Transformations de recherche dans le flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Utilisez la transformation de recherche pour référencer des données provenant d’une autre source dans un flux de données. La transformation de recherche ajoute des colonnes de données mises en correspondance à vos données sources.
Une transformation de recherche est similaire à une jointure externe gauche. Toutes les lignes du flux principal existent dans le flux de sortie avec des colonnes supplémentaires venant du flux de recherche.
Configuration
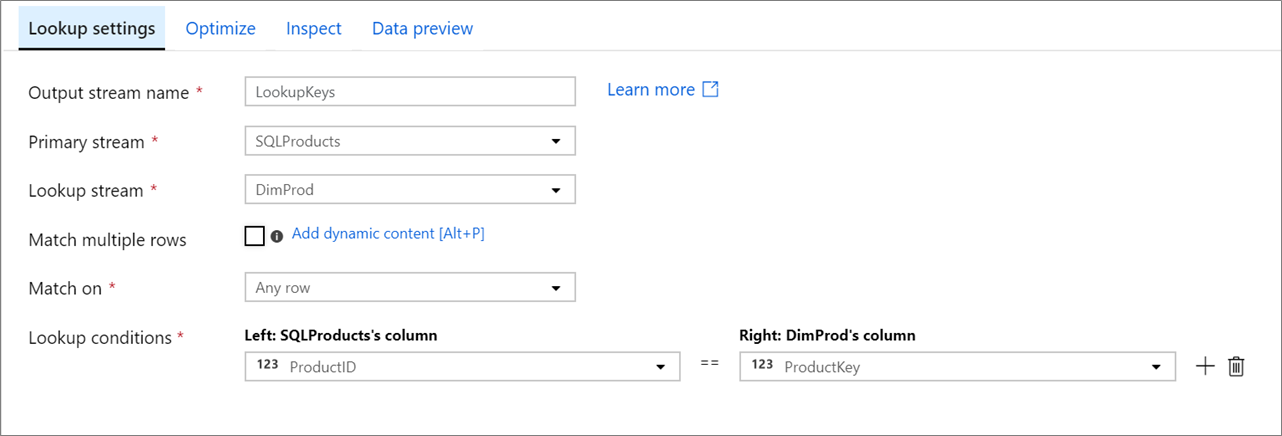
Flux principal : Le flux de données entrant. Ce flux est équivalent au côté gauche d’une jointure.
Flux de recherche : Les données ajoutées au flux de données principal. Les données ajoutées sont déterminées par les conditions de recherche. Ce flux est équivalent au côté droit d’une jointure.
Correspond à plusieurs lignes : Si cette option est activée, une ligne avec plusieurs correspondances dans le flux principal retourne plusieurs lignes. Dans le cas contraire, une seule ligne est retournée en fonction de la condition ’Match on'.
Correspond à : visible uniquement si l’option « Correspond à plusieurs lignes » n’est pas sélectionnée. Choisissez s’il faut faire correspondre sur n’importe quelle ligne, sur la première correspondance ou sur la dernière correspondance. Faire correspondre sur n’importe quelle ligne est recommandé, car c’est l’option qui s’exécute le plus rapidement. Si la première ligne ou la dernière ligne est sélectionnée, vous devez spécifier des conditions de tri.
Conditions de recherche : Choisissez les colonnes à faire correspondre. Si la condition d’égalité est remplie, les lignes sont considérées comme une correspondance. Pointez et sélectionnez « Colonne calculée » pour extraire une valeur à l’aide du Langage d’expression des flux de données.
Toutes les colonnes des deux flux sont incluses dans les données de sortie. Pour supprimer les colonnes en double ou indésirables, ajoutez une transformation de sélection après votre transformation de recherche. Les colonnes peuvent également être supprimées ou renommées dans une transformation de récepteur.
