Scénario Data Factory de bout en bout : introduction et architecture
Ce tutoriel vous aide à accélérer le processus d’évaluation de Data Factory dans Microsoft Fabric en fournissant des instructions pas à pas pour un scénario d’intégration de données complet en l’espace d’une heure. À la fin de ce tutoriel, vous comprenez la valeur et les fonctionnalités clés de Data Factory et savez comment effectuer un scénario d’intégration de données de bout en bout commun.
Vue d’ensemble : pourquoi Data Factory dans Microsoft Fabric ?
Cette section vous aide à comprendre le rôle de Fabric en général et le rôle de Data Factory dans celui-ci.
Comprendre la valeur de Microsoft Fabric
Microsoft Fabric fournit un guichet unique pour tous les besoins analytiques de chaque entreprise. Il couvre une gamme complète de services, y compris le déplacement des données, le lac de données, l’engineering données, l’intégration des données et la science des données, l’analytique en temps réel et le décisionnel. Avec Fabric, il n’est pas nécessaire d’assembler différents services provenant de plusieurs fournisseurs. Au lieu de cela, vos utilisateurs bénéficient d’un produit de bout en bout, hautement intégré, unique et complet, facile à comprendre, à intégrer, à créer et à utiliser.
Comprendre la valeur de Data Factory dans Microsoft Fabric
Data Factory dans Fabric combine la facilité d’utilisation de Power Query à la mise à l’échelle et à la puissance d’Azure Data Factory. Il réunit le meilleur des deux produits dans une expérience unifiée. L’objectif est de s’assurer que l’intégration de données dans Factory fonctionne bien pour les développeurs de données citoyens et professionnels. Il fournit des expériences de préparation et de transformation des données à faible code compatibles avec l’IA, une transformation à l’échelle du pétaoctet, des centaines de connecteurs avec une connectivité multicloud hybride. Purview fournit la gouvernance, et le service propose des engagements de données/opérations à l’échelle de l’entreprise, une intégration continue et une livraison continue, une gestion du cycle de vie des applications et une surveillance.
Introduction : comprendre les trois fonctionnalités clés de Data Factory
- Ingestion de données : l’activité Copy dans les pipelines vous permet de déplacer des données à l’échelle du pétaoctet à partir de centaines de sources de données vers votre data Lakehouse pour un traitement ultérieur.
- Transformation et préparation des données : Dataflow Gen2 fournit une interface à faible code pour transformer vos données à l’aide de plus de 300 transformations de données, avec la possibilité de charger les résultats transformés dans plusieurs destinations telles que les bases de données Azure SQL, Lakehouse, etc.
- Automatisation des flux d’intégration de bout en bout : les pipelines fournissent l’orchestration des activités qui incluent les activités Copy, Dataflow et Notebook, etc. Cela vous permet de gérer les activités au même endroit. Les activités d’un pipeline peuvent être chaînées pour fonctionner de manière séquentielle ou peuvent fonctionner en parallèle de façon indépendante.
Dans ce cas d’utilisation de l’intégration de données de bout en bout, vous apprenez :
- Comment ingérer des données à l’aide de l’Assistant de copie dans un pipeline
- Comment transformer les données à l’aide d’un flux de données avec une expérience sans code ou en écrivant votre propre code pour traiter les données avec une activité Script ou Notebook
- Comment automatiser l’ensemble du flux d’intégration de données de bout en bout à l’aide d’un pipeline avec des déclencheurs et des activités de flux de contrôle flexibles.
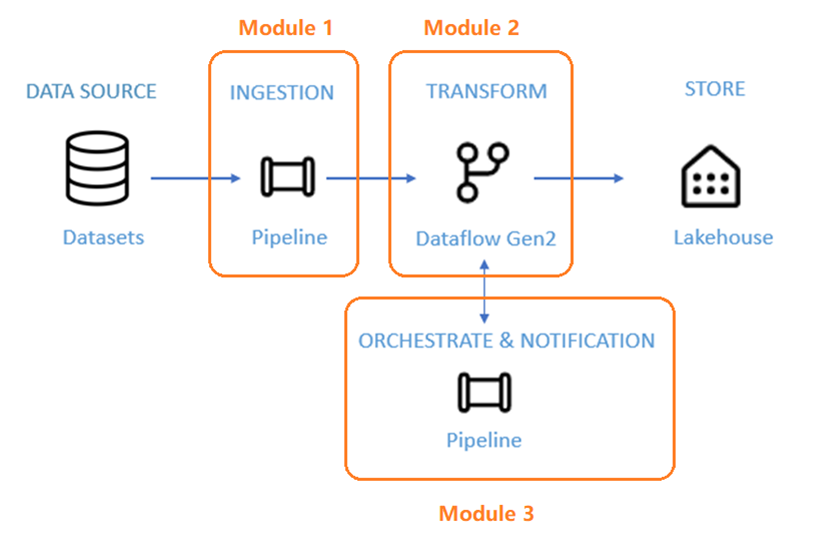
Architecture
Au cours des 50 prochaines minutes, vous êtes chargé de terminer un scénario d’intégration de données de bout en bout. Cela inclut l’ingestion de données brutes à partir d’un magasin source dans la table Bronze d’un Lakehouse, le traitement de toutes les données, leur déplacement vers la table Gold du data Lakehouse, l’envoi d’un e-mail pour vous avertir une fois que tous les travaux sont terminés et enfin, la configuration de l’ensemble du flux pour qu’il s’exécute sur une base planifiée.
Le scénario est divisé en trois modules :
- Module 1 : Créer un pipeline avec Data Factory pour ingérer des données brutes d’un stockage Blob vers une table Bronze dans un data Lakehouse.
- Module 2 : Transformer des données avec un flux de données dans Data Factory pour traiter les données brutes de votre table Bronze et les déplacer vers une table Gold dans data Lakehouse.
- Module 3 : Effectuer votre premier parcours d’intégration de données pour envoyer un e-mail pour vous avertir une fois que tous les travaux sont terminés, et enfin configurer l’ensemble du flux pour qu’il s’exécute sur une base planifiée.
Vous utilisez l’exemple de jeu de données NYC-Taxi comme source de données pour le tutoriel. Une fois que vous avez terminé, vous êtes en mesure d’obtenir des informations sur les remises quotidiennes sur les tarifs des taxis pendant une période spécifique à l’aide de Data Factory dans Microsoft Fabric.
Contenu connexe
Dans cette introduction à notre tutoriel de bout en bout pour votre première intégration de données à l’aide de Data Factory dans Microsoft Fabric, vous avez découvert :
- La valeur et le rôle de Microsoft Fabric
- La valeur et le rôle de Data Factory dans Fabric
- Fonctionnalités clés de Data Factory
- Ce que vous allez apprendre dans ce tutoriel
Passez à la section suivante maintenant pour créer votre pipeline de données.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour