Conseils sur les performances pour le SDK Java v4 Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL
Important
Ces conseils en matière de performances concernent uniquement le SDK Java v4 Azure Cosmos DB. Pour plus d’informations, consultez les notes de publication du SDK Java v4 Azure Cosmos DB, le dépôt Maven et le guide de dépannage du SDK Java v4 Azure Cosmos DB. Si vous utilisez actuellement une version antérieure à v4, consultez le guide de migration vers le SDK Java v4 Azure Cosmos DB pour obtenir de l’aide sur la mise à niveau.
Azure Cosmos DB est une base de données distribuée rapide et flexible qui peut être mise à l’échelle en toute transparence avec une latence et un débit garantis. Vous n’avez pas à apporter de modifications d’architecture majeures ou écrire de code complexe pour mettre à l’échelle votre base de données avec Azure Cosmos DB. La réduction et l’augmentation de l’échelle est aussi simple que le passage d’un appel d’API ou de Kit de développement logiciel (SDK). Toutefois, étant donné qu’Azure Cosmos DB est accessible au moyen d’appels réseau, vous pouvez apporter des optimisations côté client de manière à atteindre des performances de pointe quand vous utilisez le SDK Java v4 Azure Cosmos DB.
Par exemple, si vous vous demandez comment améliorer les performances de votre base de données, envisagez les options suivantes :
Mise en réseau
Colocaliser les clients dans la même région Azure pour de meilleures performances
Dans la mesure du possible, placez toutes les applications appelant Azure Cosmos DB dans la même région que la base de données Azure Cosmos DB. Pour une comparaison approximative, les appels à Azure Cosmos DB dans la même région s’effectuent en 1 à 2 ms, mais la latence entre les côtes Ouest et Est des États-Unis est >50 ms. Cette latence peut probablement varier d’une requête à l’autre, en fonction de l’itinéraire utilisé par la requête lorsqu’elle passe du client à la limite du centre de données Azure. Pour obtenir la latence la plus faible possible, l’application appelante doit être située dans la même région Azure que le point de terminaison Azure Cosmos DB configuré. Pour obtenir la liste des régions disponibles, voir Régions Azure.
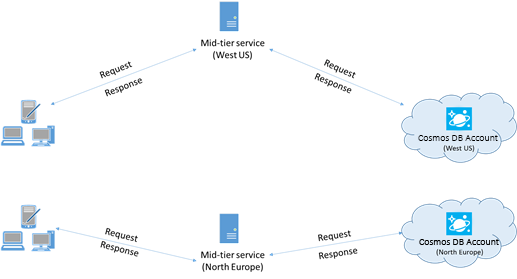
Une application qui interagit avec un compte Azure Cosmos DB multirégion doit configurer des emplacements préférés pour que les demandes soient transmises à une région colocalisée.
Activer la mise en réseau accélérée pour réduire la latence et la gigue du processeur
Nous vous recommandons vivement de suivre les instructions relatives à l’activation des performances réseau accélérées sur votre machine virtuelle Azure Windows (instructions ici) ou Linux (instructions ici) pour optimiser les performances en réduisant la latence et la gigue au niveau du processeur.
Sans les performances réseau accélérées, les E/S qui transitent entre votre machine virtuelle Azure et d’autres ressources Azure risquent d’être routées via un hôte et un commutateur virtuel situés entre la machine virtuelle et sa carte réseau. Le fait d’avoir l’hôte et le commutateur virtuel inline dans le chemin de données entraîne non seulement une augmentation de la latence et de l’instabilité dans le canal de communication, mais aussi le vol des cycles processeur de la machine virtuelle. En activant les performances réseau accélérées, la machine virtuelle s’interface directement avec la carte réseau sans intermédiaires. Tous les détails de la stratégie réseau sont gérés dans le matériel de la carte réseau, en contournant l’hôte et le commutateur virtuel. L’activation de l’accélération réseau se traduit généralement par une latence plus faible et plus cohérente, un débit plus élevé et une utilisation réduite du processeur.
Limitations : l’accélération réseau doit être prise en charge sur le système d’exploitation de la machine virtuelle et ne peut être activée que si la machine virtuelle est arrêtée et libérée. La machine virtuelle ne peut pas être déployée avec Azure Resource Manager. App Service n’a pas de réseau accéléré activé.
Pour plus d’informations, consultez les instructions propres à Windows et à Linux.
Haute disponibilité
Pour obtenir des conseils généraux sur la configuration de la haute disponibilité dans Azure Cosmos DB, consultez Haute disponibilité dans Azure Cosmos DB.
Outre une bonne configuration de base dans la plateforme de base de données, il existe des techniques spécifiques qui peuvent être implémentées dans le Kit de développement logiciel (SDK) Java lui-même, ce qui peut vous aider dans des scénarios de panne. Deux stratégies notables sont la stratégie de disponibilité basée sur le seuil et le disjoncteur au niveau de la partition.
Ces techniques fournissent des mécanismes avancés pour résoudre des problèmes spécifiques de latence et de disponibilité, allant au-delà des capacités de nouvelle tentative inter-région intégrées au Kit de développement logiciel (SDK) par défaut. En gérant de manière proactive les problèmes potentiels aux niveaux de la requête et de la partition, ces stratégies peuvent améliorer considérablement la résilience et le niveau de performance de votre application, en particulier dans des conditions de charge élevée ou détériorées.
Stratégie de disponibilité basée sur le seuil
La stratégie de disponibilité basée sur le seuil peut améliorer la latence de fin et la disponibilité en envoyant des demandes de lecture parallèles aux régions secondaires et en acceptant la réponse la plus rapide. Cette approche peut réduire considérablement l’impact des pannes régionales ou des conditions à latence élevée sur le niveau de performance des applications. En outre, la gestion proactive des connexions peut être utilisée pour améliorer le niveau de performance en préchauffant les connexions et les caches, à la fois dans la région de lecture active et les régions distantes préférées.
Exemple de configuration :
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Fonctionnement :
Requête initiale : au moment T1, une demande de lecture est effectuée dans la région primaire (par exemple, USA Est). Le Kit de développement logiciel (SDK) attend une réponse jusqu’à 500 millisecondes (valeur
threshold).Deuxième requête : s’il n’existe aucune réponse de la région primaire dans les 500 millisecondes, une requête parallèle est envoyée à la région préférée suivante (par exemple, USA Est 2).
Troisième requête : si ni la région primaire ni la région secondaire ne répondent dans les 600 millisecondes (500 ms + 100 ms, valeur
thresholdStep), le SDK envoie une autre re parallèle à la troisième région préférée (par exemple, USA Ouest).Réponse la plus rapide gagne : quelle que soit la région qui répond en premier, cette réponse est acceptée et les autres requêtes parallèles sont ignorées.
La gestion proactive des connexions préchauffe les connexions et les caches pour les conteneurs dans les régions préférées, ce qui permet de réduire la latence de démarrage à froid pour les scénarios de basculement ou pour les écritures dans les configurations multi-régions.
Cette stratégie peut améliorer considérablement la latence dans les scénarios où une région spécifique est lente ou temporairement indisponible, mais elle peut entraîner un coût plus élevé en termes d’unités de requête lorsque des requêtes inter-régions parallèles sont nécessaires.
Remarque
Si la première région préférée retourne un code d’état d’erreur non temporaire (par exemple, document introuvable, erreur d’autorisation, conflit, etc.), l’opération échoue rapidement, car la stratégie de disponibilité n’aurait aucun avantage dans ce scénario.
Disjoncteur au niveau de la partition
Le disjoncteur au niveau de la partition améliore la latence de fin et la disponibilité de l’écriture en suivant et en court-circuitant les requêtes vers des partitions physiques non saines. Il améliore le niveau de performance en évitant les partitions problématiques connues et en redirigeant les requêtes vers des régions plus saines.
Exemple de configuration :
Pour activer le disjoncteur au niveau de la partition :
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Pour définir la fréquence du processus en arrière-plan pour la vérification des régions indisponibles :
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Pour définir la durée pendant laquelle une partition peut rester indisponible :
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Fonctionnement :
Échecs de suivi : le Kit de développement logiciel (SDK) suit les échecs de terminal (par exemple, 503s, 500s, délais d’expiration) pour les partitions individuelles dans des régions spécifiques.
Marquage comme non disponible : si une partition d’une région dépasse un seuil configuré d’échecs, elle est marquée comme « Unavailable » (non disponible). Les requêtes suivantes adressées à cette partition sont court-circuitées et redirigées vers d’autres régions plus saines.
Récupération automatisée : un thread en arrière-plan vérifie régulièrement les partitions indisponibles. Après une certaine durée, ces partitions sont provisoirement marquées comme « HealthyTentative » (tentative saine) et soumises à des requêtes de test pour valider la récupération.
Promotion/rétrogradation de l’intégrité : en fonction de la réussite ou de l’échec de ces requêtes de test, l’état de la partition est promu à nouveau comme « Healthy » (saine) ou rétrogradé une fois de plus à « Unavailable » (non disponible).
Ce mécanisme permet de surveiller en permanence l’intégrité des partitions et garantit que les requêtes sont traitées avec une latence minimale et une disponibilité maximale, sans être consignées par des partitions problématiques.
Remarque
Le disjoncteur s’applique uniquement aux comptes d’écriture multi-régions, comme lorsqu’une partition est marquée comme Unavailable, les lectures et les écritures sont déplacées vers la région préférée suivante. Cela permet d’éviter que les lectures et les écritures provenant de différentes régions soient traitées à partir de la même instance cliente, car cela s’agirait d’un anti-modèle.
Important
Vous devez utiliser la version 4.63.0 du Kit de développement logiciel (SDK) Java ou une version ultérieure pour activer le disjoncteur au niveau de la partition.
Comparaison des optimisations de disponibilité
Stratégie de disponibilité basée sur le seuil :
- Avantage : Réduit la latence de fin en envoyant des demandes de lecture parallèles aux régions secondaires et améliore la disponibilité en préemptant les requêtes qui entraînent des délais d’attente réseau.
- Compromis : Entraîne des coûts supplémentaires de RU (unités de requête) par rapport au disjoncteur, en raison des demandes parallèles supplémentaires entre régions (mais uniquement pendant les périodes où les seuils sont dépassés).
- Cas d’utilisation : optimal pour les charges de travail lourdes en lecture, où la réduction de la latence est critique et un coût supplémentaire (en termes de frais de RU et de pression du processeur client) est acceptable. Les opérations d’écriture peuvent également bénéficier, si elles sont choisies dans une stratégie de nouvelle tentative d’écriture non idempotente et que le compte a des écritures multi-régions.
Disjoncteur au niveau de la partition :
- Avantage : Améliore la disponibilité et la latence en évitant les partitions non saines, ce qui garantit que les demandes sont acheminées vers des régions plus saines.
- Compromis : N’entraîne aucun coût supplémentaire de RU, mais peut toujours permettre une certaine perte de disponibilité initiale pour les requêtes qui entraînent des délais d’expiration du réseau.
- Cas d’utilisation : idéal pour les charges de travail lourdes ou mixtes d’écriture, où le niveau de performance cohérent est essentiel, en particulier lorsque vous traitez des partitions qui peuvent devenir non saines par intermittence.
Ces deux stratégies peuvent être utilisées conjointement pour améliorer la disponibilité de la lecture et de l’écriture et réduire le temps de latence de fin. Le disjoncteur au niveau de la partition peut gérer une variété de scénarios de défaillance transitoire, y compris ceux qui peuvent entraîner un ralentissement des réplicas, sans qu’il soit nécessaire d’effectuer des requêtes en parallèle. En outre, l’ajout d’une stratégie de disponibilité basée sur un seuil permettra de réduire davantage la latence de fin et d’éliminer la perte de disponibilité, si le coût supplémentaire de RU est acceptable.
En implémentant ces stratégies, les développeurs peuvent s’assurer que leurs applications restent résilientes, conservent un niveau de performance élevé et offrent une meilleure expérience utilisateur même pendant les pannes régionales ou les conditions à latence élevée.
Cohérence de session délimitée par la région
Vue d’ensemble
Pour plus d’informations sur les paramètres de cohérence en général, consultez Niveaux de cohérence dans Azure Cosmos DB. Le Kit de développement logiciel (SDK) Java fournit une optimisation pour la cohérence de session pour les comptes d’écriture multi-régions, en lui permettant d’être délimitée par la région. Cela améliore le niveau de performance en réduisant la latence de réplication inter-région grâce à une réduction des nouvelles tentatives côté client. Cela est réalisé en gérant les jetons de session au niveau de la région plutôt qu’au niveau mondial. Si la cohérence dans votre application peut être délimitée à un plus petit nombre de régions, en implémentant la cohérence de session à l’échelle régionale, vous pouvez obtenir un meilleur niveau de performance et une meilleure fiabilité pour les opérations de lecture et d’écriture dans des comptes à plusieurs écritures en réduisant les délais et les nouvelles tentatives de réplication inter-région.
Avantages
- Latence réduite : en localisant la validation des jetons de session au niveau de la région, les chances de nouvelles tentatives inter-régions coûteuses sont réduites.
- Niveau de performance amélioré : réduit l’impact du basculement régional et du décalage de réplication, offrant une cohérence de lecture/écriture plus élevée et une faible utilisation du processeur.
- Utilisation optimisée des ressources : réduit le traitement du processeur et du réseau sur les applications clientes en limitant la nécessité de nouvelles tentatives et d’appels inter-régions, ce qui optimise l’utilisation des ressources.
- Haute disponibilité : en conservant des jetons de session à l’échelle régionale, les applications peuvent continuer à s’exécuter sans problème même si certaines régions rencontrent une latence plus élevée ou des défaillances temporaires.
- Garanties de cohérence : assure que les garanties de cohérence de session (lecture de votre écriture, lecture monotonique) sont respectées de manière plus fiable sans nouvelles tentatives inutiles.
- Rentabilité : réduit le nombre d’appels inter-régions, réduisant ainsi potentiellement les coûts associés aux transferts de données entre les régions.
- Scalabilité : permet aux applications de mettre à l’échelle plus efficacement en réduisant la contention et le traitement associés à la gestion d’un jeton de session global, en particulier dans les configurations multi-régions.
Compromis
- Utilisation accrue de la mémoire : le filtre de Bloom et le stockage de jetons de session spécifiques à la région nécessitent une mémoire supplémentaire, ce qui peut être une considération à prendre en compte pour les applications avec des ressources limitées.
- Complexité de la configuration : ajuster le nombre d’insertions attendu et le taux de faux positifs pour le filtre de Bloom ajoute une couche de complexité au processus de configuration.
- Potentiel de faux positifs : même si le filtre de Bloom réduit les nouvelles tentatives inter-régions, il existe toujours une légère probabilité de faux positifs impactant la validation du jeton de session, bien que le taux puisse être contrôlé. Un faux positif signifie que le jeton de session global est résolu, ce qui augmente la probabilité de nouvelles tentatives inter-régions si la région locale n’a pas rattrapé cette session globale. Les garanties de session sont respectées même en présence de faux positifs.
- Applicabilité : cette fonctionnalité est particulièrement avantageuse pour les applications avec une cardinalité élevée des partitions logiques et des redémarrages réguliers. Les applications avec moins de partitions logiques ou des redémarrages peu fréquents pourraient ne pas bénéficier d’avantages significatifs.
Fonctionnement
Définir le jeton de session
- Achèvement de la requête : une fois qu’une requête est terminée, le Kit de développement logiciel (SDK) capture le jeton de session et l’associe à la région et à la clé de partition.
- Stockage au niveau de la région : les jetons de session sont stockés dans une
ConcurrentHashMapimbriquée qui gère les mappages entre les plages de clés de partition et la progression au niveau de la région. - Filtre de Bloom : un filtre de Bloom effectue le suivi des régions auxquelles chaque partition logique a accédé, ce qui permet de localiser la validation des jetons de session.
Résoudre le jeton de session
- Initialisation de la requête : avant l’envoi d’une demande, le Kit de développement logiciel (SDK) tente de résoudre le jeton de session pour la région appropriée.
- Vérification du jeton : le jeton est vérifié par rapport aux données spécifiques à la région pour vous assurer que la requête est acheminée vers le réplica le plus à jour.
- Logique de nouvelle tentative : si le jeton de session n’est pas validé dans la région actuelle, le Kit de développement logiciel (SDK) fait une nouvelle tentative avec d’autres régions, mais étant donné le stockage localisé, cela est moins fréquent.
Utiliser le kit SDK
Voici comment initialiser CosmosClient avec une cohérence de session délimitée par la région :
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Activer la cohérence de session délimitée par la région
Pour activer la capture de session délimitée par la région dans votre application, définissez la propriété système suivante :
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Configurer le filtre de Bloom
Ajustez le niveau de performance en configurant les insertions attendues et le taux de faux positifs pour le filtre de Bloom :
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implications sur la mémoire
Vous trouverez ci-dessous la taille retenue (taille de l’objet et tout ce dont elle dépend) du conteneur de session interne (géré par le Kit de développement logiciel (SDK)) avec différentes insertions attendues dans le filtre de Bloom.
| Insertions attendues | Taux de faux positifs | Taille retenue |
|---|---|---|
| 10, 000 | 0,001 | 21 Ko |
| 100, 000 | 0,001 | 183 Ko |
| 1 million | 0,001 | 1,8 Mo |
| 10 millions | 0,001 | 17,9 Mo |
| 100 millions | 0,001 | 179 Mo |
| 1 milliard | 0,001 | 1,8 Go |
Important
Vous devez utiliser la version 4.60.0 du Kit de développement logiciel (SDK) Java ou une version ultérieure pour activer la cohérence de session délimitée par la région.
Réglage de la configuration directe et de la connexion de passerelle
Pour optimiser les configurations de connexion directes et en mode passerelle, découvrez comment paramétrer les configurations de connexion pour le Kit de développement logiciel (SDK) Java v4.
Utilisation du Kit de développement logiciel (SDK)
- Installation du kit de développement logiciel (SDK) le plus récent
Les SDK Azure Cosmos DB sont constamment améliorés pour fournir des performances optimales. Pour connaître les améliorations les plus récentes du SDK, consultez le SDK Azure Cosmos DB.
Chaque instance du client Azure Cosmos DB est thread-safe et effectue une gestion des connexions efficace et une mise en cache d’adresses. Pour permettre une gestion des connexions efficace par le client Azure Cosmos DB et améliorer ses performances, nous vous recommandons vivement d’utiliser une seule instance du client Azure Cosmos DB pour la durée de vie de l’application.
Quand vous créez un CosmosClient, la cohérence par défaut utilisée est Session si elle n’est pas explicitement définie. Si la cohérence Session n’est pas requise par votre logique d’application, attribuez Eventual à Consistency. Remarque : Nous vous recommandons d’utiliser au moins une cohérence Session dans les applications employant le processeur de flux de modification Azure Cosmos DB.
- Utiliser l’API Async pour maximiser le débit provisionné
Le SDK Java v4 Azure Cosmos DB regroupe deux API : Sync et Async. En gros, l’API Async implémente la fonctionnalité du SDK, tandis que l’API Sync est un wrapper dynamique qui effectue des appels de blocage à l’API Async. Cela vient trancher avec l’ancien SDK Java v2 Async Azure Cosmos DB, qui était uniquement asynchrone, et avec l’ancien SDK Java v2 Sync Azure Cosmos DB, qui était uniquement synchrone et dont l’implémentation était séparée.
Le choix de l’API est déterminé lors de l’initialisation du client : un CosmosAsyncClient prend en charge l’API Async alors qu’un CosmosClient prend en charge l’API Sync.
L’API Async implémente des E/S non bloquantes et constitue le meilleur choix si votre objectif est de maximiser le débit lors de l’émission de requêtes à destination d’Azure Cosmos DB.
L’utilisation de l’API Sync peut être un bon choix si vous voulez une API qui se bloque lors de la réponse à chaque requête, ou si l’opération synchrone est le paradigme dominant dans votre application. Par exemple, vous pouvez utiliser l’API Sync quand vous persistez des données sur Azure Cosmos DB dans une application de microservices, à condition toutefois que le débit ne soit pas critique.
Notez que le débit de l’API Sync se dégrade avec l’augmentation du temps de réponse aux requêtes, tandis que l’API Async peut saturer les capacités de bande passante totale de votre matériel.
La colocalisation géographique peut vous faire bénéficier d’un débit plus élevé et plus cohérent lors de l’utilisation de l’API Sync (consultez Colocaliser des clients dans la même région Azure pour les performances), mais elle n’est pas censée dépasser le débit possible de l’API Async.
Certains utilisateurs ne connaissent peut-être pas non plus Project Reactor, l’infrastructure Reactive Streams utilisée pour implémenter l’API Async du kit SDK Java Azure Cosmos DB v4. Si cela pose problème, nous vous recommandons de lire notre guide de présentation des modèles Reactor, puis de consulter cette introduction à la programmation réactive pour vous familiariser avec ces outils. Si vous avez déjà utilisé Azure Cosmos DB avec une interface Async, et si vous avez déjà utilisé le kit SDK Async Java v2 Azure Cosmos DB, vous connaissez peut-être ReactiveX/RxJava, mais vous ne savez pas ce qui a changé dans Project Reactor. Dans ce cas, consultez notre guide sur Reactor et RxJava pour en savoir plus.
Les extraits de code suivants montrent comment initialiser votre client Azure Cosmos DB pour l’API Async ou l’API Sync, respectivement :
API asynchrone du kit SDK Java V4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Effectuer un scale-out de votre charge de travail cliente
Si vous effectuez des tests à des niveaux de débit élevés, l’application cliente peut devenir le goulot d’étranglement en raison du plafonnement de la machine en ce qui concerne l’utilisation du processeur ou du réseau. Si vous atteignez ce point, vous pouvez continuer à augmenter le compte Azure Cosmos DB en augmentant la taille des instances de vos applications clientes sur plusieurs serveurs.
La règle générale est ne pas utiliser >50 % du processeur sur un serveur donné pour maintenir la latence à un niveau minimal.
- Utilisation du Scheduler approprié (éviter le vol de threads Netty E/S Eventloop)
Les fonctionnalités asynchrones du SDK Java Azure Cosmos DB sont basées sur des E/S non bloquantes netty. Le Kit de développement logiciel (SDK) utilise un nombre fixe de threads d’E/S netty eventloop (autant de cœurs de processeur présents sur votre machine) pour l’exécution d’opérations d’E/S. Le Flux retourné par l’API émet le résultat sur l’un des threads netty eventloop d’E/S partagés. Il est donc important de ne pas bloquer les threads netty eventloop d’E/S partagés. Le fait d’effectuer un travail qui consomme beaucoup de ressources au niveau du processeur, ou d’être confronté à un blocage d’opération sur le thread netty eventloop d’E/S peut provoquer un interblocage, ou réduire considérablement le débit du kit SDK.
Par exemple, le code suivant exécute un travail gourmand en processeur sur le thread netty eventloop d’E/S :
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Une fois le résultat reçu, vous devez éviter d’effectuer tout travail nécessitant beaucoup de ressources du processeur sur le résultat sur le thread netty d’E/S eventloop. Vous pouvez fournir à la place votre propre Scheduler pour fournir votre propre thread pour l’exécution de votre travail, comme indiqué ci-dessous (nécessite import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
En fonction du type de votre travail, vous devez utiliser le Scheduler Reactor existant approprié. Lire ici Schedulers.
Pour bien comprendre le modèle de threading et de planification de Project Reactor, consultez ce billet de blog de Project Reactor.
Pour plus d’informations sur le SDK Java v4 Azure Cosmos DB, consultez le répertoire Azure Cosmos DB du SDK Azure pour le dépôt unique Java sur GitHub.
- Optimiser les paramètres de journalisation dans votre application
Pour différentes raisons, vous devez ajouter la journalisation dans un thread qui génère un débit de requête élevé. Si votre objectif est de saturer complètement le débit provisionné d’un conteneur avec les requêtes générées par ce thread, les optimisations de la journalisation peuvent améliorer considérablement les performances.
- Configurer un enregistreur asynchrone
La latence d’un enregistreur d’événements synchrone prend nécessairement en compte le calcul de latence globale de votre thread générateur de demandes. Un enregistreur d’événements asynchrone, tel que log4j2, est recommandé pour découpler la surcharge de journalisation de vos threads d’application hautes performances.
- Désactiver la journalisation de netty
La journalisation de la bibliothèque netty produit beaucoup d’informations, et doit être désactivée (la suppression de la connexion dans la configuration n’est peut-être pas suffisante) pour éviter des coûts de processeur supplémentaires. Si vous n’êtes pas en mode débogage, désactivez la journalisation de netty en même temps. Ainsi, si vous utilisez Log4j pour supprimer les coûts de processeur supplémentaires induits par org.apache.log4j.Category.callAppenders() de netty, ajoutez la ligne suivante à votre codebase :
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Limite des ressources des fichiers ouverts du système d’exploitation
Certains systèmes Linux (par exemple Red Hat) ont une limite maximale du nombre de fichiers ouverts et donc du nombre total de connexions. Exécutez la commande suivante pour afficher les limites actuelles :
ulimit -a
Le nombre de fichiers ouverts (nofile) doit être suffisamment important pour avoir suffisamment d’espace pour la taille des pools de connexions configurés et autres fichiers ouverts par le système d’exploitation. Il peut être modifié pour permettre une plus grande taille des pools de connexion.
Ouvrir le fichier limits.conf :
vim /etc/security/limits.conf
Ajoutez/modifiez les lignes suivantes :
* - nofile 100000
- Spécifier la clé de partition dans les écritures de point
Pour améliorer les performances des écritures de point, spécifiez la clé de partition de l’élément dans l’appel d’API de l’écriture de point, comme indiqué ci-dessous :
API asynchrone du kit SDK Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Plutôt que de fournir uniquement l’instance de l’élément, comme indiqué ci-dessous :
API asynchrone du kit SDK Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Ce dernier est pris en charge, mais augmente la latence de votre application. Le SDK doit analyser l’élément et extraire la clé de partition.
Opérations de requête
Pour les opérations de requête, consultez les conseils en matière de performances pour les requêtes.
Stratégie d’indexation
- Exclusion des chemins d’accès inutilisés de l’indexation pour des écritures plus rapides
La stratégie d’indexation d’Azure Cosmos DB vous permet de spécifier les chemins de document à inclure ou exclure de l’indexation à l’aide de chemins d’indexation (setIncludedPaths et setExcludedPaths). L’utilisation des chemins d’accès d’indexation peut offrir des performances d’écriture améliorées et réduire le stockage d’index pour les scénarios dans lesquels les modèles de requête sont connus d’avance, puisque les coûts d’indexation sont directement liés au nombre de chemins d’accès uniques indexés. Par exemple, le code suivant montre comment inclure et exclure de l’indexation une section entière des documents (également appelée sous-arborescence) avec le caractère générique « * ».
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Pour plus d’informations, consultez Stratégies d’indexation d’Azure Cosmos DB.
Débit
- Mesure et réglage pour réduire l’utilisation d’unités de requête par seconde
Azure Cosmos DB propose un riche ensemble d’opérations de base de données, dont les requêtes hiérarchiques et relationnelles avec les fonctions définies par l’utilisateur, les procédures stockées et les déclencheurs, qui fonctionnent toutes au niveau des documents d’une collection de base de données. Le coût associé à chacune de ces opérations varie en fonction du processeur, des E/S et de la mémoire nécessaires à l’exécution de l’opération. Plutôt que de vous soucier de la gestion des ressources matérielles, vous pouvez considérer une unité de demande comme une mesure unique des ressources nécessaires à l’exécution des opérations de base de données et à la réponse à la requête de l’application.
Le débit est provisionné en fonction du nombre d’unités de requête défini pour chaque conteneur. La consommation d’unités de requête est évaluée en fonction d’un taux par seconde. Les applications qui dépassent le taux d’unités de requête configuré pour le conteneur associé sont limitées jusqu’à ce que le taux soit inférieur au niveau configuré pour le conteneur. Si votre application requiert un niveau de débit plus élevé, vous pouvez augmenter le débit en provisionnant des unités de requête supplémentaires.
La complexité d’une requête a un impact sur le nombre d’unités de requête consommées pour une opération. Le nombre de prédicats, la nature des prédicats, le nombre de fonctions définies par l’utilisateur et la taille du jeu de données sources ont tous une influence sur le coût des opérations de requête.
Pour mesurer la surcharge de toute opération (création, mise à jour ou suppression), inspectez l’en-tête x-ms-request-charge afin de mesurer le nombre d’unités de requête consommées par ces opérations. Vous pouvez également examiner la propriété RequestCharge équivalente dans ResourceResponse<T> ou FeedResponse<T>.
API asynchrone du kit SDK Java V4 (Maven com.azure::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Les frais de la requête retournée dans cet en-tête correspondent à une fraction du débit provisionné. Par exemple, si 2 000 RU/seconde sont approvisionnées et que la requête précédente retourne 1 000 documents de 1 Ko, le coût de l’opération est de 1 000. Par conséquent, en une seconde, le serveur honore uniquement deux requêtes avant de limiter le taux de requêtes suivantes. Pour plus d’informations, consultez Unités de requête et la calculatrice d’unités de requête.
- Gestion de la limite de taux/du taux de requête trop importants
Lorsqu’un client tente de dépasser le débit réservé pour un compte, les performances au niveau du serveur ne sont pas affectées et la capacité de débit n’est pas utilisée au-delà du niveau réservé. Le serveur met fin à la requête de manière préventive avec RequestRateTooLarge (code d’état HTTP 429) et il retourne l’en-tête x-ms-retry-after-ms indiquant la durée, en millisecondes, pendant laquelle l’utilisateur doit attendre avant de réessayer.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Les kits de développement logiciel (SDK) interceptent tous implicitement cette réponse, respectent l’en-tête retry-after spécifiée par le serveur, puis relancent la requête. La tentative suivante réussira toujours, sauf si plusieurs clients accèdent simultanément à votre compte.
Si plusieurs clients dépassent fréquemment la limite du taux de requêtes, le nombre de nouvelles tentatives par défaut défini à 9 de manière interne par le client risque de ne pas suffire. Dans ce cas, le client lève une exception CosmosClientException ayant le code d’état 429, et la signale à l’application. Le compte par défaut peut être modifié en utilisant setMaxRetryAttemptsOnThrottledRequests() sur l’instance ThrottlingRetryOptions. Par défaut, l’exception CosmosClientException avec le code d’état 429 est retournée après un temps d’attente cumulé de 30 secondes si la requête continue à fonctionner au-dessus du taux de requête. Cela se produit même lorsque le nombre de nouvelles tentatives actuel est inférieur au nombre maximal de nouvelles tentatives, qu’il s’agisse de la valeur par défaut de 9 ou d’une valeur définie par l’utilisateur.
Alors que le comportement de nouvelle tentative automatique permet d’améliorer la résilience et la facilité d’utilisation pour la plupart des applications, il peut se révéler contradictoire lors de l’exécution de tests de performances, en particulier lors de la mesure de la latence. La latence client observée atteindra un pic si l’expérience atteint la limite de serveur et oblige le kit de développement logiciel (SDK) client à effectuer une nouvelle tentative en silence. Pour éviter des pics de latence lors des expériences de performances, mesurez la charge renvoyée par chaque opération et assurez-vous que les requêtes fonctionnent en dessous du taux de requête réservé. Pour plus d’informations, consultez Unités de requête.
- Conception de documents plus petits pour un débit plus élevé
Les frais de requête (le coût de traitement de requête) d’une opération donnée sont directement liés à la taille du document. Des opérations sur des documents volumineux coûtent plus cher que des opérations sur de petits documents. Dans l’idéal, concevez votre application et vos workflows pour que la taille de votre élément soit d’environ 1 Ko (ou d’un ordre ou d’une magnitude similaire). Pour les applications sensibles à la latence, évitez les éléments volumineux comme les documents de plusieurs mégaoctets qui ralentissent votre application.
Étapes suivantes
Pour en savoir plus sur la conception de votre application pour une mise à l’échelle et de hautes performances, consultez Partitionnement, clés de partition et mise à l’échelle dans Cosmos DB.
Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ? Vous pouvez utiliser les informations sur votre cluster de bases de données existant pour la planification de la capacité.
- Si vous ne connaissez que le nombre de vCore et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCore ou de processeurs virtuels.
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB