Stockage des données
Remarque
Le service Time Series Insights va être mis hors service le 7 juillet 2024. Prévoyez de migrer les environnements existants vers des solutions alternatives dès que possible. Pour plus d’informations sur la dépréciation et la migration, consultez notre documentation.
Cet article décrit le stockage des données dans Azure Time Series Insights Gen2. Il aborde le stockage à chaud et à froid, la disponibilité des données et les meilleures pratiques.
Approvisionnement
Lorsque vous créez un environnement Azure Time Series Insights Gen2, vous disposez des deux options suivantes :
- Stockage de données à froid :
- Créez une ressource de stockage Azure dans l’abonnement et la région que vous avez choisie pour votre environnement.
- Joignez un compte de stockage Azure existant. Cette option n’est disponible que si vous opérez un déploiement à partir d’un modèle Azure Resource Manager, et n’est pas visible dans le portail Azure.
- Stockage de données à chaud :
- Un magasin de stockage à chaud est facultatif et peut être activé ou désactivé pendant ou après l’exécution de l’approvisionnement. Si vous décidez d’activer le magasin de stockage à chaud ultérieurement et qu’il existe déjà des données dans votre magasin de stockage à froid, consultez cette section ci-dessous pour comprendre le comportement attendu. La durée de conservation des données du magasin de stockage à chaud peut être définie entre 7 et 31 jours, et peut être ajustée en fonction des besoins.
Lors de l’ingestion d’un événement, celui-ci est indexé tant dans le magasin de stockage à chaud (s’il est activé) et dans le magasin de stockage à froid.

Avertissement
En tant que propriétaire du compte de stockage Blob Azure où résident les données du magasin froid, vous avez un accès total à toutes les données du compte. Cet accès comprend des autorisations d’écriture et de suppression. Ne modifiez pas ni ne supprimez les données qu’Azure Time Series Insights Gen2 écrit, car cela peut entraîner une perte de données.
Disponibilité des données
Azure Time Series Insights Gen2 partitionne et indexe les données pour optimiser les performances des requêtes. Il est possible d’interroger les données après les avoir indexées à la fois depuis un magasin chaud (s’il est activé) et un magasin froid. La quantité de données ingérées et le débit par partition peuvent affecter la disponibilité. Pour obtenir des performances optimales, examinez les limites de débit de la source de l’événement et les meilleures pratiques. Vous pouvez également configurer une alerte de latence pour être notifié si votre environnement rencontre des problèmes de traitement des données.
Important
Il peut s’écouler jusqu’à 60 secondes avant que les données soient disponibles via les API Time Series Query. Si vous constatez une latence significative supérieure à 60 secondes, veuillez envoyer un ticket de support par le biais du Portail Azure.
Il peut s’écouler jusqu’à cinq minutes avant que les données soient disponibles lorsque vous accédez directement aux fichiers Parquet en dehors d’Azure Time Series Insights Gen2. Pour plus d’informations, consultez la section Format de fichier Parquet.
Magasin de stockage à chaud
Les données de votre magasin de stockage à chaud sont disponibles uniquement via les API Time Series Query, l’Explorateur Azure Time Series Insights TSI ou le Connecteur Power BI. Les requêtes de magasin de stockage à chaud sont gratuites et il n’y a pas de quota, mais il existe une limite de 30 requêtes simultanées.
Comportement du magasin de stockage à chaud
Lorsque cette option est activée, toutes les données diffusées dans votre environnement sont routées vers votre magasin de stockage à chaud, quel que soit l’horodateur de l’événement. Notez que le pipeline d’ingestion de diffusion en continu est conçu pour la diffusion en quasi temps réel et que l’ingestion d’événements historiques n’est pas prise en charge.
La période de rétention est calculée en fonction du moment où l’événement a été indexé dans le magasin de stockage à chaud, et non de l’horodateur de l’événement. Cela signifie que les données ne sont plus disponibles dans le magasin de stockage à chaud après l’expiration de la période de rétention, même si l’horodateur de l’événement est défini pour l’avenir.
- Exemple : un événement dont les prévisions météorologiques à 10 jours sont ingérées et indexées dans un conteneur de stockage à chaud configuré avec une période de rétention de 7 jours. Après sept jours, la prédiction n’est plus accessible dans le magasin de stockage à chaud, mais peut être interrogée à partir du magasin de stockage à froid.
Si vous activez le magasin de stockage à chaud sur un environnement existant qui contient déjà des données récentes indexées dans le stockage froid, notez que votre magasin de stockage à chaud ne sera pas rempli avec ces données.
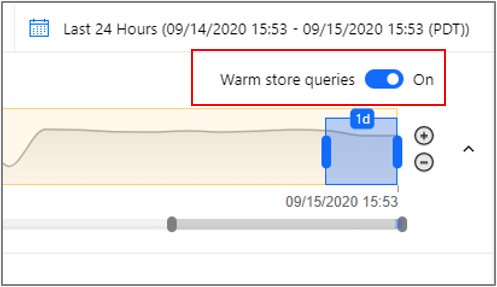
Si vous venez d’activer le magasin de stockage à chaud et que vous rencontrez des problèmes lors de l’affichage de vos données récentes dans l’Explorateur, vous pouvez désactiver temporairement les requêtes du magasin de stockage à chaud :

Magasin de stockage à froid
Cette section décrit les détails du stockage Azure relatifs à Azure Time Series Insights Gen2.
Pour obtenir une description complète du stockage Blob Azure, lisez l’introduction aux objets blob de stockage.
Votre compte de stockage à froid
Azure Time Series Insights Gen2 conserve jusqu’à deux copies de chaque événement dans votre compte Stockage Azure. Une copie stocke les événements classés par heure d’ingestion, autorisant toujours l’accès aux événements dans un ordre chronologique. Au fil du temps, Azure Time Series Insights Gen2 crée également une copie repartitionnée des données à optimiser pour des requêtes performantes.
Toutes vos données sont stockées indéfiniment dans votre compte de Stockage Azure.
Avertissement
Ne limitez pas l'accès Internet public au compte de stockage utilisé par Time Series Insights, sinon la connexion nécessaire sera interrompue.
Création et modification de d’objets blob
Pour garantir les performances des requêtes et la disponibilité des données, ne modifiez ni ne supprimez aucun objet blob créé par Azure Time Series Insights Gen2.
Accès aux données du magasin froid
En plus d’accéder à vos données à partir de l’Explorateur Time Series Insights et des API Time Series Query, vous pouvez également accéder à vos données directement à partir des fichiers Parquet stockés dans le magasin froid. Par exemple, vous pouvez lire, transformer et nettoyer les données d’un notebook Jupyter, puis les utiliser pour effectuer l’apprentissage de votre modèle Azure Machine Learning dans le même workflow Spark.
Pour accéder aux données directement à partir de votre compte Stockage Azure, vous avez besoin d’un accès en lecture au compte utilisé pour stocker vos données Azure Time Series Insights Gen2. Vous pouvez ensuite lire les données sélectionnées en fonction de l’heure de création du fichier Parquet situé dans le dossier PT=Time décrit ci-dessous dans la section Format de fichier Parquet. Pour plus d’informations sur l’activation de l’accès en lecture à votre compte de stockage, consultez Gérer l’accès aux ressources de votre compte de stockage.
Suppression de données
Ne supprimez pas vos fichiers Azure Time Series Insights Gen2. Gérez les données associées à partir d’Azure Time Series Insights Gen2 uniquement.
Format de fichier Parquet et structure de dossiers
Parquet est un format de fichier en colonnes open source qui a été conçu pour un stockage et des performances efficaces. Azure Time Series Insights Gen2 utilise Parquet pour permettre la performance des requêtes basées sur l’ID Time Series à grande échelle.
Pour plus d’informations sur le type de fichier Parquet, consultez la documentation relative au format Parquet.
Azure Time Series Insights Gen2 stocke des copies de vos données comme suit :
Le dossier
PT=Timeest partitionné par heure d’ingestion et stocke les données par ordre approximatif d’arrivée. Ces données sont conservées dans le temps et vous pouvez y accéder directement en dehors d’Azure Time Series Insight Gen2, par exemple à partir de vos notebooks Spark. Le timestamp<YYYYMMDDHHMMSSfff>correspond à l’heure d’ingestion des données.<MinEventTimeStamp>et<MaxEventTimeStamp>correspondent à la plage de timestamps d’événements inclus dans le fichier. Le chemin d’accès et le nom de fichier sont formatés comme suit :V=1/PT=Time/Y=<YYYY>/M=<MM>/<BlobCreationTimestamp>_<MinEventTimestamp>_<MaxEventTimestamp>_<TsiInternalSuffix>.parquetLes dossiers
PT=LiveetPT=Tsidcontiennent une seconde copie de vos données, repartitionnée pour des performances de requête de série chronologique à grande échelle. Ces données sont optimisées dans le temps et ne sont pas statiques. Pendant le repartitionnement, certains événements peuvent être présents dans plusieurs blobs et les noms des blobs peuvent changer. Ces dossiers sont utilisés par Azure Time Series Insights Gen2 et ne doivent pas être accessibles directement. Vous devez utiliserPT=Timeuniquement à cette fin.
Remarque
Les données du dossier PT=Time antérieures à juin 2021 peuvent avoir un format de nom de fichier sans intervalles de temps d’événement : V=1/PT=Time/Y=<YYYY>/M=<MM>/<BlobCreationTimestamp>_<TsiInternalSuffix>.parquet. Le format de fichier interne est le même, et les fichiers avec les deux schémas de dénomination peuvent être utilisés ensemble.
<YYYY>correspond à une représentation de l’année à quatre chiffres.<MM>correspond à une représentation du mois à deux chiffres.- Le format
<YYYYMMDDHHMMSSfff>des timestamps correspond à une année à quatre chiffres (YYYY), un mois à deux chiffres (MM), un jour à deux chiffres (DD), une heure à deux chiffres (HH), une minute à deux chiffres (MM), une seconde à deux chiffres (SS) et une milliseconde à trois chiffres (fff).
Les événements Azure Time Series Insights Gen2 sont mappés au contenu du fichier Parquet comme suit :
- Chaque événement correspond à une ligne unique.
- Chaque ligne comprend la colonne timestamp avec un horodatage de l’événement. La propriété timestamp n’est jamais nulle. Par défaut, elle a la valeur event enqueued time si la propriété timestamp n’est pas spécifiée dans la source de l’événement. L’horodatage stocké est toujours au format UTC.
- Chaque ligne comprend les colonnes ID Time Series (TSID) telles qu’elles sont définies lors de la création de l’environnement Azure Time Series Insights Gen2. Le nom de la propriété TSID comprend le suffixe
_string. - Toutes les autres propriétés envoyées en tant que données de télémétrie sont mappées à des noms de colonnes qui se terminent par
_bool(booléen),_datetime(horodatage),_long(long),_double(double),_string(chaîne) ou_dynamic(dynamique), en fonction du type de propriété. Pour en savoir plus, découvrez les types de données pris en charge. - Ce schéma de mappage s’applique à la première version du format de fichier, référencée V=1 et stockée dans le dossier de base du même nom. À mesure que cette fonctionnalité évolue, ce schéma de mappage est susceptible de changer et le nom de référence d’être incrémenté.
Étapes suivantes
En savoir plus sur la modélisation des données.
Planifier votre environnement Azure Time Series Insights Gen2.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour