Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Les flux de données sont disponibles dans les pipelines Azure Data Factory et les pipelines Azure Synapse Analytics. Cet article s’applique aux flux de données de mappage. Si vous débutez avec les transformations, reportez-vous à l’article d’introduction Transformer des données à l’aide de flux de données de mappage.
La transformation de fractionnement conditionnel route les lignes de données vers différents flux en fonction de conditions de correspondance. La transformation de fractionnement conditionnel est similaire à une structure de décision CASE dans un langage de programmation. La transformation évalue les expressions, et selon les résultats, dirige la ligne de données vers le flux spécifié.
Configuration
Le paramètre SplitOn détermine si la ligne de données est acheminée vers le premier flux correspondant ou vers chaque flux auquel elle correspond.
Utilisez le générateur d’expressions de flux de données afin d’entrer une expression pour la condition de fractionnement. Pour ajouter une nouvelle condition, cliquez sur l’icône plus dans une ligne existante. Vous pouvez également ajouter un flux par défaut pour les lignes qui ne correspondent à aucune condition.
Script de flux de données
Syntaxe
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Exemple
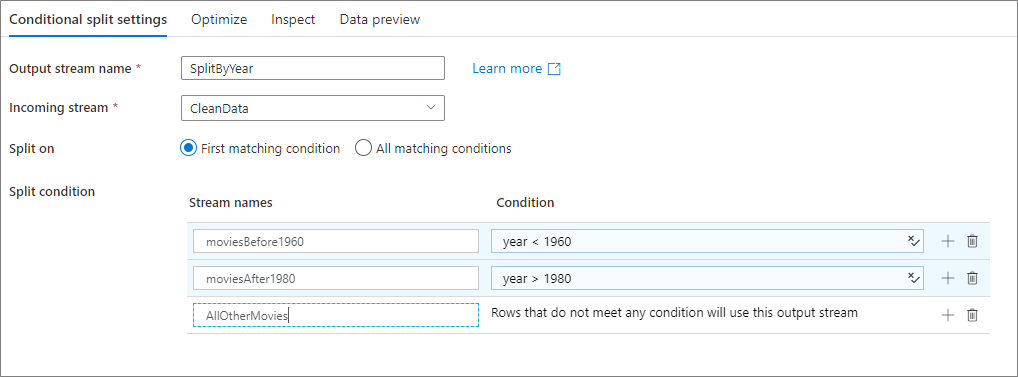
L’exemple ci-dessous illustre une transformation de fractionnement conditionnel nommée SplitByYear traitant le flux entrant CleanData. Cette transformation a deux conditions de fractionnement : year < 1960 et year > 1980.
disjoint est incorrect, car les données sont dirigées vers la première condition satisfaite et non vers l’ensemble des conditions correspondantes. Chaque ligne correspondant à la première condition est acheminée vers le flux de sortie moviesBefore1960. Toutes les lignes restantes correspondant à la deuxième condition sont acheminées vers le flux de sortie moviesAFter1980. Toutes les autres lignes sont acheminées vers le flux par défaut AllOtherMovies.
Dans l’interface utilisateur du service, cette transformation se présente comme sur l’image ci-dessous :
Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous :
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Contenu connexe
Les transformations de flux de données courantes utilisées avec le fractionnement conditionnel sont la transformation de jointure, la transformation de recherche et la transformation de sélection.