Processus des pipelines de déploiement
Le processus de déploiement vous permet de cloner le contenu d’une étape de pipeline de déploiement vers une autre, en général du développement au test et du test à la production.
Pendant le déploiement, Microsoft Fabric copie le contenu de l’étape actuelle vers le contenu cible. Les connexions entre les éléments copiés sont conservées lors du processus de copie. Fabric applique également les règles de déploiement configurées au contenu mis à jour à la phase cible. Le déploiement du contenu peut prendre un certain temps, en fonction du nombre d’éléments déployés. Pendant ce temps, vous pouvez accéder à d’autres pages dans le portail, mais vous ne pouvez pas utiliser le contenu dans l’étape cible.
Vous pouvez aussi déployer du contenu programmatiquement, en utilisant les API REST des pipelines de déploiement. Pour plus d’informations sur ce processus, consultez Automatiser votre pipeline de déploiement en utilisant des API et DevOps.
Déployer du contenu dans une étape vide
Quand vous déployez du contenu dans une étape vide, un espace de travail est créé sur une capacité pour l’étape sur laquelle vous effectuez le déploiement. Toutes les métadonnées contenues dans les rapports, les tableaux de bord et les modèles sémantiques de l’espace de travail d’origine sont copiées dans le nouvel espace de travail à l’étape vers laquelle vous effectuez le déploiement.
Il existe plusieurs façons de déployer le contenu d’une étape à l’autre. Vous pouvez déployer tout le contenu, ou vous pouvez sélectionner les éléments à déployer.
Vous pouvez également déployer le contenu vers l’arrière, d’une étape ultérieure du pipeline de déploiement vers une ancienne.
Après le déploiement, actualisez les modèles sémantiques pour pouvoir utiliser le nouveau contenu copié. L’actualisation des modèles sémantiques est nécessaire, car les données ne sont pas copiées d’une étape à l’autre. Pour savoir quelles propriétés d’élément sont copiées pendant le processus de déploiement et quelles propriétés ne le sont pas, consultez la section Propriétés d’élément copiées lors du déploiement.
Créer un espace de travail
Lors du premier déploiement de contenu, les pipelines de déploiement vérifient si vous disposez d’autorisations.
Si vous disposez d’autorisations, le contenu de l’espace de travail est copié à la phase vers laquelle vous effectuez le déploiement et un espace de travail pour cette phase est créé sur la capacité.
Si vous n’avez pas d’autorisations, l’espace de travail est créé, mais le contenu n’est pas copié. Vous pouvez demander à un administrateur de capacité d’ajouter votre espace de travail à une capacité ou demander l’attribution d’autorisations pour la capacité. Plus tard, lorsque l’espace de travail est affecté à une capacité, vous pouvez déployer le contenu dans cet espace de travail.
Si vous utilisez Premium par utilisateur (PPU), votre espace de travail est automatiquement créé dans la capacité associée à votre PPU. Dans ce cas, les autorisations ne sont pas nécessaires. Toutefois, si vous créez un espace de travail avec une PPU, seuls les autres utilisateurs de la PPU peuvent y accéder. En outre, seuls les utilisateurs de l’UPP peuvent consommer le contenu créé dans ces espaces de travail.
L’utilisateur qui effectue le déploiement devient automatiquement le propriétaire des modèles sémantiques clonés et le seul administrateur du nouvel espace de travail.
Déployer du contenu dans un espace de travail existant
Le déploiement de contenu depuis un pipeline de production en cours d’utilisation, sur une étape disposant d’un espace de travail existant, inclut les éléments suivants :
Déploiement d’un nouveau contenu en tant qu’ajout au contenu déjà présent.
Déploiement de contenu mis à jour pour remplacer une partie du contenu déjà présent.
Processus de déploiement
Quand le contenu de l’étape actuelle est copié vers l’étape cible, Fabric identifie le contenu existant dans la phase cible et le remplace. Pour identifier l’élément de contenu qui doit être remplacé, les pipelines de déploiement utilisent la connexion entre l’élément parent et ses clones. Cette connexion est conservée lors de la création de nouveau contenu. L’opération de remplacement remplace uniquement le contenu de l’élément. L’ID, l’URL et les autorisations de l’élément restent inchangés.
Dans l’étape cible, les propriétés d’élément qui ne sont pas copiées restent telles qu’elles étaient avant le déploiement. Le nouveau contenu et les nouveaux éléments sont copiés de l’étape actuelle à l’étape cible.
Liaison automatique
Dans Fabric, quand des éléments sont connectés, un des éléments dépend de l’autre. Par exemple, un rapport dépend toujours du modèle sémantique auquel il est connecté. Un modèle sémantique peut dépendre d’un autre modèle sémantique et peut également être connecté à plusieurs rapports qui en dépendent. S’il existe une connexion entre deux éléments, les pipelines de déploiement essaient toujours de conserver cette connexion.
Lors du déploiement, les pipelines de déploiement vérifient les dépendances. Le déploiement réussit ou échoue en fonction de l’emplacement de l’élément qui fournit les données dont l’élément déployé dépend.
