Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans cet article, vous allez apprendre à configurer Mosaic AI Gateway sur un point de terminaison de service de modèle.
Spécifications
- Un espace de travail Databricks dans une région où la modélisation est prise en charge par le système. Consultez Modèle servant la disponibilité régionale.
- Un point de terminaison de service de modèle. Vous pouvez utiliser l’un des points de terminaison de paiement par jeton préconfigurés sur votre espace de travail ou effectuer les opérations suivantes :
- Pour créer un point de terminaison pour les modèles externes, effectuez les étapes 1 et 2 de Créer un modèle externe servant le point de terminaison.
- Pour créer un point de terminaison pour le débit provisionné, consultez API Foundation Model avec débit provisionné.
- Pour créer un point de terminaison pour un modèle personnalisé, consultez Créer un point de terminaison.
Configurer AI Gateway à l’aide de l’interface utilisateur
Dans la section AI Gateway de la page de création de point d'accès, vous pouvez configurer individuellement les fonctionnalités de l'AI Gateway. Consultez Fonctionnalités prises en charge pour savoir quelles fonctionnalités sont disponibles sur les points de terminaison de service de modèle externes et les points de terminaison à débit provisionné.
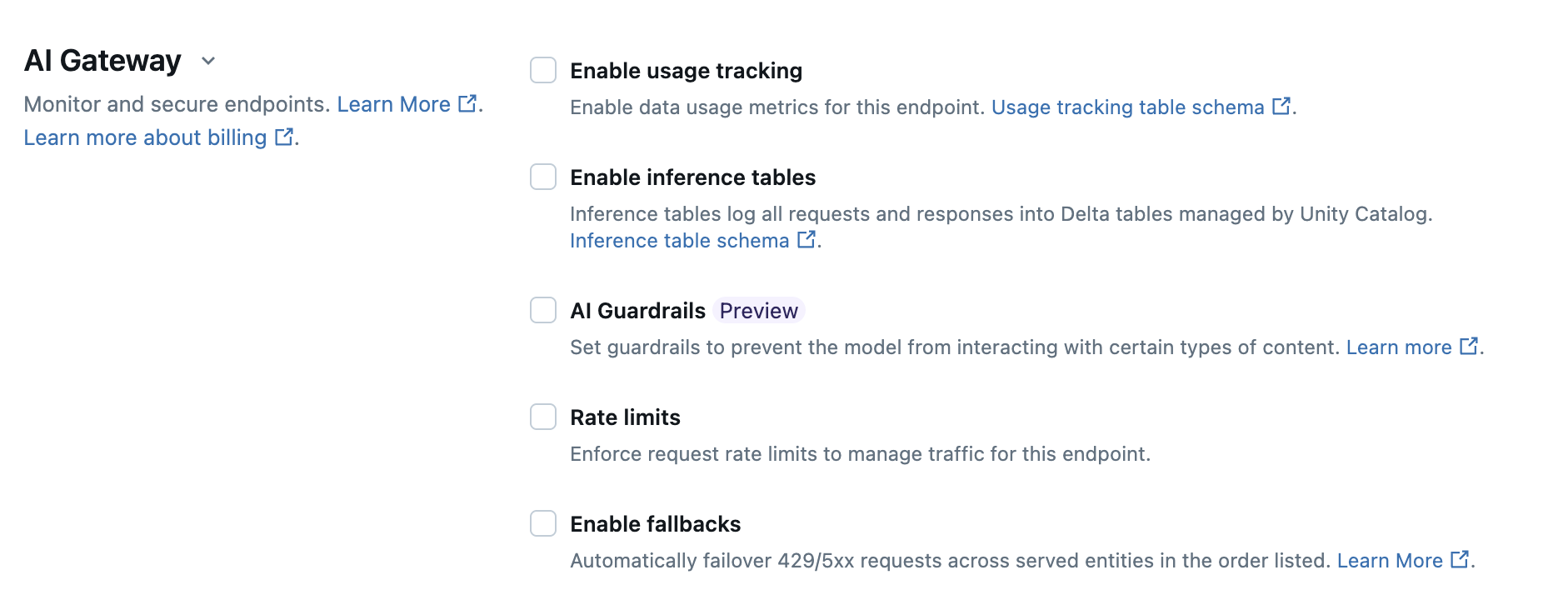
Le tableau suivant résume comment configurer la passerelle AI pendant la création d’un point de terminaison à l’aide de l’interface utilisateur de service. Si vous préférez effectuer cette opération en la programmant, consultez l'exemple de notebook.