Jointures différentes
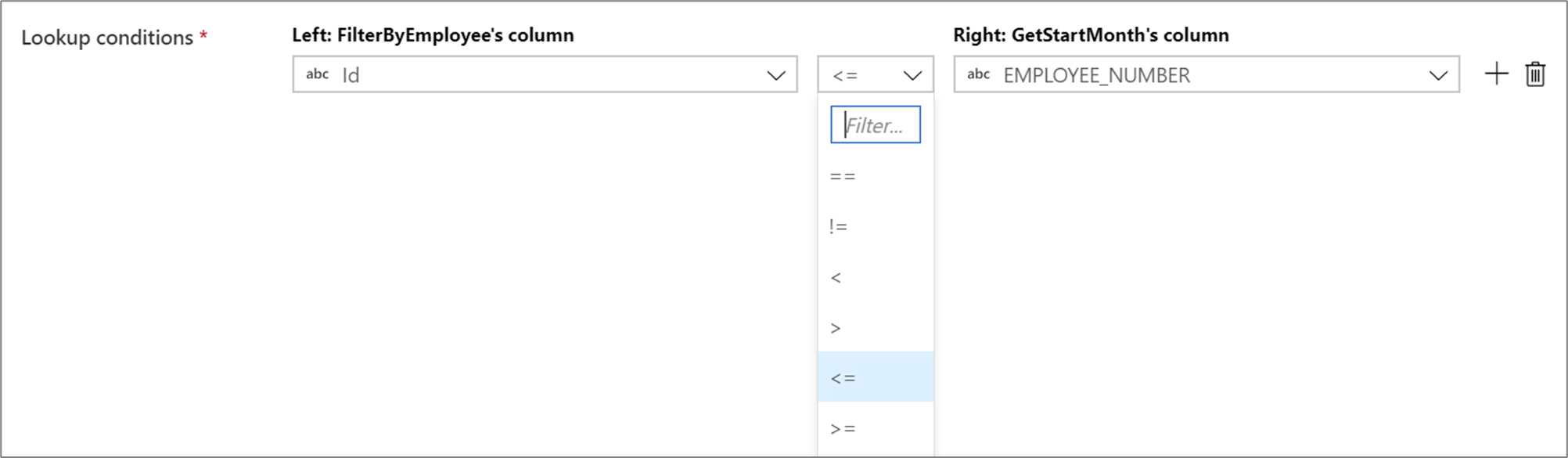
Pour utiliser un opérateur conditionnel tel que « différent de » (!=) ou « supérieur à » (>) dans vos conditions de recherche, modifiez la liste déroulante des opérateurs entre les deux colonnes. Des jointures différentes nécessitent qu’au moins l’un des deux flux soit diffusés en utilisant la diffusion fixe dans l’onglet Optimiser.
Analyse des lignes correspondantes
Après la transformation de recherche, la fonction isMatch() peut être utilisée pour déterminer si la recherche correspond à des lignes individuelles.
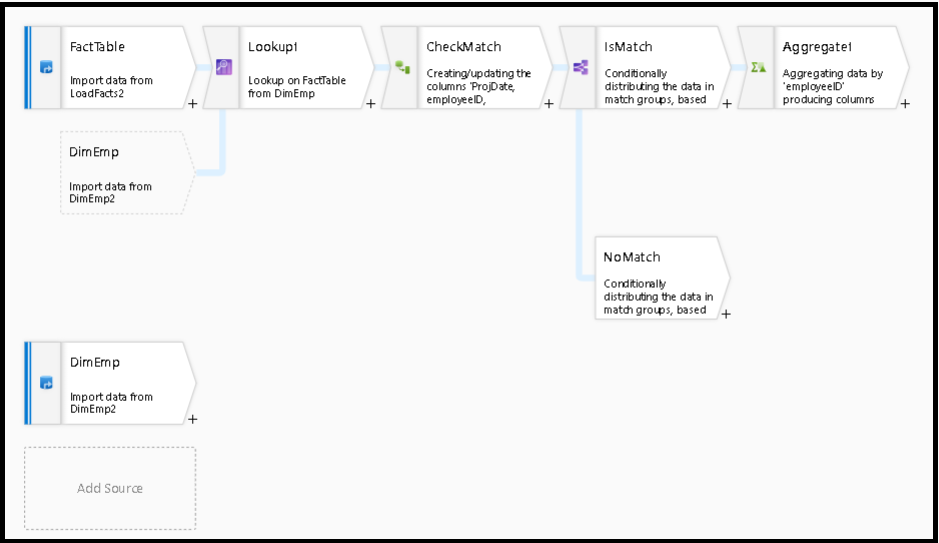
Un exemple de ce modèle consiste à utiliser la transformation de fractionnement conditionnel pour fractionner sur la fonction isMatch(). Dans l’exemple ci-dessus, les lignes correspondantes passent par le flux principal, et les lignes sans correspondance transitent par le flux NoMatch.
Test des conditions de recherche
Lorsque vous testez la transformation de recherche avec l’aperçu des données en mode débogage, utilisez un jeu de données connues peu volumineux. Lors de l’échantillonnage de lignes à partir d’un jeu de données volumineux, vous ne pouvez pas prédire quelles lignes et quelles clés seront lues dans le cadre du test. Le résultat n’est pas déterministe, ce qui signifie que vos conditions de jointure peuvent ne renvoyer aucun résultat.
Optimisation de la diffusion
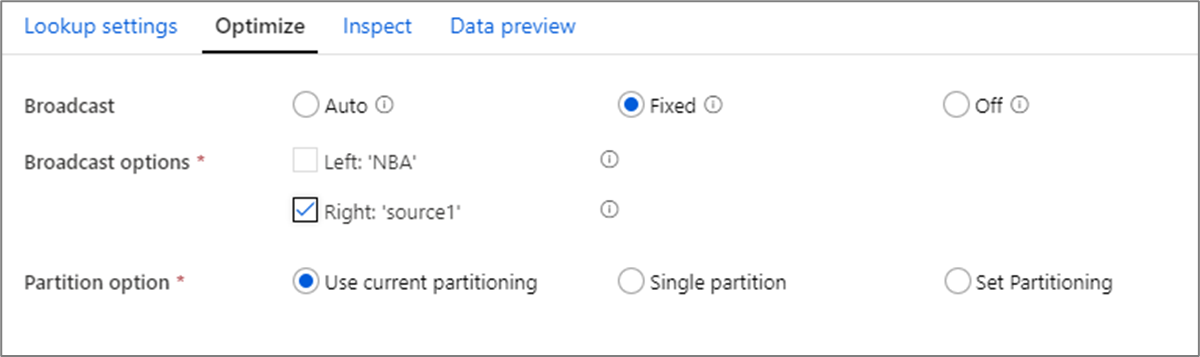
Dans les transformations de jointure, de recherche et d’existence, si l’un des flux de données ou les deux tiennent dans la mémoire de nœud Worker, vous pouvez optimiser les performances en activant la diffusion. Par défaut, le moteur Spark détermine automatiquement s’il faut diffuser un côté. Pour choisir manuellement le côté à diffuser, sélectionnez Fixe.
Il n’est pas recommandé de désactiver la diffusion à l’aide de l’option Désactivé à moins que vos jointures ne rencontrent des erreurs de délai d’attente.
Recherche mise en cache
Si vous effectuez plusieurs petites recherches sur la même source, un récepteur et une recherche en cache sont peut-être préférables à la transformation de recherche. La recherche d’une valeur maximale dans un magasin de données et la mise en correspondance des codes d’erreur avec une base de données de messages d’erreur sont des situations courantes dans lesquelles un récepteur de cache peut être préférable. Pour plus d’informations, apprenez-en plus sur les récepteurs de cache et les recherches mises en cache.
Script de flux de données
Syntaxe
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Exemple
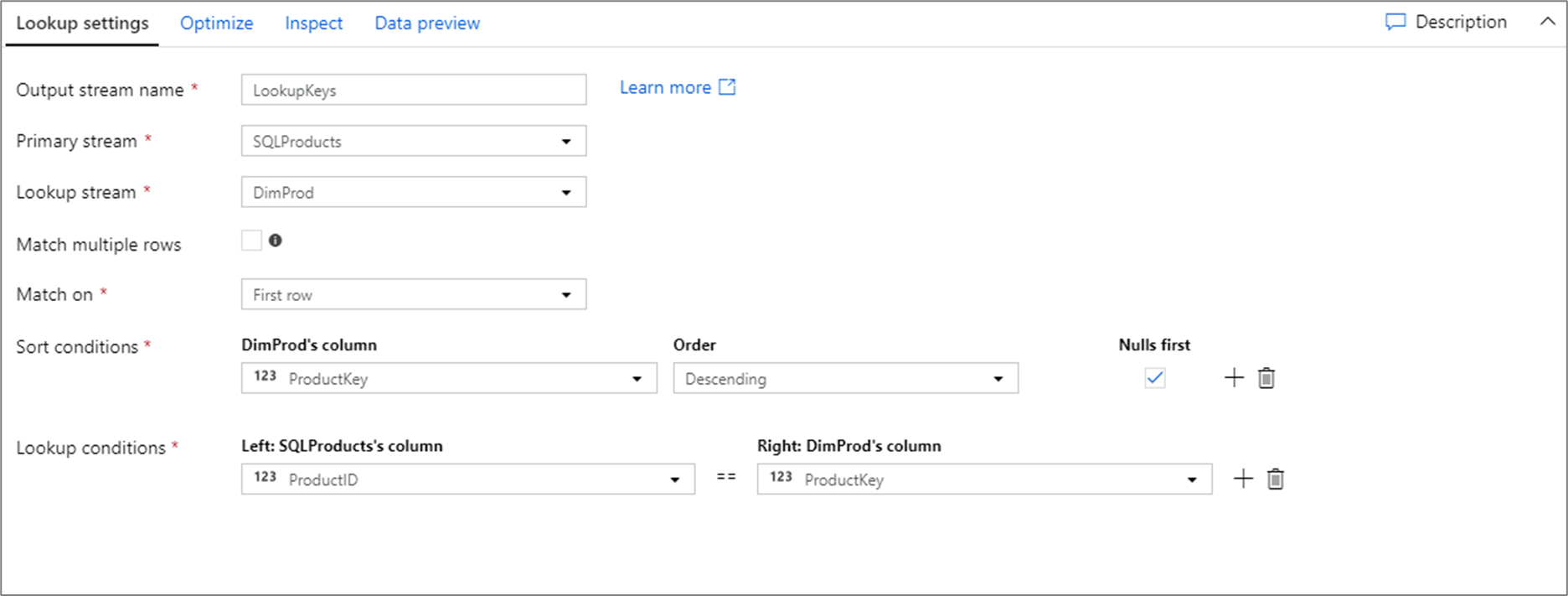
Le script de transmission de données pour la configuration de recherche ci-dessus se trouve dans l’extrait de code suivant.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Contenu connexe
- Les transformations join et exists prennent toutes les deux plusieurs entrées de flux
- Utiliser une transformation de fractionnement conditionnel avec
isMatch()pour fractionner des lignes sur des valeurs correspondantes et non correspondantes