Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article décrit les fonctionnalités d’optimisation des performances de l’activité de copie que vous pouvez tirer parti des pipelines Azure Data Factory et Synapse.
Configuration des fonctionnalités de performances avec l’interface utilisateur
Lorsque vous sélectionnez un Copy activity sur le canevas de l’éditeur de pipeline et choisissez l’onglet Paramètres dans la zone de configuration de l’activité sous le canevas, vous verrez les options permettant de configurer toutes les fonctionnalités de performances détaillées ci-dessous.
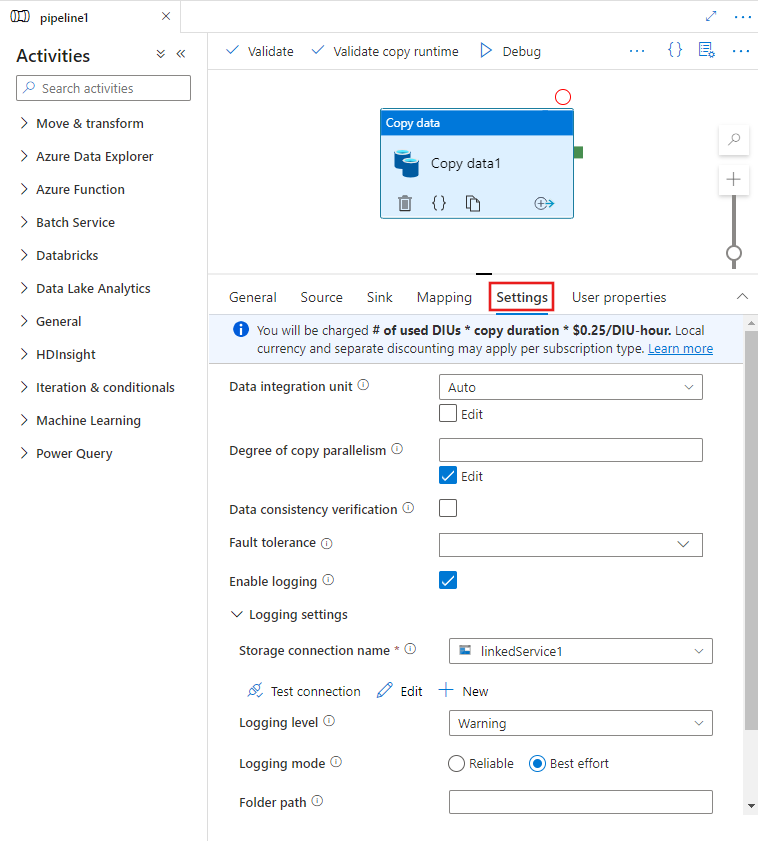
Unités d’intégration de données
Une unité d’intégration de données est une mesure qui représente la puissance (combinaison de l’allocation de ressources de processeur, de mémoire et de réseau) d’une seule unité dans le service. Unité d'Intégration de Données s’applique uniquement au runtime d’intégration Azure, mais pas au runtime d’intégration auto-hébergé.
Le nombre d’unités d’intégration de données (DIU) autorisées pour permettre l’exécution d’une activité de copie se situe entre 4 et 256. Si ce paramètre n’est pas spécifié ou si vous choisissez « Auto » dans l’interface utilisateur, le service applique dynamiquement le paramètre DIU optimal en fonction de la paire source-récepteur et du schéma de données. Le tableau suivant répertorie les plages de DIU (unités d'intégration de données) prises en charge et le comportement par défaut dans différents scénarios de copie.
| Scénario de copie | Plage d’unités d’intégration de données prise en charge | Unités d’intégration de données par défaut déterminées par service |
|---|---|---|
| Entre les stockages de fichiers |
-
Copie depuis ou vers un fichier unique : 4 - Copie depuis ou vers plusieurs fichiers : de 4 à 256, selon le nombre et la taille des fichiers Par exemple, si vous copiez des données à partir d’un dossier contenant 4 fichiers volumineux et que vous choisissez de conserver la hiérarchie, le nombre effectif maximal d’unités d’intégration de données est de 16. Lorsque vous choisissez de fusionner un fichier, le nombre effectif maximal d’unités d’intégration de données est de 4. |
Entre 4 et 32, selon le nombre et la taille des fichiers |
| D’un magasin de fichiers vers un magasin hors fichier |
-
Copie depuis un fichier unique : 4 - Copie depuis plusieurs fichiers : de 4 à 256, selon le nombre et la taille des fichiers Par exemple, si vous copiez des données à partir d’un dossier contenant 4 fichiers volumineux, le nombre effectif maximal d’unités d’intégration de données est de 16. |
-
Copy dans Azure SQL Database ou Azure Cosmos DB : entre 4 et 16 en fonction du niveau récepteur (DTU/RU) et du modèle de fichier source - Copier dans Azure Synapse Analytics en utilisant l'instruction PolyBase ou COPY : 2 - Autre scénario : 4 |
| D’un magasin hors fichier vers un magasin de fichiers |
-
Copy à partir de magasins de données compatibles avec l’option de partition (y compris Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server et Teradata) : 4-256 lors de l’écriture dans un dossier et 4 lors de l’écriture dans un fichier unique. Remarquez que la partition de données par source peut utiliser jusqu’à 4 unités d’intégration de données. - Autres scénarios : 4 |
-
Copie depuis REST ou HTTP : 1 - Copie depuis Amazon Redshift à l’aide d’UNLOAD :4 - Autre scénario : 4 |
| Entre des magasins hors fichiers |
-
Copy à partir de magasins de données compatibles avec l’option de partition (y compris Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server et Teradata) : 4-256 lors de l’écriture dans un dossier et 4 lors de l’écriture dans un fichier unique. Remarquez que la partition de données par source peut utiliser jusqu’à 4 unités d’intégration de données. - Autres scénarios : 4 |
-
Copie depuis REST ou HTTP : 1 - Autre scénario : 4 |
Vous pouvez voir les DIU utilisées pour chaque exécution de copie dans la vue de surveillance de l'activité de copie ou dans les résultats de l'activité. Pour plus d’informations, consultez Surveillance de l'activité de copie. Pour remplacer cette valeur par défaut, spécifiez une valeur pour la propriété dataIntegrationUnits, comme suit. Le nombre réel d’unités d’intégration de données que l’opération de copie utilise au moment de l’exécution est égal ou inférieur à la valeur configurée, en fonction de votre modèle de données.
Vous serez facturé # de DIUs utilisées * durée de copie * prix unitaire/DIU-heure. Consultez les tarifs actuels ici. Une monnaie locale et une remise distincte peuvent s’appliquer par type d’abonnement.
Exemple :
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Extensibilité du runtime d’intégration auto-hébergé
Si vous souhaitez obtenir un débit plus élevé, vous pouvez appliquer un scale-up ou un scale-out au runtime d’intégration auto-hébergé :
- Si le processeur et la mémoire disponible sur le nœud du runtime d’intégration auto-hébergé ne sont pas entièrement utilisés, mais que l’exécution de travaux simultanés atteint la limite, vous devez procéder à un scale-up en augmentant le nombre de travaux simultanés pouvant s’exécuter sur un nœud. Pour obtenir des instructions, consultez ces informations.
- Si, en revanche, le processeur est élevé sur le nœud du runtime d’intégration auto-hébergé ou que la mémoire disponible est faible, vous pouvez ajouter un nouveau nœud pour faciliter le scale-out de la charge sur les divers nœuds. Pour obtenir des instructions, consultez ces informations.
Notez que dans les scénarios suivants, l’exécution d’une activité de copie simple peut tirer parti de plusieurs nœuds d’IR auto-hébergé :
- Copiez les données à partir de magasins de fichiers, en tenant compte du nombre et de la taille des fichiers.
- Copier des données à partir d’un magasin de données avec option de partition (y compris Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server et Teradata), en fonction du nombre de partitions de données.
Copie en parallèle
Vous pouvez définir la copie parallèle (propriété parallelCopies dans la définition JSON de l’Copy activity, ou Degree of parallelism dans l’onglet Settings des propriétés Copy activity de l’interface utilisateur) sur copy activity pour indiquer le parallélisme que vous souhaitez que le copy activity utilise. Vous pouvez voir cette propriété comme le nombre maximum de threads dans l’activité de copie qui lisent dans votre source ou écrivent dans vos magasins de données récepteurs en parallèle.
La copie parallèle est orthogonale aux unités d’intégration de données ou aux nœuds de runtime d’intégration auto-hébergé. Elle est comptée sur toutes les unités d’intégration de données ou tous les nœuds de runtime d’intégration auto-hébergé.
Pour chaque exécution d’activité de copie, par défaut, le service applique dynamiquement le paramètre de copie en parallèle optimal en fonction de la paire source-récepteur et du modèle de données.
Conseil
Le comportement par défaut de la copie parallèle vous donne généralement le meilleur débit, déterminé automatiquement par le service en fonction de votre paire source-récepteur, du modèle de données et du nombre d’unités d’intégration de données ou du nombre de processeurs/mémoire/nœuds de l’IR auto-hébergé. Reportez-vous à Résoudre les problèmes de performances de l’activité de copie pour savoir quand ajuster la copie en parallèle.