L’élément lié existe dans la phase cible : les pipelines de déploiement connectent automatiquement (liaison automatique) l’élément déployé à l’élément dont il dépend dans la phase déployée. Par exemple, si vous déployez un rapport paginé de l’étape de développement vers l’étape de test et que le rapport est connecté à un modèle sémantique ayant précédemment été déployé dans l’étape de test, il se connecte automatiquement à ce modèle sémantique.
L’élément lié n’existe pas dans la phase cible : le déploiement des pipelines de déploiement échouent si un élément a une dépendance vis-à-vis d’un autre élément, et que l’élément qui fournit les données n’est pas déployé et ne se trouve pas dans la phase cible. Par exemple, si vous déployez un rapport de l’étape de développement vers l’étape de test et que l’étape de test ne contient pas son modèle sémantique, le déploiement échoue. Pour éviter les échecs de déploiement dus à des éléments dépendants qui n’ont pas été déployés, utilisez le bouton Sélectionner les éléments connexes. Sélectionner les éléments connexes sélectionne automatiquement tous les éléments associés qui fournissent des dépendances aux éléments que vous allez déployer.
La liaison automatique fonctionne uniquement avec les articles qui sont pris en charge par les pipelines de déploiement et qui se trouvent dans Fabric. Pour visualiser les dépendances d’un élément, dans le menu Plus d’options de l’élément, sélectionnez Afficher la traçabilité.
Liaison automatique entre les pipelines
Les pipelines de déploiement lient automatiquement les éléments qui sont connectés entre les pipelines s’ils sont dans la même phase de pipeline. Quand vous déployez ces éléments, les pipelines de déploiement tentent d’établir une nouvelle connexion entre l’élément déployé et l’élément auquel il est connecté dans l’autre pipeline. Par exemple, si vous avez un rapport dans l’étape de test du pipeline A qui est connecté à un modèle sémantique dans l’étape de test du pipeline B, les pipelines de déploiement reconnaissent cette connexion.
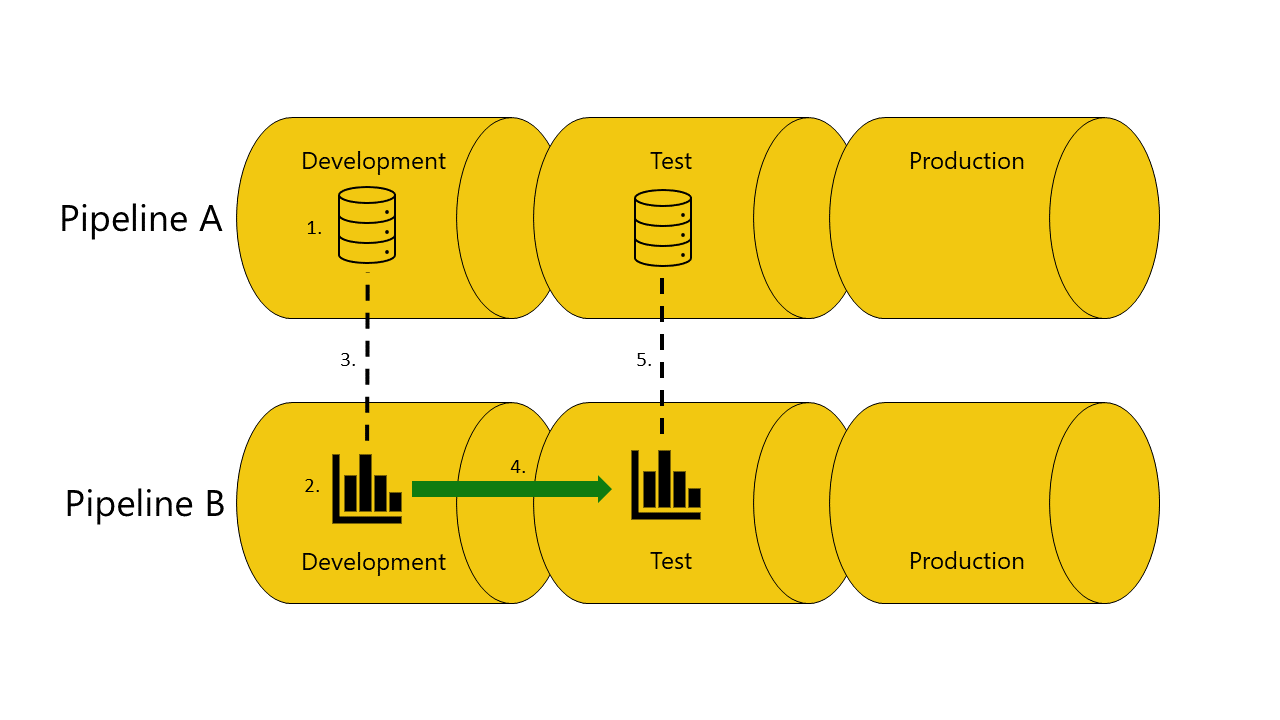
Voici un exemple avec des illustrations qui montrent le fonctionnement de la liaison automatique entre des pipelines :
Vous avez un modèle sémantique dans l’étape de développement du pipeline A.
Vous avez aussi un rapport dans l’étape de développement du pipeline B.
Votre rapport dans le pipeline B est connecté à votre modèle sémantique dans le pipeline A. Votre rapport dépend de ce modèle sémantique.
Vous déployez le rapport dans le pipeline B de la phase de développement à la phase de test.
Le déploiement réussit ou échoue, selon que vous disposez ou non d’une copie du modèle sémantique dont le rapport dépend dans l’étape de test du pipeline A :
Si vous avez une copie du modèle sémantique, le rapport en dépend dans l’étape de test du pipeline A :
Le déploiement réussit et les pipelines de déploiement connectent (lient automatiquement) le rapport de l'aperçu de test du pipeline B au modèle sémantique de l'aperçu de test du pipeline A.
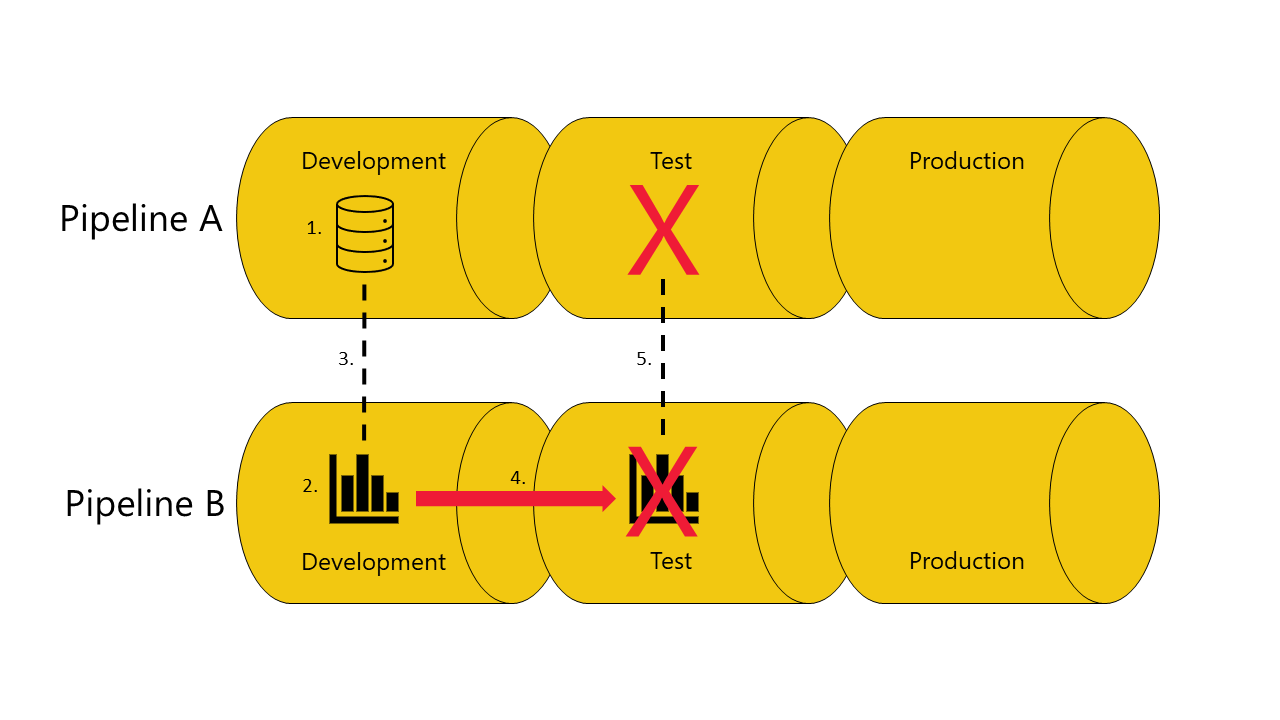
Si vous n’avez pas de copie du modèle sémantique, le rapport en dépend dans la phase de test du pipeline A :
Le déploiement échoue, car les pipelines de déploiement ne peuvent pas connecter (lier automatiquement) le rapport de l'aperçu de test du pipeline B au modèle sémantique de l'aperçu de test du pipeline A.
Éviter d'utiliser la liaison automatique
Dans certains cas, vous ne souhaitez pas utiliser la liaison automatique. Par exemple, vous utilisez un pipeline pour développer des modèles sémantiques organisationnels et un autre pour créer des rapports. Dans ce cas, vous pouvez souhaiter que tous les rapports soient toujours connectés aux modèles sémantiques dans la phase de production du pipeline auquel ils appartiennent. Pour cela, évitez d’utiliser la fonctionnalité de liaison automatique.
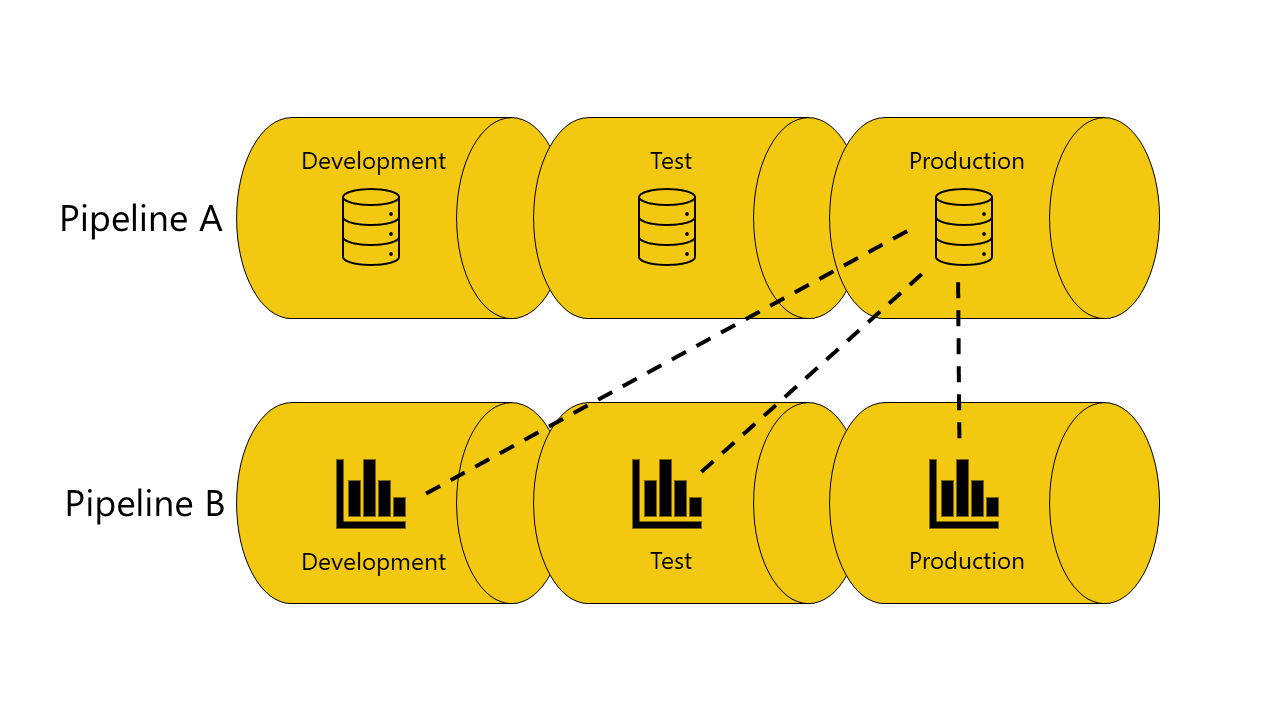
Trois méthodes vous permettent d'éviter d'utiliser la liaison automatique :
Ne pas connecter l’élément aux phases correspondantes. Quand les éléments ne sont pas connectés dans la même phase, les pipelines de déploiement conservent la connexion d’origine. Par exemple, vous avez un rapport dans l’étape de développement du pipeline B qui est connecté à un modèle sémantique dans l’étape de production du pipeline A. Lorsque vous déployez le rapport vers l’étape de test du pipeline B, il reste connecté au modèle sémantique dans l’étape de production du pipeline A.
Définir une règle de paramètre. Cette option n’est pas disponible pour les rapports. Vous ne pouvez l’utiliser qu’avec des modèles sémantiques et des flux de données.
Connectez vos rapports, tableaux de bord et vignettes à un flux de données ou modèle sémantique proxy qui n’est pas connecté à un pipeline.
Liaison automatique et paramètres
Les paramètres peuvent être utilisés pour contrôler les connexions entre les modèles sémantiques ou flux de données et les éléments dont ils dépendent. Quand un paramètre contrôle la connexion, la liaison automatique après le déploiement n’a pas lieu, même quand la connexion comprend un paramètre qui s’applique à l’ID du modèle sémantique ou du flux de données, ou à l’ID de l’espace de travail. Dans ce cas, vous devrez relier les éléments après le déploiement en modifiant la valeur du paramètre ou en utilisant des règles de paramètre.
Notes
Si vous utilisez des règles de paramètre pour relier des éléments, les paramètres doivent être de type Text.
Actualisation des données
Dans la mesure du possible, les données de l’élément cible, comme un modèle sémantique ou un flux de données, sont conservées. Si aucune modification n’est apportée à un élément, les données sont conservées telles qu’elles étaient avant le déploiement.
Dans de nombreux cas, quand vous avez une petite modification, comme l’ajout ou la suppression d’une table, Fabric conserve les données d’origine. Pour les modifications de schéma cassants ou les modifications apportées à la connexion de source de données, une actualisation complète est requise.
Conditions requises pour le déploiement sur une étape avec un espace de travail existant
Un utilisateur disposant d’une licence contributeur des espaces de travail de déploiement cible et source peut déployer du contenu qui se trouve sur une capacité vers une phase avec un espace de travail existant. Pour plus d'informations, consultez la section Autorisations.
Dossiers dans les pipelines de déploiement (aperçu)
Les dossiers permettent aux utilisateurs d’organiser et de gérer efficacement les éléments de l’espace de travail d’une manière familière. Lorsque vous déployez un contenu contenant des dossiers vers une étape différente, la hiérarchie des dossiers des éléments appliqués est automatiquement appliquée.
Représentation des dossiers
Puisqu’un déploiement ne concerne que des éléments, le contenu de l’espace de travail est affiché dans les pipelines de déploiement sous la forme d’une liste plate d’éléments. Le chemin complet d’un élément est affiché lorsque vous survolez son nom dans la liste. Dans les pipelines de déploiement, les dossiers sont considérés comme faisant partie du nom d’un élément (le nom d’un élément inclut son chemin complet). Lorsqu’un élément est déployé, après que son chemin a été modifié (déplacé du dossier A au dossier B, par exemple), les pipelines de déploiement appliquent cette modification à son élément associé pendant le déploiement. L’élément associé sera également déplacé vers le dossier B. Si le dossier B n’existe pas dans l’étape vers laquelle nous effectuons le déploiement, il sera d’abord créé dans l’espace de travail de l’étape. Les dossiers ne peuvent être vus et gérés que sur la page de l’espace de travail.
Identifier les éléments qui ont été déplacés vers d’autres dossiers
Puisque les dossiers sont considérés comme faisant partie du nom de l’élément, les éléments déplacés dans un dossier différent dans l’espace de travail sont identifiés sur la page Pipelines de déploiement comme Différents en mode Comparer. En outre, à moins qu'il n'y ait également une modification du schéma, l'option près de l'étiquette permettant d'ouvrir une fenêtre Examen des modifications, qui présente les modifications de schéma, est désactivée. En survolant cette option, vous verrez apparaître une note indiquant qu’il s’agit d’une modification de paramètres (ex : renommer). Cette désactivation est due au fait que la modification n'a pas encore été déployée par rapport aux articles qui lui sont associés dans l'aperçu source.
Les dossiers individuels ne peuvent pas être déployés manuellement dans les pipelines de déploiement. Leur déploiement est déclenché automatiquement lorsque au moins un de leurs éléments est déployé.
La hiérarchie des dossiers des éléments associés n’est mise à jour que pendant le déploiement. Lors de l’affectation, après le processus d’association, la hiérarchie des éléments appariés n’est pas encore mise à jour.
Étant donné qu’un dossier n’est déployé que si l’un de ses éléments est déployé, un dossier vide ne peut pas être déployé.
Le déploiement d'un article parmi plusieurs dans un dossier met également à jour la structure des articles qui ne sont pas déployés à l'aperçu cible, même si les articles eux-mêmes ne sont pas déployés.
Propriétés de l’élément copiées lors du déploiement
Pour obtenir la liste des éléments pris en charge, consultez Éléments pris en charge par les pipelines de déploiement.
Pendant le déploiement, les propriétés d’élément suivantes sont copiées et remplacent les propriétés de l’élément à l’étape cible :
Sources de données (les règles de déploiement sont prises en charge)
Paramètres (les règles de déploiement sont prises en charge)
Visuels de rapport
Pages d’un rapport
Vignettes de tableau de bord
Métadonnées du modèle
Relations d’élément
Les étiquettes de confidentialité sont copiées uniquement quand l’une des conditions suivantes est remplie. Si ces conditions ne sont pas remplies, les étiquettes de confidentialité ne sont pas copiées lors du déploiement.
Un nouvel élément est déployé, ou un élément existant est déployé sur une scène vide.
Remarque
Dans les cas où l’étiquetage par défaut est activé sur le locataire et où l’étiquette par défaut est valide, si l’élément déployé est un modèle sémantique ou un flux de données, l’étiquette est copiée de l’élément source uniquement si l’étiquette a une protection. Si l’étiquette n’est pas protégée, l’étiquette par défaut est appliquée au nouveau modèle sémantique ou flux de données cible.
L’élément source a une étiquette avec protection et l’élément cible n’en a pas. Dans ce cas, une fenêtre contextuelle vous demande de consentir au remplacement de l’étiquette de confidentialité cible.
Propriétés d’élément qui ne sont pas copiées
Les propriétés d’élément suivantes ne sont pas copiées lors du déploiement :
Données : les données ne sont pas copiées, seules les métadonnées le sont
URL
ID
Autorisations : pour un espace de travail ou un élément spécifique
Paramètres de l’espace de travail : chaque étape a son propre espace de travail
Contenu et paramètres des applications - Pour mettre à jour vos applications, consultez Mettre à jour du contenu vers dans applications Power BI
Les propriétés de modèle sémantique suivantes ne sont pas non plus copiées pendant le déploiement :
Attribution de rôle
Planification de l’actualisation
Informations d’identification de la source de données
Paramètres de mise en cache des requêtes (peuvent être hérités de la capacité)
Paramètres d’approbation
Fonctionnalités de modèle sémantique prises en charge
Les pipelines de déploiement prennent en charge de nombreuses fonctionnalités de modèle sémantique. Cette section en présente deux, qui peuvent améliorer votre expérience avec les pipelines de déploiement :
Actualisation incrémentielle
Les pipelines de déploiement prennent en charge l’actualisation incrémentielle, une fonctionnalité qui rend le processus d’actualisation des modèles sémantiques volumineux plus rapide et plus fiable, tout en diminuant la consommation.
Avec les pipelines de déploiement, vous pouvez mettre à jour un modèle sémantique avec une actualisation incrémentielle tout en conservant les données et les partitions. Lorsque vous déployez le modèle sémantique, la stratégie est copiée en même temps.
Pour comprendre le comportement de l’actualisation incrémentielle avec les flux de données, consultez Pourquoi est-ce que je vois deux sources de données connectées à mon flux de données après avoir utilisé des règles de flux de données ?
Remarque
Les paramètres d’actualisation incrémentielle ne sont pas copiés dans Gen 1.
Activation de l’actualisation incrémentielle dans un pipeline
Pour activer l’actualisation incrémentielle, configurez-la dans Power BI Desktop, puis publiez votre modèle sémantique. Après publication, la stratégie d’actualisation incrémentielle est similaire dans tout le pipeline. Elle ne peut être créée que dans Power BI Desktop.
Une fois votre pipeline configuré avec l’actualisation incrémentielle, nous vous recommandons de suivre le flux suivant :
Apportez des modifications à votre fichier .pbix dans Power BI Desktop. Pour éviter un long temps d’attente, vous pouvez effectuer des modifications en utilisant un échantillon de vos données.
Chargez votre fichier .pbix dans la première étape (généralement l’étape de développement).
Déployez le contenu à l’étape suivante. Après le déploiement, les modifications que vous avez apportées sont appliquées à l’ensemble du modèle sémantique que vous utilisez.
Évaluez les modifications apportées à chaque étape et, après les avoir vérifiées, passez à l’étape suivante jusqu’à l’étape finale.
Exemples d'utilisation
Voici quelques exemples d'intégrations possibles de l'actualisation incrémentielle avec des pipelines de déploiement.
Créez un pipeline et connectez-le à un espace de travail qui utilise un modèle sémantique avec l’option d’actualisation incrémentielle activée.
Activez l’actualisation incrémentielle dans un modèle sémantique qui se trouve déjà dans un espace de travail de développement.
Créez un pipeline à partir d’un espace de travail de production où un modèle sémantique utilise l’actualisation incrémentielle. Par exemple, attribuez l’espace de travail à la phase de production d’un nouveau pipeline et utilisez le déploiement à rebours pour le déployer à l’étape de test, puis à l’étape de développement.
Publiez un modèle sématique qui utilise l’actualisation incrémentielle dans un espace de travail faisant partie d’un pipeline existant.
Limitations de l’actualisation incrémentielle
Pour l’actualisation incrémentielle, les pipelines de déploiement prennent uniquement en charge les modèles sémantiques qui utilisent des métadonnées de modèle sémantique améliorées. Tous les modèles sémantiques créés ou modifiés avec Power BI Desktop implémentent automatiquement des métadonnées de modèle sémantique améliorées.
Lors de la republication d’un modèle sémantique dans un pipeline actif avec l’option d’actualisation incrémentielle activée, les changements suivants entraînent l’échec du déploiement en raison de la perte potentielle de données :
Republier un modèle sémantique qui n’utilise pas l’actualisation incrémentielle, afin de remplacer un modèle sémantique pour lequel l’actualisation incrémentielle est activée.
Attribution d’un nouveau nom à une table sur laquelle l’actualisation incrémentielle est activée
Attribution d’un nouveau nom à des colonnes non calculées dans une table sur laquelle l’actualisation incrémentielle est activée.
D’autres modifications, comme l’ajout ou la suppression d’une colonne, ou l’attribution d’un nouveau nom à une colonne calculée, sont autorisées. Toutefois, si elles affectent l’affichage, une actualisation est nécessaire pour qu’elles deviennent visibles.
Modèles composites
Les modèles composites permettent de configurer un rapport avec plusieurs connexions de données.
Vous pouvez utiliser la fonctionnalité de modèles composites pour connecter un modèle sémantique Fabric à un modèle sémantique externe comme Azure Analysis Services. Pour plus d’informations, consultez Utilisation de DirectQuery pour les modèles sémantiques Fabric et Azure Analysis Services.
Dans un pipeline de déploiement, vous pouvez utiliser des modèles composites pour connecter un modèle sémantique à un autre modèle sémantique Fabric externe au pipeline.
Agrégations automatiques
Les agrégations automatiques s’appuient sur des agrégations définies par l’utilisateur et utilisent le machine learning pour optimiser en permanence les modèles sémantiques DirectQuery et ainsi maximiser les performances des requêtes de rapport.
Chaque modèle sémantique conserve ses agrégations automatiques après le déploiement. Les pipelines de déploiement ne modifient pas l’agrégation automatique d’un modèle sémantique. Cela signifie que si vous déployez un modèle sémantique avec une agrégation automatique, l’agrégation automatique dans l’étape cible reste la même et n’est pas remplacée par l’agrégation automatique déployée à partir de l’étape source.
Pour activer les agrégations automatiques, suivez les instructions fournies dans Configurer les agrégations automatiques.
Tables hybrides
Les tables hybrides sont des tables avec actualisation incrémentielle qui peuvent avoir des partitions d’importation et de requête directe. Durant un nouveau déploiement, la stratégie d’actualisation et les partitions de table hybride sont copiées. Dans le cas d’un déploiement sur une phase de pipeline qui a déjà des partitions de table hybride, seule la stratégie d’actualisation est copiée. Pour mettre à jour les partitions, actualisez la table.
Mettre à jour du contenu vers des applications Power BI
Les applications Fabric sont la méthode recommandée pour distribuer du contenu aux consommateurs Fabric gratuits. Vous pouvez mettre à jour le contenu de vos applications Power BI à l’aide d’un pipeline de déploiement, ce qui vous offre plus de contrôle et de flexibilité en termes de le cycle de vie de vos applications.
Créez une application pour chaque étape du pipeline de déploiement, afin de pouvoir tester chaque mise à jour du point de vue d’un utilisateur final. Utilisez le bouton Publier ou Afficher de la carte de l’espace de travail pour publier ou afficher l’application dans une étape de pipeline spécifique.

Au cours de l’étape de production, le bouton d’action principal situé dans le coin inférieur droit ouvre la page Mettre à jour l’application dans Fabric, afin que toutes les mises à jour de contenu soient disponibles pour les utilisateurs de l’application.

Important
Le processus de déploiement n’inclut pas la mise à jour du contenu ou des paramètres de l’application. Pour appliquer les modifications apportées au contenu ou aux paramètres, vous devez mettre à jour manuellement l’application dans l’étape de pipeline requise.
Autorisations
Des autorisations sont requises pour le pipeline, ainsi que pour les espaces de travail qui lui sont attribués. Les autorisations de pipeline et d’espace de travail sont accordées et gérées séparément.
Les pipelines disposent d’une seule autorisation, Administration, qui est requise pour le partage, la modification et la suppression d’un pipeline.
Les espaces de travail disposent d’autorisations différentes, également appelées rôles. Les rôles d’espace de travail déterminent le niveau d’accès à un espace de travail dans un pipeline.
Les pipelines de déploiement ne prennent pas en charge les Groupes Microsoft 365 en tant qu'administrateurs de pipeline.
Pour effectuer un déploiement d’une étape à une autre dans le pipeline, vous devez être administrateur de pipeline et contributeur, membre ou administrateur des espaces de travail attribués aux étapes impliquées. Par exemple, un administrateur de pipeline auquel un rôle d’espace de travail n’est pas attribué peut afficher le pipeline et le partager avec d’autres. Toutefois, cet utilisateur ne peut pas afficher le contenu de l'espace de travail dans le pipeline, ni dans le service, et ne peut pas effectuer de déploiements.
Tableau des autorisations
Cette section décrit les autorisations de pipeline de déploiement. Les autorisations indiquées dans cette section peuvent avoir des applications différentes dans d'autres caractéristiques de Fabric.
L’autorisation de pipeline de déploiement la plus faible est administrateur de pipeline, et elle est requise pour toutes les opérations de pipeline de déploiement.
| Utilisateur | Autorisations de pipeline | Commentaires |
|---|---|---|
| Administrateur de pipeline |
|
L’accès au pipeline n’accorde pas d’autorisations pour afficher ou prendre des mesures sur le contenu de l’espace de travail. |
| Visionneuse d’espace de travail (et administrateur de pipeline) |
|
Les membres de l’espace de travail qui ont le rôle Lecteur sans autorisations de création ne peuvent pas accéder au modèle sémantique ni modifier le contenu de l’espace de travail. |
| Contributeur d’espace de travail (et administrateur de pipeline) |
|
|
| Membre de l’espace de travail (et administrateur de pipeline) |
|
Si le paramètre pour bloquer la republication et désactiver l’actualisation de package est activé dans la section de la sécurité des modèles sémantiques du locataire, seuls les propriétaires de modèles sémantiques peuvent mettre à jour les modèles sémantiques. |
| Administrateur de l’espace de service (et administrateur de pipeline) |
|
Permissions accordées
Lors du déploiement d'articles Power BI, la propriété de l'article déployé peut changer. Consultez le tableau ci-dessous pour savoir qui peut déployer chaque élément et comment le déploiement affecte la propriété de l’élément.
| Élément Fabric | Autorisation nécessaire pour déployer un élément existant | Propriété de l’élément après un nouveau déploiement | Propriété de l’élément après un déploiement sur une phase avec l’élément |
|---|---|---|---|
| Modèle sémantique | Membre de l’espace de travail | L’utilisateur qui a effectué le déploiement devient le propriétaire | Inchangé |
| Flux de données | Propriétaire du flux de données | L’utilisateur qui a effectué le déploiement devient le propriétaire | Inchangé |
| Datamart | Propriétaire du datamart | L’utilisateur qui a effectué le déploiement devient le propriétaire | Inchangé |
| Rapport paginé | Membre de l’espace de travail | L’utilisateur qui a effectué le déploiement devient le propriétaire | L’utilisateur qui a effectué le déploiement devient le propriétaire |
Autorisations requises pour les actions courantes
Le tableau ci-dessous répertorie les autorisations requises pour les actions courantes de pipeline de déploiement. Sauf indication contraire, pour chaque action, vous devez disposer de toutes les autorisations listées.
| Action | Autorisations requises |
|---|---|
| Afficher la liste des pipelines de votre organisation | Aucune licence requise (utilisateur gratuit) |
| Créer un pipeline | Utilisateur disposant de l’une des licences suivantes :
|
| Supprimer un pipeline | Administrateur de pipeline |
| Ajouter ou supprimer un utilisateur de pipeline | Administrateur de pipeline |
| Attribuer un espace de travail à une étape |
|
| Désattribuer un espace de travail à une étape | Celui-ci peut avoir l'une des valeurs suivantes :
|
| Déployer dans une étape vide |
|
| Déployer des éléments vers l’étape suivante |
|
| Afficher ou définir une règle |
|
| Gérer les paramètres de pipeline | Administrateur de pipeline |
| Afficher une étape de pipeline |
|
| Afficher la liste des éléments d’une étape | Administrateur de pipeline |
| Comparer deux étapes |
|
| Voir l’historique des déploiements | Administrateur de pipeline |
Considérations et limitations
Cette section répertorie la plupart des limitations dans les pipelines de déploiement.
- L’espace de travail doit résider sur une capacité Fabric.
- Le nombre maximal d'éléments pouvant être déployés dans un seul déploiement est de 300.
- Le téléchargement d’un fichier .pbix après le déploiement n’est pas pris en charge.
- Les groupes Microsoft 365 ne sont pas pris en charge en tant qu’administrateurs de pipeline.
- Lors du déploiement d’un élément Power BI pour la première fois, si un autre élément dans la phase cible est de type similaire (par exemple, si les deux fichiers sont des rapports) et porte le même nom, le déploiement échoue.
- Pour obtenir la liste des limitations des espaces de travail, consultez Limitations de l’attribution d’espaces de travail.
- Pour obtenir la liste des éléments pris en charge, consultez Éléments pris en charge. Tout élément ne figurant pas dans la liste n’est pas pris en charge.
- Le déploiement échoue si l'un des éléments a des dépendances circulaires ou autonomes (par exemple, l'élément A fait référence à l'élément B et l'élément B fait référence à l'élément A).
- Seuls les éléments Power BI peuvent être déployés sur un espace de travail dans une autre région de capacité. Les autres articles Fabric ne peuvent pas être déployés dans un espace de travail situé dans une région de capacité différente.
Limitations du modèle sémantique
Les jeux de données qui utilisent la connectivité des données en temps réel ne peuvent pas être déployés.
Un modèle sémantique avec le mode de connectivité DirectQuery ou Composite, qui utilise des tables de variation Date/heure automatiques, n’est pas pris en charge. Pour plus d’informations, consultez Que puis-je faire si j’ai un jeu de données avec le mode de connectivité DirectQuery ou Composite, qui utilise des tableaux de variation ou de calendrier ?.
Pendant le déploiement, si le modèle sémantique cible utilise une connexion en direct, le modèle sémantique source doit également utiliser ce mode de connexion.
Après le déploiement, le téléchargement d'un modèle sémantique (à partir de l'aperçu où il a été déployé) n'est pas pris en charge.
Pour obtenir une liste des limitations des règles de déploiement, consultez les limitations des règles de déploiement.
Le déploiement n’est pas pris en charge sur un modèle sémantique qui utilise une requête native et DirectQuery ensemble et la liaison automatique est engagée sur la source de données DirectQuery.
Lorsqu’un modèle sémantique Direct Lake est déployé, il ne se lie pas automatiquement aux éléments de la phase cible. Par exemple, si un LakeHouse est une source pour un modèle sémantique DirectLake et qu’ils sont tous deux déployés vers la phase suivante, le modèle sémantique DirectLake dans la phase cible est lié au LakeHouse dans la phase source. Utilisez des règles de source de données pour le lier à un élément de la phase cible. D’autres types de modèles sémantiques sont automatiquement liés à l’élément associé dans la phase cible.
Limitations des flux de données
Les paramètres d’actualisation incrémentielle ne sont pas copiés dans Gen 1.
Lors du déploiement d’un flux de données dans une phase vide, les pipelines de déploiement créent un espace de travail et définissent le stockage du flux de données sur un stockage d’objets blob Fabric. Un stockage d’objets blob est utilisé même si l’espace de travail source est configuré pour utiliser Azure Data Lake Storage Gen2 (ADLS Gen2).
Le principal de service n’est pas pris en charge pour les flux de données.
Le déploiement du modèle CDM (Common Data Model) n’est pas pris en charge.
Pour les limitations des règles de pipeline de déploiement qui affectent les flux de données, consultez Limitations des règles de déploiement.
Si un flux de données est actualisé pendant le déploiement, le déploiement échoue.
Quand vous comparez des aperçus pendant l'actualisation des flux de données, les résultats sont imprévisibles.
Limites des datamarts
Vous ne pouvez pas déployer un datamart avec des étiquettes de confidentialité.
Pour déployer un datamart, vous devez être le propriétaire du datamart.