Copier des données à partir d’Amazon RDS for SQL Server avec Azure Data Factory ou Azure Synapse Analytics
Cet article décrit comment utiliser l’activité de copie dans des pipelines Azure Data Factory et Azure Synapse pour copier des données depuis Amazon RDS pour une base de données SQL Server. Pour en savoir plus, lisez l’article d’introduction pour Azure Data Factory ou Azure Synapse Analytics.
Fonctionnalités prises en charge
Cet Amazon RDS pour connecteur SQL Server est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | ① ② |
| Activité de recherche | ① ② |
| Activité GetMetadata | ① ② |
| Activité de procédure stockée | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Plus précisément, ce connecteur Amazon RDS for SQL Server prend en charge :
- SQL Server version 2005 et versions ultérieures.
- La copie des données à l'aide de l'authentification SQL ou Windows
- En tant que source, la récupération de données à l’aide d’une requête SQL ou d’une procédure stockée. Vous pouvez également choisir de faire une copie parallèle à partir de la source Amazon RDS for SQL Server, voir la section Copie parallèle à partir de la base de données SQL pour plus de détails.
SQL Server Express LocalDB n’est pas pris en charge.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Amazon RDS for SQL Server en utilisant l'interface utilisateur
Utilisez les étapes suivantes pour créer un service lié SQL Server dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Amazon RDS for SQL server et sélectionnez le connecteur Amazon RDS for SQL Server.
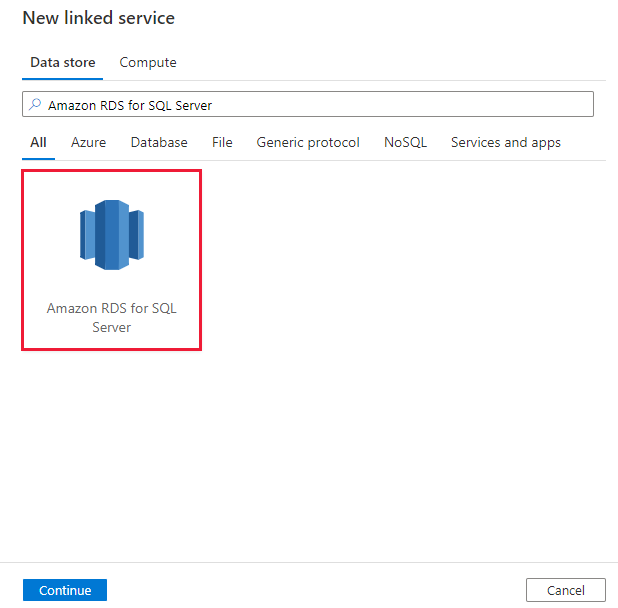
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
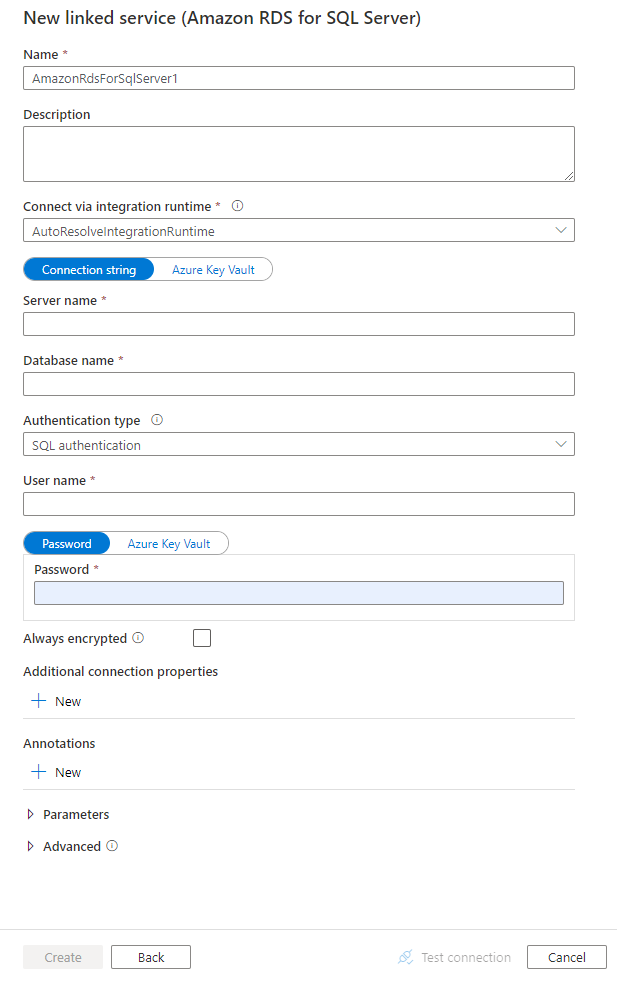
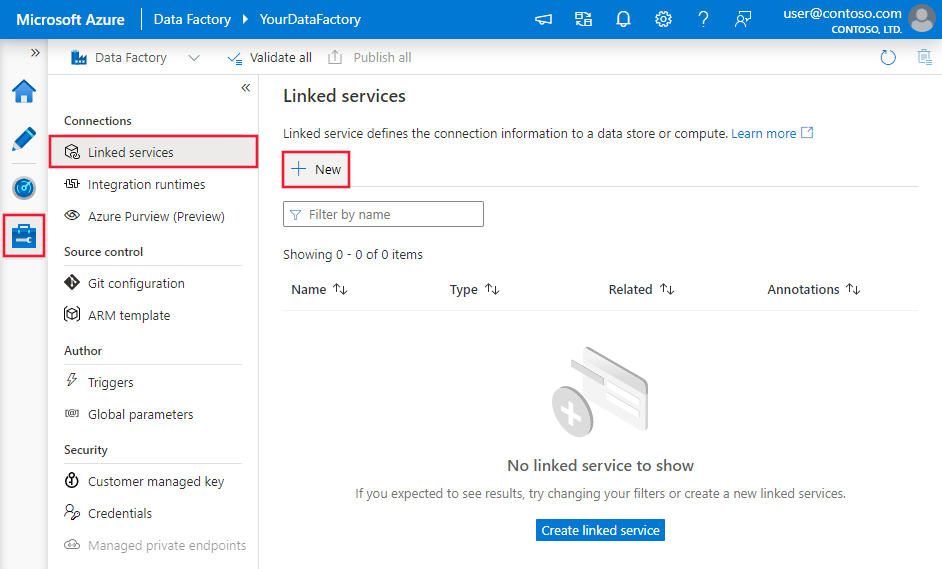
Informations de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir des entités de pipelines Data Factory et Synapse propres au connecteur de base de données SQL Server.
Propriétés du service lié
Le connecteur Amazon RDS pour SQL Server version recommandée prend en charge TLS 1.3. Reportez-vous à cette section pour mettre à niveau votre version du connecteur Amazon RDS pour SQL Server à partir de la version héritée. Pour plus d’informations sur la propriété, consultez les sections correspondantes.
Remarque
Amazon RDS for SQL Server Always Encrypted n'est pas pris en charge dans le flux de données.
Conseil
Si vous rencontrez une erreur avec le code d’erreur « UserErrorFailedToConnectToSqlServer » et un message tel que « La limite de session de la base de données XXX a été atteinte », ajoutez Pooling=false à votre chaîne de connexion, puis réessayez.
Version recommandée
Ces propriétés génériques sont prises en charge pour un service lié Amazon RDS pour SQL Server lorsque vous appliquez la version recommandée :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonRdsForSqlServer | Oui |
| server | Nom ou adresse réseau de l’instance de SQL Server à laquelle vous souhaitez vous connecter. | Oui |
| database | Nom de la base de données. | Oui |
| authenticationType | Type utilisé pour l’authentification. Les valeurs autorisées sont SQL (par défaut), Windows. Accédez à la section d’authentification appropriée sur les propriétés et les prérequis spécifiques. | Oui |
| alwaysEncryptedSettings | Spécifiez les informations alwaysencryptedsettings nécessaires pour permettre à Always Encrypted de protéger les données sensibles stockées dans SQL Server à l’aide d’une identité managée ou d’un principal de service. Pour plus d’informations, consultez l’exemple JSON figurant après le tableau et la section Utilisation d’Always Encrypted. S’il n’est pas spécifié, le paramètre par défaut Always Encrypted est désactivé. | Non |
| encrypt | Indiquez si le chiffrement TLS est obligatoire pour toutes les données envoyées entre le client et le serveur. Options : obligatoire (pour true, valeur par défaut)/facultatif (pour false)/strict. | Non |
| trustServerCertificate | Indiquez si le canal est chiffré tout en contournant la chaîne de certificats pour valider l’approbation. | Non |
| hostNameInCertificate | Nom d’hôte à utiliser au moment de la validation du certificat de serveur pour la connexion. Quand il n’est pas spécifié, le nom du serveur est utilisé pour la validation de certificat. | Non |
| connectVia | Ce runtime d'intégration permet de se connecter au magasin de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Pour obtenir des propriétés de connexion supplémentaires, consultez le tableau ci-dessous :
| Propriété | Description | Obligatoire |
|---|---|---|
| applicationIntent | Type de charge de travail de l’application au moment de la connexion à un serveur. Les valeurs autorisées sont ReadOnly et ReadWrite. |
Non |
| connectTimeout | Durée d’attente (en secondes) d’une connexion au serveur avant l’arrêt de la tentative, et la génération d’une erreur. | Non |
| connectRetryCount | Nombre de tentatives de reconnexions après l’identification d’une défaillance due à une connexion inactive. La valeur doit être un entier compris entre 0 et 255. | Non |
| connectRetryInterval | Durée (en secondes) entre chaque tentative de reconnexion après l’identification d’une défaillance due à une connexion inactive. La valeur doit être un entier compris entre 1 et 60. | Non |
| loadBalanceTimeout | Durée minimale (en secondes) pendant laquelle la connexion doit rester dans le pool de connexions avant d’être détruite. | Non |
| commandTimeout | Délai d’attente par défaut (en secondes) avant l’arrêt de la tentative d’exécution d’une commande, et la génération d’une erreur. | Non |
| integratedSecurity | Les valeurs autorisées sont true ou false. Quand vous spécifiez false, indique si userName et password sont spécifiés dans la connexion. Quand vous spécifiez true, indique si les informations d’identification du compte Windows actuel sont utilisées pour l’authentification. |
Non |
| failoverPartner | Nom ou adresse du serveur partenaire auquel se connecter si le serveur principal est en panne. | Non |
| maxPoolSize | Nombre maximal de connexions autorisées dans le pool de connexions pour la connexion spécifique. | Non |
| minPoolSize | Nombre minimal de connexions autorisées dans le pool de connexions pour la connexion spécifique. | Non |
| multipleActiveResultSets | Les valeurs autorisées sont true ou false. Quand vous spécifiez true, une application peut gérer plusieurs jeux de résultats MARS (Multiple Active Result Set). Quand vous spécifiez false, une application doit traiter ou annuler tous les jeux de résultats d’un lot pour pouvoir exécuter d’autres lots sur cette connexion. |
Non |
| multiSubnetFailover | Les valeurs autorisées sont true ou false. Si votre application se connecte à un groupe de disponibilité AlwaysOn sur différents sous-réseaux, l’affectation de la valeur true à cette propriété accélère la détection du serveur actif et la connexion à celui-ci. |
Non |
| packetSize | Taille en octets des paquets réseau utilisés pour communiquer avec une instance de serveur. | Non |
| pooling | Les valeurs autorisées sont true ou false. Quand vous spécifiez true, la connexion est groupée. Quand vous spécifiez false, la connexion est explicitement ouverte chaque fois qu’elle est demandée. |
Non |
Authentification SQL
Pour utiliser l’authentification SQL, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| userName | Nom d’utilisateur utilisé pour se connecter au serveur. | Oui |
| mot de passe | Mot de passe du nom d’utilisateur. Marquez ce champ comme SecureString pour le stocker en toute sécurité. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Exemple : utilisez l’authentification SQL
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : utilisez l’authentification SQL avec un mot de passe dans Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : utiliser Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification Windows
Pour utiliser l’authentification Windows, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| userName | Indique un nom d'utilisateur. Exemple : nom-domaine\nom-utilisateur. | Oui |
| mot de passe | Spécifiez un mot de passe pour le compte d’utilisateur que vous avez spécifié pour le nom d’utilisateur. Marquez ce champ comme SecureString pour le stocker en toute sécurité. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Exemple : utiliser l’authentification Windows
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Version héritée
Ces propriétés génériques sont prises en charge pour un service lié Amazon RDS pour SQL Server lorsque vous appliquez la version héritée :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonRdsForSqlServer | Oui |
| alwaysEncryptedSettings | Spécifiez les informations alwaysencryptedsettings nécessaires pour permettre à Always Encrypted de protéger les données sensibles stockées dans SQL Server à l’aide d’une identité managée ou d’un principal de service. Pour plus d’informations, consultez la section Utilisation d’Always Encrypted. S’il n’est pas spécifié, le paramètre par défaut Always Encrypted est désactivé. | Non |
| connectVia | Ce runtime d'intégration permet de se connecter au magasin de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Ce connecteur Amazon RDS pour SQL Server prend en charge les types d’authentification suivants. Pour plus d’informations, consultez les sections correspondantes.
Authentification SQL pour la version héritée
Pour utiliser l’authentification SQL, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| connectionString | Spécifiez les informations connectionStringnécessaires pour se connecter à la base de données Amazon RDS pour SQL Server. Spécifiez un nom de connexion comme nom d’utilisateur et vérifiez que la base de données que vous souhaitez connecter est mappée à cette connexion. | Oui |
| mot de passe | Si vous voulez définir un mot de passe dans Azure Key Vault, il vous faut extraire la configuration password de la chaîne de connexion. Pour plus d’informations, consultez Store credential in Azure Key Vault (Stocker les informations d’identification dans Azure Key Vault). |
Non |
Authentification Windows pour la version héritée
Pour utiliser l’authentification Windows, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| connectionString | Spécifiez les informations connectionStringnécessaires pour se connecter à la base de données Amazon RDS pour SQL Server. | Oui |
| userName | Indique un nom d'utilisateur. Exemple : nom-domaine\nom-utilisateur. | Oui |
| mot de passe | Spécifiez un mot de passe pour le compte d’utilisateur que vous avez spécifié pour le nom d’utilisateur. Marquez ce champ comme SecureString pour le stocker en toute sécurité. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit une liste des propriétés prises en charge par le jeu de données SQL Server.
Pour copier des données depuis et vers la base de données SQL Server, les propriétés suivantes sont prises en charge :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de l'ensemble de données doit être définie comme AmazonRdsForSqlServerTable. | Oui |
| schéma | Nom du schéma. | Non |
| table | Nom de la table/vue. | Non |
| tableName | Nom de la table/vue avec schéma. Cette propriété est prise en charge pour la compatibilité descendante. Pour les nouvelles charges de travail, utilisez schema et table. |
Non |
Exemple
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l'article Pipelines. Cette section fournit une liste des propriétés prises en charge par le jeu de données SQL Server.
Amazon RDS pour SQL Server en tant que source
Conseil
Pour charger efficacement les données d'Amazon RDS for SQL Server en utilisant le partitionnement des données, apprenez-en plus sur la copie parallèle de la base de données SQL.
Pour copier des données depuis Amazon RDS for SQL Server, définissez le type de source dans l'activité de copie sur AmazonRdsForSqlServerSource. Les propriétés prises en charge dans la section source de l'activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l'activité de copie doit être définie sur AmazonRdsForSqlServerSource. | Oui |
| sqlReaderQuery | Utiliser la requête SQL personnalisée pour lire les données. par exemple select * from MyTable. |
Non |
| sqlReaderStoredProcedureName | Cette propriété est le nom de la procédure stockée qui lit les données dans la table source. La dernière instruction SQL doit être une instruction SELECT dans la procédure stockée. | Non |
| storedProcedureParameters | Ces paramètres concernent la procédure stockée. Les valeurs autorisées sont des paires de noms ou de valeurs. Les noms et la casse des paramètres doivent correspondre aux noms et à la casse des paramètres de procédure stockée. |
Non |
| isolationLevel | Spécifie le comportement de verrouillage des transactions pour la source SQL. Les valeurs autorisées sont les suivantes : ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. S’il n’est pas spécifié, le niveau d’isolation par défaut de la base de données est utilisé. Pour plus d’informations, consultez ce document. | Non |
| partitionOptions | Spécifie les options de partitionnement des données utilisées pour charger les données depuis Amazon RDS for SQL Server. Les valeurs autorisées sont les suivantes : None (valeur par défaut), PhysicalPartitionsOfTable et DynamicRange. Lorsqu'une option de partition est activée (c'est-à-dire non None), le degré de parallélisme pour charger simultanément les données d'Amazon RDS for SQL Server est contrôlé par le parallelCopiesparamètre de l'activité de copie. |
Non |
| partitionSettings | Spécifiez le groupe de paramètres pour le partitionnement des données. S’applique lorsque l’option de partitionnement n’est pas None. |
Non |
Sous partitionSettings : |
||
| partitionColumnName | Spécifiez le nom de la colonne source en type entier ou date/DateHeure (int, smallint, bigint, date, smalldatetime, datetime, datetime2 ou datetimeoffset) qu’utilisera le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table seront automatiquement détectés et utilisés en tant que colonne de partition.S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?DfDynamicRangePartitionCondition dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
| partitionUpperBound | Valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. S’applique lorsque l’option de partitionnement est DynamicRange. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
| partitionLowerBound | Valeur minimale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. S’applique lorsque l’option de partitionnement est DynamicRange. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
Notez les points suivants :
- Si sqlReaderQuery est spécifié pour AmazonRdsForSqlServerSource, l'activité de copie exécute cette requête contre la source Amazon RDS for SQL Server pour obtenir les données. Vous pouvez également spécifier une procédure stockée en spécifiant sqlReaderStoredProcedureName et storedProcedureParameters si la procédure stockée accepte des paramètres.
- Lorsque vous utilisez une procédure stockée dans la source pour récupérer des données, sachez que si votre procédure stockée est conçue pour renvoyer un schéma différent quand une valeur de paramètre différente est entrée, vous risquez d’échouer ou d’obtenir un résultat inattendu lors de l’importation d’un schéma à partir de l’interface utilisateur ou lors de la copie de données dans la base de données SQL avec création de table automatique.
Exemple : Utiliser une requête SQL
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemple : Utilisation d'une procédure stockée
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Définition de la procédure stockée
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Copier en parallèle à partir de la base de données SQL
Le connecteur Amazon RDS for SQL Server dans l'activité de copie fournit un partitionnement des données intégré pour copier les données en parallèle. Vous trouverez des options de partitionnement de données dans l’onglet Source de l’activité de copie.
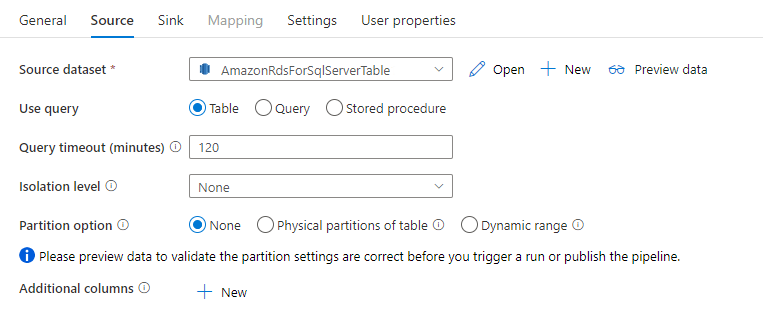
Lorsque vous activez la copie partitionnée, l'activité de copie exécute des requêtes parallèles contre votre source Amazon RDS for SQL Server pour charger les données par partitions. Le degré de parallélisme est contrôlé via le paramètre parallelCopies sur l’activité de copie. Par exemple, si vous définissez parallelCopies quatre, le service génère et exécute simultanément quatre requêtes basées sur l'option de partition et les paramètres spécifiés, et chaque requête récupère une partie des données de votre Amazon RDS for SQL Server.
Nous vous suggérons d'activer la copie parallèle avec le partitionnement des données, en particulier lorsque vous chargez une grande quantité de données depuis votre Amazon RDS for SQL Server. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. | Option de partition : Partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partition. Pour vérifier si votre table possède, ou non, une partition physique, vous pouvez vous reporter à cette requête. |
| Chargement complet d’une table volumineuse, sans partitions physiques, avec une colonne d’entiers ou DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Colonne de partition (facultatif) : Spécifiez la colonne utilisée pour partitionner les données. Si la valeur n’est pas spécifiée, la colonne de la clé primaire est utilisée. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes de la table sont partitionnées et copiées. S’il n’est pas spécifié, l’activité Copy détecte automatiquement les valeurs et peut prendre beaucoup de temps en fonction des valeurs MIN et MAX. Il est recommandé de fournir une limite supérieure et une limite inférieure. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions, (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, sans partitions physiques, et avec une colonne d’entiers ou de date/DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes du résultat de la requête sont partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). Voici d’autres exemples de requêtes pour différents scénarios : 1. Interroger l’ensemble de la table : SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Interroger une table avec une sélection de colonnes et des filtres de la clause WHERE supplémentaires : SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Effectuer une requête avec des sous-requêtes : SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Effectuer une requête avec une partition dans une sous-requête : SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Meilleures pratiques pour charger des données avec l’option de partition :
- Choisissez une colonne distinctive comme colonne de partition (p. ex. : clé primaire ou clé unique) pour éviter l’asymétrie des données.
- Si la table possède une partition intégrée, utilisez l’option de partition « Partitions physiques de la table » pour obtenir de meilleures performances.
- Si vous utilisez Azure Integration Runtime pour copier des données, vous pouvez définir des « unités d’intégration de données (DIU) » plus grandes (>4) pour utiliser davantage de ressources de calcul. Vérifiez les scénarios applicables ici.
- Le « degré de parallélisme de copie » contrôle le nombre de partitions : un nombre trop élevé nuit parfois aux performances. Il est recommandé de définir ce nombre selon (DIU ou nombre de nœuds d'IR auto-hébergé) * (2 à 4).
Exemple : chargement complet à partir d’une table volumineuse, avec des partitions physiques
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemple : requête avec partition dynamique par spécification de plages de valeurs
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exemple de requête pour vérifier une partition physique
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la table a une partition physique, vous voyez « HasPartition » avec la valeur « yes » (oui) comme suit.

Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Utilisation d’Always Encrypted
Lorsque vous copiez des données de/vers Amazon RDS for SQL Server avec Always Encrypted, suivez les étapes ci-dessous :
Stockez la valeur Clé principale de colonne (CMK) dans un coffre Azure Key Vault. En savoir plus sur la configuration d’Always Encrypted à l’aide d’Azure Key Vault
Vérifiez que le coffre de clés où la valeur Clé principale de colonne (CMK) est stockée est totalement accessible. Consultez cet article pour connaître les autorisations requises.
Créez un service lié pour vous connecter à votre base de données SQL et activez la fonction « Always Encrypted » en utilisant une identité managée ou un principal de service.
Résoudre les problèmes de connexion
Configurez votre instance Amazon RDS for SQL Server pour accepter les connexions à distance. Lancez Amazon RDS for SQL Server Management Studio, cliquez avec le bouton droit de la souris sur le serveur, puis sélectionnez Propriétés. Sélectionnez Connexions dans la liste, puis cochez la case Autoriser les accès distants à ce serveur.
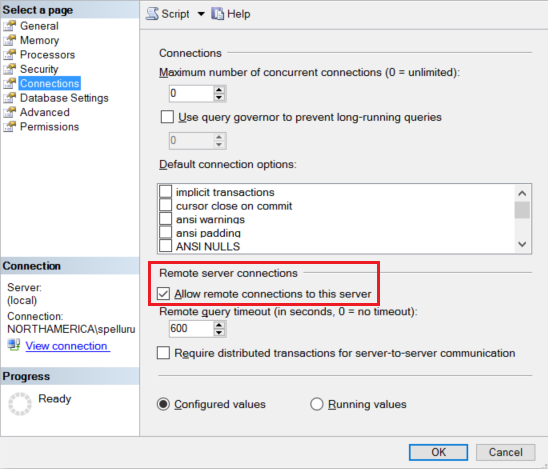
Pour obtenir des instructions détaillées, consultez Configurer l’option de configuration du serveur d’accès à distance.
Démarrer Amazon RDS for SQL Server Configuration Manager. Développez Amazon RDS for SQL Server Network Configuration pour l'instance souhaitée, puis sélectionnez Protocoles pour MSSQLSERVER. Des protocoles s’affichent dans le volet droit. Activez TCP/IP en cliquant avec le bouton droit sur TCP/IP, puis en sélectionnant Activer.
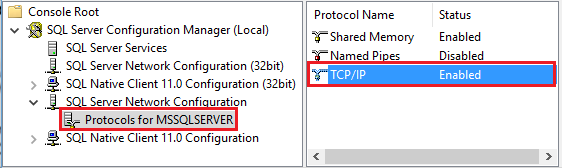
Pour obtenir des informations supplémentaires et découvrir d’autres façons d’activer le protocole TCP/IP, consultez Activer ou désactiver un protocole réseau de serveur.
Dans la même fenêtre, double-cliquez sur TCP/IP pour lancer la fenêtre des propriétés TCP/IP.
Allez sous l’onglet Adresses IP . Faites défiler l’écran vers le bas jusqu’à la section IPAll. Notez le port TCP. La valeur par défaut est 1433.
Créez une règle de Pare-feu Windows sur l’ordinateur pour autoriser le trafic à entrer par ce port.
Vérifiez la connexion: Pour vous connecter à Amazon RDS for SQL Server en utilisant un nom entièrement qualifié, utilisez Amazon RDS for SQL Server Management Studio à partir d'une autre machine. par exemple
"<machine>.<domain>.corp.<company>.com,1433".
Mettre à niveau la version d’Amazon RDS pour SQL Server
Pour mettre à niveau la version d’Amazon RDS pour SQL Server, sur la page Modifier le service lié, sélectionnez Recommandé sous Version et configurez le service lié en faisant référence aux Propriétés du service lié pour la version recommandée.
Différences entre la version recommandée et la version héritée
Le tableau ci-dessous présente les différences dans Amazon RDS pour SQL Server lors de l’utilisation de la version recommandée et de la version héritée.
| Version recommandée | Version héritée |
|---|---|
Prend en charge TLS 1.3 via encrypt en tant que strict. |
TLS 1.3 n’est pas pris en charge. |
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour