Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Cet article explique comment bien démarrer avec Azure OpenAI Service dans IntelliJ IDEA. Il vous montre comment utiliser des modèles de chat tels que GPT-3.5-Turbo et GPT-4 pour tester et expérimenter avec différents paramètres et sources de données.
Conditions préalables
Kit de développement Java (JDK) pris en charge. Pour plus d’informations sur les JDK disponibles lors du développement sur Azure, consultez prise en charge de Java sur Azure et Azure Stack.
IntelliJ IDEA, Ultimate ou Community Edition.
Kit de ressources Azure pour IntelliJ. Pour plus d’informations, consultez Installer le kit de ressources Azure pour IntelliJ. Vous devez également vous connecter à votre compte Azure pour le Kit de ressources Azure pour IntelliJ. Pour plus d’informations, consultez les instructions de connexion pour le kit de ressources Azure pour IntelliJ.
Un abonnement Azure : créez-en un gratuitement.
Accès accordé à Azure OpenAI dans l’abonnement Azure souhaité.
L’accès à ce service n’est accordé qu’à l’application. Vous pouvez demander l’accès à Azure OpenAI en remplissant le formulaire à l’adresse Demander l’accès au service Azure OpenAI.
Une ressource Azure OpenAI Service avec les modèles
gpt-35-turboougpt-4déployés. Pour plus d’informations sur le déploiement de modèles, consultez Créer et déployer une ressource Azure OpenAI Service.
Installer et se connecter
Les étapes suivantes vous guident tout au long du processus de connexion Azure dans votre environnement de développement IntelliJ :
Si le plug-in n’est pas installé, consultez Le Kit de ressources Azure pour IntelliJ.
Pour vous connecter à votre compte Azure, accédez à la barre latérale gauche d’Azure Explorer , puis sélectionnez l’icône de connexion Azure . Vous pouvez également accéder à Outils, développer Azure, puis sélectionner Connexion Azure.
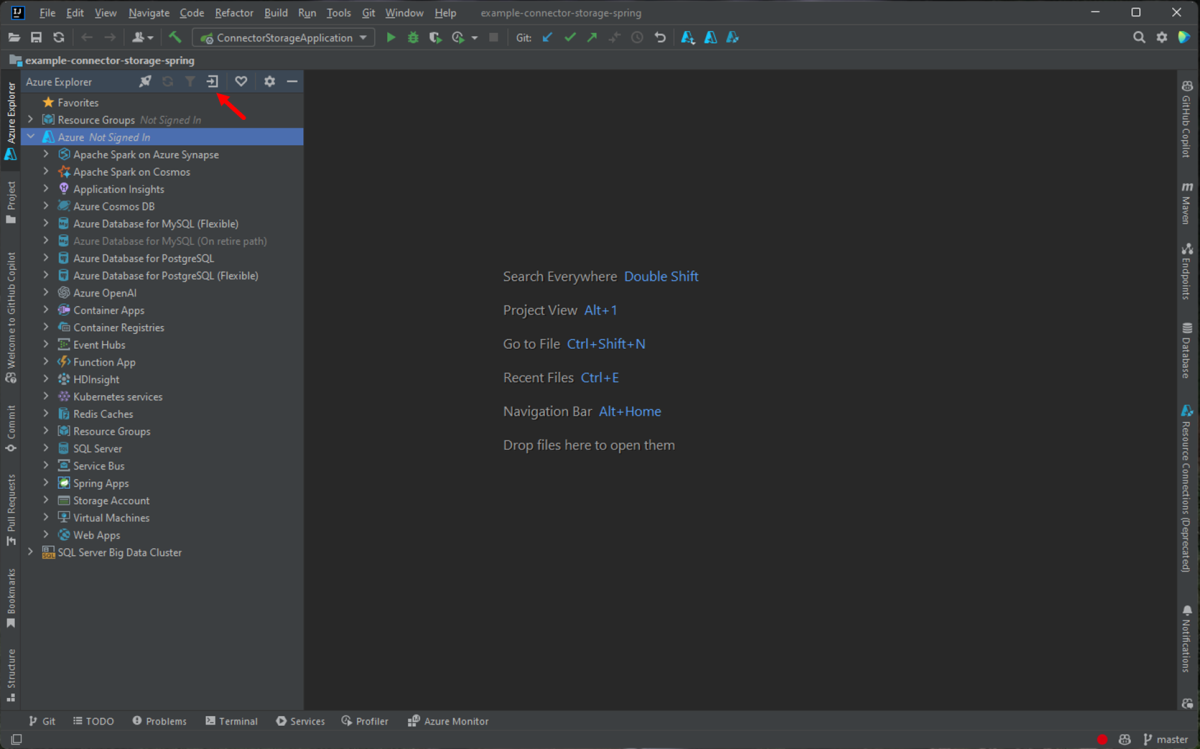
Dans la fenêtre Connexion à Azure qui s’affiche, sélectionnez OAuth 2.0, puis Se connecter. Pour d’autres options de connexion, consultez Instructions de connexion pour Azure Toolkit for IntelliJ.
Dans le navigateur, connectez-vous avec votre compte qui a accès à votre ressource OpenAI, puis revenez à IntelliJ. Dans la boîte de dialogue Sélectionner des abonnements , sélectionnez l’abonnement que vous souhaitez utiliser, puis sélectionnez Sélectionner.

Créer et déployer une ressource Azure OpenAI Service
Après le flux de travail de connexion, cliquez avec le bouton droit sur l’élément Azure OpenAI dans Azure Explorer, puis sélectionnez Créer un service Azure OpenAI.
Dans la boîte de dialogue Créer un service Azure OpenAI , spécifiez les informations suivantes, puis sélectionnez OK :
- Nom : nom descriptif de votre ressource Azure OpenAI Service, telle que MyOpenAIResource. Ce nom est également votre nom de domaine personnalisé dans votre point de terminaison. Votre nom de ressource ne peut inclure que des caractères alphanumériques et des traits d’union, et ne peut pas commencer ou se terminer par un trait d’union.
- Région : emplacement de votre instance. Certains modèles sont disponibles uniquement dans des régions spécifiques. Pour plus d’informations, consultez Modèles Azure OpenAI Service.
- SKU : Les ressources Azure OpenAI de type standard sont facturées en fonction de l’utilisation des jetons. Pour plus d’informations, consultez la tarification du service Azure OpenAI.
Avant de pouvoir utiliser les achèvements de conversation, vous devez déployer un modèle. Cliquez avec le bouton droit sur votre instance Azure OpenAI, puis sélectionnez Créer un nouveau déploiement. Dans la boîte de dialogue Créer un déploiement Azure OpenAI , spécifiez les informations suivantes, puis sélectionnez OK :
- Nom du déploiement : choisissez un nom soigneusement. Le nom du déploiement est utilisé dans votre code pour appeler le modèle en utilisant les bibliothèques clientes et les API REST.
- Modèle : sélectionnez un modèle. La disponibilité des modèles varie selon la région. Pour obtenir la liste des modèles disponibles par région, consultez la section Récapitulative du modèle et de la disponibilité des régions des modèles azure OpenAI Service.
Le kit de ressources affiche un message d’état lorsque le déploiement est terminé et prêt à être utilisé.
Interagir avec Azure OpenAI à l’aide d’invites et de paramètres
Cliquez avec le bouton droit sur votre ressource Azure OpenAI, puis sélectionnez Ouvrir dans AI Playground.
Vous pouvez commencer à explorer les fonctionnalités OpenAI via le terrain de jeu Azure OpenAI Studio Chat dans IntelliJ IDEA.
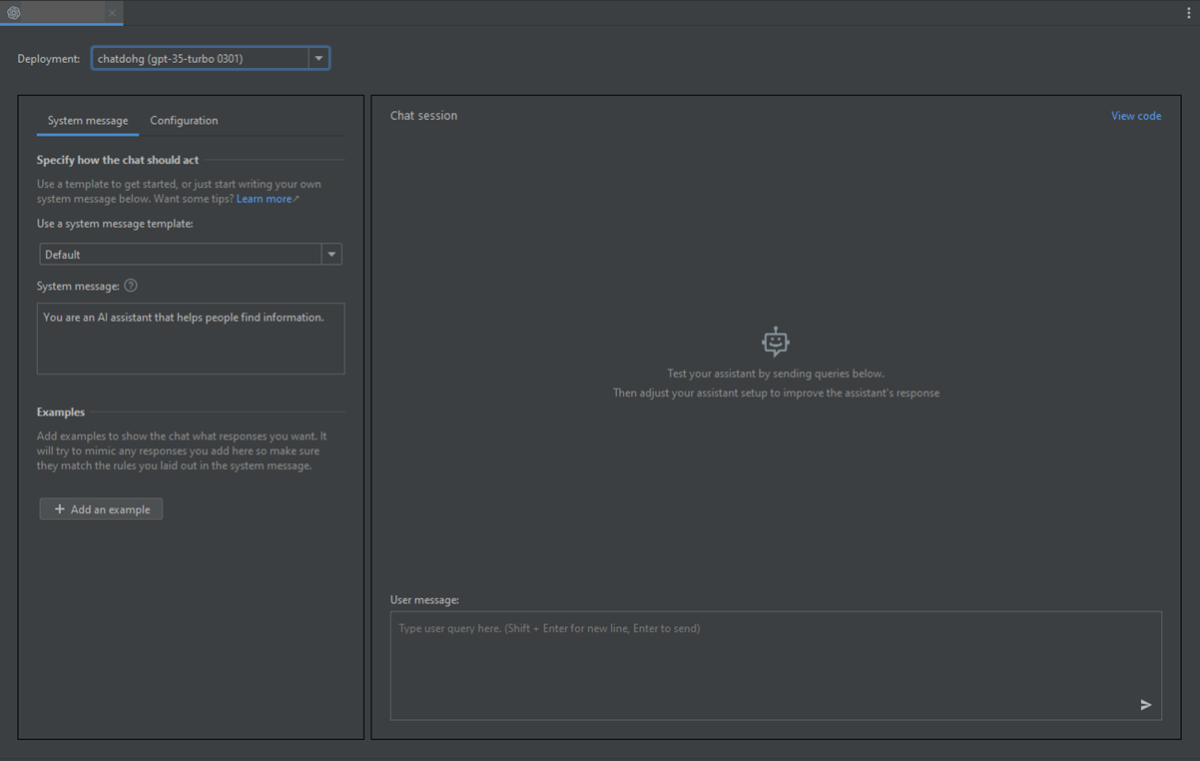

Pour déclencher la complétion, vous pouvez entrer du texte comme élément déclencheur. Le modèle génère la saisie semi-automatique et tente de compléter votre contexte ou modèle.
Pour démarrer une session de conversation, procédez comme suit :
Dans le volet de session de conversation, vous pouvez commencer par une simple invite comme celle-ci : « Je suis intéressé par l’achat d’une nouvelle Surface ». Après avoir tapé l’invite, sélectionnez Envoyer. Vous recevez une réponse similaire à l’exemple suivant :
Great! Which Surface model are you interested in? There are several options available such as the Surface Pro, Surface Laptop, Surface Book, Surface Go, and Surface Studio. Each one has its own unique features and specifications, so it's important to choose the one that best fits your needs.
Entrez une question de suivi, par exemple : « Quels modèles prennent en charge LE GPU », puis sélectionnez Envoyer. Vous recevez une réponse similaire à l’exemple suivant :
Most Surface models come with an integrated GPU (Graphics Processing Unit), which is sufficient for basic graphics tasks such as video playback and casual gaming. However, if you're looking for more powerful graphics performance, the Surface Book 3 and the Surface Studio 2 come with dedicated GPUs. The Surface Book 3 has an NVIDIA GeForce GTX GPU, while the Surface Studio 2 has an NVIDIA GeForce GTX 1060 or 1070 GPU, depending on the configuration.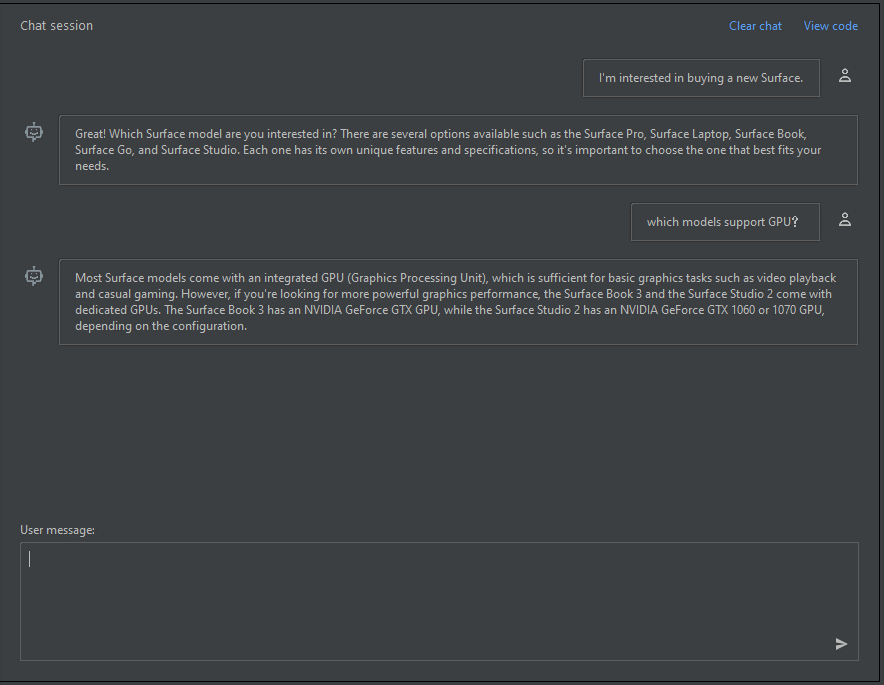
Maintenant que vous avez une conversation de base, sélectionnez Afficher le code dans le volet, et vous pouvez voir un aperçu du code derrière toute la conversation jusqu’à présent. Vous pouvez voir les exemples de code basés sur le Kit de développement logiciel (SDK) Java, curl et JSON correspondant à votre session de conversation et paramètres, comme illustré dans la capture d’écran suivante :
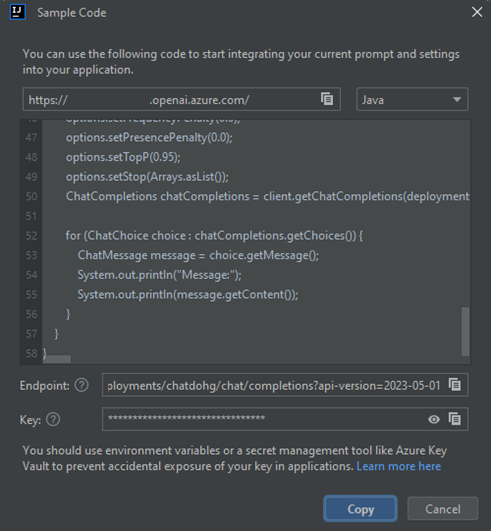
Vous pouvez ensuite sélectionner Copier pour prendre ce code et écrire une application pour effectuer la même tâche que celle que vous effectuez actuellement avec le terrain de jeu.



Paramètres
Vous pouvez sélectionner l’onglet Configuration pour définir les paramètres suivants :
| Nom | Descriptif |
|---|---|
| Réponse maximale | Définit une limite sur le nombre de jetons que le modèle peut générer. Le nombre total de jetons (invite + réponse) que vous pouvez envoyer dépend du modèle que vous déployez : • gpt-35-turbo-1106 / 0125 – jusqu’à 16 385 jetons • gpt-35-turbo-16k-0613 – jusqu’à 16 385 jetons • gpt-4-turbo-2024-04-09 – jusqu’à 128 000 jetons • gpt-4o-2024-05-13 – jusqu’à 128 000 jetons Pour obtenir la liste complète des limites de up-to-date, consultez la table récapitulative du modèle et disponibilité de la région. Assurez-vous toujours que la somme de votre prompt et du temps d’achèvement attendu s’inscrit dans la fenêtre contextuelle du modèle. |
| Température | Contrôle le caractère aléatoire. La réduction de la température signifie que le modèle produit des réponses plus répétitives et déterministes. L’augmentation de la température entraîne des réponses plus inattendues ou créatives. Essayez d’ajuster la température ou les probabilités principales, mais pas les deux. |
| Probabilités principales | Similaire à la température, contrôle l’aléatoire mais utilise une autre méthode. L’abaissement de la valeur de probabilité supérieure réduit la sélection de jetons du modèle aux jetons les plus probables. L’augmentation de la valeur permet au modèle de choisir parmi les jetons avec une probabilité élevée et faible. Essayez d’ajuster la température ou les probabilités principales, mais pas les deux. |
| Séquences d’arrêt | Met fin à la réponse du modèle à un point souhaité. La réponse du modèle se termine avant la séquence spécifiée, de sorte qu’elle ne contient pas le texte de séquence d’arrêt. Pour GPT-35-Turbo, l’utilisation de <|im_end|> garantit que la réponse du modèle ne génère pas de requête utilisateur de suivi. Vous pouvez inclure jusqu’à quatre séquences d’arrêt. |
| Pénalité de fréquence | Réduit le risque de répéter un jeton proportionnellement à la fréquence à laquelle il apparaît dans le texte jusqu’à présent. Cette action réduit la probabilité de répéter exactement le même texte dans une réponse. |
| Pénalité de présence | Réduit les risques de répétition d’un élément qui apparaît dans le texte à tout moment jusqu’à présent. Cela augmente la probabilité d’introduire de nouvelles rubriques dans une réponse. |
Nettoyer les ressources
Une fois que vous avez terminé de tester le terrain de jeu de conversation, si vous souhaitez nettoyer et supprimer une ressource OpenAI, vous pouvez supprimer la ressource ou le groupe de ressources. La suppression du groupe de ressources efface également les autres ressources qui y sont associées. Procédez comme suit pour nettoyer les ressources :
Pour supprimer vos ressources Azure OpenAI, accédez à la barre latérale d’Azure Explorer de gauche et recherchez l’élément Azure OpenAI .
Cliquez avec le bouton droit sur le service Azure OpenAI que vous souhaitez supprimer, puis sélectionnez Supprimer.
Pour supprimer votre groupe de ressources, visitez le portail Azure et supprimez manuellement les ressources sous votre abonnement.
Étapes suivantes
Pour plus d’informations, consultez Découvrez comment utiliser les modèles GPT-35-Turbo et GPT-4.
Pour plus d’exemples, consultez le dépôt GitHub d’exemples Azure OpenAI.