Le tableau suivant liste le comportement de copie en parallèle :
| Scénario de copie | Comportement de copie en parallèle |
|---|---|
| Entre les stockages de fichiers |
parallelCopies détermine le parallélisme au niveau du fichier. La segmentation au sein de chaque fichier se produit en arrière-plan de manière automatique et transparente. Elle est conçue pour utiliser la taille de segment la plus appropriée pour un type de magasin de données particulier pour charger les données en parallèle. Le nombre réel de copies en parallèle que l’activité de copie utilise au moment de l’exécution ne dépasse pas le nombre de fichiers dont vous disposez. Si le comportement de copie est défini sur mergeFile dans le puits de fichier, l’activité de copie ne peut pas tirer parti du parallélisme au niveau du fichier. |
| D’un magasin de fichiers vers un magasin hors fichier | - Lors de la copie de données dans Azure SQL Database ou Azure Cosmos DB, la copie parallèle par défaut dépend également du niveau récepteur (nombre de DTU/RU). - Lors de la copie de données dans Azure Table, la copie parallèle par défaut est 4. |
| D’un magasin hors fichier vers un magasin de fichiers | - Lors de la copie de données à partir d’un magasin de données avec option de partition (y compris Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS pour SQL Server et Teradata), la copie parallèle par défaut est 4. Le nombre réel de copies en parallèle que l’activité de copie utilise au moment de l’exécution ne dépasse pas le nombre de partitions de données dont vous disposez. Lorsque vous utilisez des Integration Runtime auto-hébergés et que vous copiez vers Azure Blob/ADLS Gen2, notez que la copie parallèle maximale effective est de 4 ou 5 par nœud IR. - Pour d’autres scénarios, la copie en parallèle ne prend pas effet. Même si le parallélisme est spécifié, il n’est pas appliqué. |
| Entre des magasins hors fichiers | - Lors de la copie de données dans Azure SQL Database ou Azure Cosmos DB, la copie parallèle par défaut dépend également du niveau récepteur (nombre de DTU/RU). - Lors de la copie de données à partir d’un magasin de données avec option de partition (y compris Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS pour SQL Server et Teradata), la copie parallèle par défaut est 4. - Lors de la copie de données dans Azure Table, la copie parallèle par défaut est 4. |
Pour contrôler la charge sur les machines qui hébergent vos magasins de données ou pour ajuster les performances de copie, vous pouvez remplacer la valeur par défaut et spécifier une valeur pour la propriété parallelCopies. La valeur doit être un nombre entier supérieur ou égal à 1. Au moment de l’exécution, pour des performances optimales, l’activité de copie utilise une valeur inférieure ou égale à la valeur que vous avez définie.
Lorsque vous spécifiez une valeur pour la propriété parallelCopies, prenez en compte l’augmentation de la charge sur vos stockages de données source et cibles. Considérez également l’augmentation de la charge pour le runtime d’intégration auto-hébergé si l’activité de copie repose sur celui-ci. Cela se produit en particulier lorsque plusieurs activités ou exécutions simultanées des mêmes activités ont lieu en même temps dans la même banque de données. Si vous remarquez que le magasin de données ou le runtime d’intégration auto-hébergé est submergé par la charge, diminuez la valeur parallelCopies pour alléger la charge.
Exemple :
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
copie intermédiaire
Lorsque vous copiez des données d'un magasin de données source vers un magasin de données récepteur, vous pouvez choisir d’utiliser Azure Blob Storage ou Azure Data Lake Storage Gen2 comme magasin de mise en attente intermédiaire. La fonctionnalité intermédiaire est particulièrement utile dans les cas suivants :
- Vous souhaitez ingérer des données à partir de différents magasins de données dans Azure Synapse Analytics via PolyBase, copier des données depuis/vers Snowflake ou ingérer des données à partir d’Amazon Redshift/HDFS de manière performante. Pour plus de détails, consultez :
- Vous ne souhaitez pas ouvrir des ports autres que le port 80 et le port 443 dans votre pare-feu, en raison des stratégies informatiques d’entreprise. Par exemple, lorsque vous copiez des données d’un magasin de données local vers un Azure SQL Database ou un Azure Synapse Analytics, vous devez activer la communication TCP sortante sur le port 1433 pour le pare-feu Windows et votre pare-feu d’entreprise. Dans ce scénario, la copie intermédiaire peut tirer parti du runtime d’intégration auto-hébergé pour d’abord copier des données vers un stockage intermédiaire via HTTP ou HTTPS sur le port 443, puis charger les données de préproduction dans SQL Database ou Azure Synapse Analytics. Dans ce flux, vous n’avez pas besoin d’activer le port 1433.
