Idées de solution
Cet article présente une idée de solution. Votre architecte cloud peut s’appuyer sur ces conseils pour visualiser les principaux composants d’une implémentation typique de cette architecture. Utilisez cet article comme point de départ pour concevoir une solution bien conçue qui répond aux exigences spécifiques de votre charge de travail.
Cette architecture fournit des conseils et des recommandations pour le développement d’une solution de conduite automatisée.
Architecture

Téléchargez un fichier Visio qui contient les diagrammes d’architecture de cet article.
Dataflow
Les données de mesure proviennent de flux de données pour des capteurs comme les caméras, les radars, les ultrasons, le lidar et les données de télémétrie des véhicules. Les enregistreurs de données du véhicule stockent les données de mesure sur les appareils de stockage de l’enregistreur d’événements. Les données de stockage de l’enregistreur d’événements sont ensuite chargées dans le lac de données d’atterrissage. Un service comme Azure Data Box ou Azure Stack Edge, ou une connexion dédiée comme Azure ExpressRoute, ingère des données dans Azure.
Les données de mesure peuvent également être des données synthétiques provenant de simulations ou d’autres sources. (MDF4, TDMS et rosbag sont des formats de données courants pour les mesures.) Dans la phase DataOps, les mesures ingérées sont traitées. La validation et les vérifications de la qualité des données, comme la somme de contrôle, sont effectuées pour éliminer les données de faible qualité. À cette étape, les métadonnées d’informations brutes enregistrées par un pilote d’essai lors d’un tour d’essai sont extraites. Ces données sont stockées dans un catalogue de métadonnées centralisé. Ces informations aident les processus en aval à identifier des scènes et des séquences spécifiques.
Les données sont traitées par un pipeline Azure Data Factory extraire, transformer et charger (ETL). La sortie est stockée sous forme de données brutes et binaires dans Azure Data Lake. Les métadonnées sont stockées dans Azure Cosmos DB. Selon le scénario, elle peut ensuite être envoyée à Azure Data Explorer ou Recherche cognitive Azure.
Des informations, des insights et un contexte supplémentaires sont ajoutés aux données pour améliorer leur précision et leur fiabilité.
Les données de mesure extraites sont fournies aux partenaires d’étiquetage (humain dans la boucle) via Azure Data Share. Les partenaires tiers effectuent l’étiquetage automatique, le stockage et l’accès aux données via un compte Data Lake distinct.
Les jeux de données étiquetés sont acheminés vers les processus MLOps en aval, principalement pour créer des modèles de perception et de fusion de capteurs. Ces modèles exécutent des fonctions utilisées par les véhicules autonomes pour détecter des scènes (comme les changements de voie, les routes bloquées, les piétons, les feux de circulation et les panneaux de signalisation).
Dans la phase ValOps, les modèles entraînés sont validés via des tests en boucle ouverte et en boucle fermée.
Des outils tels que Foxglove, s’exécutant sur Azure Kubernetes Service ou Azure Container Instances, visualisent les données ingérées et traitées.
Collecte de données
La collecte de données est l’un des principaux défis des opérations de véhicules autonomes (AVOps). Le diagramme suivant montre comment les données de véhicules hors connexion et en ligne peuvent être collectées et stockées dans un lac de données.

DataOps
Les opérations de données (DataOps) sont un ensemble de pratiques, de processus et d’outils visant à améliorer la qualité, la rapidité et la fiabilité des opérations de données. L’objectif du flux DataOps pour la conduite autonome (AD) est de garantir que les données utilisées pour contrôler le véhicule sont de haute qualité, précises et fiables. En utilisant un flux DataOps cohérent, vous pouvez améliorer la vitesse et la précision de vos opérations de données et prendre de meilleures décisions pour contrôler vos véhicules autonomes.
Composants DataOps
- Data Box est utilisé pour transférer les données de véhicule collectées vers Azure via un opérateur régional.
- ExpressRoute étend les réseaux locaux au cloud Microsoft via une connexion privée.
- Azure Data Lake Storage stocke les données en fonction des phases, par exemple brutes ou extraites.
- Azure Data Factory effectue l’ETL via le calcul par lots et crée des workflows pilotés par les données pour orchestrer le déplacement et la transformation des données.
- Azure Batch exécute des applications à grande échelle pour des tâches comme la collecte de données, le filtrage et la préparation des données et l’extraction des métadonnées.
- Azure Cosmos DB stocke les résultats des métadonnées, comme les mesures stockées.
- Data Share est utilisé pour partager des données avec des organisations partenaires, comme les entreprises d’étiquetage, avec une sécurité renforcée.
- Azure Databricks fournit un ensemble d’outils permettant de gérer des solutions de données de qualité entreprise à grande échelle. Cela est nécessaire pour les opérations de longue durée sur de grandes quantités de données de véhicule. Les ingénieurs données utilisent Azure Databricks comme banc d’essai analytique.
- Azure Synapse Analytics raccourcit le délai d’obtention d’analyses sur l’ensemble des entrepôts de données et des systèmes Big Data.
- Recherche cognitive Azure fournit des services de recherche dans le catalogue de données.
MLOps
Les opérations de Machine Learning (MLOps) comprennent :
- Modèles d’extraction de fonctionnalités (comme CLIP et YOLO) pour classifier des scènes (par exemple, si un piéton se trouve dans la scène) pendant le pipeline DataOps.
- Modèles d’étiquetage automatique pour l’étiquetage des images ingérées et des données lidar et radar.
- Modèles de perception et de vision par ordinateur pour la détection d’objets et de scènes.
- Modèle de fusion de capteur qui combine des flux de capteurs.
Le modèle de perception est un composant important de cette architecture. Ce modèle Azure Machine Learning génère un modèle de détection d’objet à l’aide de scènes détectées et extraites.
Le transfert du modèle Machine Learning conteneurisé vers un format qui peut être lu par le système sur un matériel avec système sur puce (SoC) et le logiciel de validation/simulation se produit dans le pipeline MLOps. Cette étape nécessite la prise en charge du fabricant de SoC.
Composants MLOps
- Azure Machine Learning est utilisé pour développer des algorithmes d’apprentissage automatique, comme l’extraction de fonctionnalités, l’étiquetage automatique, la détection et la classification d’objets et la fusion de capteurs.
- Azure DevOps prend en charge les tâches DevOps, comme la CI/CD, les tests et l’automatisation.
- GitHub pour les entreprises est un choix alternatif pour les tâches DevOps comme la CI/CD, les tests et l’automatisation.
- Azure Container Registry vous permet de générer, stocker et gérer des images et artefacts conteneur dans un registre privé.
ValOps
Le processus d’opérations de validation (ValOps) consiste à tester les modèles développés dans des environnements simulés via des scénarios managés avant d’effectuer des tests environnementaux réels, qui sont coûteux. Les tests ValOps permettent de s’assurer que les modèles répondent aux normes de performances et de précision et aux exigences de sécurité souhaitées. L’objectif du processus de validation dans le cloud est d’identifier et de résoudre les problèmes potentiels avant de déployer le véhicule autonome dans un environnement réel. Le processus de ValOps comprend :
- Validation de simulation. Les environnements de simulation basée sur le cloud (test en boucle ouverte et en boucle fermée) permettent de tester virtuellement des modèles de véhicules autonomes. Ces tests s’exécutent à grande échelle et sont moins coûteux que les tests réels.
- Validation des performances. L’infrastructure basée sur le cloud peut exécuter des tests à grande échelle pour évaluer les performances des modèles de véhicules autonomes. La validation des performances peut inclure des tests de contrainte, des tests de charge et des benchmarks.
L’utilisation de ValOps pour la validation peut vous aider à tirer parti de la scalabilité, de la flexibilité et de la rentabilité d’une infrastructure basée sur le cloud et à réduire le délai de commercialisation des modèles de véhicules autonomes.
Test en boucle ouverte
La re-simulation, ou le traitement des capteurs, est un système de test et de validation en boucle ouverte pour les fonctions de conduite automatique. Il s’agit d’un processus complexe, et il peut y avoir des exigences réglementaires en matière de sécurité, de confidentialité des données, de contrôle de version des données et d’audit. La re-simulation traite les données brutes enregistrées à partir de différents capteurs de voiture via un graphique dans le cloud. La re-simulation valide les algorithmes de traitement des données ou détecte les régressions. Les OEM combinent des capteurs dans un graphe orienté acyclique qui représente un véhicule réel.
La re-simulation est un travail de calcul parallèle à grande échelle. Elle traite des dizaines ou des centaines de Po de données à l’aide de dizaines de milliers de cœurs. Elle nécessite un débit d’E/S supérieur à 30 Go/s. Les données de plusieurs capteurs sont combinées en jeux de données qui représentent une vue de ce que les systèmes de vision par ordinateur du véhicule enregistrent lorsque le véhicule navigue dans le monde réel. Un test en boucle ouverte valide les performances des algorithmes par rapport à la réalité en utilisant la relecture et le scoring. La sortie est utilisée ultérieurement dans le workflow pour l’entraînement de l’algorithme.
- Les jeux de données proviennent de véhicules de la flotte de test qui collectent des données de capteur brutes (par exemple, des données de caméra, de lidar, de radar et d’ultrasons).
- Le volume des données dépend de la résolution de la caméra et du nombre de capteurs sur le véhicule.
- Les données brutes sont traitées à nouveau par rapport à différentes versions logicielles des appareils.
- Les données brutes du capteur sont envoyées à l’interface d’entrée du capteur du logiciel du capteur.
- La sortie est comparée à la sortie des versions logicielles précédentes et est vérifiée par rapport aux correctifs de bogues ou aux nouvelles fonctionnalités, comme la détection de nouveaux types d’objets.
- Une deuxième réinjection du travail est effectuée après la mise à jour du modèle et du logiciel.
- Les données de vérité au sol sont utilisées pour valider les résultats.
- Les résultats sont écrits dans le stockage et déchargés dans Azure Data Explorer à des fins de visualisation.
Simulation et test en boucle fermée
Le test en boucle fermée des véhicules autonomes est le processus de test des capacités des véhicules tout en incluant les retours en temps réel de l’environnement. Les actions du véhicule sont basées à la fois sur son comportement pré-programmé et sur les conditions dynamiques qu’il rencontre, et il ajuste ses actions en conséquence. Les tests en boucle fermée s’exécutent dans un environnement plus complexe et réaliste. Ils sont utilisés pour évaluer la capacité du véhicule à gérer des scénarios réels, y compris la façon dont il réagit aux situations inattendues. L’objectif des tests en boucle fermée est de vérifier que le véhicule peut fonctionner en toute sécurité et efficacement dans diverses conditions, et d’affiner ses algorithmes de contrôle et ses processus de prise de décision en fonction des besoins.
Le pipeline ValOps intègre des tests en boucle fermée, des simulations tierces et des applications ISV.
Gestion des scénarios
Au cours de la phase ValOps, un catalogue de scénarios réels est utilisé pour valider la capacité de la solution de conduite autonome à simuler le comportement des véhicules autonomes. L’objectif est d’accélérer la création de catalogues de scénarios en lisant automatiquement le réseau d’itinéraires, qui fait partie d’un scénario, à partir de cartes numériques accessibles au public et disponibles gratuitement. Utilisez des outils tiers pour la gestion des scénarios, ou un simulateur open source léger comme CARLA, qui prend en charge le format OpenDRIVE (xodr). Pour plus d’informations, consultez ScenarioRunner pour CARLA.
Composants ValOps
- Azure Kubernetes Service exécute l’inférence par lots à grande échelle pour la validation en boucle ouverte dans une infrastructure Resin. Nous vous recommandons d’utiliser BlobFuse2 pour accéder aux fichiers de mesure. Vous pouvez également utiliser NFS, mais vous devez évaluer les performances pour le cas d’usage.
- Azure Batch exécute l’inférence par lots à grande échelle pour la validation en boucle ouverte dans une infrastructure Resin.
- Azure Data Explorer fournit un service d’analytique pour les mesures et les indicateurs de performance clés (c’est-à-dire, la re-simulation et les exécutions de travaux).
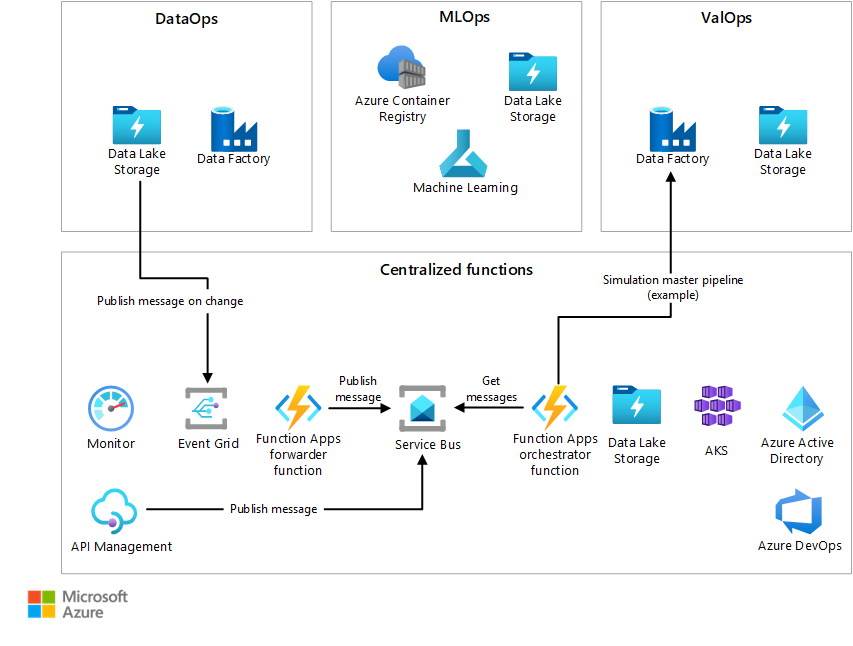
Fonctions AVOps centralisées
Une architecture AVOps est complexe et implique différents tiers, rôles et phases de développement. Il est donc important d’implémenter un modèle de gouvernance approprié.
Nous vous recommandons de créer une équipe centralisée pour gérer des fonctions comme l’approvisionnement d’infrastructure, la gestion des coûts, le catalogue de métadonnées et de données, la traçabilité, ainsi que l’orchestration globale et la gestion des événements. La centralisation de ces services est efficace et simplifie les opérations.
Nous vous recommandons d’utiliser une équipe centralisée pour gérer ces responsabilités :
- Fournir des modèles ARM/Bicep, y compris des modèles pour les services standard, comme le stockage et le calcul, utilisés par chaque zone et sous-zone de l’architecture AVOps
- Implémenter des instances Azure Service Bus/Azure Event Hubs centrales pour une orchestration pilotée par les événements de la boucle de données AVOps
- Propriété du catalogue de métadonnées
- Fonctionnalités de traçabilité des données et de traçabilité de bout en bout sur tous les composants AVOps
Détails du scénario
Vous pouvez utiliser cette architecture pour créer une solution de conduite automatisée sur Azure.
Cas d’usage potentiels
Les OEM automobiles, fournisseurs de niveau 1 et éditeurs de logiciels indépendants qui développent des solutions pour la conduite automatisée.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework, un ensemble de principes directeurs que vous pouvez utiliser pour améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Il est important de comprendre la répartition des responsabilités entre l’OEM automobile et le fournisseur de cloud. Dans le véhicule, l’OEM possède l’ensemble de la pile, mais à mesure que les données se déplacent vers le cloud, certaines responsabilités sont transférées au fournisseur de cloud. Azure PaaS (Platform-as-a-Service) fournit une sécurité intégrée améliorée sur la pile physique, y compris le système d’exploitation. Vous pouvez appliquer les améliorations suivantes en plus des composants de sécurité de l’infrastructure. Ces améliorations permettent une approche de confiance zéro.
- Points de terminaison privés pour la sécurité réseau. Pour plus d’informations, consultez Points de terminaison privé pour Azure Data Explorer et Autoriser l’accès aux espaces de noms Azure Event Hubs via des points de terminaison privés.
- Chiffrement au repos et en transit. Pour plus d’informations, consultez Vue d’ensemble du chiffrement Azure.
- Gestion des identités et des accès qui utilise les identités Microsoft Entra et les stratégies d’Accès conditionnel Microsoft Entra.
- Sécurité au niveau des lignes (RLS) pour Azure Data Explorer.
- Gouvernance de l’infrastructure qui utilise Azure Policy.
- Gouvernance des données qui utilise Microsoft Purview.
- Gestion des certificats pour sécuriser la connexion des véhicules.
- Accès avec le privilège minimum. Limitez l’accès utilisateur avec l’accès juste-à-temps (JIT) et juste suffisant (JEA), des stratégies adaptatives basées sur les risques et une protection des données.
Optimisation des coûts
L’optimisation des coûts consiste à réduire les dépenses inutiles et à améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Vous pouvez utiliser ces stratégies pour réduire les coûts associés au développement de solutions de conduite autonome :
- Optimisez l’infrastructure cloud. Une planification et une gestion minutieuses de l’infrastructure cloud peuvent vous aider à réduire les coûts. Par exemple, utilisez des types d’instances rentables et mettez à l’échelle l’infrastructure pour répondre à des charges de travail changeantes. Suivez les instructions de l’Azure Cloud Adoption Framework.
- Utilisez des Machines virtuelles Spot. Vous pouvez déterminer quelles charges de travail dans votre déploiement AVOps ne nécessitent pas de traitement dans un laps de temps spécifique et utiliser des machines virtuelles spot pour ces charges de travail. Les machines virtuelles spot vous permettent de disposer de notre capacité Azure inutilisée en réalisant des économies significatives. Si Azure a besoin de récupérer la capacité, l’infrastructure Azure supprime les machines virtuelles spot.
- Utiliser la mise à l’échelle automatique. La mise à l’échelle automatique vous permet d’ajuster automatiquement votre infrastructure cloud en fonction de la demande, ce qui réduit la nécessité d’une intervention manuelle et vous aide à réduire les coûts. Pour plus d’informations, reportez-vous à la Concevoir pour la mise à l’échelle.
- Envisagez d’utiliser les niveaux chaud, froid et archive pour le stockage. Le stockage peut représenter un coût important dans une solution de conduite autonome. Vous devez donc choisir des options de stockage rentables, comme le stockage froid ou le stockage à accès peu fréquent. Pour plus informations, consultez Gestion de cycle de vie des données.
- Utilisez des outils de gestion et d’optimisation des coûts. Microsoft Cost Management fournit des outils qui peuvent vous aider à identifier et à traiter les domaines où une réduction des coûts est possible, comme les ressources inutilisées ou sous-utilisées.
- Envisagez d’utiliser les services Azure. Par exemple, vous pouvez utiliser Azure Machine Learning pour créer et entraîner des modèles de conduite autonome. L’utilisation de ces services peut être plus rentable que la création et l’entretien d’une infrastructure interne.
- Utilisez des ressources partagées. Si possible, vous pouvez utiliser des ressources partagées, comme des bases de données ou des ressources de calcul partagées, pour réduire les coûts associés au développement de la conduite autonome. Les fonctions centralisées dans cette architecture, par exemple, implémentent un bus central, un hub d’événements et un catalogue de métadonnées. Des services comme Azure Data Share peuvent également vous aider à atteindre cet objectif.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Ryan Matsumura | Responsable de programme senior
- Jochen Schroeer | Architecte principal (Service Line Mobility)
Autres contributeurs :
- Mick Alberts | Rédacteur technique
- David Peterson | Architecte en chef
- Gabriel Sallah | Spécialiste Black Belt global HPC/AI
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Qu'est-ce que Microsoft Azure Machine Learning ?
- Présentation d’Azure Batch
- Documentation Azure Data Factory
- Qu’est-ce qu’Azure Data Share ?
Ressources associées
Pour plus d’informations sur le développement de DataOps pour un système de conduite automatisée, consultez :
Les rubriques suivantes peuvent également vous intéresser :