Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel vous montre comment créer un générateur de recommandations vidéo avec ML.NET dans une application console .NET. Les étapes utilisent C# et Visual Studio 2019.
Dans ce tutoriel, vous allez apprendre à :
- Sélectionner un algorithme Machine Learning
- Préparer et charger vos données
- Générer et entraîner un modèle
- Évaluer un modèle
- Déployer et consommer un modèle
Vous trouverez le code source de ce didacticiel dans le référentiel dotnet/samples .
Flux de travail Machine Learning
Vous allez utiliser les étapes suivantes pour accomplir votre tâche, ainsi que toute autre tâche ML.NET :
Prerequisites
Sélectionner la tâche machine learning appropriée
Il existe plusieurs façons d’aborder les problèmes de recommandation, tels que la recommandation d’une liste de films ou la recommandation d’une liste de produits connexes, mais dans ce cas, vous prédirez quelle évaluation (1-5) un utilisateur donnera à un film particulier et recommandera ce film s’il est supérieur à un seuil défini (plus l’évaluation est élevée, plus la probabilité d’un utilisateur aime un film particulier).
Création d’une application console
Création d’un projet
Créez une application console C# appelée « MovieRecommender ». Cliquez sur le bouton Suivant .
Choisissez .NET 8 comme framework à utiliser. Cliquez sur le bouton Créer.
Créez un répertoire nommé Data dans votre projet pour stocker le jeu de données :
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Ajouter>un nouveau dossier. Tapez « Données », puis sélectionnez Entrée.
Installez les packages NuGet Microsoft.ML et Microsoft.ML.Recommender :
Note
Cet exemple utilise la dernière version stable des packages NuGet mentionnés, sauf indication contraire.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Gérer les packages NuGet. Choisissez « nuget.org » comme source du package, sélectionnez l’onglet Parcourir, recherchezMicrosoft.ML, sélectionnez le package dans la liste, puis sélectionnez Installer. Sélectionnez le bouton OK dans la boîte de dialogue Aperçu des modifications , puis sélectionnez le bouton J’acceptedans la boîte de dialogue Acceptation de licence si vous acceptez les termes du contrat de licence pour les packages répertoriés. Répétez ces étapes pour Microsoft.ML.Recommender.
Ajoutez les directives suivantes
usingen haut de votre fichier Program.cs :using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Téléchargez vos données
Téléchargez les deux jeux de données et enregistrez-les dans le dossier Données que vous avez créé précédemment :
Cliquez avec le bouton droit sur recommendation-ratings-train.csv , puis sélectionnez « Enregistrer le lien (ou cible) En tant que ... »
Cliquez avec le bouton droit sur recommendation-ratings-test.csv , puis sélectionnez « Enregistrer le lien (ou cible) En tant que ... »
Veillez à enregistrer les fichiers *.csv dans le dossier Données ou après l’avoir enregistré ailleurs, déplacez les fichiers *.csv vers le dossier Données .
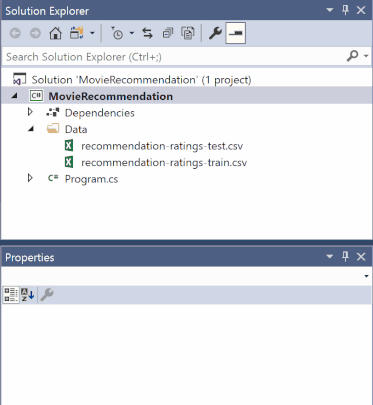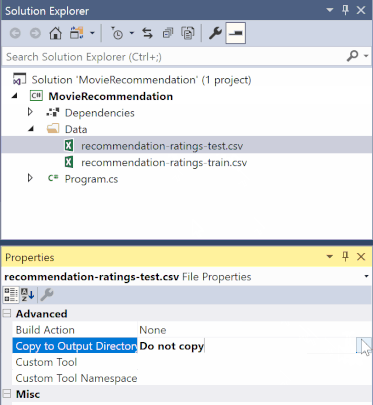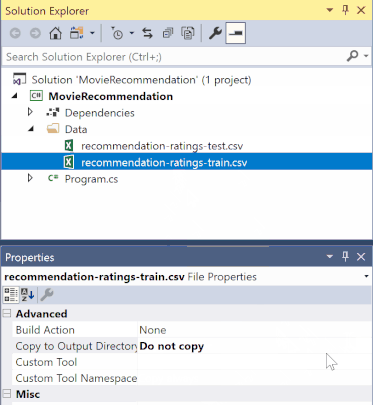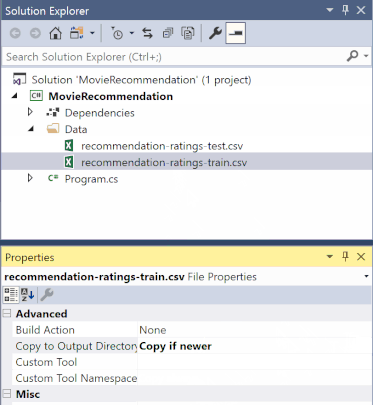
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur chacun des fichiers *.csv, puis sélectionnez Propriétés. Sous Avancé, modifiez la valeur de Copie dans le répertoire de sortie pour copier si elle est plus récente.
Charger vos données
La première étape du processus de ML.NET consiste à préparer et charger vos données d’entraînement et de test de modèle.
Les données d’évaluation des recommandations sont divisées en jeux de données et Train en Test jeux de données. Les Train données sont utilisées pour ajuster votre modèle. Les Test données sont utilisées pour effectuer des prédictions avec votre modèle entraîné et évaluer les performances du modèle. Il est courant d’avoir un fractionnement de 80/20 avec et Train des Test données.
Vous trouverez ci-dessous un aperçu des données de vos fichiers *.csv :
Dans les fichiers *.csv, il existe quatre colonnes :
userIdmovieIdratingtimestamp
Dans le Machine Learning, les colonnes utilisées pour effectuer une prédiction sont appelées Fonctionnalités, et la colonne avec la prédiction retournée est appelée Étiquette.
Vous souhaitez prédire les évaluations de films, de sorte que la colonne d’évaluation est la Label. Les trois autres colonnes, userId, movieIdet timestamp sont toutes Features utilisées pour prédire le Label.
| Fonctionnalités | Étiquette |
|---|---|
userId |
rating |
movieId |
|
timestamp |
C’est à vous de décider qui Features sont utilisés pour prédire le Label. Vous pouvez également utiliser des méthodes telles que l’importance des fonctionnalités de permutation pour vous aider à sélectionner le meilleur Features.
Dans ce cas, vous devez éliminer la colonne timestamp en tant que Feature parce que l’horodatage n’affecte pas vraiment la façon dont un utilisateur évalue un film donné et ne contribuerait donc pas à une prédiction plus précise :
| Fonctionnalités | Étiquette |
|---|---|
userId |
rating |
movieId |
Ensuite, vous devez définir votre structure de données pour la classe d’entrée.
Ajoutez une nouvelle classe à votre projet :
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet, puis sélectionnez Ajouter > un nouvel élément.
Dans la boîte de dialogue Ajouter un nouvel élément, sélectionnez Classe et remplacez le champ Nom par MovieRatingData.cs. Ensuite, sélectionnez Ajouter.
Le fichier MovieRatingData.cs s’ouvre dans l’éditeur de code. Ajoutez la directive suivante using en haut de MovieRatingData.cs :
using Microsoft.ML.Data;
Créez une classe appelée MovieRating en supprimant la définition de classe existante et en ajoutant le code suivant dans MovieRatingData.cs :
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating spécifie une classe de données d’entrée. L’attribut LoadColumn spécifie les colonnes (par index de colonne) dans le jeu de données à charger. Les colonnes userId et movieId sont vos Features (les entrées que vous donnez au modèle pour prédire le Label), et la colonne de notation est celle que vous allez prédire, c’est-à-dire la sortie du modèle Label.
Créez une autre classe, MovieRatingPredictionpour représenter les résultats prédits en ajoutant le code suivant après la MovieRating classe dans MovieRatingData.cs :
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Dans Program.cs, remplacez le Console.WriteLine("Hello World!") code suivant :
MLContext mlContext = new MLContext();
La classe MLContext est un point de départ pour toutes les opérations ML.NET, et l’initialisation mlContext crée un environnement ML.NET qui peut être partagé entre les objets de flux de travail de création de modèle. Il est similaire, conceptuellement, à DBContext entity Framework.
En bas du fichier, créez une méthode appelée LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Note
Cette méthode vous donnera une erreur jusqu’à ce que vous ajoutiez une instruction return dans les étapes suivantes.
Initialisez vos variables de chemin d’accès aux données, chargez les données à partir des fichiers *.csv, puis retournez les données Train et Test sous forme d’objets IDataView en ajoutant la ligne de code suivante dans LoadData() :
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Les données de ML.NET sont représentées sous forme d’interface IDataView.
IDataView est un moyen flexible et efficace de décrire les données tabulaires (numériques et textuelles). Les données peuvent être chargées à partir d’un fichier texte ou en temps réel (par exemple, des fichiers de base de données SQL ou des fichiers journaux) dans un IDataView objet.
LoadFromTextFile() définit le schéma de données et lit dans le fichier. Il prend les variables de chemin d’accès aux données et retourne un IDataView. Dans ce cas, vous fournissez les chemins d’accès de vos fichiers Test et Train et indiquez à la fois l’en-tête du fichier texte (afin qu’il puisse utiliser correctement les noms de colonnes) et le séparateur de données par virgule (le séparateur par défaut est un caractère de tabulation).
Ajoutez le code suivant pour appeler votre LoadData() méthode et retourner les données et Train les Test données :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Générer et entraîner votre modèle
Créez la BuildAndTrainModel() méthode, juste après la LoadData() méthode, à l’aide du code suivant :
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Note
Cette méthode vous donnera une erreur jusqu’à ce que vous ajoutiez une instruction return dans les étapes suivantes.
Définissez les transformations de données en ajoutant le code suivant à BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Étant donné que userId et movieId représentent des utilisateurs et des titres de films, et non des valeurs réelles, vous utilisez la méthode MapValueToKey() pour transformer chaque userId et chaque movieId en colonne de type clé numérique Feature (un format accepté par les algorithmes de recommandation) et les ajouter en tant que nouvelles colonnes du jeu de données :
| userId | movieId | Étiquette | IdentifiantUtilisateurCodé | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Choisissez l’algorithme Machine Learning et ajoutez-le aux définitions de transformation de données en ajoutant ce qui suit comme ligne de code suivante dans BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer est votre algorithme d’entraînement de recommandation. Matrix Factorization est une approche courante de la recommandation lorsque vous avez des données sur la façon dont les utilisateurs ont évalué les produits dans le passé, ce qui est le cas pour les jeux de données de ce tutoriel. Il existe d’autres algorithmes de recommandation pour chaque fois que vous disposez de données différentes (consultez la section Autres algorithmes de recommandation ci-dessous pour en savoir plus).
Dans ce cas, l’algorithme Matrix Factorization utilise une méthode appelée « filtrage collaboratif », qui suppose que si l’utilisateur 1 a la même opinion que l’utilisateur 2 sur un certain problème, l’utilisateur 1 est plus susceptible de se sentir de la même façon que l’utilisateur 2 sur un autre problème.
Par exemple, si l’utilisateur 1 et l’utilisateur 2 évaluent les films de la même façon, l’utilisateur 2 est plus susceptible de profiter d’un film que l’utilisateur 1 a regardé et évalué fortement :
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Utilisateur 1 | Regardé et aimé film | Regardé et aimé film | Regardé et aimé film |
| Utilisateur 2 | Regardé et aimé film | Regardé et aimé film | N’a pas regardé – RECOMMANDER un film |
L’entraîneur Matrix Factorization dispose de plusieurs options, que vous pouvez en savoir plus dans la section Hyperparamètres d’algorithme ci-dessous.
Ajuster le modèle aux Train données et renvoyer le modèle entraîné en ajoutant la ligne de code suivante dans la BuildAndTrainModel() méthode :
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
La méthode Fit() entraîne votre modèle avec le jeu de données d’entraînement fourni. Techniquement, il exécute les Estimator définitions en transformant les données et en appliquant l’entraînement, et retourne le modèle entraîné, qui est un Transformer.
Pour plus d’informations sur le flux de travail d’entraînement du modèle dans ML.NET, consultez Qu’est-ce que ML.NET et comment fonctionne-t-il ?.
Ajoutez ce qui suit comme ligne de code suivante sous l’appel à la LoadData() méthode pour appeler votre BuildAndTrainModel() méthode et retourner le modèle entraîné :
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Évaluer votre modèle
Une fois que vous avez entraîné votre modèle, utilisez vos données de test pour évaluer l’exécution de votre modèle.
Créez la EvaluateModel() méthode, juste après la BuildAndTrainModel() méthode, à l’aide du code suivant :
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Transformez les Test données en ajoutant le code suivant à EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
La méthode Transform() effectue des prédictions pour plusieurs lignes d’entrée fournies d’un jeu de données de test.
Évaluez le modèle en ajoutant ce qui suit comme ligne de code suivante dans la EvaluateModel() méthode :
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Une fois que vous avez le jeu de prédictions, la méthode Evaluate() évalue le modèle, qui compare les valeurs prédites avec la valeur réelle Labels dans le jeu de données de test et retourne des métriques sur la façon dont le modèle fonctionne.
Imprimez vos métriques d’évaluation dans la console en ajoutant les éléments suivants comme ligne de code suivante dans la EvaluateModel() méthode :
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Ajoutez ce qui suit comme ligne de code suivante sous l’appel à la BuildAndTrainModel() méthode pour appeler votre EvaluateModel() méthode :
EvaluateModel(mlContext, testDataView, model);
Jusqu’à présent, la sortie doit ressembler au texte suivant :
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Dans ce résultat, il existe 20 itérations. Dans chaque itération, la mesure de l’erreur diminue et converge plus près de 0.
Le root of mean squared error (RMS ou RMSE) est utilisé pour mesurer les différences entre les valeurs prédites du modèle et le jeu de données de test observé. Techniquement, il s’agit de la racine carrée de la moyenne des carrés des erreurs. Plus il est bas, mieux le modèle est.
R Squared indique comment les données correspondent bien à un modèle. Est comprise entre 0 et 1. La valeur 0 signifie que les données sont aléatoires ou ne peuvent pas être adaptées au modèle. La valeur 1 signifie que le modèle correspond exactement aux données. Vous souhaitez que votre R Squared score soit le plus proche de 1 possible.
La création de modèles réussis est un processus itératif. Ce modèle a une qualité initiale inférieure, car le didacticiel utilise de petits jeux de données pour fournir une formation rapide sur les modèles. Si vous n’êtes pas satisfait de la qualité du modèle, vous pouvez essayer de l’améliorer en fournissant des jeux de données d’entraînement plus volumineux ou en choisissant différents algorithmes d’entraînement avec différents hyper-paramètres pour chaque algorithme. Pour plus d’informations, consultez la section Améliorer votre modèle ci-dessous.
Utiliser votre modèle
Vous pouvez maintenant utiliser votre modèle entraîné pour effectuer des prédictions sur de nouvelles données.
Créez la UseModelForSinglePrediction() méthode, juste après la EvaluateModel() méthode, à l’aide du code suivant :
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Utilisez la PredictionEngine méthode pour prédire l’évaluation en ajoutant le code suivant à UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine est une API pratique, qui vous permet d’effectuer une prédiction sur une seule instance de données.
PredictionEngine n’est pas thread-safe. Il est acceptable d’utiliser dans des environnements monothreads ou prototypes. Pour améliorer les performances et la sécurité des threads dans les environnements de production, utilisez le PredictionEnginePool service, qui crée un ObjectPool objet PredictionEngine à utiliser dans votre application. Consultez ce guide sur l’utilisation PredictionEnginePool dans une API web ASP.NET Core.
Note
PredictionEnginePool l’extension de service est actuellement en préversion.
Créez une instance d’appelée MovieRatingtestInput et transmettez-la au moteur de prédiction en ajoutant les lignes de code suivantes comme lignes de code suivantes dans la UseModelForSinglePrediction() méthode :
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
La fonction Predict() effectue une prédiction sur une seule colonne de données.
Vous pouvez ensuite utiliser l’évaluation prédite ou l’évaluation Scoreprédite pour déterminer si vous souhaitez recommander le film avec movieId 10 à l’utilisateur 6. Plus la Scorevaleur est élevée, plus la probabilité d’un utilisateur aime un film particulier. Dans ce cas, supposons que vous recommandez des films avec une évaluation prédite de > 3,5.
Pour imprimer les résultats, ajoutez les lignes de code suivantes comme lignes de code suivantes dans la UseModelForSinglePrediction() méthode :
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Ajoutez ce qui suit comme ligne de code suivante après l’appel à la EvaluateModel() méthode pour appeler votre UseModelForSinglePrediction() méthode :
UseModelForSinglePrediction(mlContext, model);
La sortie de cette méthode doit ressembler au texte suivant :
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Enregistrer votre modèle
Pour utiliser votre modèle pour effectuer des prédictions dans les applications utilisateur final, vous devez d’abord enregistrer le modèle.
Créez la SaveModel() méthode, juste après la UseModelForSinglePrediction() méthode, à l’aide du code suivant :
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Enregistrez votre modèle entraîné en ajoutant le code suivant dans la SaveModel() méthode :
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Cette méthode enregistre votre modèle entraîné dans un fichier .zip (dans le dossier « Données »), qui peut ensuite être utilisé dans d’autres applications .NET pour effectuer des prédictions.
Ajoutez ce qui suit comme ligne de code suivante après l’appel à la UseModelForSinglePrediction() méthode pour appeler votre SaveModel() méthode :
SaveModel(mlContext, trainingDataView.Schema, model);
Utiliser votre modèle enregistré
Une fois que vous avez enregistré votre modèle entraîné, vous pouvez utiliser le modèle dans différents environnements. Consultez Enregistrer et charger des modèles entraînés pour apprendre à opérationnaliser un modèle Machine Learning entraîné dans les applications.
Results
Après avoir suivi les étapes ci-dessus, exécutez votre application console (Ctrl + F5). Vos résultats de la prédiction unique ci-dessus doivent être similaires à ce qui suit. Vous pouvez voir des avertissements ou des messages de traitement, mais ces messages ont été supprimés des résultats suivants pour plus de clarté.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Félicitations! Vous avez maintenant créé un modèle Machine Learning pour recommander des films. Vous trouverez le code source de ce didacticiel dans le référentiel dotnet/samples .
Améliorer votre modèle
Il existe plusieurs façons d’améliorer les performances de votre modèle afin d’obtenir des prédictions plus précises.
Data
L’ajout de données d’apprentissage suffisantes pour chaque utilisateur et ID vidéo peut améliorer la qualité du modèle de recommandation.
La validation croisée est une technique permettant d’évaluer des modèles qui fractionne de façon aléatoire les données en sous-ensembles (au lieu d’extraire des données de test à partir du jeu de données comme vous l’avez fait dans ce tutoriel) et prend certains des groupes comme données d’apprentissage et certains des groupes comme données de test. Cette méthode surperforme la division d’un test d’apprentissage en termes de qualité de modèle.
Fonctionnalités
Dans ce tutoriel, vous utilisez uniquement les trois Features (user idet movie idrating) fournis par le jeu de données.
Bien qu’il s’agit d’un bon début, en réalité, vous souhaiterez peut-être ajouter d’autres attributs ou Features (par exemple, âge, sexe, géolocalisation, etc.) s’ils sont inclus dans le jeu de données. L’ajout d’éléments plus pertinents Features peut vous aider à améliorer les performances de votre modèle de recommandation.
Si vous n’êtes pas sûr de celui qui Features peut être le plus pertinent pour votre tâche de Machine Learning, vous pouvez également utiliser le calcul des contributions aux fonctionnalités (FCC) et l'importance des fonctionnalités par permutation, que ML.NET fournit pour découvrir les plus influents Features.
Hyperparamètres d’algorithme
Bien que ML.NET fournit de bons algorithmes d’apprentissage par défaut, vous pouvez affiner davantage les performances en modifiant les hyperparamètres de l’algorithme.
Pour Matrix Factorization, vous pouvez expérimenter des hyperparamètres tels que NumberOfIterations et ApproximationRank pour voir si cela vous donne de meilleurs résultats.
Par exemple, dans ce tutoriel, les options d’algorithme sont les suivantes :
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Autres algorithmes de recommandation
L’algorithme de factorisation de matrice avec filtrage collaboratif n’est qu’une seule approche pour effectuer des recommandations de films. Dans de nombreux cas, vous n’avez peut-être pas les données d’évaluation disponibles et n’avez que l’historique des films disponible auprès des utilisateurs. Dans d’autres cas, vous pouvez avoir plus que les données d’évaluation de l’utilisateur.
| Algorithm | Scénario | Sample |
|---|---|---|
| Factorisation de matrice d’une classe | Utilisez cette option lorsque vous avez uniquement userId et movieId. Ce style de recommandation est basé sur le scénario de co-achat, ou les produits fréquemment achetés ensemble, ce qui signifie qu’il recommandera aux clients un ensemble de produits en fonction de leur propre historique de bon de commande. | >Essayez-le |
| Machines de factorisation prenant en compte les champs | Utilisez cette option pour formuler des recommandations lorsque vous avez davantage de fonctionnalités au-delà de userId, productId et rating (par exemple, description du produit ou prix du produit). Cette méthode utilise également une approche de filtrage collaborative. | >Essayez-le |
Nouveau scénario utilisateur
Un problème courant dans le filtrage collaboratif est le problème de démarrage à froid, c’est-à-dire lorsque vous avez un nouvel utilisateur sans données précédentes pour dessiner des inférences. Ce problème est souvent résolu en demandant aux nouveaux utilisateurs de créer un profil et, par exemple, de noter les films qu’ils ont vus dans le passé. Bien que cette méthode impose une certaine charge à l’utilisateur, elle fournit des données de démarrage pour les nouveaux utilisateurs sans historique d’évaluation.
Ressources
Les données utilisées dans ce didacticiel sont dérivées du jeu de données MovieLens.
Étapes suivantes
Dans ce didacticiel, vous avez appris à :
- Sélectionner un algorithme Machine Learning
- Préparer et charger vos données
- Générer et entraîner un modèle
- Évaluer un modèle
- Déployer et consommer un modèle
Passez au tutoriel suivant pour en savoir plus
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.