Déployer et configurer les sources des données de santé dans les solutions de données de santé (version préliminaire)
[Cet article fait partie de la documentation en version préliminaire et peut faire l’objet de modifications.]
Les Sources des données de santé offrent des pipelines de données prêts à l’emploi, conçus pour structurer efficacement les données à des fins d’analyse et de modélisation IA/Machine Learning. Vous pouvez déployer et configurer la fonctionnalité Sources des données de santé après avoir déployé les solutions de données de santé (version préliminaire) sur votre espace de travail Fabric.
Note
La fonctionnalité Sources des données de santé est requise pour exécuter d’autres fonctionnalités des solutions de données de santé (version préliminaire). Assurez-vous de déployer avec succès cette fonctionnalité avant de tenter d’en déployer d’autres.
Conditions préalables au déploiement
Si vous utilisez Services de données de santé Azure comme FHIR source de données, assurez-vous de suivre les étapes de configuration dans Utiliser le service FHIR.
Si vous ne disposez pas de serveur FHIR dans votre environnement de test, utilisez plutôt les exemples de données. Suivez les étapes de la section Déployer des exemples de données pour télécharger les exemples de données dans votre environnement.
déployer Sources des données de santé
Pour déployer des Sources des données de santé dans votre espace de travail, procédez comme suit :
Accédez à la page d’accueil des solutions de données de santé sur Fabric.
Sélectionnez la vignette Sources des données de santé.
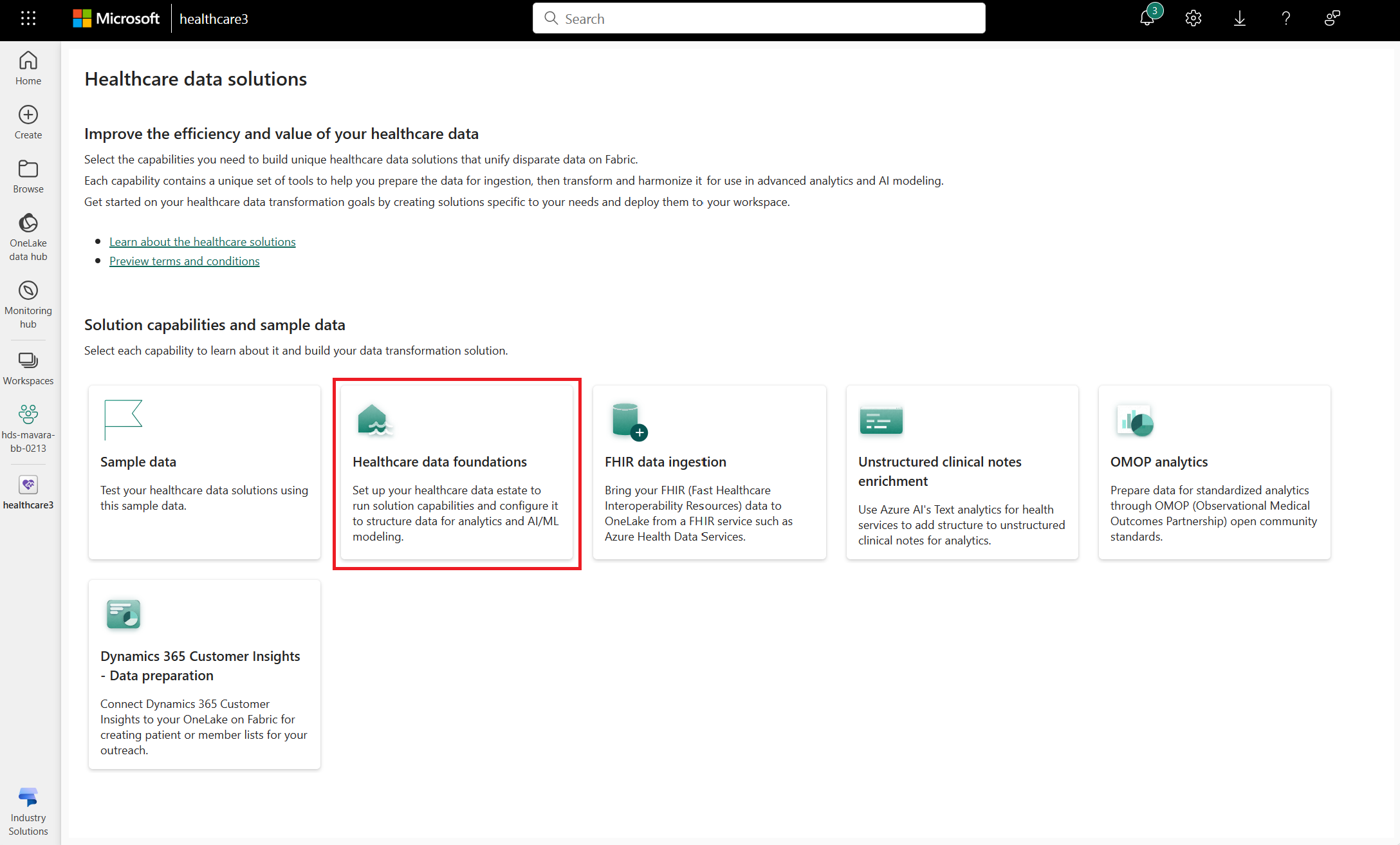
Sur la page des fonctionnalités, sélectionnez Déployer sur l’espace de travail.
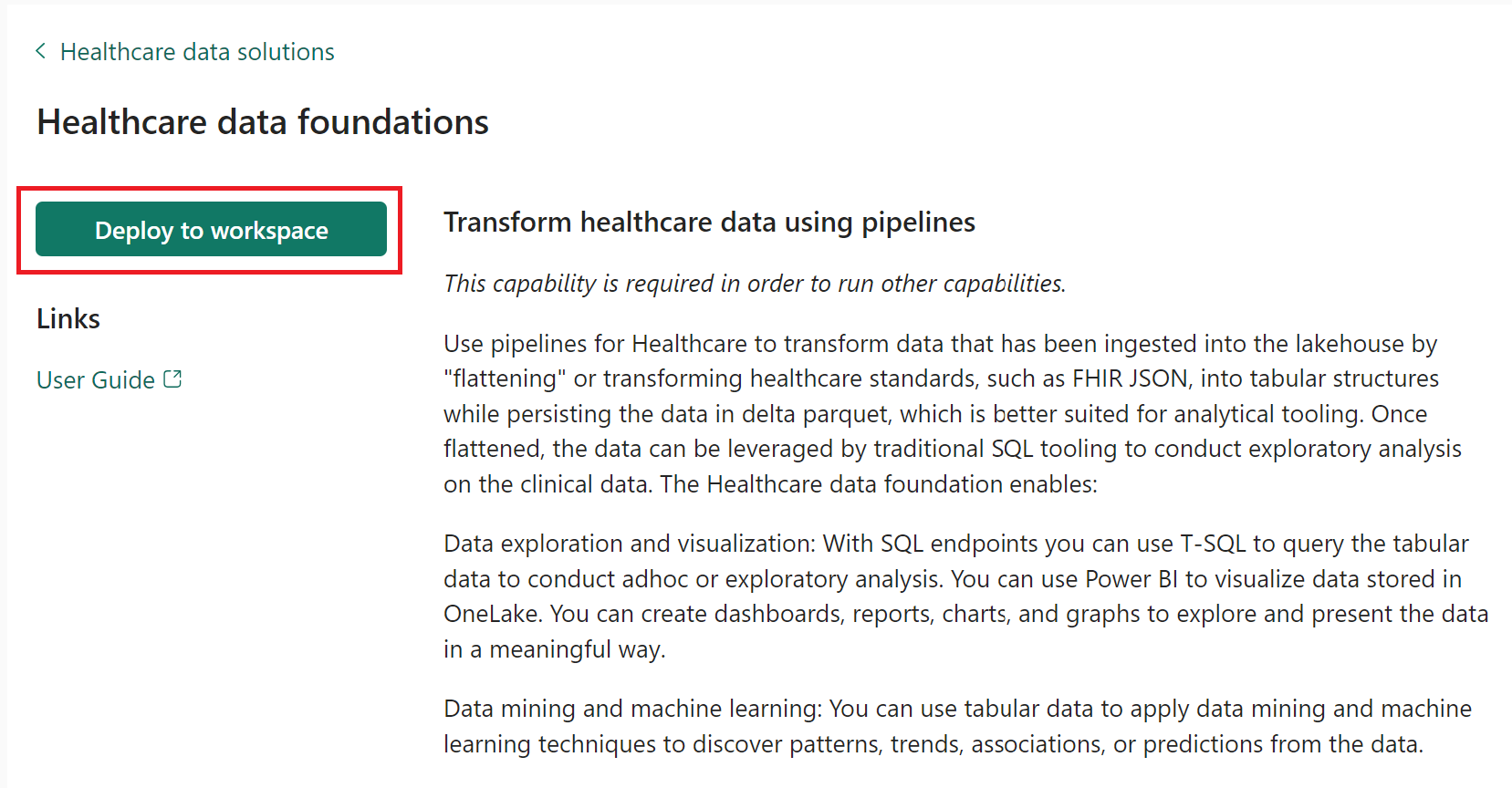
Le déploiement peut prendre plusieurs minutes. Évitez de fermer l’onglet ou le navigateur pendant que le déploiement est en cours. En attendant, vous pouvez travailler dans un autre onglet.
Une fois le déploiement terminé, vous serez averti. Sélectionnez le bouton Gérer les capacités dans la barre de messages pour accéder à la page de gestion des capacités des Sources des données de santé. Ici, vous pouvez afficher, configurer et gérer les artefacts déployés suivants (l’image est uniquement à des fins de représentation) :
