Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce guide de démarrage rapide, vous utilisez l’Assistant Importation et vectorisation des données dans le portail Azure pour commencer à effectuer une recherche modale. L’Assistant simplifie le processus d’extraction, de segmentation, de vectorisation et de chargement de texte et d’images dans un index pouvant faire l’objet d’une recherche.
Contrairement au démarrage rapide : Recherche vectorielle dans le portail Azure, qui traite des images contenant du texte simple, ce guide de démarrage rapide prend en charge le traitement avancé des images pour les scénarios RAG modals.
Ce démarrage rapide utilise un PDF multimodal à partir du dépôt azure-search-sample-data. Toutefois, vous pouvez utiliser différents fichiers et suivre ce guide de démarrage rapide.
Prérequis
Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Un service Recherche d’IA Azure. Nous vous recommandons le niveau Essentiel ou un niveau supérieur.
Un compte de stockage Azure. Utilisez le Stockage Blob Azure ou Azure Data Lake Storage Gen2 (compte de stockage avec un espace de noms hiérarchique), sur un compte de performances standard (v2 à usage général). Les niveaux d'accès peuvent être chauds, tièdes ou froids.
Connaissance de l’Assistant. Consultez Assistant Importation de données dans le portail Azure.
Méthodes d’extraction prises en charge
Pour l’extraction de contenu, vous pouvez choisir l’extraction par défaut par le biais d’Azure AI Search ou l’extraction améliorée via Azure AI Document Intelligence. Le tableau suivant décrit les deux méthodes d’extraction.
| Méthode | Descriptif |
|---|---|
| Extraction par défaut | Extrait les métadonnées d’emplacement des images PDF uniquement. Ne nécessite pas une autre ressource Azure AI. |
| Extraction améliorée | Extrait les métadonnées d’emplacement à partir de texte et d’images pour plusieurs types de documents. Nécessite une ressource multiservices des services Azure AI1 dans une région prise en charge. |
1 À des fins de facturation, vous devez attacher votre ressource multiservices Azure AI à l’ensemble de compétences de votre service Recherche d’IA Azure. Sauf si vous utilisez une connexion sans clé pour créer l’ensemble de compétences, les deux ressources doivent se trouver dans la même région.
Méthodes d'intégration prises en charge
Pour l’incorporation de contenu, vous pouvez choisir une verbalisation d’image (suivie de la vectorisation de texte) ou des incorporations modales. Les instructions de déploiement pour les modèles sont fournies dans une section ultérieure. Le tableau suivant décrit les deux méthodes d’incorporation.
| Méthode | Descriptif | Modèles pris en charge |
|---|---|---|
| Verbalisation de l’image | Utilise un LLM pour générer des descriptions en langage naturel d’images, puis utilise un modèle d’incorporation pour vectoriser du texte brut et des images verbalisées. Nécessite un projet Azure OpenAI resource1, 2 ou Azure AI Foundry. Pour la vectorisation de texte, vous pouvez également utiliser une ressource multiservices Azure AI services3 dans une région prise en charge. |
LLMs : GPT-4o GPT-4o-mini phi-4 4 Modèles d’incorporation : text-embedding-ada-002 (modèle de création d'embeddings textuels) intégration de texte - 3 - petit text-embedding-3-large |
| Intégrations multimodales | Utilise un modèle d’incorporation pour vectoriser directement le texte et les images. Nécessite un projet Azure AI Foundry ou une ressource multiservices Azure AI Services3 dans une région prise en charge. |
Cohere-embed-v3-english Cohere-embed-v3-multilingue |
1 Le point de terminaison de votre ressource Azure OpenAI doit avoir un sous-domaine personnalisé, tel que https://my-unique-name.openai.azure.com. Si vous avez créé votre ressource dans le portail Azure, ce sous-domaine a été généré automatiquement lors de la configuration de la ressource.
2 ressources Azure OpenAI (avec accès aux modèles incorporés) créées dans le portail Azure AI Foundry ne sont pas prises en charge. Vous devez créer une ressource Azure OpenAI dans le portail Azure.
3 À des fins de facturation, vous devez attacher votre ressource multiservices Azure AI à l’ensemble de compétences de votre service Recherche d’IA Azure. À moins que vous n'utilisiez une connexion sans clé (aperçu) pour créer l'ensemble de compétences, les deux ressources doivent se trouver dans la même région.
4phi-4 est disponible uniquement pour les projets Azure AI Foundry.
Exigences relatives aux points de terminaison publics
Toutes les ressources précédentes doivent disposer d’un accès public pour que les nœuds du Portail Azure puissent y accéder. Sinon, l’Assistant échoue. Une fois l’Assistant exécuté, vous pouvez activer des pare-feux et des points de terminaison privés sur les composants d’intégration à des fins de sécurité. Pour plus d’informations, consultez Connexions sécurisées dans les Assistants d’importation.
Si des points de terminaison privés sont déjà présents et que vous ne pouvez pas les désactiver, l’alternative consiste à exécuter le flux de bout en bout respectif à partir d’un script ou d’un programme sur une machine virtuelle. La machine virtuelle doit se trouver sur le même réseau virtuel que le point de terminaison privé. Voici un exemple de code Python pour la vectorisation intégrée. Le même dépôt GitHub contient des exemples dans d’autres langages de programmation.
Vérifier l’espace disponible
Si vous commencez avec le niveau gratuit, vous êtes limité à trois index, trois sources de données, trois ensembles de compétences et trois indexeurs. Avant de commencer, assurez-vous de disposer d’assez d’espace pour stocker des éléments supplémentaires. Ce guide de démarrage rapide crée une occurrence de chaque objet.
Configurer l’accès
Avant de commencer, vérifiez que vous disposez des autorisations nécessaires pour accéder au contenu et aux opérations. Nous recommandons l’authentification d’ID Microsoft Entra et l’accès en fonction du rôle pour l’autorisation. Vous devez être propriétaire ou administrateur de l’accès utilisateur pour attribuer des rôles. Si les rôles ne sont pas réalisables, vous pouvez utiliser l’authentification basée sur des clés à la place.
Configurez les rôles requis et les rôles conditionnels identifiés dans cette section.
Rôles requis
Recherche Azure AI et Stockage Azure sont requis pour tous les scénarios de recherche modale.
Recherche Azure AI fournit le pipeline multimodal. Configurez l’accès vous-même et votre service de recherche pour lire des données, exécuter le pipeline et interagir avec d’autres ressources Azure.
Sur votre service Recherche d’IA Azure :
Attribuez les rôles suivants à vous-même :
Contributeur du service de recherche
Contributeur de données d’index de la Recherche
Lecteur de données d’index de la Recherche
Rôles conditionnels
Les onglets suivants couvrent toutes les ressources compatibles avec l’assistant pour la recherche multimodale. Sélectionnez uniquement les onglets qui s’appliquent à votre méthode d’extraction choisie et à la méthode d’incorporation.
Azure OpenAI fournit des machines virtuelles LLMs pour la verbalisation d’images et l’incorporation de modèles pour la vectorisation de texte et d’image. Votre service de recherche nécessite un accès pour utiliser la compétence GenAI Prompt et la compétence Azure OpenAI Embedding.
Sur votre ressource Azure OpenAI :
- Attribuez un utilisateur OpenAI Cognitive Services à votre identité de service de recherche.
Préparer l’exemple de données
Ce guide de démarrage rapide utilise un exemple de pdf modal, mais vous pouvez également utiliser vos propres fichiers. Si vous utilisez un service de recherche gratuit, utilisez moins de 20 fichiers pour respecter le quota gratuit pour le traitement d'enrichissement.
Pour préparer les exemples de données pour ce guide de démarrage rapide :
Connectez-vous au portail Azure et sélectionnez votre compte stockage Azure.
Dans le volet gauche, sélectionnezstockage de données>Conteneurs.
Créez un conteneur, puis chargez l’exemple de fichier PDF dans le conteneur.
Créez un autre conteneur pour stocker des images extraites du fichier PDF.
Déployer des modèles
L'assistant propose plusieurs options pour l'intégration de contenu. La verbalisation des images nécessite un LLM pour décrire des images et un modèle d’incorporation pour vectoriser du texte et du contenu d’image, tandis que les incorporations modales directes nécessitent uniquement un modèle d’incorporation. Ces modèles sont disponibles via Azure OpenAI et Azure AI Foundry.
