le rappel) dans l’expression. La valeur par défaut est tout. Si vous prévoyez une utilisation intensive d’opérateurs booléens, ce qui est plus probable dans les index contenant des blocs de texte volumineux (un champ de contenu ou des descriptions longues), veillez à tester les requêtes avec le paramètresearchMode=Any|Allpour évaluer l’impact de ce paramètre sur la recherche booléenne.searchFieldslimite l’exécution des requêtes à des champs spécifiques pouvant faire l’objet d’une recherche. Pendant le développement, il est utile d'utiliser la même liste de champs pour la sélection et la recherche. Sinon, une correspondance peut être basée sur des valeurs de champ que vous ne pouvez pas voir dans les résultats, ce qui crée une incertitude quant à la raison pour laquelle le document a été renvoyé.
Paramètres utilisés pour former la réponse :
selectspécifie les champs à retourner dans la réponse. Seuls les champs marqués comme récupérables dans l’index peuvent être utilisés dans une instruction select.topretourne le nombre de documents les mieux correspondants spécifié. Dans cet exemple, seuls 10 correspondances sont retournées. Vous pouvez utiliser Top et Skip (non affichés) pour paginer les résultats.countindique le nombre total de documents dans l’index complet, ce qui peut être supérieur à ce qui est retourné.orderbyest utilisé si vous souhaitez trier les résultats en fonction d’une valeur, telle qu’une évaluation ou un emplacement. Dans le cas contraire, la valeur par défaut consiste à utiliser le score de pertinence pour classer les résultats. Un champ doit être triable pour être candidat à ce paramètre.
Choisissez un client
Pour le développement précoce et les tests de preuve de concept, commencez par le portail Azure ou un client REST. Ces deux approches sont interactives, utiles pour des tests ciblés, et permettent d’évaluer les effets de différentes propriétés sans avoir à écrire de code.
Pour appeler la recherche à partir d’une application, utilisez les bibliothèques clientes Azure.Document.Search dans les kits de développement logiciel (SDK) Azure pour .NET, Java, JavaScript et Python.
Dans le portail, lorsque vous ouvrez un index, vous pouvez utiliser le Navigateur de recherche en même temps que la définition JSON de l’index dans les onglets côte à côte pour faciliter l’accès aux attributs du champ. Consultez la table Fields pour voir les champs qui sont compatibles avec la recherche, le tri, les filtres et les facettes pendant le test des requêtes.
Connectez-vous au Portail Azure, puis trouvez votre service de recherche.
Dans votre service, sélectionnez index et choisissez un index.
Un index s’ouvre sous l’onglet Explorateur de recherche pour que vous puissiez lancer immédiatement l’interrogation. Basculez vers vue JSON pour spécifier la syntaxe de requête.
Voici une expression de requête de recherche en texte intégral qui fonctionne pour l’exemple d’index Hotels :
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }La capture d’écran suivante illustre la requête et la réponse :
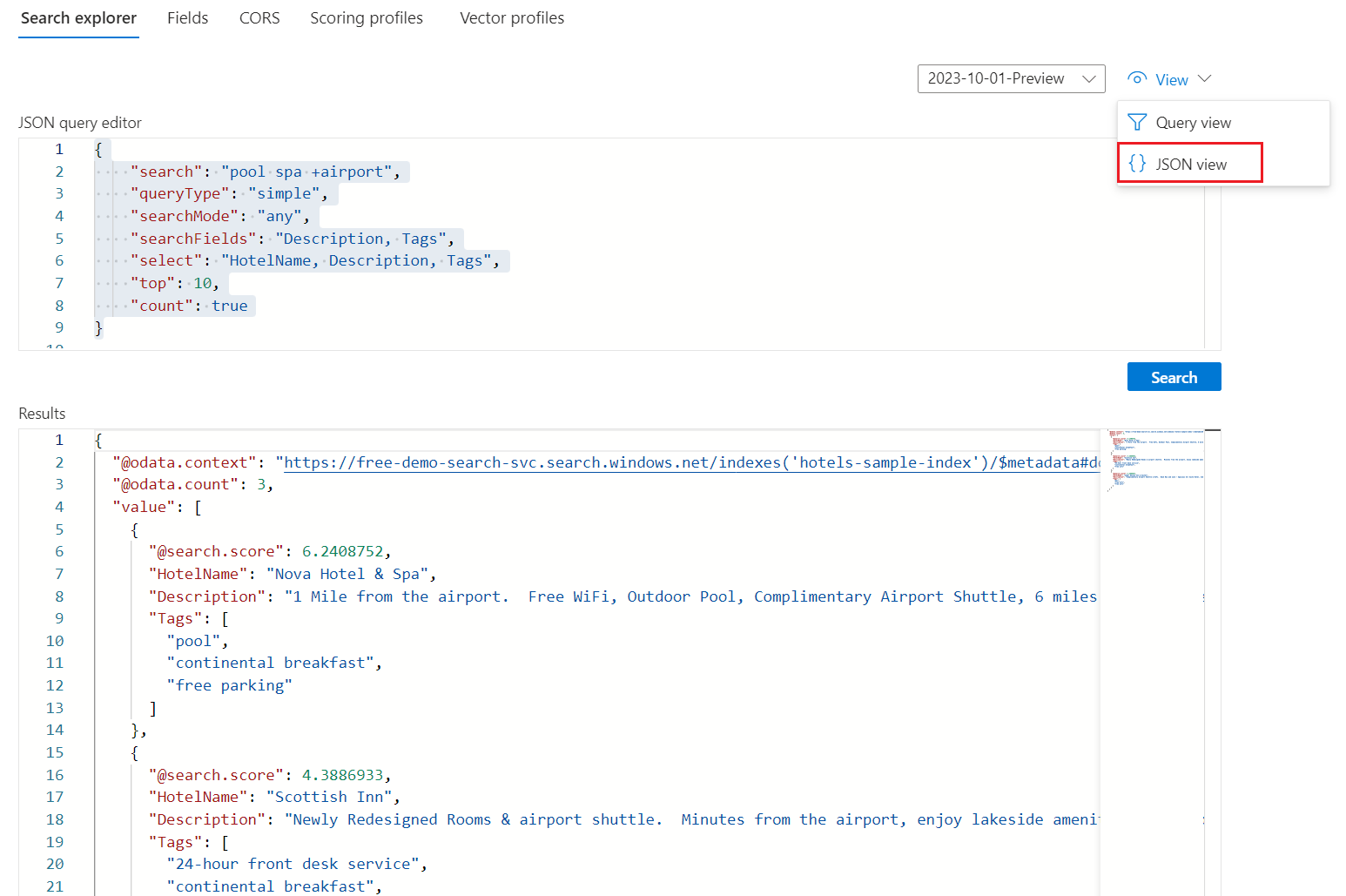
Choisir un type de requête : simple | complète
Si votre requête est une recherche en texte intégral, un analyseur de requête est utilisé pour traiter tout le texte transmis sous la forme de termes et d’expressions de recherche. La Recherche Azure AI offre deux analyseurs de requête.
L’analyseur simple comprend la syntaxe de requête simple. Cet analyseur a été sélectionné comme valeur par défaut pour sa vitesse et son efficacité dans les requêtes de texte de forme libre. La syntaxe prend en charge les opérateurs de recherche courants (AND, OR, NOT) pour les recherches de termes et d’expressions, et le préfixe (
*) recherche (comme danssea*pour Seattle et Bord de mer). Une recommandation générale consiste à essayer d’abord l’analyseur simple, puis à passer à l’analyseur complet si les exigences de l’application nécessitent des requêtes plus puissantes.La syntaxe de requête Lucene complète, activée lorsque vous ajoutez
queryType=fullà la demande, est basée sur l’analyseur Apache Lucene.
Une syntaxe complète et une syntaxe simple se chevauchent dans la mesure où toutes deux prennent en charge le même préfixe et les mêmes opérations booléennes, mais la syntaxe complète fournit davantage d’opérateurs. Dans la syntaxe complète, il existe d’autres opérateurs pour les expressions booléennes, et plus d’opérateurs pour les requêtes avancées, telles que la recherche approximative, la recherche de caractères génériques, la recherche de proximité et les expressions régulières.
Choisir des méthodes d’interrogation
La recherche est essentiellement un exercice piloté par l’utilisateur, où les termes ou expressions sont collectés à partir d’une zone de recherche ou à partir d’événements de clic sur une page. Le tableau suivant récapitule les mécanismes par lesquels vous pouvez collecter les entrées utilisateur, ainsi que l’expérience de recherche attendue.
