Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Microsoft Fabric fournit plusieurs façons d’intégrer des données dans votre environnement d’analytique. Que vous deviez traiter les événements de diffusion en continu en temps réel, répliquer des bases de données opérationnelles, orchestrer des pipelines par lots ou accéder aux données sans les copier, Fabric offre des fonctionnalités intégrées pour prendre en charge chaque scénario.
Cet article décrit les options d’ingestion et de déplacement de données principales dans Fabric. Il couvre :
- Ingestion en temps réel avec Eventstreams et Eventhouse
- Orchestration par lots avec des pipelines Data Factory et une tâche de copie
- Réplication en temps quasi réel avec la mise en miroir
- Virtualisation des données avec raccourcis OneLake
Utilisez cette vue d’ensemble pour comprendre le fonctionnement de chaque approche et choisir la stratégie qui convient le mieux à vos exigences de charge de travail pour la latence, la transformation et la complexité opérationnelle.
Ingestion de données en temps réel
Les flux d’événements et les éléments Eventhouse dans la charge de travail Real-Time Intelligence prennent en charge les scénarios de données de streaming. Eventstreams ingèrent et traitent les événements en temps réel, et Eventhouses stockent et interrogent ces événements à grande échelle. En règle générale, vous utilisez un Eventstream pour capturer et router les données vers un Eventhouse. Vous pouvez également utiliser chaque fonctionnalité indépendamment en fonction de vos besoins. Le diagramme suivant montre comment les jeux de données en temps réel circulent vers Eventstream et Eventhouse dans Fabric :
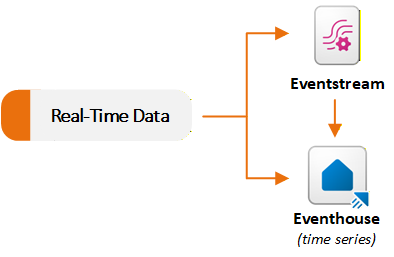
Ingérer et acheminer des événements avec Eventstream
Eventstream offre une expérience sans code pour ingérer des événements dans Fabric, appliquer des transformations en flux et acheminer des données vers plusieurs destinations. Un eventstream agit comme un pipeline d’ingestion en temps réel. Vous créez un eventstream et ajoutez un ou plusieurs connecteurs sources. Fabric prend en charge de nombreuses sources de diffusion en continu, notamment les événements fabric internes tels que les événements d’espace de travail Fabric, les événements de fichier OneLake et les événements de travail de pipeline.
Une fois que les événements commencent à circuler, vous pouvez appliquer en temps réel des transformations facultatives via un éditeur de glisser-déposer. Par exemple, vous pouvez filtrer des événements, calculer des agrégats de fenêtre de temps, joindre plusieurs flux ou remodeler des champs sans écrire de code.
Vous pouvez envoyer le flux traité à une ou plusieurs destinations prises en charge. Les flux d’événements peuvent exposer des points de terminaison Apache Kafka via des sources et des destinations de point de terminaison personnalisées. Cette fonctionnalité permet aux producteurs Kafka de diffuser en continu des événements vers Fabric et aux consommateurs Kafka de consommer des événements depuis Fabric.
Les flux d’événements ne stockent pas les données définitivement. Ils diffusent des événements par le biais de la mémoire et les transfèrent vers des destinations configurées. Cette conception rend Eventstreams adapté aux scénarios d’extraction, de transformation, de chargement (ETL) en temps réel et de distribution de données de streaming à plusieurs cibles. Par exemple, vous pouvez ingérer des données de télémétrie à partir de capteurs IoT (Internet des objets), filtrer et agréger des données en temps réel, envoyer le flux affiné à un Eventhouse pour l’analytique et acheminer les événements d’anomalie vers Activateor pour les alertes.
Ingérer des données directement dans Eventhouse
Les entrepôts d’événements peuvent ingérer des données directement à partir de plusieurs sources. Fabric inclut une expérience d’obtention de données intégrée dans Eventhouse. L’Assistant se connecte à des sources telles que des fichiers locaux, stockage Azure, Amazon S3, Azure Event Hubs et OneLake. Vous pouvez charger des données dans une table de base de données Kusto Query Language (KQL) en temps réel ou en mode batch à l’aide de l’interface utilisateur Eventhouse.
Vous pouvez également sélectionner un eventstream existant dans Fabric en tant que source. Par exemple, si vous utilisez un eventstream qui ingère des données à partir d’IoT Hub ou kafka, vous pouvez router sa sortie directement vers une table de base de données KQL sans configuration supplémentaire.
Ingestion de données batch
Data Factory offre l’expérience principale pour les pipelines d’extraction, de transformation, de chargement (ETL) traditionnels et d’extraction, de chargement, de transformation (ELT). Il inclut une grande bibliothèque de connecteurs. Fabric Data Factory fournit une liste de connecteurs natifs pour les magasins de données locaux et cloud, notamment les bases de données, les applications SaaS (software as a service) et les systèmes basés sur des fichiers. Ces connecteurs vous aident à vous connecter à presque n’importe quel système source.
Orchestrer le déplacement des données avec des pipelines
Vous pouvez créer des pipelines qui utilisent ces connecteurs pour copier ou déplacer des données dans OneLake ou dans des magasins analytiques. Cette approche prend en charge les points suivants :
- Jeux de données non structurés tels que les images, la vidéo et l’audio
- Jeux de données semi-structurés tels que JSON, CSV et XML
- Jeux de données structurés à partir de systèmes de base de données relationnelles pris en charge
Dans un pipeline, vous combinez plusieurs composants d’orchestration, notamment :
- Activités de déplacement des données, telles que copier des données et copier des tâches
- Activités de transformation de données, telles que Dataflow Gen2, Supprimer des données, Bloc-notes Fabric et script SQL
- Contrôler les activités de flux, telles que ForEach, Lookup, Set Variable et Webhook
Vous pouvez exécuter un pipeline à la demande, selon une planification ou en réponse aux événements. Par exemple, vous pouvez planifier l’exécution d’un pipeline toutes les deux heures en semaine ou le déclencher lorsqu’un nouveau fichier est créé dans OneLake.
Simplifier le déplacement des données avec la fonction de copie
Tâche de copie prend en charge plusieurs modèles de livraison de données, notamment la copie en bloc, la copie incrémentielle et la réplication de capture de données de modification (CDC). Vous pouvez utiliser le travail de copie pour déplacer des données d’une source vers OneLake sans créer de pipeline, tout en accédant aux options de configuration avancées. L'opération de copie prend en charge de nombreuses sources et destinations. Il offre plus de contrôle que la réplication et réduit la complexité opérationnelle par rapport à la gestion des pipelines utilisant l’activité Copier.
Répliquer des données avec la mise en miroir
La mise en miroir réplique les données à partir de systèmes externes dans Fabric en quasi-temps réel avec une configuration automatisée. Vous vous connectez à un système externe, tel qu’Azure SQL Database, SQL Server, Oracle, SAP ou Snowflake. Fabric réplique en continu des données ou des métadonnées dans OneLake. La mise en miroir prend en charge trois types :
- La mise en miroir de bases de données réplique des bases de données et des tables entières.
- La mise en miroir de métadonnées synchronise les métadonnées telles que les noms de catalogue, les schémas et les tables au lieu de déplacer physiquement des données. Cette approche utilise des raccourcis pour que les données restent dans son système source tout en étant toujours accessibles dans Fabric.
- La mise en miroir ouverte utilise le format de table Delta Lake ouvert. Les développeurs peuvent écrire des modifications d’application directement dans un élément de base de données mis en miroir dans OneLake à l’aide d’API publiques.
Fabric écoute les modifications du système source (par le biais de la capture de données modifiées ou de méthodes similaires) et applique ces modifications en quasi temps réel à la copie mise en miroir. Le résultat est un jeu de données dynamique et interrogeable qui reste synchronisé avec une faible latence, sans pipelines ETL complexes.
La mise en miroir prend actuellement en charge différentes sources, notamment Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database pour PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake et SQL Server. Il prend également en charge les sources de données des solutions partenaires qui ont implémenté l’API Open Mirroring. Les données répliquées sont stockées dans OneLake en tant que tables Delta à jour. Fabric gère automatiquement ces tables afin que vous puissiez les utiliser pour des analyses en temps réel ou les combiner avec d’autres données Fabric. Cette fonctionnalité prend en charge les scénarios de traitement transactionnel et analytique hybrides, où les données opérationnelles circulent en permanence dans votre plateforme d’analyse.
La mise en miroir élimine le besoin de construire manuellement des pipelines de chargements incrémentaux. Du point de vue des coûts de mise en miroir, les opérations de calcul qui conservent les bases de données mises en miroir synchronisées n’utilisent pas les unités de capacité (CUs) de votre capacité de Fabric. Le stockage de données mis en miroir dans OneLake est également gratuit jusqu’à la limite de téraoctets dans votre référence SKU Fabric (par exemple, F64 inclut 64 To de stockage de base de données en miroir libre).
Accéder aux données externes avec des raccourcis
Fabric fournit des raccourcis pour activer la virtualisation des données. Un raccourci dans OneLake fait référence aux données stockées dans un système externe, comme Azure Data Lake Storage Gen2, Amazon S3 ou SharePoint. Au lieu de copier des données, les raccourcis permettent à OneLake de référencer des fichiers externes dans le cadre du lac de données unifié. Vous pouvez interroger ou joindre des données externes avec des données locales sans effectuer une migration initiale. Cette approche d’ingestion sans copie est utile lorsque les exigences de résidence des données ou les problèmes de duplication empêchent le déplacement des données. Le diagramme suivant montre comment les raccourcis connectent des systèmes de stockage externes à des éléments Fabric sans copier de données :
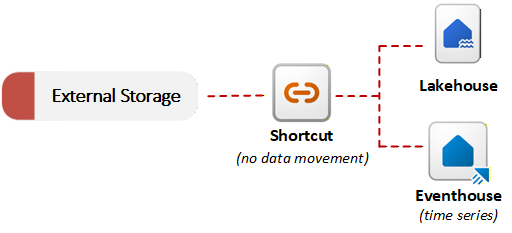
OneLake peut détecter le type de données référencé par un raccourci et appliquer des transformations de fichier ou d’IA sans nécessiter de pipeline ou de code personnalisé. OneLake gère automatiquement la table Delta résultante en synchronisation avec la source. Par exemple, vous pouvez convertir .csv des fichiers en tables Delta ou appliquer une analyse des sentiments basée sur l’IA aux .txt fichiers d’un dossier.
Combinés à la mise en miroir, les raccourcis vous donnent des modèles d’accès aux données flexibles. Vous pouvez conserver les données en place à l’aide de raccourcis, ou vous pouvez répliquer des données à l’aide de la mise en miroir. Dans les deux cas, les données sont prêtes pour les outils d’analytique Fabric sans ETL complexe.
Guide de décision : Choisir une stratégie de déplacement des données
Microsoft Fabric propose plusieurs options pour intégrer des données dans Fabric, notamment eventstreams pour le traitement en temps réel, la mise en miroir, les pipelines avec les activités de copie, le travail de copie et les raccourcis. Chaque option offre un équilibre différent entre le contrôle, l’automatisation et la complexité opérationnelle.
Pour obtenir des conseils sur la sélection de l’approche appropriée pour votre scénario, consultez le guide de décision microsoft Fabric : Choisir une stratégie de déplacement des données.