Conseils sur les performances pour le SDK Python Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL
Important
Ces conseils en matière de performances concernent uniquement le SDK Python Azure Cosmos DB. Pour plus d’informations, consultez le Kit de développement logiciel (SDK) Python Azure Cosmos DB, le fichier Readme, les Notes de publication, le Package (PyPI), le Package (Conda) et le guide de résolution des problèmes .
Azure Cosmos DB est une base de données distribuée rapide et flexible qui peut être mise à l’échelle en toute transparence avec une latence et un débit garantis. Vous n’avez pas à apporter de modifications d’architecture majeures ou écrire de code complexe pour mettre à l’échelle votre base de données avec Azure Cosmos DB. La réduction et l’augmentation de l’échelle est aussi simple que le passage d’un appel d’API ou de Kit de développement logiciel (SDK). Toutefois, étant donné qu’Azure Cosmos DB est accessible au moyen d’appels réseau, vous pouvez apporter des optimisations côté client de manière à atteindre des performances de pointe quand vous utilisez le SDK Python Azure Cosmos DB.
Par exemple, si vous vous demandez comment améliorer les performances de votre base de données, envisagez les options suivantes :
Mise en réseau
- Colocaliser les clients dans la même région Azure pour de meilleures performances
Dans la mesure du possible, placez toutes les applications appelant Azure Cosmos DB dans la même région que la base de données Azure Cosmos DB. Pour une comparaison approximative, les appels à Azure Cosmos DB dans la même région s’effectuent en 1 à 2 ms, mais la latence entre les côtes Ouest et Est des États-Unis est >50 ms. Cette latence peut probablement varier d’une requête à l’autre, en fonction de l’itinéraire utilisé par la requête lorsqu’elle passe du client à la limite du centre de données Azure. Pour obtenir la latence la plus faible possible, l’application appelante doit être située dans la même région Azure que le point de terminaison Azure Cosmos DB configuré. Pour obtenir la liste des régions disponibles, voir Régions Azure.
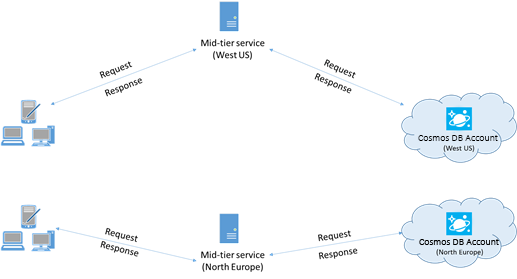
Une application qui interagit avec un compte Azure Cosmos DB multirégion doit configurer des emplacements préférés pour que les demandes soient transmises à une région colocalisée.
Activer la mise en réseau accélérée pour réduire la latence et la gigue du processeur
Il est recommandé de suivre les instructions relatives à l’activation des performances réseau accélérées sur votre machine virtuelle Azure Windows (instructions ici) ou Linux (instructions ici) pour optimiser les performances (réduire la latence et la gigue au niveau du processeur).
Sans les performances réseau accélérées, les E/S qui transitent entre votre machine virtuelle Azure et d’autres ressources Azure risquent d’être routées inutilement via un hôte et un commutateur virtuel situés entre la machine virtuelle et sa carte réseau. Le fait d’avoir l’hôte et le commutateur virtuel inline dans le chemin de données entraîne non seulement une augmentation de la latence et de l’instabilité dans le canal de communication, mais aussi le vol des cycles processeur de la machine virtuelle. L’accélération réseau offre plusieurs avantages : la machine virtuelle interagit directement avec la carte réseau sans intermédiaires, les détails de la stratégie réseau précédemment gérés par l’hôte et le commutateur virtuel sont désormais gérés dans le matériel au niveau de la carte réseau, et l’hôte et le commutateur virtuel sont contournés. L’activation de l’accélération réseau se traduit généralement par une latence plus faible et plus cohérente, un débit plus élevé et une utilisation réduite du processeur.
Limitations : l’accélération réseau doit être prise en charge sur le système d’exploitation de la machine virtuelle et ne peut être activée que si la machine virtuelle est arrêtée et libérée. La machine virtuelle ne peut pas être déployée avec Azure Resource Manager. App Service n’a pas de réseau accéléré activé.
Pour plus d’informations, consultez les instructions propres à Windows et à Linux.
Utilisation du Kit de développement logiciel (SDK)
- Installation du kit de développement logiciel (SDK) le plus récent
Les SDK Azure Cosmos DB sont constamment améliorés pour fournir des performances optimales. Consultez les Notes de publication du SDK Azure Cosmos DB pour déterminer quel est le SDK le plus récent et passer en revue les améliorations.
- Utiliser un client Azure Cosmos DB singleton pour la durée de vie de votre application
Chaque instance du client Azure Cosmos DB est thread-safe et effectue une gestion des connexions efficace et une mise en cache d’adresses. Pour permettre une gestion des connexions efficace par le client Azure Cosmos DB et améliorer ses performances, nous vous recommandons d’utiliser une seule instance du client Azure Cosmos DB pendant toute la durée de vie de l’application.
- Ajuster les configurations de délai d’attente et de nouvelle tentative
Les configurations de délai d’attente et les stratégies de nouvelle tentative peuvent être personnalisées en fonction des besoins de l’application. Reportez-vous au document sur les configurations de délai d’attente et de nouvelle tentative pour obtenir la liste complète des configurations qui peuvent être personnalisées.
- Utiliser le niveau de cohérence le plus bas requis pour votre application
Lorsque vous créez un CosmosClient, la cohérence au niveau du compte est utilisée si aucune n’est spécifiée dans la création du client. Pour plus d'informations sur les niveaux de cohérence, consultez le document sur les niveaux de cohérence.
- Effectuer un scale-out de votre charge de travail cliente
Si vous effectuez des tests à des niveaux de débit élevés, l’application cliente peut devenir le goulot d’étranglement en raison du plafonnement de la machine en ce qui concerne l’utilisation du processeur ou du réseau. Si vous atteignez ce point, vous pouvez continuer à augmenter le compte Azure Cosmos DB en augmentant la taille des instances de vos applications clientes sur plusieurs serveurs.
La règle générale est ne pas utiliser >50 % du processeur sur un serveur donné pour maintenir la latence à un niveau minimal.
- Limite des ressources des fichiers ouverts du système d’exploitation
Certains systèmes Linux (par exemple Red Hat) ont une limite maximale du nombre de fichiers ouverts et donc du nombre total de connexions. Exécutez la commande suivante pour afficher les limites actuelles :
ulimit -a
Le nombre de fichiers ouverts (nofile) doit être suffisamment important pour avoir suffisamment d’espace pour la taille des pools de connexions configurés et autres fichiers ouverts par le système d’exploitation. Il peut être modifié pour permettre une plus grande taille des pools de connexion.
Ouvrir le fichier limits.conf :
vim /etc/security/limits.conf
Ajoutez/modifiez les lignes suivantes :
* - nofile 100000
Opérations de requête
Pour les opérations de requête, consultez les conseils en matière de performances pour les requêtes.
Stratégie d’indexation
- Exclusion des chemins d’accès inutilisés de l’indexation pour des écritures plus rapides
La stratégie d’indexation d’Azure Cosmos DB vous permet de spécifier les chemins d’accès de document à inclure ou exclure de l’indexation en tirant parti des chemins d’accès d’indexation (setIncludedPaths et setExcludedPaths). L’utilisation des chemins d’accès d’indexation peut offrir des performances d’écriture améliorées et réduire le stockage d’index pour les scénarios dans lesquels les modèles de requête sont connus d’avance, puisque les coûts d’indexation sont directement liés au nombre de chemins d’accès uniques indexés. Par exemple, le code suivant montre comment inclure et exclure de l’indexation une section entière des documents (également appelée sous-arborescence) avec le caractère générique « * ».
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Pour plus d’informations, consultez Stratégies d’indexation d’Azure Cosmos DB.
Débit
- Mesure et réglage pour réduire l’utilisation d’unités de requête par seconde
Azure Cosmos DB propose un riche ensemble d’opérations de base de données, dont les requêtes hiérarchiques et relationnelles avec les fonctions définies par l’utilisateur, les procédures stockées et les déclencheurs, qui fonctionnent toutes au niveau des documents d’une collection de base de données. Le coût associé à chacune de ces opérations varie en fonction du processeur, des E/S et de la mémoire nécessaires à l’exécution de l’opération. Plutôt que de vous soucier de la gestion des ressources matérielles, vous pouvez considérer une unité de demande comme une mesure unique des ressources nécessaires à l’exécution des opérations de base de données et à la réponse à la requête de l’application.
Le débit est provisionné en fonction du nombre d’unités de requête défini pour chaque conteneur. La consommation d’unités de requête est évaluée en fonction d’un taux par seconde. Les applications qui dépassent le taux d’unités de requête configuré pour le conteneur associé sont limitées jusqu’à ce que le taux soit inférieur au niveau configuré pour le conteneur. Si votre application requiert un niveau de débit plus élevé, vous pouvez augmenter le débit en provisionnant des unités de requête supplémentaires.
La complexité d’une requête a un impact sur le nombre d’unités de requête consommées pour une opération. Le nombre de prédicats, la nature des prédicats, le nombre de fonctions définies par l’utilisateur et la taille du jeu de données sources ont tous une influence sur le coût des opérations de requête.
Pour mesurer la surcharge de toute opération (création, mise à jour ou suppression), inspectez l’en-tête x-ms-request-charge afin de mesurer le nombre d’unités de requête consommées par ces opérations.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Les frais de la requête retournée dans cet en-tête correspondent à une fraction du débit provisionné. Par exemple, si 2 000 RU/seconde sont provisionnées et que la requête ci-dessus retourne 1000 documents de 1 Ko, le coût de l’opération est de 1000. Par conséquent, en une seconde, le serveur honore uniquement deux requêtes avant de limiter le taux de requêtes suivantes. Pour plus d’informations, consultez Unités de requête et la calculatrice d’unités de requête.
- Gestion de la limite de taux/du taux de requête trop importants
Lorsqu’un client tente de dépasser le débit réservé pour un compte, les performances au niveau du serveur ne sont pas affectées et la capacité de débit n’est pas utilisée au-delà du niveau réservé. Le serveur met fin à la requête de manière préventive avec RequestRateTooLarge (code d’état HTTP 429) et il retourne l’en-tête x-ms-retry-after-ms indiquant la durée, en millisecondes, pendant laquelle l’utilisateur doit attendre avant de réessayer.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Les kits de développement logiciel (SDK) interceptent tous implicitement cette réponse, respectent l’en-tête retry-after spécifiée par le serveur, puis relancent la requête. La tentative suivante réussira toujours, sauf si plusieurs clients accèdent simultanément à votre compte.
Si plusieurs clients dépassent fréquemment la limite du taux de requêtes, le nombre de nouvelles tentatives par défaut défini à 9 de manière interne par le client risque de ne pas suffire. Dans ce cas, le client lève une exception CosmosHttpResponseError avec le code d’état 429, et la signale à l’application. Le nombre de nouvelles tentatives par défaut peut être modifié en transmettant la configuration retry_total au client. Par défaut, l’exception CosmosHttpResponseError avec le code d’état 429 est retournée après un temps d’attente cumulé de 30 secondes si la requête continue à fonctionner au-dessus du taux de requête. Cela se produit même lorsque le nombre de nouvelles tentatives actuel est inférieur au nombre maximal de nouvelles tentatives, qu’il s’agisse de la valeur par défaut de 9 ou d’une valeur définie par l’utilisateur.
Alors que le comportement de nouvelle tentative automatique permet d’améliorer la résilience et la facilité d’utilisation pour la plupart des applications, il peut se révéler contradictoire lors de l’exécution de tests de performances, en particulier lors de la mesure de la latence. La latence client observée atteindra un pic si l’expérience atteint la limite de serveur et oblige le kit de développement logiciel (SDK) client à effectuer une nouvelle tentative en silence. Pour éviter des pics de latence lors des expériences de performances, mesurez la charge renvoyée par chaque opération et assurez-vous que les requêtes fonctionnent en dessous du taux de requête réservé. Pour plus d’informations, consultez Unités de requête.
- Conception de documents plus petits pour un débit plus élevé
Les frais de requête (le coût de traitement de requête) d’une opération donnée sont directement liés à la taille du document. Des opérations sur des documents volumineux coûtent plus cher que des opérations sur de petits documents. Dans l’idéal, concevez votre application et vos workflows pour que la taille de votre élément soit d’environ 1 Ko (ou d’un ordre ou d’une magnitude similaire). Pour les applications sensibles à la latence, évitez les éléments volumineux comme les documents de plusieurs mégaoctets qui ralentissent votre application.
Étapes suivantes
Pour en savoir plus sur la conception de votre application pour une mise à l’échelle et de hautes performances, consultez Partitionnement, clés de partition et mise à l’échelle dans Cosmos DB.
Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ? Vous pouvez utiliser les informations sur votre cluster de bases de données existant pour la planification de la capacité.
- Si vous ne connaissez que le nombre de vCore et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCore ou de processeurs virtuels.
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB