Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Découvrez comment les pipelines d’intégration et de déploiement Git fonctionnent avec l’API pour GraphQL dans Microsoft Fabric. Cet article vous aide à comprendre comment configurer une connexion à votre référentiel, gérer votre API pour GraphQL et les déployer dans différents environnements.
Qui utilise le contrôle de code source et le déploiement
Les pipelines d’intégration et de déploiement Git sont essentiels pour :
- Ingénieurs données gérant les configurations d’API Fabric GraphQL via le contrôle de version et les flux de travail CI/CD
- Administrateurs d’espaces de travail Fabric qui coordonnent les déploiements entre les espaces de travail Fabric de développement, de test et de production
- Équipes DevOps implémentant des pipelines de déploiement pour les API Fabric sur plusieurs environnements et capacités
- Équipes de plateforme nécessitant des fonctionnalités de gouvernance, de suivi et de restauration pour les modifications apportées aux API Fabric
Utilisez des pipelines de contrôle de code source et de déploiement lorsque vous devez gérer les API GraphQL dans le cadre d’un cycle de vie de développement structuré avec plusieurs environnements.
Remarque
L’API pour le contrôle de code source GraphQL et le déploiement sont actuellement en préversion.
Conditions préalables
- Vous devez disposer d’une API pour GraphQL dans Fabric. Pour plus d’informations, consultez Créer une API pour GraphQL dans Fabric et ajouter des données.
Aperçu
Fabric offre de puissants outils pour CI/CD (intégration continue et déploiement continu) et la gestion du cycle de vie du développement via deux composants principaux : intégration Git (CI) et pipelines de déploiement (CD). Les espaces de travail servent de composants centraux pour les phases de synchronisation et de déploiement Git.
Intégration Git (CI) : synchronise les éléments de l’espace de travail (par exemple, le code, les configurations, les API) avec les référentiels de contrôle de version, en activant le contrôle de version et le suivi des modifications via Git.
Pipelines de déploiement (CD) : permet la création d’étapes (par exemple, développement, test, production) avec des espaces de travail liés. Les éléments pris en charge dans chaque étape sont automatiquement répliqués aux étapes suivantes, et les modifications dans un espace de travail déclenchent le déploiement dans un pipeline de publication. Vous pouvez configurer le pipeline pour vous assurer que les modifications sont testées et déployées efficacement dans les environnements.
Fabric prend en charge différents flux de travail CI/CD adaptés aux scénarios courants. Pour plus d’informations, consultez les options de flux de travail CI/CD dans Fabric.
Remarque
Seules les métadonnées sont copiées pendant le déploiement ; et les données ne sont pas copiées.
Les éléments de l’espace de travail sont stockés dans le référentiel Git associé en tant qu'Infrastructure as Code (IaC). Les modifications de code dans le référentiel peuvent déclencher le déploiement dans les pipelines. Cette méthode vous permet de répliquer automatiquement les modifications de code entre les étapes à des fins de test et de mise en production.
Méthodes d’authentification de source de données
Lorsque vous créez votre API pour GraphQL, vous choisissez la façon dont les clients authentifient et accèdent à vos sources de données. Ce choix a des répercussions importantes sur les pipelines de déploiement et le comportement de liaison automatique. La compréhension de ces méthodes d’authentification est essentielle pour planifier votre flux de travail CI/CD. Pour plus d’informations sur la liaison automatique et le processus de déploiement, consultez Comprendre le processus de déploiement.
Il existe deux options de connectivité disponibles lors de la connexion de sources de données à votre API pour GraphQL : l’authentification unique (SSO) et les informations d’identification enregistrées.

Authentification unique (SSO)
Avec l’authentification unique, les clients d’API utilisent leurs propres informations d’identification pour accéder aux sources de données. L’utilisateur de l’API authentifié doit disposer d’autorisations pour l’API et la source de données sous-jacente.
Utilisez l’authentification unique quand :
- Exposition des sources de données Fabric (les lakehouses, les entrepôts, les points de terminaison pour l'analyse SQL)
- Vous souhaitez que les utilisateurs accèdent aux données en fonction de leurs autorisations individuelles
- Vous avez besoin d’une sécurité au niveau des lignes ou d’autres stratégies d’accès aux données à appliquer par utilisateur
Exigences d’autorisation :
- Les utilisateurs d’API ont besoin d’autorisations d’exécution sur l’API GraphQL (Exécuter des requêtes et mutations)
- Les utilisateurs d’API ont besoin d’autorisations de lecture ou d’écriture sur la source de données
- Vous pouvez également ajouter des utilisateurs en tant que membres de l’espace de travail avec le rôle Contributeur où se trouvent à la fois l’API et la source de données
Comportement de liaison automatique dans les pipelines de déploiement : Lorsque vous déployez une API à l’aide de SSO (authentification unique) à partir de l’espace de travail source (par exemple, Dev) dans l’espace de travail cible (par exemple, Test) :
- La source de données et l’API GraphQL sont tous deux déployés sur l’espace de travail cible
- L’API de l’espace de travail cible est automatiquement liée à la copie de la source de données locale dans l’espace de travail cible
- Chaque environnement (Dev, Test, Production) utilise sa propre instance de source de données
Remarque
Il existe des limitations spécifiques lors de l'utilisation du SSO avec des endpoints SQL Analytics. Pour plus d’informations, consultez les limitations actuelles .
Informations d’identification enregistrées
Avec les informations d’identification enregistrées, une seule information d’identification partagée s’authentifie entre l’API et les sources de données. Les utilisateurs d’API doivent uniquement accéder à l’API elle-même, et non aux sources de données sous-jacentes.
Utilisez les informations d’identification enregistrées lorsque :
- Exposition de sources de données Azure (Azure SQL Database, bases de données externes)
- Vous souhaitez simplifier la gestion des autorisations (les utilisateurs ont uniquement besoin d’un accès API)
- Tous les utilisateurs d’API doivent accéder aux mêmes données avec les mêmes autorisations
- Vous avez besoin d’informations d’identification cohérentes dans toutes les demandes d’API
Exigences d’autorisation :
- Les utilisateurs d’API ont uniquement besoin d’autorisations d’exécution sur l’API GraphQL (Exécuter des requêtes et mutations)
- Les informations d’identification enregistrées doivent disposer d’autorisations appropriées sur la source de données
- Les développeurs qui déploient l’API doivent avoir accès aux informations d’identification enregistrées
Comportement de liaison automatique dans les pipelines de déploiement : Lorsque vous déployez une API à l’aide d’informations d’identification enregistrées à partir de l’espace de travail source (Dev) dans l’espace de travail cible (test) :
- La source de données est déployée sur l’espace de travail cible
- L’API de l’espace de travail cible reste connectée à la source de données dans l’espace de travail source (Dev)
- La liaison automatique ne se produit pas : l’API déployée continue à utiliser les informations d’identification enregistrées pointant vers la source de données d’origine
- Vous devez reconfigurer manuellement les connexions ou créer des informations d’identification enregistrées dans chaque environnement cible
Important
Une fois que vous avez choisi une méthode d’authentification pour votre API, elle s’applique à toutes les sources de données ajoutées à cette API. Vous ne pouvez pas combiner l’authentification unique et les informations d’identification enregistrées dans la même API.
Connexions entre espaces de travail
Si votre API dans l’espace de travail source (Dev) se connecte à une source de données dans un autre espace de travail, l’API déployée dans l’espace de travail cible (Test) reste connectée à cette source de données externe , quelle que soit la méthode d’authentification. La liaison automatique fonctionne uniquement lorsque l’API et la source de données se trouvent dans le même espace de travail source.
Le diagramme suivant illustre ces scénarios de déploiement :

Pour plus d’informations sur la configuration de ces méthodes d’authentification lors de la création de votre API, consultez Se connecter à une source de données.
Intégration Git avec l’API GraphQL
L’API Fabric pour GraphQL prend en charge l’intégration Git, ce qui vous permet de gérer vos API GraphQL en tant que code dans votre système de contrôle de version. Cette intégration fournit l’historique des versions, la collaboration par le biais de branches et de pull requests, la possibilité de rétablir les modifications et un journal d’audit complet des modifications d’API. En traitant votre configuration d’API GraphQL comme Infrastructure as Code (IaC), vous pouvez appliquer les meilleures pratiques de développement logiciel à votre couche d’accès aux données.
L’intégration Git est essentielle pour :
- Contrôle de version : suivre toutes les modifications apportées à votre schéma GraphQL, aux connexions de source de données et aux relations au fil du temps
- Collaboration : Travailler avec les membres de l’équipe à l’aide de branches, de demandes de tirage et de révisions de code
- Fonctionnalité de restauration : rétablir les configurations d’API précédentes lorsque des problèmes se produisent
- Promotion de l’environnement : Utiliser Git comme source de vérité pour déployer des API dans des environnements
Connecter votre espace de travail à Git
Pour activer l’intégration Git pour vos API GraphQL :
- Ouvrir les paramètres de l’espace de travail pour l’espace de travail contenant votre API pour GraphQL
- Configurer la connexion Git à votre référentiel (Azure DevOps, GitHub ou un autre fournisseur Git)
- Une fois connectés, tous les éléments de l’espace de travail, y compris les API pour GraphQL, apparaissent dans le panneau de configuration source
Pour obtenir des instructions d’installation détaillées, consultez Prise en main de l’intégration git.

Valider et synchroniser vos API GraphQL
Après vous être connecté à Git, vous pouvez valider votre API pour les configurations GraphQL dans le référentiel. Chaque validation crée un instantané de votre définition d’API, notamment :
- Définitions de schéma GraphQL
- Connexions à la source de données et paramètres d’authentification
- Configurations de relation
- Définitions de requête et de mutation
Une fois validées, vos API GraphQL apparaissent dans votre référentiel Git avec une hiérarchie de dossiers structurée. À partir de ce point, vous pouvez utiliser les flux de travail Git standard, tels que la création de pull requests, la gestion des branches et la collaboration avec votre équipe via des révisions de code. Pour plus d’informations sur l’utilisation des branches, consultez Gérer les branches.
Représentation de l’API GraphQL dans Git
Chaque API pour l’élément GraphQL est stockée dans Git avec une structure de dossiers bien définie qui représente tous les aspects de votre configuration d’API :

Les fichiers de définition d’API contiennent toutes les métadonnées nécessaires pour recréer votre API GraphQL dans n’importe quel espace de travail Fabric. Cela inclut les définitions de schéma, les mappages de sources de données et les paramètres de configuration. Lorsque vous effectuez une synchronisation de Git vers un espace de travail Fabric, le système utilise ces fichiers de définition pour restaurer votre API exactement dans l'état où elle était au moment de sa validation.

Utilisation des fichiers de définition d’API :
Le format de définition de l’API GraphQL suit les normes Infrastructure as Code (IaC) de Fabric. Vous pouvez afficher et modifier ces fichiers directement dans votre référentiel Git, bien que la plupart des modifications doivent être apportées via le portail Fabric pour garantir la validité du schéma. Les fichiers de définition sont particulièrement utiles pour :
- Révisions de code : les membres de l’équipe peuvent examiner les modifications des API dans les requêtes de tirage
- Documentation : Les fichiers servent de documentation de votre structure d’API
- Automatisation : les pipelines CI/CD peuvent lire ces fichiers pour comprendre les configurations d’API
- Récupération d’urgence : les définitions d’API complètes sont conservées dans le contrôle de version
Pour plus d’informations sur le format, la syntaxe et les exemples de définition de l’API GraphQL, consultez la documentation des API du plan de contrôle Fabric :
API pour GraphQL dans le pipeline de déploiement
Les pipelines de déploiement vous permettent de promouvoir votre API pour les configurations GraphQL dans les environnements (généralement développement, test et production). Lorsque vous déployez une API pour GraphQL via un pipeline, seules les métadonnées de l’API sont copiées, notamment les définitions de schéma, les connexions de source de données et les configurations de relation. Les données réelles restent dans les sources de données connectées et ne sont pas copiées pendant le déploiement.
Considérations clés relatives au déploiement :
Avant de déployer, découvrez comment les méthodes d’authentification et l’organisation de l’espace de travail affectent votre déploiement :
- Les API utilisant l’authentification unique (Sign-On SSO) peuvent se connecter automatiquement à des sources de données locales dans l’espace de travail cible (lorsque la source de données a également été déployée à partir du même espace de travail source)
- Les API utilisant les informations d’identification enregistrées ne sont pas autobinées et restent connectées à la source de données de l’espace de travail source
- Les sources de données inter-espaces de travail ne sont jamais liées automatiquement, quelle que soit la méthode d’authentification
Pour une compréhension complète du processus de déploiement, consultez Comprendre le processus de déploiement.
Déployer votre API pour GraphQL
Pour déployer votre API pour GraphQL à l’aide de pipelines de déploiement :
Créez un pipeline de déploiement ou ouvrez un pipeline de déploiement existant. Pour obtenir des instructions détaillées, consultez Prise en main des pipelines de déploiement.
Affectez des espaces de travail aux phases de pipeline (Développement, Test, Production) en fonction de votre stratégie de déploiement. Chaque étape doit avoir un espace de travail dédié.
Passez en revue et comparez les éléments entre les étapes. Le pipeline indique les API pour GraphQL qui ont changé, indiquées par les nombres d’éléments dans les zones mises en surbrillance. Cette comparaison vous aide à comprendre ce qui sera affecté par le déploiement.
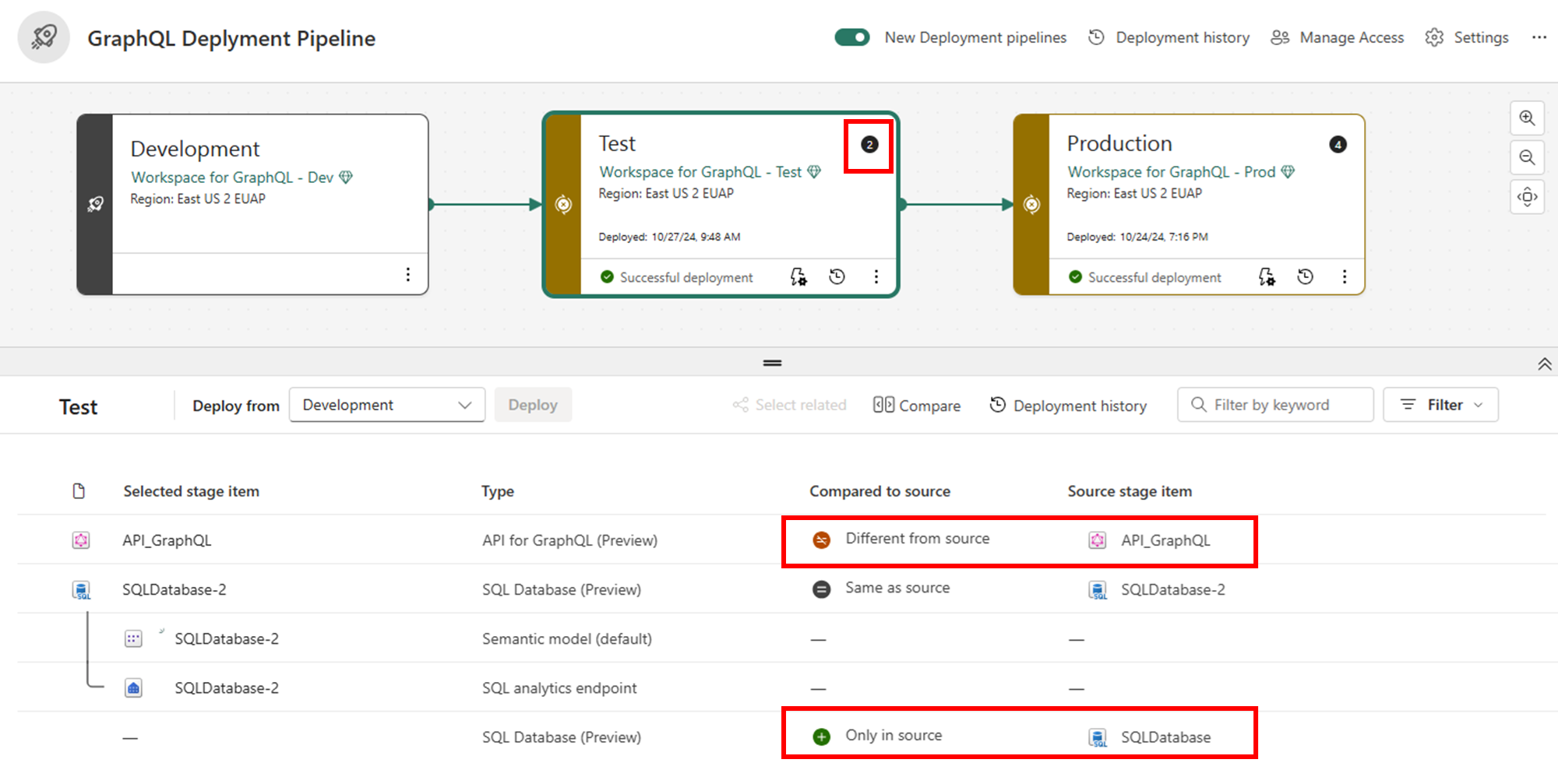
Sélectionnez les API pour GraphQL et tous les éléments associés (tels que les sources de données connectées) que vous souhaitez déployer. Sélectionnez Ensuite Déployer pour les déplacer vers la phase suivante.
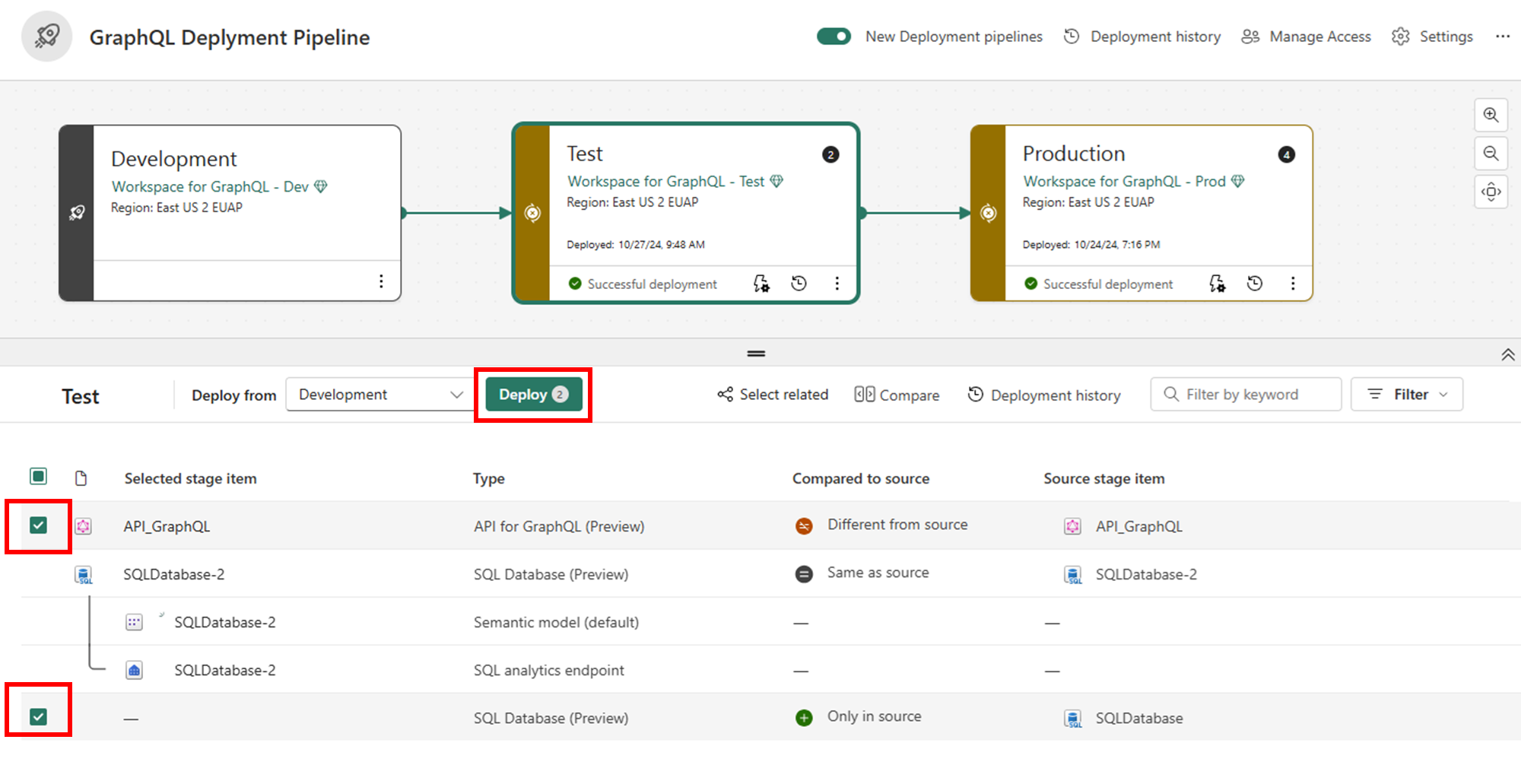
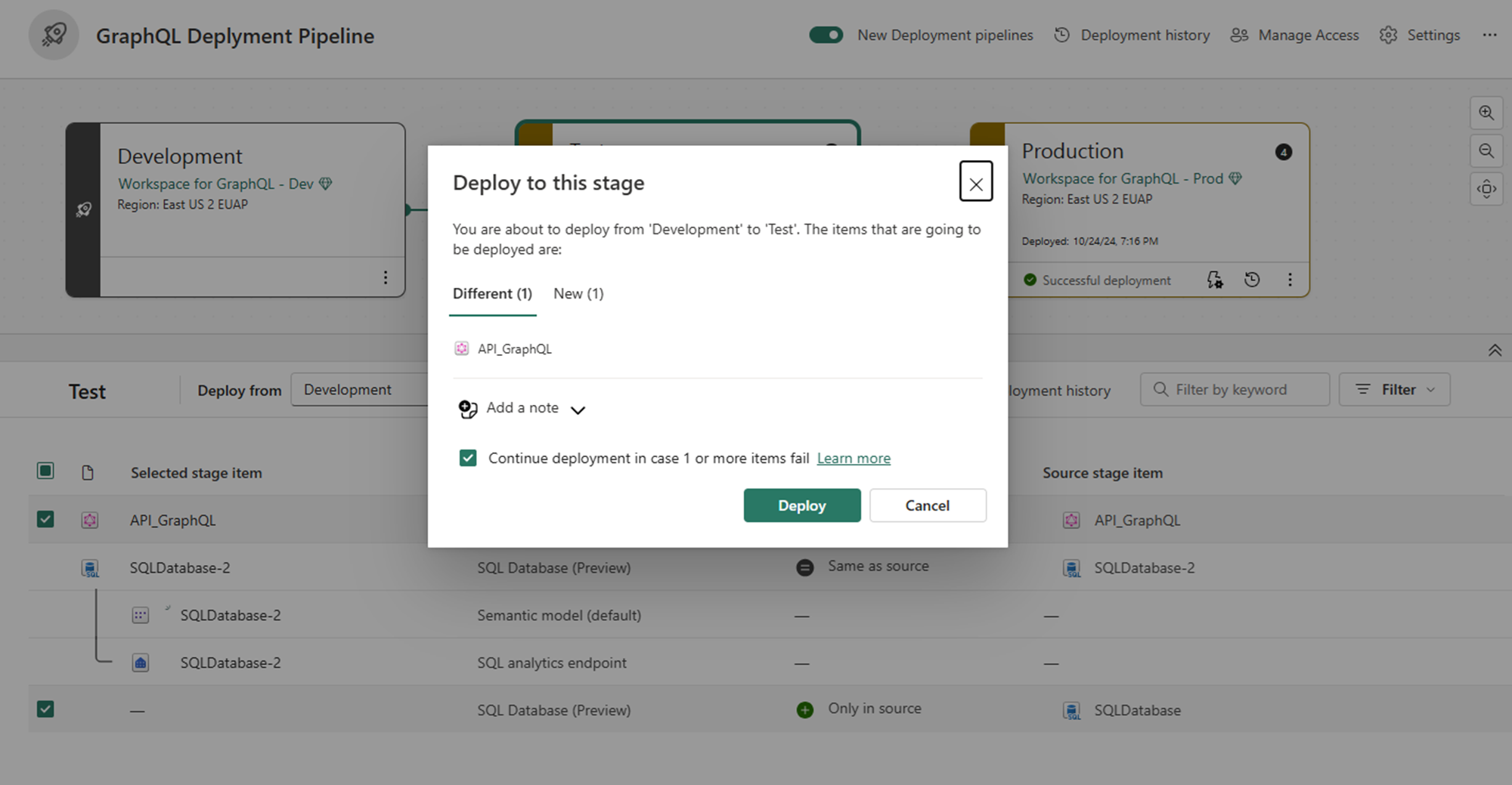
Passez en revue la boîte de dialogue de confirmation du déploiement, qui affiche tous les éléments sur le point d’être déployés. Sélectionnez Déployer pour continuer.



Limitations actuelles
Lors du déploiement d’API pour GraphQL via des pipelines de déploiement, la liaison automatique présente les limitations suivantes :
Éléments enfants : la liaison automatique ne fonctionne pas lorsque l’API se connecte à un point de terminaison SQL Analytics qui est un enfant d’une source de données parente (par exemple, lakehouse). L’API déployée reste connectée au point de terminaison de l’espace de travail source.
Informations d’identification enregistrées : les API utilisant la méthode d’authentification des informations d’identification enregistrées ne prennent pas en charge la liaison automatique. L’API reste connectée à la source de données de l’espace de travail source après le déploiement.
Pour plus d’informations sur les méthodes d’authentification et leur comportement de liaison automatique, consultez les méthodes d’authentification de source de données.