| Fonctionnalité | Comment activer | Détails |
|---|---|---|
| Suivi de l’utilisation | Sélectionnez Enable usage tracking pour activer le suivi et la surveillance des métriques d’utilisation des données. Cette fonctionnalité est activée par défaut pour les points de terminaison de paiement par jeton . |
|
| Journalisation des charges utiles | Sélectionnez Enable inference tables pour journaliser automatiquement les requêtes et les réponses de votre point de terminaison dans des tables Delta managées par Unity Catalog. |
|
| Garde-fous IA | Consultez Configurer les garde-fous IA dans l'interface utilisateur. |
|
| Limites du taux de transfert | Sélectionnez les limites de débit pour gérer le trafic pour votre point de terminaison et spécifiez le nombre de requêtes par minute que votre point de terminaison peut recevoir.
|
Par exemple,
|
| Fractionnement du trafic | Dans la section Entités servies , spécifiez le pourcentage de trafic que vous souhaitez router vers des modèles spécifiques. Pour configurer le fractionnement du trafic sur votre point de terminaison par programmation, consultez Servir plusieurs modèles externes à un point de terminaison. |
|
| Options de Repli | Sélectionnez Enable fallbacks (activer les solutions de secours) dans la section Gateway IA pour envoyer votre demande à d’autres modèles desservis sur le point de terminaison en guise de solution de repli. |
|
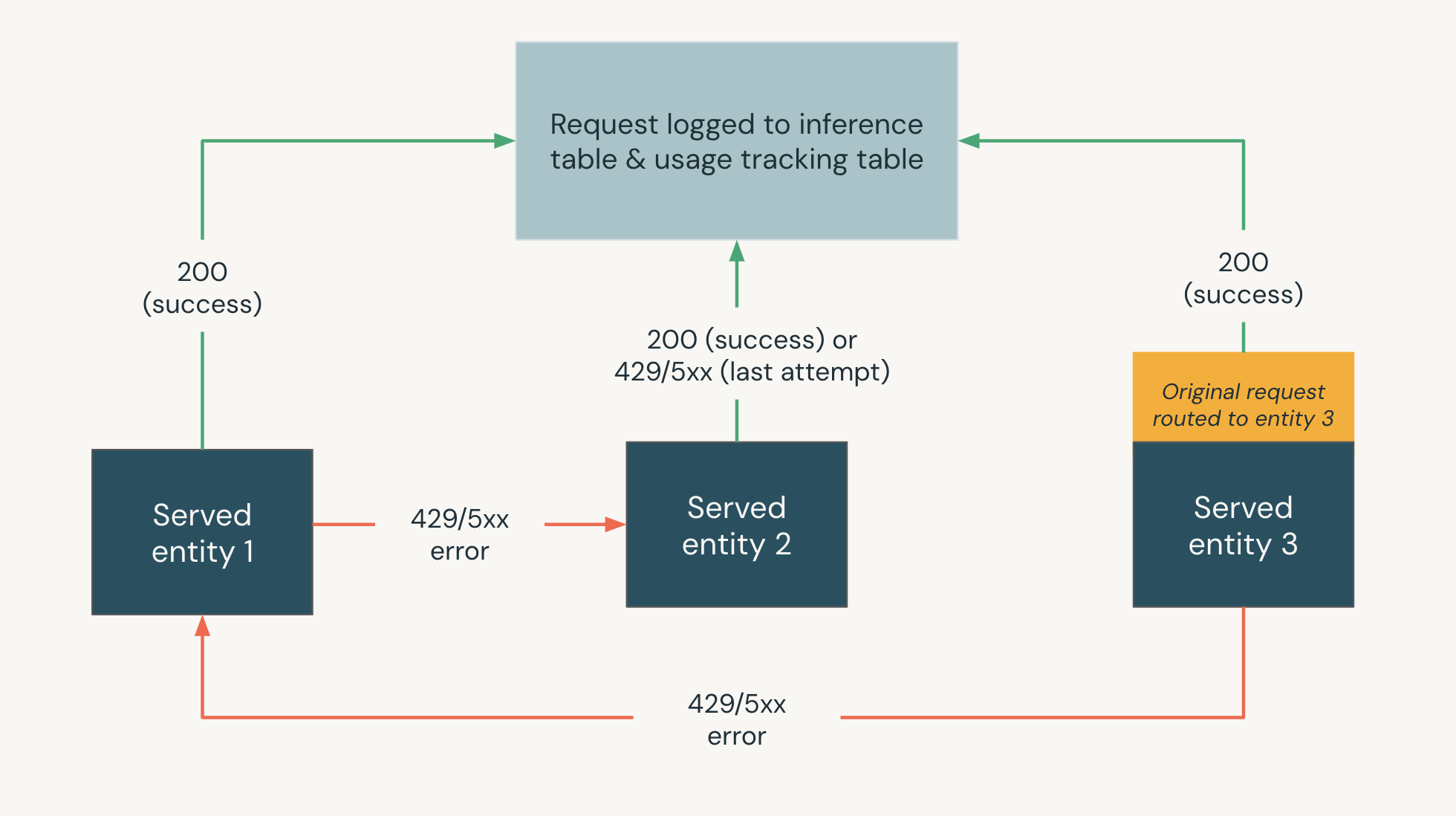
Le diagramme suivant montre un exemple de solutions de rechange où,
- Trois entités desservies sont desservies sur un point de terminaison de mise en service.
