Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des conseils aux créateurs de données et analyse qui gèrent leur contenu tout au long de son cycle de vie dans Microsoft Fabric. L’article décrit l’utilisation de l’intégration Git pour le contrôle de code source et des pipelines de déploiement comme outil de mise en production. Pour obtenir des conseils généraux sur la publication de contenu d’entreprise, consultez Publication de contenu d’entreprise.
Cet article est divisé en quatre sections :
Préparation du contenu : Préparez votre contenu pour la gestion du cycle de vie.
Développement : Découvrez les meilleures façons de créer du contenu dans l’étape de développement des pipelines de déploiement.
Test : Comprenez comment utiliser l’étape de test des pipelines de déploiement pour tester votre environnement.
Production : Utilisez l’étape de production des pipelines de déploiement lorsque vous rendez votre contenu disponible à la consommation.
Meilleures pratiques pour la préparation du contenu
Pour préparer au mieux votre contenu pour la gestion continue tout au long de son cycle de vie, passez en revue les informations de cette section avant de :
Publiez le contenu en production.
Commencez à utiliser un pipeline de déploiement pour un espace de travail spécifique.
Séparer le développement entre les équipes
Les différentes équipes de l’organisation ont généralement des compétences, des propriétés et des méthodes de travail différentes, même quand elles travaillent sur le même projet. Il est important de définir des limites tout en donnant à chaque équipe son indépendance pour travailler comme il le souhaite. Envisagez d’avoir des espaces de travail distincts pour différentes équipes. Avec des espaces de travail distincts, chaque équipe peut disposer d’autorisations différentes, travailler avec divers référentiels de contrôle de code source et expédier du contenu en production à une cadence différente. La plupart des éléments peuvent se connecter et utiliser des données dans tous les espaces de travail, de sorte qu’ils ne bloquent pas la collaboration sur les mêmes données et le même projet.
Planifier votre modèle d’autorisation
L’intégration Git et les pipelines de déploiement nécessitent des autorisations différentes de celles de l’espace de travail. En savoir plus sur les exigences d’autorisation pour l’intégration Git et les pipelines de déploiement.
Pour implémenter un workflow sécurisé et facile, planifiez qui a accès à chaque partie des environnements utilisés, à la fois au dépôt Git et aux phases dev/test/prod dans un pipeline. Quelques éléments à prendre en compte :
Qui doit avoir accès au code source dans le dépôt Git ?
Quelles opérations les utilisateurs avec accès au pipeline peuvent-ils effectuer à chaque étape ?
Qui examine le contenu au cours de l’étape de test ?
Les réviseurs de l’étape de test doivent-ils avoir accès au pipeline ?
Qui devrait surveiller le déploiement à l’étape de production ?
Quel espace de travail attribuez-vous à un pipeline ou se connectant à Git ?
À quelle branche connectez-vous l’espace de travail ? Quelle est la stratégie définie pour cette branche ?
L’espace de travail est-il partagé par plusieurs membres de l’équipe ? Doivent-ils apporter des modifications directement dans l’espace de travail, ou uniquement par le biais de demandes de tirage ?
À quelle étape affectez-vous votre espace de travail ?
Avez-vous besoin d’apporter des modifications aux autorisations d’espace de travail que vous attribuez ?
Connecter différentes étapes à différentes bases de données
Une base de données de production doit toujours être stable et disponible. Il est préférable de ne pas la surcharger avec les requêtes générées par les créateurs BI pour leurs modèles sémantiques de développement ou de test. Créez des bases de données distinctes pour le développement et le test afin de protéger les données de production, et ne surchargez pas la base de données de développement avec l’intégralité du volume de données de production.
Utiliser des paramètres pour les configurations qui changent d’une phase à l’autre
Dans la mesure du possible, ajoutez des paramètres à n’importe quelle définition susceptible de changer entre les phases dev/test/prod. L’utilisation de paramètres vous permet de modifier facilement les définitions lorsque vous déplacez vos modifications en production.
Les paramètres ont des utilisations différentes, telles que la définition de connexions à des sources de données ou à des éléments internes dans Fabric. Ils peuvent également être utilisés pour apporter des modifications aux requêtes, aux filtres et au texte affiché aux utilisateurs.
Dans les pipelines de déploiement, vous pouvez configurer des règles de paramètre pour définir des valeurs différentes pour chaque étape de déploiement.
Meilleures pratiques pour l’étape de développement des pipelines de déploiement
Cette section fournit des conseils pour travailler avec les pipelines de déploiement et les utiliser pour votre stade de développement.
Sauvegarder votre travail dans un dépôt Git
Avec l’intégration Git, les développeurs peuvent sauvegarder leur travail en le commitant dans Git. Sauvegardez correctement votre travail dans Fabric. Voici quelques règles de base :
Assurez-vous que vous disposez d’un environnement isolé pour que les autres ne remplacent pas votre travail avant sa validation. Cela signifie utiliser un outil de bureau (comme VS Code, Power BI Desktop ou autre) ou un espace de travail distinct auquel les autres utilisateurs ne peuvent pas accéder.
Validez dans une branche que vous avez créée et qu’aucun autre développeur n’utilise. Si vous utilisez un espace de travail comme environnement de création, découvrez comment utiliser des branches.
Validez ensemble les modifications qui doivent être déployées ensemble. Ce conseil s’applique à un seul élément ou à plusieurs éléments liés à la même modification. La validation de toutes les modifications associées peut vous aider ultérieurement lors du déploiement vers d’autres phases, de la création de demandes de tirage ou de la restauration des modifications.
Les validations volumineuses peuvent atteindre une limite de taille de validation maximale. Gardez à l’esprit le nombre d’éléments que vous validez ensemble ou la taille générale d’un élément. Par exemple, les rapports peuvent devenir volumineux lors de l’ajout d’images volumineuses. Il est déconseillé de stocker des éléments de grande taille dans des systèmes de contrôle de code source, même si cela fonctionne. Envisagez des moyens de réduire la taille de vos éléments s’ils ont beaucoup de ressources statiques, comme des images.
Restauration des changements
Après la sauvegarde de votre travail, il peut arriver que vous souhaitiez revenir à une version précédente et la restaurer dans l’espace de travail. Il existe plusieurs façons de rétablir une version antérieure :
Bouton Annuler : l’opération Annuler est un moyen simple et rapide de rétablir les modifications immédiates que vous avez apportées, tant qu’elles ne sont pas encore validées. Vous pouvez également annuler chaque élément séparément. En savoir plus sur l’opération d’annulation.
Rétablissement des validations plus anciennes : il n’existe aucun moyen direct de revenir à un commit précédent dans l’interface utilisateur. La meilleure option consiste à promouvoir un commit plus ancien pour qu’il soit le HEAD à l’aide de git revert ou git reset. Cela montre qu’il existe une mise à jour dans le volet de contrôle de code source et que vous pouvez mettre à jour l’espace de travail avec cette nouvelle validation.
Étant donné que les données ne sont pas stockées dans Git, notez que le rétablissement d’un élément de données à une version antérieure peut arrêter les données existantes et éventuellement nécessiter votre suppression des données pour éviter l’échec de l’opération. Vérifiez cela à l’avance avant de rétablir les modifications.
Utilisation d’un espace de travail « privé »
Lorsque vous souhaitez travailler de manière isolée, utilisez un espace de travail distinct en tant qu’environnement isolé. Lisez plus d’informations sur l’isolation de votre environnement de travail dans Utilisation des branches. Pour obtenir un flux de travail optimal pour vous et l’équipe, tenez compte des éléments suivants :
Configuration de l’espace de travail : avant de commencer, assurez-vous que vous pouvez créer un espace de travail (si vous n’en avez pas encore), que vous pouvez l’affecter à une capacité Fabric et que vous avez accès aux données pour travailler dans votre espace de travail.
Création d’une branche : créez une branche à partir de la branche primaire afin de disposer de la version la plus récente de votre contenu. Veillez également à vous connecter au dossier approprié dans la branche, afin de pouvoir extraire le contenu approprié dans l’espace de travail.
Petits changements fréquents : la bonne pratique est de faire des petits changements incrémentiels faciles à fusionner et moins susceptibles d’entraîner des conflits. Si ce n’est pas possible, veillez à mettre à jour votre branche à partir de la primaire afin de pouvoir d’abord résoudre les conflits par vous-même.
Modifications de configuration : si nécessaire, modifiez les configurations de votre espace de travail pour vous aider à travailler de manière plus productive. Certaines modifications peuvent inclure une connexion entre des éléments, ou à différentes sources de données ou des modifications de paramètres sur un élément donné. N’oubliez pas que tout ce que vous validez devient partie intégrante de la validation et peut être accidentellement fusionné dans la branche primaire.
Utiliser les outils clients pour modifier votre travail
Pour les éléments et les outils qui le prennent en charge, il peut être plus facile d’utiliser des outils clients pour la création, comme Power BI Desktop pour les rapports et les modèles sémantiques, VS Code pour les notebooks, etc. Ces outils peuvent être votre environnement de développement local. Une fois votre travail terminé, envoyez les modifications dans le dépôt distant et synchronisez l’espace de travail pour charger les modifications. Vérifiez simplement que vous utilisez la structure prise en charge de l’élément que vous créez. Si vous n’êtes pas sûr, clonez d’abord un dépôt avec du contenu déjà synchronisé avec un espace de travail, puis commencez à créer à partir de là, où la structure est déjà en place.
Gestion des espaces de travail et des branches
Étant donné qu’un espace de travail ne peut être connecté qu’à une seule branche à la fois, nous vous recommandons de traiter cela comme un mappage 1:1. Toutefois, pour réduire la quantité d’espace de travail qu’elle implique, envisagez les options suivantes :
Si un développeur configure un espace de travail privé avec toutes les configurations requises, il peut continuer à utiliser cet espace de travail pour n’importe quelle branche future qu’il créera. Quand un sprint est terminé, vos modifications sont fusionnées et vous démarrez une nouvelle tâche. Il vous suffit de basculer la connexion vers une nouvelle branche sur le même espace de travail. Vous pouvez également le faire si vous avez soudainement besoin de corriger un bogue au milieu d’un sprint. Considérez-le comme un répertoire de travail sur le web.
Les développeurs qui utilisent un outil client (comme VS Code, Power BI Desktop ou autre) n’ont pas nécessairement besoin d’un espace de travail. Ils peuvent créer des branches et valider les modifications apportées à cette branche localement, les pousser vers le dépôt distant et créer une demande de tirage vers la branche main, le tout sans espace de travail. Un espace de travail est nécessaire uniquement en tant qu’environnement de test pour vérifier que tout fonctionne dans un scénario réel. C’est à vous de décider quand cela devrait se produire.
Dupliquer un élément dans un dépôt Git
Pour dupliquer un élément dans un dépôt Git :
- Copiez l’intégralité du répertoire de l’élément.
- Remplacez le logicalId par une valeur unique pour cet espace de travail connecté.
- Changez le nom d’affichage pour le différencier de l’élément d’origine et éviter l’erreur de nom d’affichage en double.
- Si nécessaire, mettez à jour le logicalId et/ou les noms d’affichage dans toutes les dépendances.
Meilleures pratiques pour l’étape de test des pipelines de déploiement
Cette section fournit des conseils pour travailler avec une étape de développement des pipelines de test.
Simuler votre environnement de production
Il est important de voir comment votre modification proposée aura un impact sur la phase de production. Une phase de test des pipelines de déploiement vous permet de simuler un environnement de production réel à des fins de test. Vous pouvez également simuler cela en connectant Git à un espace de travail supplémentaire.
Assurez-vous que ces trois facteurs sont traités dans votre environnement de test :
Volume de données
Volume d’utilisation
Une capacité similaire à celle de la production
Lors du test, vous pouvez utiliser la même capacité que l’étape de production. Toutefois, l’utilisation de la même capacité peut rendre la production instable pendant le test de charge. Pour éviter une production instable, utilisez une autre capacité similaire aux ressources de la capacité de production. Pour éviter les coûts supplémentaires, utilisez une capacité permettant de payer uniquement pour la durée du test.
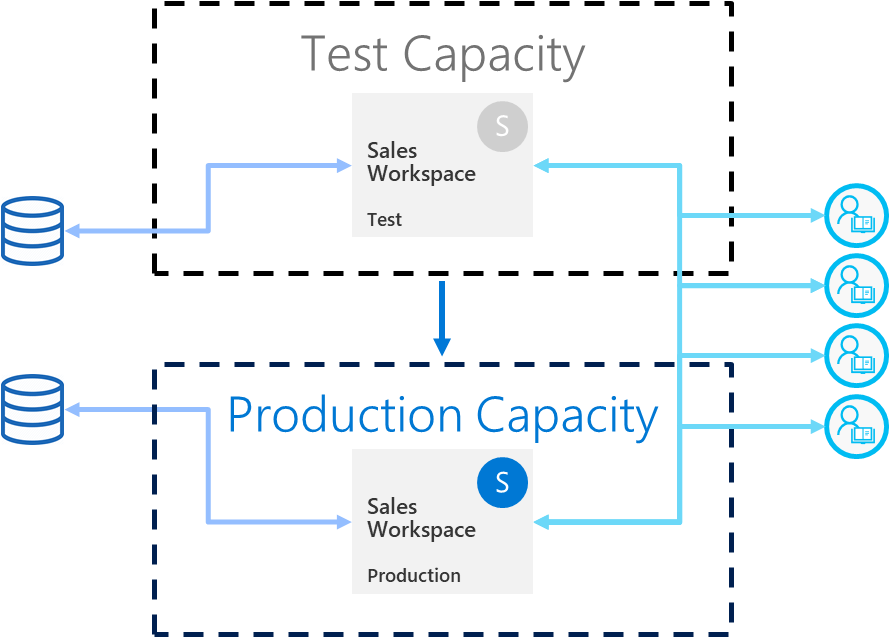
Utiliser des règles de déploiement avec une source de données réelle
Si vous utilisez la phase de test to simuler une utilisation de données réelles, il est conseillé de séparer le développement et les source de données de test. La base de données de développement doit être relativement petite, et la base de données de test doit être aussi similaire que possible à la base de données de production. Utilisez des règles de source de données pour basculer des sources de données dans la phase de test ou paramétrer la connexion si vous ne fonctionnez pas via des pipelines de déploiement.
Vérifier les éléments connexes
Les modifications que vous apportez peuvent également affecter les éléments dépendants. Pendant le test, vérifiez que vos modifications n’affectent pas ou n’interrompent pas les performances des éléments existants, qui peuvent dépendre des éléments mis à jour.
Vous pouvez facilement trouver les éléments liés en utilisant l'analyse d'impact.
Mettre à jour des données
Les éléments de données sont des éléments qui stockent des données. La définition de l’élément dans Git définit la façon dont les données sont stockées. Lors de la mise à jour d’un élément dans l’espace de travail, nous importons sa définition dans l’espace de travail et l’appliquons aux données existantes. L’opération de mise à jour des éléments de données est la même pour Git et les pipelines de déploiement.
Étant donné que différents éléments ont des fonctionnalités différentes lorsqu’il s’agit de conserver des données lorsque des modifications apportées à la définition sont appliquées, soyez attentif lors de l’application des modifications. Voici quelques pratiques qui peuvent vous aider à appliquer les modifications de la manière la plus sûre :
Sachez à l’avance ce que sont les modifications et leur impact sur les données existantes. Utilisez des messages de validation pour décrire les modifications apportées.
Pour voir comment cet élément gère la modification avec des données test, chargez les modifications en premier dans un environnement de test ou de développement.
Si tout se passe bien, il est recommandé de le vérifier également dans un environnement d'essai, avec des données réelles (ou aussi proches que possible), afin de minimiser les comportements inattendus en production.
Tenez compte du meilleur moment lors de la mise à jour de l’environnement Prod pour réduire les dommages que les erreurs peuvent causer aux utilisateurs de votre entreprise qui consomment les données.
Après le déploiement, les tests post-déploiement dans Prod pour vérifier que tout fonctionne comme prévu.
Certaines modifications seront toujours considérées comme des changements cassants. Nous espérons que les étapes précédentes vous aideront à les suivre avant la production. Créez un plan pour appliquer les modifications dans Prod et récupérer les données pour revenir à l’état normal et réduire les temps d’arrêt pour les utilisateurs professionnels.
Test de l'application
Si vous distribuez du contenu à vos clients par le biais d’une application, passez en revue la nouvelle version de l’application avant qu’elle ne soit en production. Comme chaque étape du pipeline de déploiement a son propre espace de travail, vous pouvez facilement publier et mettre à jour des applications à des stades de développement et de test. La publication et la mise à jour d’applications vous permettent de tester l’application du point de vue d’un utilisateur final.
Important
Le processus de déploiement n’inclut pas la mise à jour du contenu ou des paramètres de l’application. Pour appliquer les modifications apportées au contenu ou aux paramètres, mettez à jour manuellement l’application dans l’étape de pipeline requise.
Meilleures pratiques pour l’étape de production des pipelines de déploiement
Cette section fournit des conseils pour l’étape de production des pipelines de déploiement.
Gérer les utilisateurs autorisés à déployer en production
Puisque le déploiement en production doit être géré avec précaution, il est conseillé d’autoriser uniquement des personnes spécifiques à gérer cette opération sensible. Toutefois, vous souhaitez probablement que tous les créateurs BI pour un espace de travail spécifique aient accès au pipeline. Utilisez les autorisations d’espace de travail de production pour gérer les autorisations d’accès. Les autres utilisateurs peuvent avoir un rôle de viewer sur l’espace de travail de production pour voir le contenu de l’espace de travail sans toutefois pouvoir faire des changements à partir de Git ou des pipelines de déploiement.
En outre, limitez l'accès à la base de données ou au pipeline en n'accordant des autorisations qu'aux utilisateurs qui participent au processus de création de contenu.
Définir des règles pour garantir la disponibilité de l’étape de production
Les règles de déploiement constituent un moyen efficace pour garantir que les données en production soient toujours connectées et disponibles pour les utilisateurs. Grâce aux règles de déploiement appliquées, les déploiements peuvent s'effectuer tout en garantissant que les clients peuvent consulter les informations pertinentes sans perturbation.
Veillez à définir des règles de déploiement de production pour les sources de données et les paramètres définis dans le modèle sémantique.
Mettre à jour l’application de production
Le déploiement dans un pipeline via l’IU met à jour le contenu de l’espace de travail. Pour mettre à jour l’appli associée, utilisez l’API de pipelines de déploiement. Il n’est pas possible de mettre à jour l’application via l’interface utilisateur. Si vous utilisez une application pour la distribution de contenu, n’oubliez pas de mettre à jour l’application après le déploiement en production, afin que les utilisateurs finaux puissent immédiatement utiliser la version la plus récente.
Déploiement en production en utilisant des branches Git
Comme le dépôt sert de « source unique de vérité », certaines équipes peuvent souhaiter déployer des mises à jour dans différentes phases directement à partir de Git. Cela est possible avec l’intégration Git, en tenant compte de certains points :
Nous vous recommandons d’utiliser les branches de mise en production. Vous devez modifier en permanence la connexion de l’espace de travail aux nouvelles branches de mise en production avant chaque déploiement.
Si votre pipeline de build ou de mise en production vous oblige à changer le code source ou à exécuter des scripts dans un environnement de build avant le déploiement sur l’espace de travail, la connexion de l’espace de travail à Git n’est pas utile.
Après le déploiement sur chaque étape, veillez à modifier toute la configuration spécifique à cette étape.
Correctifs rapides pour le contenu
Parfois, il existe des problèmes en production qui nécessitent une solution rapide. Le déploiement d’un correctif sans le tester d’abord est une mauvaise pratique. Par conséquent, implémentez toujours le correctif dans l’étape de développement et transmettez-le au reste des étapes du pipeline de déploiement. Le déploiement en phase de développement vous permet de vérifier que le correctif fonctionne avant de le déployer en production. Le déploiement à travers le pipeline ne prend que quelques minutes.
Si vous utilisez un déploiement à partir de Git, nous vous recommandons de suivre les pratiques décrites dans Adopter une stratégie de branches Git.