| Entrée | Expérience |
|---|---|
| Méthode de recherche | Un utilisateur tape les termes ou expressions dans une zone de recherche, avec ou sans opérateurs, puis sélectionne recherche pour envoyer la requête. La recherche peut être utilisée avec des filtres sur la même demande, mais pas avec la saisie semi-automatique ni les suggestions. |
| Méthode de saisie semi-automatique | Un utilisateur tape quelques caractères et des requêtes sont lancées après la saisie de chaque nouveau caractère. La réponse est une chaîne complétée à partir de l’index. Si la chaîne fournie est valide, l’utilisateur sélectionne recherche pour envoyer cette requête au service. |
| Méthode de suggestions | Comme avec la saisie semi-automatique, un utilisateur tape quelques caractères et des requêtes incrémentielles sont générées. La réponse est une liste déroulante de documents correspondants, généralement représentée par quelques champs uniques ou descriptifs. Si l’une des sélections est valide, l’utilisateur en sélectionne un et le document correspondant est retourné. |
| Navigation à facettes | Une page affiche des liens de navigation cliquables ou des barres de navigation qui réduisent la portée de la recherche. Une structure de navigation à facettes est composée dynamiquement en fonction d’une requête initiale. Par exemple, search=* pour remplir une arborescence de navigation à facettes composée de chaque catégorie possible. Une structure de navigation à facettes est créée à partir d’une réponse à une requête, mais il s’agit également d’un mécanisme permettant d’exprimer la requête suivante. Dans la référence d’API REST, facets est documenté comme un paramètre de requête d’une opération Recherche dans des documents, mais peut être utilisé sans le paramètre search. |
| Méthode de filtre | Les filtres sont utilisés avec des facettes pour affiner les résultats. Vous pouvez également implémenter un filtre derrière la page, par exemple pour initialiser la page avec des champs spécifiques à une langue. Dans la référence d’API REST, $filter est documenté comme un paramètre de requête d’une opération Recherche dans des documents, mais peut être utilisé sans le paramètre search. |
Effet des attributs de champ sur les requêtes
Si vous connaissez les types de requêtes et leur composition, vous vous souvenez peut-être que les paramètres d’une demande de requête dépendent d’attributs de champs dans un index. Par exemple, seuls des champs marqués comme pouvant faire l’objet d’une recherche et pouvant être extraits peuvent être utilisés dans des requêtes et des résultats de recherche. Lors de la définition des paramètres search, filter et orderby dans votre demande, vous devez vérifier les attributs pour éviter des résultats inattendus.
Dans la capture d’écran suivante tirée de l’exemple d’index Hotels, seuls les deux derniers champs LastRenovationDate et Rating sont sortable, un attribut obligatoire pour être utilisés dans une clause "$orderby" uniquement.
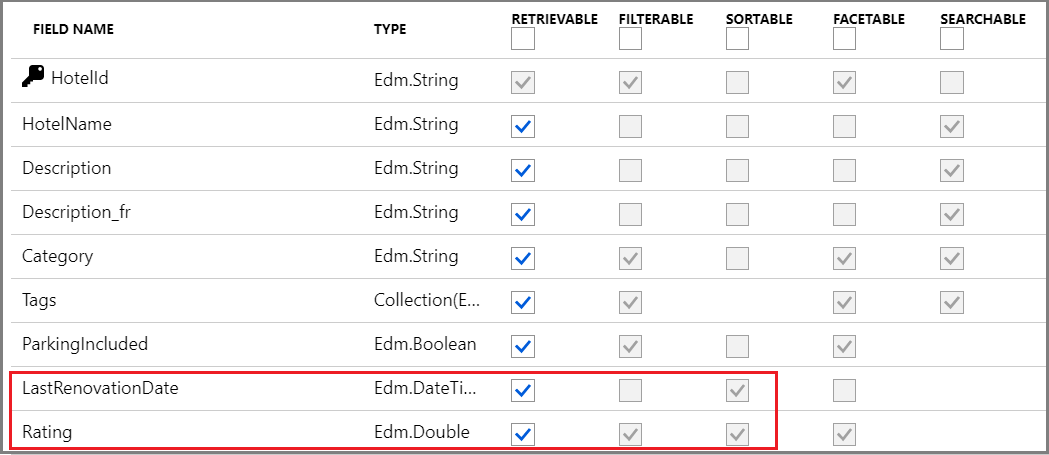
Pour les définitions d’attribut de champ, consultez Créer un index (API REST).
Effet des jetons sur les requêtes
Pendant l’indexation, le moteur de recherche utilise un analyseur de texte sur les chaînes pour maximiser le risque de découverte d’une correspondance au moment de la requête. Au minimum, les chaînes sont en minuscules mais, en fonction de l’analyseur, elles peuvent également faire l’objet d’une lemmatisation et arrêter la suppression de mots. Les chaînes plus grandes ou les mots composés sont généralement fractionnés en fonction des espaces blancs, des traits d’union ou des tirets, et indexés comme des jetons distincts.
Le point clé est que ce que vous pensez que votre index contient, et ce qui est réellement dans celui-ci, peut être différent. Si les requêtes ne renvoient pas les résultats attendus, vous pouvez inspecter les jetons créés par l’analyseur en utilisant Analyser le texte (API REST). Pour plus d’informations sur la segmentation du texte en unités lexicales et l’effet sur les requêtes, consultez recherche et modèles de termes partiels avec des caractères spéciaux.
Contenu connexe
Maintenant que vous avez une meilleure compréhension du fonctionnement d’une demande de requête, essayez les démarrages rapides suivants pour une expérience pratique.