Tutoriel : indexer des données volumineuses provenant d’Apache Spark en utilisant SynapseML et la recherche Azure AI
Dans ce tutoriel sur la recherche Azure AI, découvrez comment indexer et interroger des données volumineuses qui ont été chargées depuis un cluster Spark. Configurez un Jupyter Notebook qui effectue les actions suivantes :
- Charger plusieurs formulaires (factures) dans un dataframe dans une session Apache Spark
- Analyser les formulaires pour en déterminer les caractéristiques
- Assembler la sortie obtenue dans une structure de données tabulaires
- Écrire la sortie dans un index de recherche qui est hébergé dans la recherche Azure AI
- Explorer et interroger le contenu que vous avez créé
Ce tutoriel utilise SynapseML, une bibliothèque open source qui prend en charge le machine learning massivement parallèle sur le Big Data. Dans SynapseML, l’indexation de recherche et le machine learning sont exposés par le biais de transformateurs qui effectuent des tâches spécialisées. Les transformateurs s’appuient sur un large éventail de capacités d’IA. Dans cet exercice, utilisez les API AzureSearchWriter pour l’analyse et l’enrichissement par IA.
Bien que la recherche Azure AI a une fonctionnalité d’enrichissement par IA natif, ce tutoriel vous montre comment accéder aux fonctionnalités d’IA en dehors de la recherche Azure AI. En utilisant SynapseML plutôt que des indexeurs ou des compétences, vous vous affranchissez des limites de données ou de toute autre contrainte associée à ces objets.
Conseil
Regardez une courte vidéo de cette démonstration ici : https://www.youtube.com/watch?v=iXnBLwp7f88. La vidéo complète ce tutoriel avec des étapes et visuels supplémentaires.
Prérequis
Vous avez besoin de la bibliothèque synapseml et de plusieurs ressources Azure. Si possible, utilisez le même abonnement et la même région pour vos ressources Azure, et placez le tout dans un seul groupe de ressources pour faciliter le nettoyage ultérieur. Les liens suivants concernent les installations à partir du portail. Les exemples de données sont importés d’un site public.
- Package SynapseML1
-
Recherche Azure AI (tout niveau), avec un Type d’API de
AIServices2 - Compte multiservice Azure AI (tout niveau) 3
- Azure Databricks (tout niveau) avec runtime Apache Spark 3.3.0 4
1 Ce lien est résolu en didacticiel pour le chargement du package.
2 Vous pouvez utiliser le niveau de recherche gratuit pour indexer les données d’échantillon, mais choisissez un niveau supérieur si vous avez de gros volumes de données. Pour les niveaux facturables, fournissez la clé API de recherche dans l’étape Configurer les dépendances.
3 Ce tutoriel utilise Azure AI Intelligence documentaire et Azure AI Traducteur. Dans les instructions qui suivent, fournissez un compte multiservice et la région. La même clé fonctionne pour les deux services.
Il est important que vous utilisiez un compte multiservice Azure AI de type d’API AIServices pour ce tutoriel. Vous pouvez vérifier le type d’API dans le Portail Azure sur la section Vue d’ensemble de la page de votre compte multiservice Azure AI. Pour découvrir plus d’informations sur le type d’API, consultez Attacher une ressource multiservices Azure AI dans Recherche Azure AI.
4 Dans ce tutoriel, Azure Databricks fournit la plateforme informatique Spark. Nous avons utilisé les instructions du portail pour configurer le cluster et l’espace de travail.
Remarque
Toutes les ressources Azure ci-dessus prennent en charge les fonctionnalités de sécurité de la Plateforme d’identités Microsoft. Par souci de simplicité, ce tutoriel suppose l’utilisation de l’authentification basée sur des clés, où les points de terminaison et les clés sont copiés des pages du portail Azure de chaque service. Si vous implémentez ce workflow dans un environnement de production ou que vous partagez la solution avec d’autres personnes, n’oubliez pas de remplacer les clés codées en dur par la sécurité intégrée ou des clés chiffrées.
Étape 1 : créer un cluster Spark et un notebook
Dans cette section, créez un cluster, installez la bibliothèque synapseml et créez un notebook pour exécuter le code.
Dans le portail Azure, recherchez votre espace de travail Azure Databricks et sélectionnez Lancer l’espace de travail.
Dans le menu de gauche, sélectionnez Compute.
Sélectionnez Créer un calcul.
Acceptez la configuration par défaut. La création du cluster prend quelques minutes.
Confirmez que le cluster est opérationnel. Un point vert près du nom du cluster confirme son état.

Installez la bibliothèque
synapsemlune fois le cluster créé :Sélectionnez Bibliothèques dans les onglets en haut de la page du cluster.
Sélectionnez Installer.
Sélectionnez Maven.
Dans Coordonnées, recherchez ou tapez
com.microsoft.azure:synapseml_2.12:1.0.9Sélectionnez Installer.
Dans le menu de gauche, sélectionnez Créer>Notebook.
Nommez le notebook, sélectionnez Python comme langage par défaut, puis sélectionnez le cluster qui a la bibliothèque
synapseml.Créez sept cellules consécutives. Vous les utilisez pour coller du code dans les sections suivantes.
Étape 2 : configurer les dépendances
Collez le code suivant dans la première cellule de votre notebook.
Remplacez les espaces réservés par des points de terminaison et des clés d’accès pour chaque ressource. Fournissez un nom pour un nouvel index de recherche créé pour vous. Il n’y a aucune autre modification à faire. Vous pouvez donc exécuter le code dès que vous êtes prêt.
Ce code importe plusieurs packages et il configure l’accès aux ressources Azure utilisées dans ce workflow.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-azure-ai-services-multi-service-key"
cognitive_services_region = "placeholder-azure-ai-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-admin-api-key"
search_index = "placeholder-for-new-search-index-name"
Étape 3 : charger des données dans Spark
Collez le code ci-après dans la deuxième cellule. Il n’y a aucune modification à faire. Vous pouvez donc exécuter le code dès que vous êtes prêt.
Ce code charge quelques fichiers externes à partir d’un compte de stockage Azure. Les fichiers sont diverses factures et sont lus dans un dataframe.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Étape 4 : ajouter l’intelligence documentaire
Collez le code ci-dessous dans la troisième cellule. Il n’y a aucune modification à faire. Vous pouvez donc exécuter le code dès que vous êtes prêt.
Ce code charge le transformateur AnalyzeInvoices et passe une référence au dataframe contenant les factures. Il appelle le modèle de facture prédéfini d’Azure AI Intelligence documentaire pour extraire des informations des factures.
from synapse.ml.services import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
La sortie de cette étape doit ressembler à la capture d’écran suivante. Vous voyez que l’analyse des formulaires est comprimée dans une colonne à la structure dense, difficile à utiliser. La transformation suivante résout ce problème en analysant la colonne en lignes et colonnes.
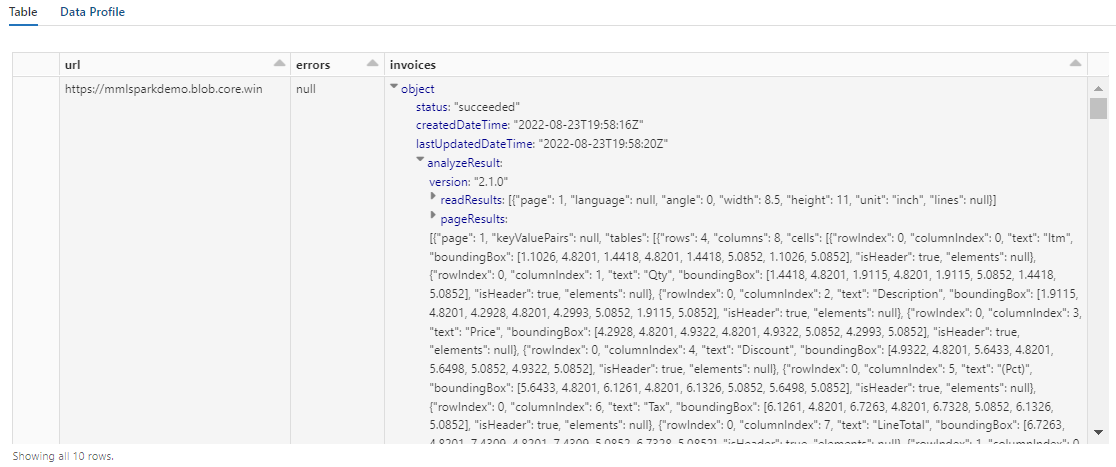
Étape 5 : restructurer la sortie de l’intelligence documentaire
Collez le code suivant dans la quatrième cellule et exécutez-le. Il n’y a aucune modification à faire.
Ce code charge FormOntologyLearner, un transformateur qui analyse la sortie des transformateurs Document Intelligence et en déduit une structure de données tabulaires. La sortie d’AnalyzeInvoices est dynamique et varie selon les caractéristiques détectées dans votre contenu. En outre, le transformateur regroupe la sortie en une seule colonne. Du fait que la sortie est dynamique et regroupée, elle est difficile à utiliser dans les transformations en aval qui nécessitent plus de structure.
FormOntologyLearner étend l’utilitaire du transformateur AnalyzeInvoices en recherchant des modèles qui peuvent être utilisés pour créer une structure de données tabulaires. L’organisation de la sortie en plusieurs colonnes et lignes rend le contenu consommable dans d’autres transformateurs, comme AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Notez comment cette transformation convertit les champs imbriqués en table, ce qui permet d’effectuer les deux transformations suivantes. Cette capture d’écran a été tronquée par souci de concision. Si vous suivez votre propre notebook, vous avez 19 colonnes et 26 lignes.
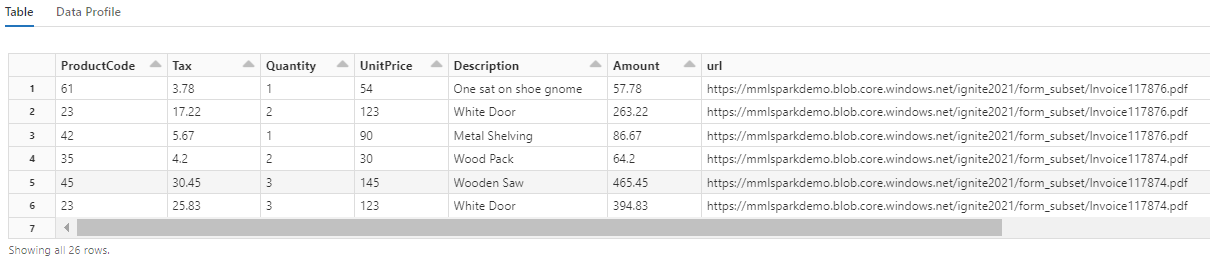
Étape 6 : ajouter des traductions
Collez le code suivant dans la cinquième cellule. Il n’y a aucune modification à faire. Vous pouvez donc exécuter le code dès que vous êtes prêt.
Ce code charge Translate, un transformateur qui appelle le service Azure AI Traducteur dans Azure AI services. Le texte d’origine, qui est en anglais dans la colonne « Description », est traduit automatiquement en différentes langues. Toutes les sorties sont regroupées dans le tableau « output.translations ».
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Conseil
Pour rechercher les chaînes traduites, faites défiler le tableau jusqu’à la fin des lignes.
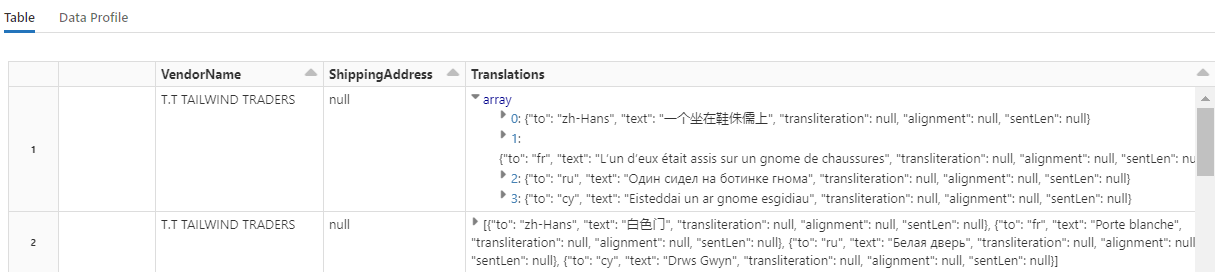
Étape 7 : ajouter un index de recherche avec AzureSearchWriter
Collez le code suivant dans la sixième cellule, puis exécutez-le. Il n’y a aucune modification à faire.
Ce code charge AzureSearchWriter. Il consomme un jeu de données tabulaires et en déduit un schéma d’index de recherche qui définit un champ par colonne. Étant donné que la structure des traductions est un tableau, elle est articulée dans l’index sous la forme d’une collection complexe, avec des sous-champs pour chaque traduction linguistique. L’index généré a une clé de document et utilise les valeurs par défaut pour les champs créés à l’aide de l’API REST Create Index.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Vous pouvez consulter les pages de service de recherche dans le portail Azure pour examiner la définition d’index créée par AzureSearchWriter.
Notes
Si vous ne pouvez pas utiliser l’index de recherche par défaut, vous pouvez fournir une définition personnalisée externe au format JSON, en passant son URI en tant que chaîne dans la propriété « indexJson ». Générez d’abord l’index par défaut pour savoir quels champs spécifier, puis suivez avec des propriétés personnalisées si vous avez besoin d’analyseurs spécifiques, par exemple.
Étape 8 : interroger l’index
Collez le code suivant dans la septième cellule, puis exécutez-le. Vous n’avez aucune modification à faire, sauf si vous souhaitez changer la syntaxe ou tester d’autres exemples pour explorer davantage votre contenu :
Aucun transformateur ou module n’émet de requêtes. Cette cellule est un appel simple à l’API REST Search Documents.
Cet exemple particulier recherche le mot « door » ("search": "door"). Il retourne également le nombre de documents correspondants ("count") et inclut uniquement le contenu des champs « Description » et « Translations » dans les résultats. Si vous souhaitez afficher la liste complète des champs, supprimez le paramètre « select ».
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
La capture d’écran suivante montre la sortie de cellules de l’exemple de script.
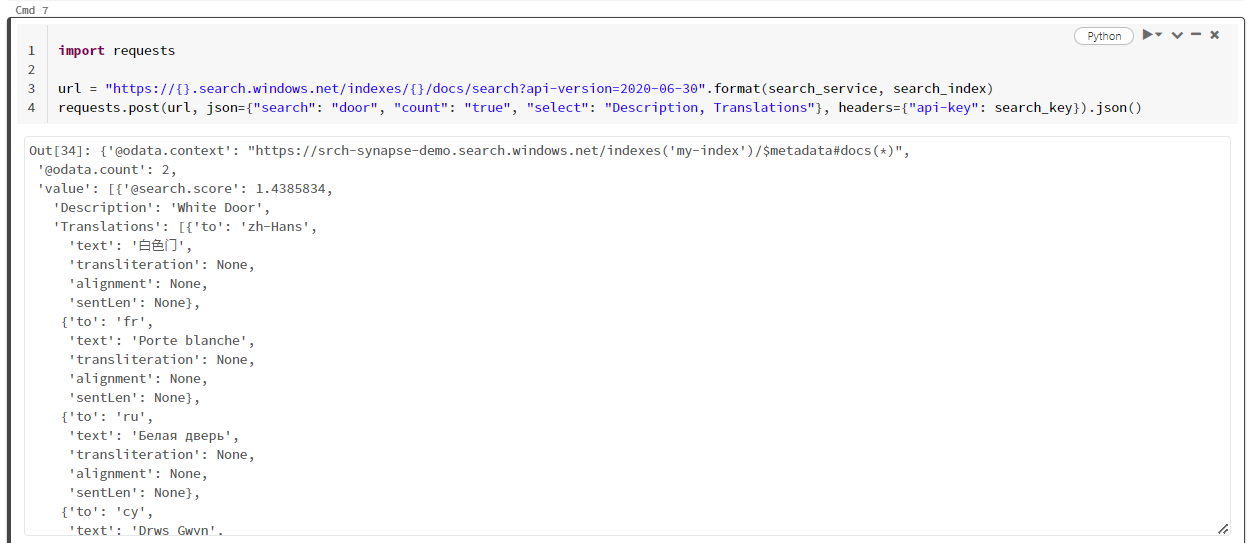
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer des ressources dans le portail Azure, en utilisant le lien Toutes les ressources ou Groupes de ressources dans le volet de navigation de gauche.
Étapes suivantes
Dans ce tutoriel, vous avez découvert le transformateur AzureSearchWriter dans SynapseML, qui offre une nouvelle façon de créer et charger des index de recherche dans la recherche Azure AI. Le transformateur prend le code JSON structuré comme entrée. FormOntologyLearner peut fournir la structure nécessaire pour la sortie produite par les transformateurs Document Intelligence dans SynapseML.
L’étape suivante est d’effectuer les autres tutoriels SynapseML qui produisent du contenu transformé que vous souhaitez explorer via la recherche Azure AI :