- La requête est routée à l’origine vers l’entité 3 du service.
- Si la requête retourne une réponse 200, la requête a réussi sur l’entité 3 servie et la demande et sa réponse sont enregistrées dans les tables de suivi de l’utilisation et de journalisation des charges utiles du point de terminaison.
- Si la requête retourne une erreur 429 ou 5xx sur l’entité 3 servie, la requête revient à l’entité servie suivante sur le point de terminaison, entité servie 1.
- Si la requête retourne une erreur 429 ou 5xx sur l’entité 1 servie, la requête revient à l’entité servie suivante sur le point de terminaison, entité servie 2.
- Si la requête retourne une erreur 429 ou 5xx sur l’entité 2 servie, la requête échoue, car il s’agit du nombre maximal d’entités de secours. La requête ayant échoué et l’erreur de réponse sont enregistrées dans les tables de suivi de l’utilisation et de journalisation de charge utile.
Configurer les garde-fous IA dans l'interface utilisateur
Importante
Cette fonctionnalité est disponible en préversion publique.
Le tableau suivant vous montre comment configurer les garde-fous pris en charge.
Remarque
Après le 30 mai 2025, la modération des rubriques et le filtrage de mots clés par les garde-fous d'IA ne sont plus pris en charge. Si ces fonctionnalités sont nécessaires pour vos flux de travail, contactez votre équipe de compte Databricks pour participer à la préversion privée des garde-fous personnalisés.
| Garde-fou | Comment activer |
|---|---|
| Sûreté | Sélectionnez Safety pour activer les garde-fous disponibles afin d'empêcher votre modèle d’interagir avec des contenus dangereux ou inappropriés. |
| Détection d’informations d’identification personnelle | Sélectionnez cette option pour bloquer ou masquer les données d’identification personnelle telles que les noms, les adresses, les numéros de carte de crédit si de telles informations sont détectées dans les demandes de point de terminaison et les réponses. Sinon, sélectionnez Aucun pour qu’aucune détection d’informations personnelles ne se produise. |

Schémas de table de suivi d’utilisation
Les sections suivantes résument les schémas des tables de suivi de l'utilisation pour les tables système system.serving.served_entities et system.serving.endpoint_usage.
system.serving.served_entities schéma de table de suivi de l’utilisation
Remarque
La table système de suivi de l’utilisation system.serving.served_entities n’est actuellement pas prise en charge pour les points de terminaison de paiement par jeton.
La table système de suivi d’utilisation system.serving.served_entities s'appuie sur le schéma suivant :
| Nom de la colonne | Descriptif | Type |
|---|---|---|
served_entity_id |
ID unique de l'entité servie. | STRING |
account_id |
ID de compte client pour le partage Delta. | STRING |
workspace_id |
ID d’espace de travail client du point de terminaison de service. | STRING |
created_by |
ID du créateur. | STRING |
endpoint_name |
Nom du point de terminaison de service. | STRING |
endpoint_id |
ID unique du point de terminaison de service. | STRING |
served_entity_name |
Nom de l’entité servie. | STRING |
entity_type |
Type de l’entité servie. Peut être FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL ou CUSTOM_MODEL. |
STRING |
entity_name |
Nom sous-jacent de l'entité. Différent de served_entity_name qui est un nom fourni par l’utilisateur. Par exemple, entity_name est le nom du modèle Unity Catalog. |
STRING |
entity_version |
Version de l’entité servie. | STRING |
endpoint_config_version |
Version de la configuration du point de terminaison. | INT |
task |
Type de tâche. Peut être llm/v1/chat, llm/v1/completions ou llm/v1/embeddings. |
STRING |
external_model_config |
Configurations pour les modèles externes. Exemple : {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Configurations pour les modèles de base. Exemple : {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Configurations pour les modèles personnalisés. Exemple :{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Configurations pour les spécifications de fonctionnalités. Exemple : { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Horodatage de la modification de l’entité servie. | timestamp |
endpoint_delete_time |
Horodatage de la suppression de l'entité. Le point de terminaison est le conteneur de l'entité servie. Une fois le point de terminaison supprimé, l’entité servie est également supprimée. | timestamp |
system.serving.endpoint_usage schéma de table de suivi de l’utilisation
La table système de suivi d’utilisation system.serving.endpoint_usage s'appuie sur le schéma suivant :
| Nom de la colonne | Descriptif | Type |
|---|---|---|
account_id |
ID du compte client. | STRING |
workspace_id |
ID d’espace de travail client du point de terminaison de service. | STRING |
client_request_id |
Identifiant de requête fourni par l'utilisateur, qui peut être spécifié dans le corps de la requête de service de modèle. Non pris en charge pour les requêtes supérieures à 4MiB. | STRING |
databricks_request_id |
Identifiant de requête généré par Azure Databricks attaché à toutes les requêtes de service de modèle. | STRING |
requester |
ID de l’utilisateur ou du principal de service dont les autorisations sont utilisées pour la requête d’appel du point de terminaison de service. | STRING |
status_code |
Code d’état HTTP retourné par le modèle. | INTEGER |
request_time |
Horodatage de réception de la requête. | timestamp |
input_token_count |
Nombre de jetons de l'entrée. | LONG |
output_token_count |
Nombre de jetons de la sortie. | LONG |
input_character_count |
Nombre de caractères de la chaîne ou du prompt d’entrée. | LONG |
output_character_count |
Nombre de caractères de la chaîne de sortie de la réponse. | LONG |
usage_context |
Mappage fourni par l'utilisateur contenant les identifiants de l'utilisateur final ou de l'application du client qui effectue l'appel vers le point d'extrémité. Voir Plus d’informations sur l’utilisation avec usage_context. Non pris en charge pour les requêtes supérieures à 4MiB. |
CARTE |
request_streaming |
Indique si la requête est en mode flux. | BOOLEAN |
served_entity_id |
ID unique utilisé pour joindre la table de dimension system.serving.served_entities afin de rechercher des informations sur le point de terminaison et l'entité servie. |
STRING |
Définir plus précisément l'utilisation avec usage_context
Lorsque vous interrogez un modèle externe avec le suivi de l’utilisation activé, vous pouvez fournir le paramètre usage_context avec le type Map[String, String]. Le mappage du contexte d'utilisation apparaît dans le tableau de suivi des utilisations dans la colonne usage_context. La taille du mappage usage_context ne peut pas dépasser 10 Kio.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Si vous utilisez le client Python OpenAI, vous pouvez le spécifier usage_context en l’incluant dans le extra_body paramètre.
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
Les administrateurs de compte peuvent agréger différentes lignes en fonction du contexte d’utilisation pour obtenir des aperçus et peuvent associer ceux-ci ces informations à celles de la table de journalisation de la charge utile. Par exemple, vous pouvez ajouter end_user_to_charge au usage_context pour suivre l'attribution des coûts aux utilisateurs finaux.
Surveiller l’utilisation du point de terminaison
Pour surveiller l’utilisation du point de terminaison, vous pouvez joindre les tables système et les tables d’inférence pour votre point de terminaison.
Joindre des tables système
Cet exemple s’applique uniquement aux points de terminaison des modèles externes et des flux de débit provisionné. La table système served_entities n’est pas prise en charge sur les points de terminaison de paiement par jeton, mais vous pouvez Joindre des tables d’inférence et d’utilisation pour obtenir des détails similaires.
Pour joindre les tables système endpoint_usage et served_entities, utilisez le SQL suivant :
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
Joindre des tables d’inférence et d’utilisation
Le code suivant réunit la endpoint_usage table du système et la table d’inférence pour un point de terminaison de type paiement par jeton. Les tables d’inférence et le suivi de l’utilisation doivent être activés sur le point de terminaison pour joindre ces tables.
SELECT * FROM system.serving.endpoint_usage AS endpoint_usage
JOIN
(SELECT DISTINCT(served_entity_id) AS fmapi_served_entity_id
FROM <inference table name>) fmapi_id
ON fmapi_id.fmapi_served_entity_id = endpoint_usage.served_entity_id;
Mettre à jour des fonctionnalités AI Gateway sur les points de terminaison
Vous pouvez mettre à jour les fonctionnalités AI Gateway sur les points de terminaison de service de modèle qui les avaient précédemment activées et sur ceux qui ne les avaient pas activées. Les mises à jour des configurations AI Gateway prennent de l'ordre de 20 à 40 secondes, mais les mises à jour de limitation de débit peuvent prendre jusqu’à 60 secondes.
La capture d'écran suivante vous montre comment mettre à jour les fonctionnalités AI Gateway sur un point de terminaison de service de modèle à l’aide de l’interface utilisateur de service.
Dans la section Gateway de la page du point de terminaison, vous pouvez voir quelles fonctionnalités sont activées. Pour mettre à jour ces fonctionnalités, cliquez sur Edit AI Gateway.

Exemple de notebook
Le notebook suivant vous montre comment programmer l'activation et l'utilisation des fonctionnalités Databricks Mosaic AI Gateway pour gérer et gouverner les modèles des fournisseurs. Pour plus d’informations sur l’API REST, consultez put /api/2.0/service-endpoints/{name}/ai-gateway .