- Il peut être assez long parfois d’effectuer des déplacements de données hybrides (c’est-à-dire, de copier à partir d’une banque de données locale vers une banque de données cloud) sur une connexion réseau lente. Pour améliorer les performances, vous pouvez utiliser une copie intermédiaire pour compresser les données locales afin de réduire le temps nécessaire pour déplacer des données vers la banque de données intermédiaire dans le cloud. Ensuite, vous pouvez décompresser les données dans la banque intermédiaire avant de charger dans la banque de données de destination.
Fonctionnement de la copie intermédiaire
Lorsque vous activez la fonctionnalité de préproduction, commencez par copier les données du magasin de données source vers le stockage intermédiaire (apportez votre propre Azure Blob ou Azure Data Lake Storage Gen2). Ensuite, les données sont copiées à partir du stockage intermédiaire vers le magasin de données récepteur. L’activité de copie gère automatiquement le flux en deux étapes, et nettoie les données temporaires du stockage intermédiaire une fois le déplacement des données terminé.

Vous devez accorder l’autorisation de suppression à votre Azure Data Factory dans votre stockage intermédiaire afin que les données temporaires puissent être nettoyées après l’exécution de l’activité de copie.
Lorsque vous activez le déplacement des données à l’aide d’un magasin de données intermédiaire, vous pouvez indiquer si vous souhaitez compresser les données avant de les déplacer du magasin de données source vers le stockage intermédiaire, puis les décompresser avant leur transfert d’un magasin de données intermédiaire ou temporaire vers le magasin de données récepteur.
Actuellement, vous ne pouvez pas copier des données entre deux banques de données qui sont connectées via différents runtimes d’intégration auto-hébergés, ni avec ni sans copie intermédiaire. Dans ce scénario, vous pouvez configurer deux activités de copie explicitement chaînées pour copier à partir de la source vers un environnement intermédiaire, puis de l’environnement intermédiaire vers le récepteur.
Configuration
Configurez le paramètre enableStaging dans l’activité de copie pour spécifier si vous souhaitez que les données soient placées dans un stockage intermédiaire avant d’être chargées dans un magasin de données de destination. Lorsque vous définissez enableStaging sur TRUE, spécifiez les propriétés supplémentaires répertoriées dans le tableau suivant.
| Propriété | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| enableStaging | Indiquez si vous souhaitez copier les données via un magasin de données intermédiaire. | Faux | Non |
| linkedServiceName | Spécifiez le nom d'un service lié Azure Blob Storage ou Azure Data Lake Storage Gen2, qui se réfère à l'instance de stockage que vous utilisez comme magasin de transit intermédiaire. | N/A | Oui, quand enableStaging est défini sur TRUE |
| chemin | Spécifiez le chemin dans lequel vous souhaitez placer les données intermédiaires. Si vous ne renseignez pas le chemin d’accès, le service crée un conteneur pour stocker les données temporaires. | N/A | Non (Oui quand storageIntegration dans le connecteur Snowflake est spécifié) |
| enableCompression | Spécifie si les données doivent être compressées avant d’être copiées vers la destination. Ce paramètre réduit le volume de données transférées. | Faux | Non |
Note
Si vous utilisez une copie intermédiaire avec compression activée, l’authentification du principal du service ou MSI pour le service lié d’objets blob intermédiaire n’est pas prise en charge.
Voici un exemple de définition de l’activité de copie avec les propriétés qui sont décrites dans le tableau précédent :
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Impact sur la facturation de la copie intermédiaire
Vous êtes facturé en fonction de deux étapes : la durée de la copie et le type de copie.
- Lorsque vous utilisez la copie intermédiaire lors d’une copie dans le cloud (qui copie des données à partir d’une banque de données cloud vers une autre banque de données cloud, les deux étapes utilisant le runtime d’intégration Azure), vous êtes facturé au prix de [somme de la durée de copie pour les étapes 1 et 2] x [prix unitaire de la copie dans le cloud].
- Lorsque vous utilisez la copie intermédiaire lors d’une copie hybride (qui copie des données à partir d’une banque de données locale vers une banque de données cloud, une étape utilisant le runtime d’intégration auto-hébergé), vous êtes facturé au prix de [durée de la copie hybride] x [prix unitaire de la copie hybride] + [durée de la copie cloud] x [prix unitaire de la copie cloud].
Contenu connexe
Consultez les autres articles relatifs à l’activité de copie :
- vue d’ensemble de l'activité de copie
- Guide des performances et de la scalabilité des activités de copie
- Résoudre les problèmes de performances de l’activité de copie
- Utilisez Azure Data Factory pour migrer des données de votre lac de données ou entrepôt de données vers Azure
- Migration des données depuis Amazon S3 vers Azure Storage