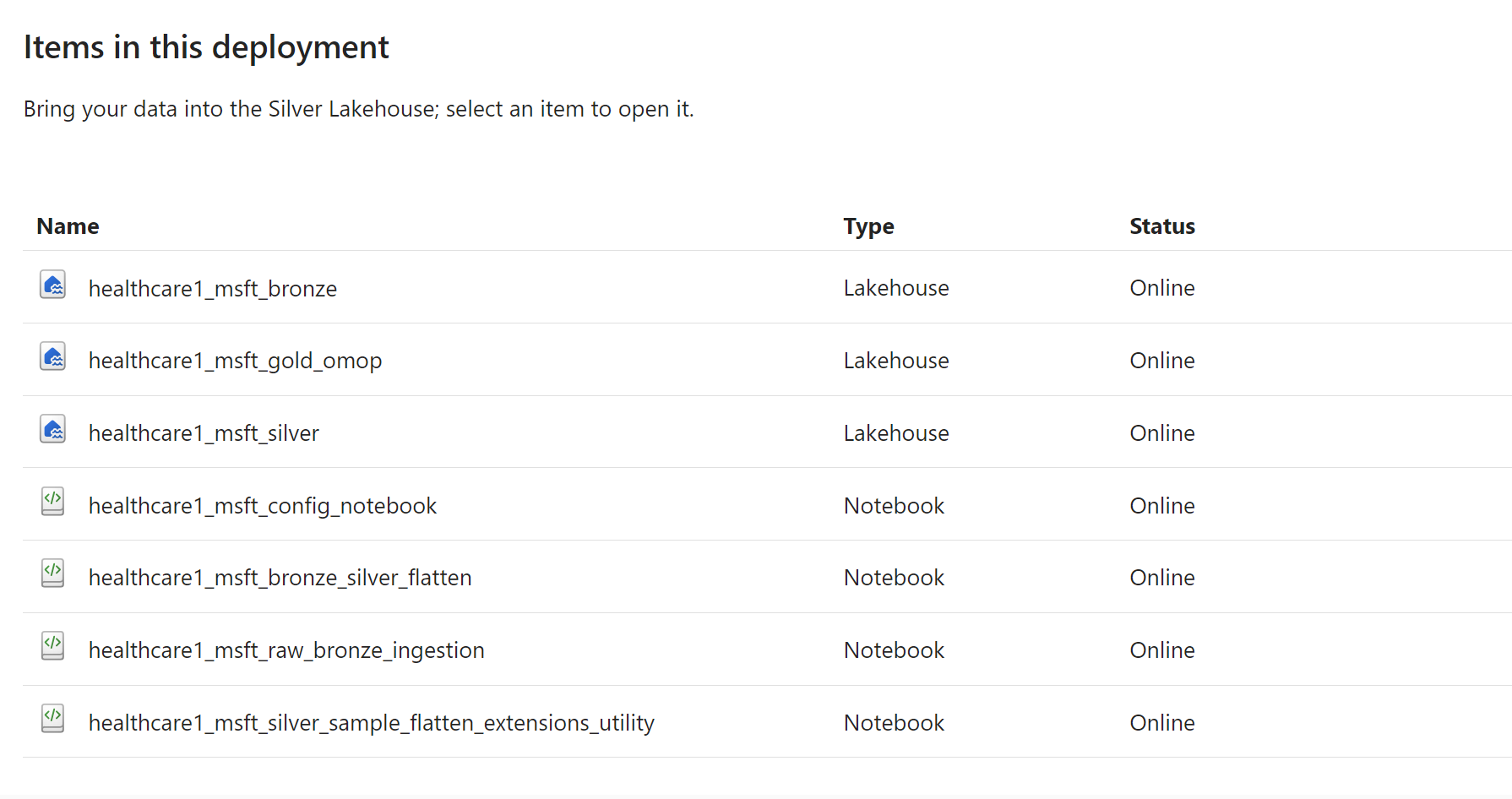



Vous pouvez sélectionner chaque artefact Lakehouse et Notebook pour l’ouvrir et examiner les détails.
Configurer le notebook de configuration globale
Le notebook healthcare#_msft_config_notebook déployé avec les Sources des données de santé est le notebook de configuration globale qui permet de configurer et de gérer la configuration nécessaire à toutes les transformations de données dans les solutions de données de santé (version préliminaire). Il englobe diverses tâches telles que la configuration des paramètres de l’espace de travail et l’installation des packages essentiels au traitement des données.
Fonctionnalités
- Résolution dynamique OneLake point de terminaison : le script résout par programme le OneLake point de terminaison en fonction des environnements d’exécution.
- Validation du runtime Fabric : garantit la compatibilité avec le runtime Fabric pris en charge pour la session Spark.
- Paramètres configurables : livré avec un ensemble de configuration prédéfini.
configuration
Vous devez terminer la configuration de healthcare#_msft_config_notebook avant d’exécuter l’un des pipelines ou notebooks inclus avec les fonctionnalités des solutions de données de santé (version préliminaire). Tous les paramètres requis ne doivent être mis à jour qu’une seule fois dans ce carnet de configuration globale.
Voici les principaux paramètres de configuration associés à ce portable :
Configuration espace de travail : spécifie les noms de l’espace de travail et de la solution, ainsi que le OneLake point de terminaison. Utilisez une convention de dénomination cohérente (nom ou GUID) pour les identifiants d’espace de travail et de solution.
workspace_name: Identifiant de l’espace de travail, soit son GUID, soit son nom.solution_name: Identifiant de l’artefact de charge de travail de soins de santé, au formatArtifactName.ArtifactTypeouArtifactId.one_lake_endpoint: Identifiant du OneLake point de terminaison.
Lakehouse/Database Config : informations sur les bases de données bronze, argent et OMOP . Utilisez une convention d’affectation de noms cohérente (nom ou GUID) telle qu’elle est utilisée dans le Configuration de l’espace de travail section.
bronze_database_name: identificateur de la lakehouse bronze.silver_database_name: identificateur de la lakehouse argent.omop_database_name: OMOP ou l’identifiant or Lakehouse.
Configuration des secrets et des clés : informations secrètes telles que le nom du coffre de clés et la clé d’informations sur l’application.
kv_name: spécifie le nom du service Key Vault contenant tous les secrets et clés nécessaires à l’exécution des pipelines de solutions de données de santé (version préliminaire). Cette valeur doit pointer vers le service de coffre de clés déployé avec le Solutions de données de santé en Microsoft Fabric Offre Azure Marketplace.
Diverse configuration : Autre configuration supplémentaire, comme savoir s’il faut ou non ignorer l’installation du package.
Configuration de la charge de travail : Vous pouvez basculer cette valeur pour la définir sur
TrueouFalse. Définir la valeur surTrueutilise le dossier de charge de travail de l’artefact et définit la valeur surFalseutilise Lakehouse pour les exemples de données et la configuration des transformations.
Lorsque vous provisionnez ce portable, les paramètres sont configurés automatiquement. Cependant, vous devez fournir le kv_name valeur sous le Configuration des secrets et des clés section, comme expliqué dans Configurer le service d’exportation FHIR.
Important
Évitez d’exécuter ce notebook, car il est exécuté dans d’autres notebooks lors de l’installation.
Configuration supplémentaire
Le déploiement de fondations de données de santé déploie également les Lakehouses et notebooks suivants dans votre environnement en plus des soins de santé#_msft_config_notebook. Toutefois, ces artefacts ne nécessitent aucune modification de configuration spécifique après le provisionnement, sauf si vous souhaitez utiliser une configuration ou des données personnalisées.
Lakehouses
Le déploiement de fondations de données de santé provisionne les Lakehouses suivants dans votre environnement :
- healthcare#_msft_bronze
- healthcare#_msft_silver
- healthcare#_msft_gold_omop
Les lakehouses vous permettent d’effectuer les opérations suivantes :
- Téléchargez des données depuis votre ordinateur local.
- Préparez, nettoyez, transformez et ingérez des données.
- Ingérez des données à grande échelle et planifiez des flux de travail de données.
- Transformez et ingérez des données à l’aide du code Apache Spark.
- Accédez aux données qui résident dans un lac externe.
- Importez automatiquement des tableaux remplis d’exemples de données.
Le provisionnement de Lakehouse crée un outil d’analyse SQL point de terminaison pour les requêtes et un modèle sémantique par défaut Power BI pour un reporting plus rapide qui se met à jour avec toutes les tables ajoutées à Lakehouse.
Blocs-notes
En plus des soins de santé#_msft_config_notebook, Le déploiement de fondations de données de santé déploie également les Lakehouses et notebooks suivants dans votre environnement.
- healthcare#_msft_raw_bronze_ingestion
- healthcare#_msft_bronze_silver_flatten
- healthcare#_msft_silver_sample_flatten_extensions_utility
healthcare#_msft_raw_bronze_ingestion
Dans l’architecture médaillon des solutions de données de santé (version préliminaire), les données sont traitées à l’aide d’une approche multicouche. La première couche est bronze qui maintient l’état brut du source de données. La deuxième couche est argent qui représente une version validée et enrichie des données. La troisième et dernière couche est l’ or qui est hautement raffiné et agrégé. Dans ce notebook, nous ingérons des données dans des tables delta du healthcare#_msft_bronze lakehouse.
La structure du notebook est la suivante :
- Charger les données et configurer : commencez par charger les détails de configuration nécessaires que vous pouvez spécifier.
- Appeler BronzeIngestionService : après avoir configuré les conditions préalables, utilisez le module BronzeIngestionService dans la bibliothèque de solutions de données de santé (version préliminaire) pour ingérer les données. Par défaut, le service est configuré pour utiliser les exemples de données fournis. Si vous souhaitez utiliser vos propres données FHIR, mettez à jour la
source_path_patternvaleur en fonction de l’emplacement de vos données. - Vérifier les résultats : affichez les résultats de l’ingestion via un appel à la table nouvellement créée.
Avant d’exécuter ce notebook, assurez-vous d’avoir terminé la configuration de healthcare#_msft_config_notebook en suivant les étapes de Configurer le notebook de configuration globale.
Voici les paramètres clés du healthcare#_msft_raw_bronze_ingestion notebook :
max_files_per_trigger: Nombre maximum de nouveaux fichiers à prendre en compte pour chaque déclencheur. Type de données des valeurs est entier.source_path_pattern: Le modèle à utiliser pour surveiller les dossiers sources. Type de données des valeurs est variable.- Valeur par défaut : les chemins de la zone d’atterrissage sous
abfss://{workspace_name}@{one_lake_endpoint}/{bronze_database_name}/Files/landing_zone/**/**/**/<resource_name>[^a-zA-Z]*ndjson
- Valeur par défaut : les chemins de la zone d’atterrissage sous
healthcare#_msft_bronze_silver_flatten
Dans ce notebook, nous utilisons le module SilverIngestionService de la bibliothèque de solutions de données de santé (version préliminaire) pour aplatir les ressources FHIR dans le lakehouse healthcare#_msft_bronze et ingérer les données résultantes dans le lakehouse healthcare#_msft_silver. Par défaut, vous n’êtes pas censé apporter de modifications à ce bloc-notes. Si vous préférez pointer vers des Lakehouses sources et cibles différentes, vous pouvez modifier les valeurs dans le healthcare#_msft_config_notebook.
Nous vous recommandons de planifier l’exécution de cette tâche de bloc-notes toutes les 4 heures. L’exécution initiale peut ne pas contenir de données à consommer en raison de tâches simultanées et dépendantes, ce qui entraîne une latence. L’ajustement de la fréquence des tâches des couches supérieures peut réduire cette latence.
healthcare#_msft_silver_sample_flatten_extensions_utility
Les extensions sont des éléments enfants qui représentent plus d’informations et peuvent être présents dans chaque élément d’une ressource. Pour en savoir plus sur l’élément d’extension, accédez à Élément d’extension FHIR.
Actuellement, le schéma prend en charge les extensions sous forme de chaînes. Ce bloc-notes fournit des exemples sur la manière d’accéder à ces données d’extension et de les utiliser dans une trame de données. Il existe deux manières d’utiliser les données dans les extensions :
- Utilisez l’utilitaire parse_extension : cet utilitaire est utilisé pour récupérer des champs spécifiques de l’extension de chaîne complète.
- Utiliser le schéma d’extension : utilisez le schéma d’extension pour analyser l’intégralité de l’extension de chaîne.
Avant d’utiliser ce carnet, assurez-vous d’avoir terminé l’ingestion du bronze et de l’argent, car ce carnet utilise la base de données d’argent dans les échantillons.
La structure du notebook est la suivante :
- Charger les données et configurer : commencez par charger les détails de configuration nécessaires que vous pouvez spécifier.
- Analyser l’extension à l’aide de l’utilitaire parse_extension : utilisez l’utilitaire parse_extension pour analyser une extension et récupérer des champs individuels.
- Analyser l’extension à l’aide du schéma d’extension fourni : utilisez le schéma d’extension fourni pour analyser l’intégralité de l’extension de chaîne.
Voici les paramètres clés de l’utilitaire parse_extension :
extension: La colonne d’extension de chaîne complète.urlList:Liste séparée par des virgules d’URL. Chaque URL séparée par des virgules représente une profondeur de niveau imbriquée.value: URL spécifiée de la valeur à récupérer.field: Une liste de champs délimités par des virgules dans le cas où la valeur est un type complexe. Si vous sélectionnez plusieurs champs, ils sont concaténés avec le<->jeton.