Remarque
Si vous utilisez Azure AI Vision, ignorez cette étape. Les incorporations modales sont intégrées à votre ressource multiservices Azure AI et ne nécessitent pas de déploiement de modèle.
Pour déployer les modèles pour ce guide de démarrage rapide :
Connectez-vous au portail Azure AI Foundry.
Sélectionnez votre ressource Azure OpenAI ou votre projet Azure AI Foundry.
Dans le volet gauche, sélectionnez Catalogue de modèles.
Déployez les modèles requis pour votre méthode d’incorporation choisie.
Démarrer l’Assistant
Pour démarrer l’Assistant pour la recherche modale :
Connectez-vous au portail Azure et sélectionnez votre service Recherche d’IA Azure.
Dans la page Vue d’ensemble, sélectionnez Importation et vectorisation des données.

Sélectionnez votre source de données : Stockage Blob Azure ou Azure Data Lake Storage Gen2.

Sélectionnez RAG multimodal.



Connexion à vos données
Azure AI Search nécessite une connexion à une source de données pour l’ingestion et l’indexation de contenu. Dans ce cas, la source de données est votre compte stockage Azure.
Pour vous connecter à vos données :
Dans la page Se connecter à vos données , spécifiez votre abonnement Azure.
Sélectionnez le compte de stockage et le conteneur dans lequel vous avez chargé les exemples de données.
Cochez la case Authentifier à l’aide de l’identité managée . Laissez le type d’identité tel que System-assigned.
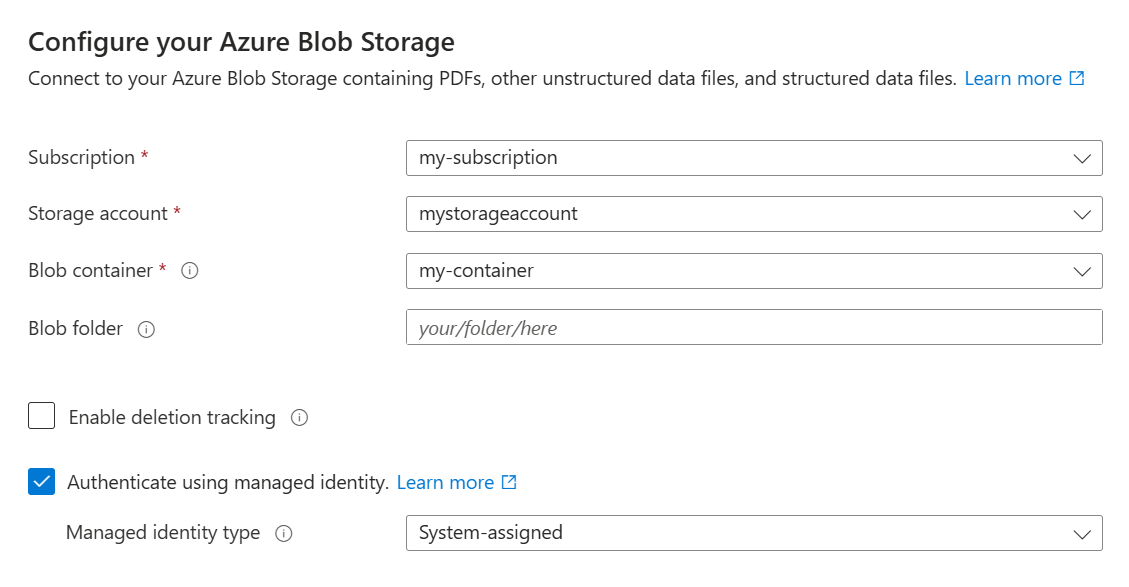
Cliquez sur Suivant.

Extraire votre contenu
En fonction de votre méthode d’extraction choisie, l’Assistant fournit des options de configuration pour le craquage et la segmentation de documents.
La méthode par défaut appelle la compétence Extraction de documents pour extraire du contenu texte et générer des images normalisées à partir de vos documents. La compétence de fractionnement de texte est ensuite appelée pour diviser le contenu du texte extrait en pages.
Pour utiliser la compétence Extraction de documents :
Dans la page d’extraction de contenu , sélectionnez Par défaut.
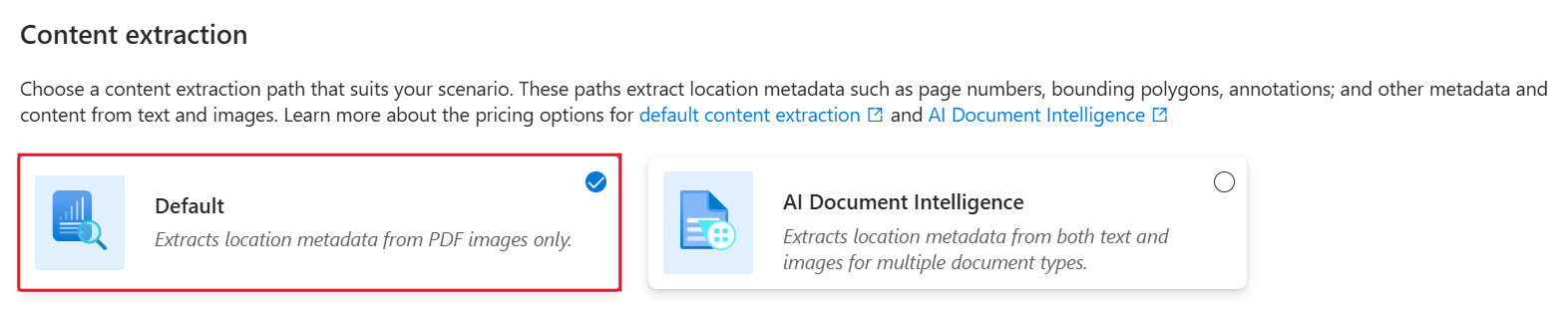
Cliquez sur Suivant.



Incorporer votre contenu
Au cours de cette étape, l’Assistant utilise votre méthode d’incorporation choisie pour générer des représentations vectorielles de texte et d’images.
L’assistant appelle une fonctionnalité pour créer un texte descriptif pour les images (verbalisation d'image) et une autre fonctionnalité pour créer des représentations vectorielles pour le texte et les images.
Pour la verbalisation d’image, la fonctionnalité Invite GenAI utilise le LLM déployé pour analyser chaque image extraite et produire une description en langage naturel.
Pour les incorporations, la compétence d’incorporation Azure OpenAI, la compétence AML ou les compétences d’incorporation modales Azure AI Vision utilisent votre modèle d’incorporation déployé pour convertir des blocs de texte et des descriptions verbales en vecteurs à haute dimension. Ces vecteurs permettent la similarité et la récupération hybride.
Pour utiliser les compétences pour la verbalisation d’image :
Dans la page d’incorporation de contenu , sélectionnez Verbalisation d’image.

Sous l’onglet Verbalisation de l’image :
Pour le type, sélectionnez votre fournisseur LLM : modèles de catalogue Azure OpenAI ou AI Foundry Hub.
Spécifiez votre abonnement, votre ressource et votre déploiement LLM Azure.
Pour le type d’authentification, sélectionnez Identité affectée par le système.
Cochez la case indiquant que vous avez connaissance des effets de l’utilisation de ces ressources sur la facturation.
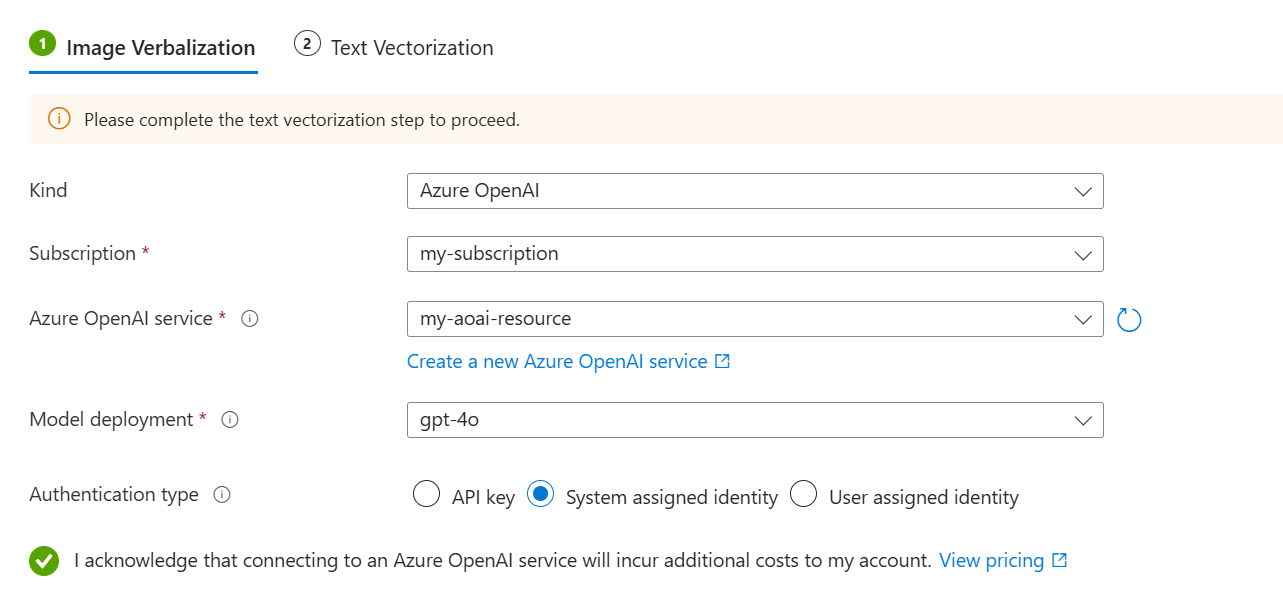
Sous l’onglet Vectorisation de texte :
Pour le type, sélectionnez votre fournisseur de modèles : Azure OpenAI, modèles catalogue AI Foundry Hub ou vectorisation AI Vision.
Spécifiez votre abonnement, votre ressource et votre déploiement de modèle d’incorporation Azure.
Pour le type d’authentification, sélectionnez Identité affectée par le système.
Cochez la case indiquant que vous avez connaissance des effets de l’utilisation de ces ressources sur la facturation.
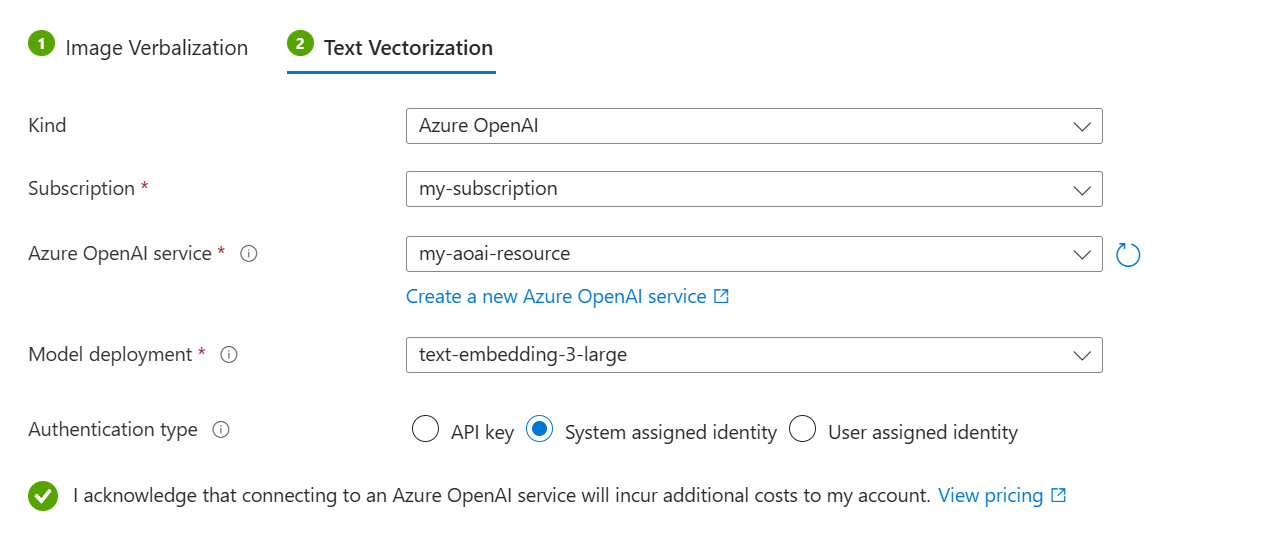
Cliquez sur Suivant.





Stocker les images extraites
L’étape suivante consiste à envoyer des images extraites de vos documents au stockage Azure. Dans Recherche IA Azure, ce stockage secondaire est connu sous le nom de base de connaissances.
Pour stocker les images extraites :
Dans la page de sortie d’image , spécifiez votre abonnement Azure.
Sélectionnez le compte de stockage et le conteneur d’objets blob que vous avez créés pour stocker les images.
Cochez la case Authentifier à l’aide de l’identité managée . Laissez le type d’identité tel que System-assigned.
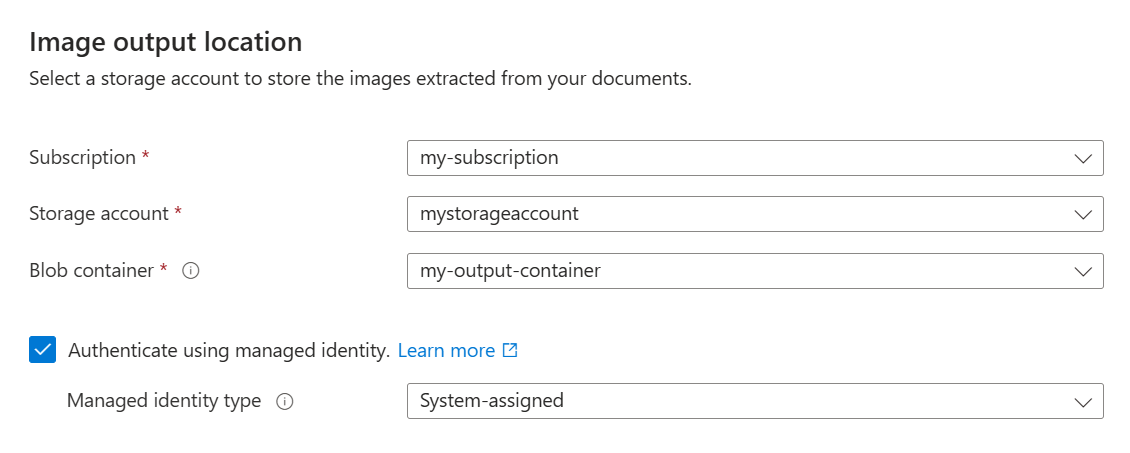
Cliquez sur Suivant.

Mapper de nouveaux champs
Dans la page Paramètres avancés , vous pouvez éventuellement ajouter des champs au schéma d’index. Par défaut, l’Assistant génère les champs décrits dans le tableau suivant.
| Champ | S’applique à | Descriptif | Attributs |
|---|---|---|---|
| content_id | Vecteurs texte et image | Champ de chaîne. Clé de document pour l’index. | Récupérable, triable et pouvant faire l’objet d’une recherche. |
| titre_de_document | Vecteurs texte et image | Champ de chaîne. Titre du document lisible par l’homme. | Récupérable et pouvant faire l’objet d’une recherche. |
| identifiant_du_document_texte | Vecteurs texte | Champ de chaîne. Identifie le document parent à partir duquel provient le bloc de texte. | Récupérable et filtrable. |
| image_document_id | Vecteurs image | Champ de chaîne. Identifie le document parent dont provient l’image. | Récupérable et filtrable. |
| content_text | Vecteurs texte | Champ de chaîne. Version lisible par l’homme du bloc de texte. | Récupérable et pouvant faire l’objet d’une recherche. |
| intégration_de_contenu | Vecteurs texte et image | Collection(Edm.Single). Représentation vectorielle du texte et des images. | Récupérable et pouvant faire l’objet d’une recherche. |
| chemin_du_contenu | Vecteurs texte et image | Champ de chaîne. Chemin d’accès au contenu dans le conteneur de stockage. | Récupérable et pouvant faire l’objet d’une recherche. |
| métadonnées de localisation | Vecteurs image | Edm.ComplexType. Contient des métadonnées sur l’emplacement de l’image dans les documents. | Varie selon le champ. |
Vous ne pouvez pas modifier les champs générés ou leurs attributs, mais vous pouvez ajouter des champs si votre source de données les fournit. Par exemple, Stockage Blob Azure fournit une collection de champs de métadonnées.
Pour ajouter des champs au schéma d’index :
Sous Champs Index, sélectionnez Aperçu et modification.
Cliquez sur Ajouter un champ.
Sélectionnez un champ source dans les champs disponibles, entrez un nom de champ pour l’index et acceptez (ou remplacez) le type de données par défaut.
Si vous souhaitez restaurer le schéma dans sa version d’origine, sélectionnez Réinitialiser.
Planifier l’indexation
Pour les sources de données où les données sous-jacentes sont volatiles, vous pouvez planifier l’indexation pour capturer les modifications à des intervalles spécifiques ou des dates et heures spécifiques.
Pour planifier l’indexation :
Dans la page Paramètres avancés , sous Planifier l’indexation, spécifiez une planification d’exécution pour l’indexeur. Nous vous recommandons Once pour ce démarrage rapide.

Cliquez sur Suivant.

Terminez l’Assistant.
La dernière étape consiste à passer en revue votre configuration et à créer les objets nécessaires à la recherche modale. Si nécessaire, revenez aux pages précédentes de l’Assistant pour ajuster votre configuration.
Pour terminer l’Assistant :
Dans la page Vérifier et créer , spécifiez un préfixe pour les objets que l’Assistant créera. Un préfixe courant vous aide à rester organisé.

Sélectionnez Créer.

Au terme de la configuration, l’Assistant crée les objets suivants :
Indexeur qui pilote le pipeline d’indexation.
Une connexion de source de données à Stockage Blob Azure.
Index avec des champs de texte, des champs vectoriels, des vectoriseurs, des profils vectoriels et des algorithmes vectoriels. Pendant le flux de travail de l’Assistant, vous ne pouvez pas modifier l’index par défaut. Les index sont conformes à l’API REST 2024-05-01-preview afin de pouvoir utiliser les fonctionnalités en préversion.
Ensemble de compétences avec les compétences suivantes :
La compétence Extraction de documents ou Disposition de documents extrait le texte et les images à partir des documents sources. La compétence Fractionnement de texte accompagne la compétence Extraction de documents pour la segmentation des données, tandis que la compétence Mise en page du document a une segmentation intégrée.
La fonctionnalité de génération d'invite AI verbalise les images en langage naturel. Si vous utilisez des embeddings multimodaux directs, cette capacité est absente.
La compétence d’incorporation Azure OpenAI, la compétence AML ou la compétence d’incorporation modale Azure AI Vision est appelée une fois pour la vectorisation de texte et une fois pour la vectorisation d’image.
La compétence Shaper enrichit la sortie avec des métadonnées et crée de nouvelles images avec des informations contextuelles.
Conseil / Astuce
Les objets créés par l’Assistant ont des définitions JSON configurables. Pour afficher ou modifier ces définitions, sélectionnez Gestion de la recherche dans le volet gauche, où vous pouvez afficher vos index, indexeurs, sources de données et ensembles de compétences.
Vérifier les résultats
Ce guide de démarrage rapide crée un index modal qui prend en charge la recherche hybride sur du texte et des images. Sauf si vous utilisez des incorporations modales directes, l’index n’accepte pas les images en tant qu’entrées de requête, ce qui nécessite la compétence AML ou la compétence d’incorporation modale Azure AI Vision avec un vectoriseur équivalent. Pour plus d’informations, consultez Configurer un vectoriseur dans un index de recherche.
La recherche hybride combine des requêtes de texte intégral et des requêtes vectorielles. Lorsque vous émettez une requête hybride, le moteur de recherche calcule la similarité sémantique entre votre requête et les vecteurs indexés et classe les résultats en conséquence. Pour l’index créé dans ce guide de démarrage, le contenu du champ content_text affiché dans les résultats s’aligne étroitement sur votre requête.
Pour interroger votre index modal :
Connectez-vous au portail Azure et sélectionnez votre service Recherche d’IA Azure.
Dans le volet gauche, sélectionnez Gestion de la recherche>Index.
Sélectionnez votre index.
Sélectionnez les options de requête, puis sélectionnez Masquer les valeurs vectorielles dans les résultats de recherche. Cette étape rend les résultats plus lisibles.
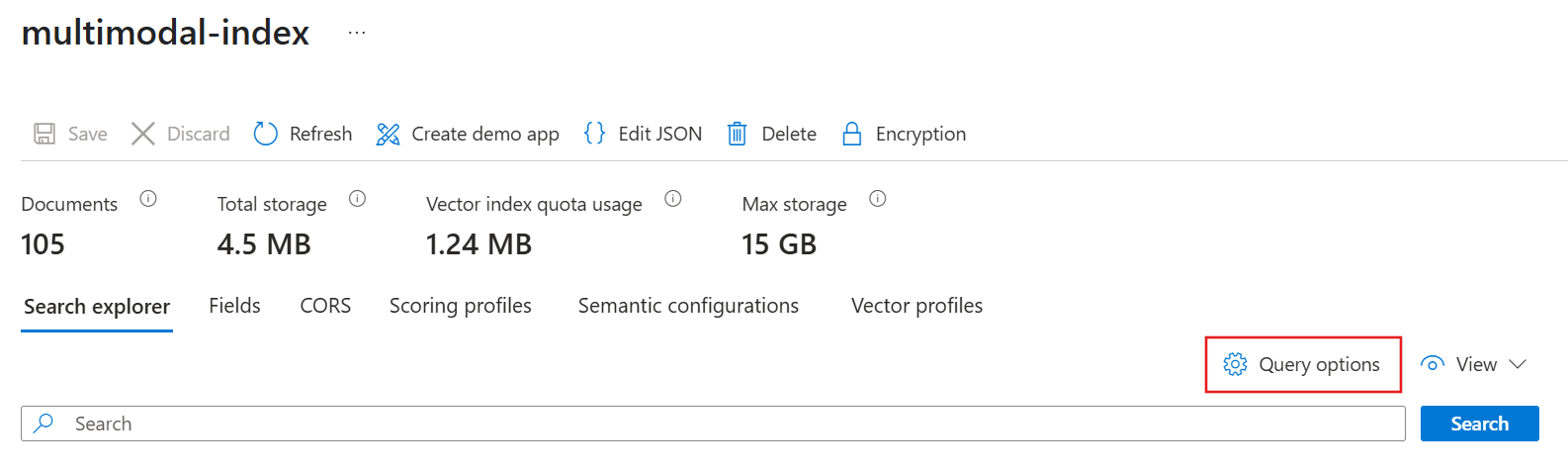
Entrez le texte pour lequel vous souhaitez effectuer une recherche. Notre exemple utilise
energy.Pour exécuter la requête, sélectionnez Rechercher.

Les résultats JSON doivent inclure du texte et du contenu d’image associé à
energydans votre index. Si vous avez activé le ranker sémantique, le@search.answerstableau fournit des réponses sémantiques concises et de haute confiance pour vous aider à identifier rapidement les correspondances pertinentes."@search.answers": [ { "key": "a71518188062_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_normalized_images_7", "text": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like energy distribution, resource allocation, and environmental monitoring. **Accelerate the development of sustainability solution...", "highlights": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like<em> energy distribution, </em>resource<em> allocation, </em>and environmental monitoring. **Accelerate the development of sustainability solution...", "score": 0.9950000047683716 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_5", "text": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim 10.5 gigawatts (GW) of renewable energy to the grid.910.5 GWof new renewable energy capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "highlights": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim <em> 10.5 gigawatts (GW) of renewable energy </em>to the<em> grid.910.5 </em>GWof new<em> renewable energy </em>capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "score": 0.9890000224113464 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_50", "text": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community Solar MicrogridsDeveloping energy transition programsWe are co-innovating with communities to develop energy transition programs that align their goals with broader s.", "highlights": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community<em> Solar MicrogridsDeveloping energy transition programsWe </em>are co-innovating with communities to develop<em> energy transition programs </em>that align their goals with broader s.", "score": 0.9869999885559082 } ]


Nettoyer les ressources
Ce guide de démarrage rapide utilise des ressources Azure facturables. Si vous n’avez plus besoin des ressources, supprimez-les de votre abonnement pour éviter les frais.
Étapes suivantes
Ce guide de démarrage rapide vous a présenté l’Assistant Importation et vectorisation des données , qui crée tous les objets nécessaires à la recherche modale. Pour explorer chaque étape en détail, consultez les didacticiels suivants :
- Tutoriel : Compétence de verbalisation d'images et d'extraction de documents
- Tutoriel : Compétence de verbalisation d’image et de mise en page de document
- Tutoriel : Représentations multimodales et compétence d’extraction de documents
- Tutoriel : Incorporations multimodales et capacité de mise en page de document