Guide d’architecture de traitement des requêtes
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Le moteur de base de données SQL Server traite les requêtes sur diverses architectures de stockage des données, telles que des tables locales, des tables partitionnées et des tables distribuées sur plusieurs serveurs. Les sections suivantes expliquent comment SQL Server traite les requêtes et optimise leur réutilisation grâce à la mise en cache du plan d’exécution.
Modes d'exécution
Le Moteur de base de données SQL Server peut traiter les instructions Transact-SQL selon deux modes de traitement distincts :
- Exécution en mode ligne
- Exécution en mode batch
Exécution en mode ligne
L'exécution en mode ligne est une méthode de traitement des requêtes utilisée avec les tables traditionnelles des SGBDR, où les données sont stockées au format ligne. Quand une requête est exécutée et accède aux données de tables contenant des lignes, les opérateurs de l’arborescence d’exécution et les opérateurs enfants lisent chaque ligne nécessaire, dans toutes les colonnes qui sont spécifiées dans le schéma de table. Pour chaque ligne lue, SQL Server récupère ensuite les colonnes qui sont nécessaires pour le jeu de résultats, telles qu’elles sont référencées par une instruction SELECT, un prédicat JOIN ou un prédicat de filtre.
Remarque
L’exécution en mode ligne est très efficace pour les scénarios OLTP, mais elle peut s’avérer moins efficace lors de l’analyse de grandes quantités de données, par exemple dans les scénarios d’entreposage de données.
Exécution en mode batch
L’exécution en mode batch est une méthode de traitement des requêtes utilisée pour traiter plusieurs lignes ensemble (d’où le terme « batch »). Chaque colonne d’un batch est stockée sous forme de vecteur dans une zone distincte de la mémoire : ainsi, le traitement en mode batch est basé sur les vecteurs. Le traitement en mode batch utilise aussi des algorithmes qui sont optimisés pour les processeurs multicœurs et un débit mémoire amélioré qui se trouvent sur le matériel moderne.
Quand elle a été introduite pour la première, l’exécution en mode batch était étroitement intégrée au format de stockage columnstore et optimisée pour celui-ci. Toutefois, à partir de SQL Server 2019 (15.x) et dans la base de données Azure SQL, l’exécution en mode batch ne nécessite plus d’index columnstore. Pour plus d’informations, consultez Mode batch sur rowstore.
Le traitement en mode batch s’effectue quand c’est possible sur des données compressées et il élimine les opérateurs d’échange utilisés par le traitement en mode ligne. Le résultat est un meilleur parallélisme et des performances plus rapides.
Quand une requête est exécutée en mode batch et qu’elle accède à des données dans des index columnstore, les opérateurs de l’arborescence d’exécution et les opérateurs enfants lisent plusieurs lignes à la fois dans les segments de colonne. SQL Server lit seulement les colonnes nécessaires pour le résultat, telles qu’elles sont référencées par une instruction SELECT, un prédicat JOIN ou un prédicat de filtre. Pour plus d’informations sur les index columnstore, consultez Architecture des index columnstore.
Remarque
L’exécution en mode batch est très efficace dans les scénarios d’entreposage des données, où de grandes quantités de données sont lues et agrégées.
Traitement des instructions SQL
Le traitement d’une seule instruction Transact-SQL est le cas le plus simple d’exécution des instructions Transact-SQL par SQL Server. Les étapes de traitement d’une instruction SELECT unique qui ne fait référence qu’à des tables de base locales (et non à des vues ou à des tables distantes) illustrent le processus de base.
Priorité des opérateurs logiques
Quand une instruction contient plusieurs opérateurs logiques, NOT est traité en premier, ensuite AND et enfin OR. Les opérateurs arithmétiques, et au niveau du bit, sont traités avant les opérateurs logiques. Pour plus d’informations, consultez Priorité des opérateurs.
Dans l'exemple suivant, la condition de couleur est associée au modèle de produit 21 et non au modèle de produit 20, car AND est prioritaire sur OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Vous pouvez modifier la signification de la requête en forçant le traitement de OR en premier lieu à l'aide de parenthèses. La requête suivante recherche uniquement les produits rouges dans les modèles 20 et 21.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
L’utilisation de parenthèses, même quand elles ne sont pas nécessaires, peut améliorer la lisibilité des requêtes et limiter les risques d’erreurs dues à la priorité des opérateurs. L'utilisation de parenthèses ne diminue pas les performances du système. L'exemple suivant est plus lisible que le premier, bien qu'il soit identique sur le plan de la syntaxe.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optimiser des instructions SELECT
Une instruction SELECT est non procédurale ; elle ne précise pas les étapes exactes à suivre par le serveur de base de données pour extraire les données demandées. Cela signifie que le serveur de base de données doit analyser l'instruction afin de déterminer la manière la plus efficace d'extraire les données demandées. Cette opération est nommée optimisation de l’instruction SELECT . Le composant qui s’en charge est l’optimiseur de requête. L’entrée de l’optimiseur de requête est composée de la requête, du schéma de base de données (définitions des tables et des index) et de ses statistiques de base de données. La sortie de l’optimiseur de requête est un plan d’exécution de requête, parfois appelé plan de requête ou plan d’exécution. Le contenu d'un plan d’exécution est détaillé plus loin dans cet article.
Les entrées et les sorties de l’optimiseur de requête pendant l’optimisation d’une instruction SELECT unique sont illustrées dans le diagramme suivant :
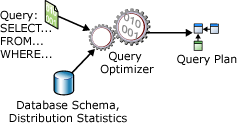
Une instruction SELECT ne définit que :
- le format du jeu de résultats. Il est principalement spécifié dans la liste de sélection. Toutefois, d’autres clauses telles que
ORDER BYetGROUP BYinfluencent également la syntaxe finale du jeu de résultats. - les tables contenant les données source. Ceci est spécifié dans la clause
FROM. - la manière dont les tables sont reliées de façon logique pour les besoins de l’instruction
SELECT. Elle est définie dans les spécifications de jointure, qui peuvent être présentes dans la clauseWHEREou dans une clauseONà la suite deFROM. - Les conditions auxquelles doivent répondre les lignes des tables sources afin de correspondre à l’instruction
SELECT. Elles sont spécifiées dans les clausesWHEREetHAVING.
Un plan d'exécution de requête permet de définir :
L’ordre d’accès aux tables sources.
Pour créer le jeu de résultats, le serveur de bases de données peut accéder aux tables de base selon de nombreux ordres différents. Par exemple, si l’instructionSELECTfait référence à trois tables, le serveur de base de données accédera d’abord àTableA, utilisera les données deTableApour extraire les lignes correspondantes deTableB, puis utilisera les données deTableBpour extraire les données deTableC. Les autres séquences dans lesquelles le serveur de bases de données peut accéder aux tables sont les suivantes :
TableC,TableB,TableAou
TableB,TableA,TableCou
TableB,TableC,TableAou
TableC, ,TableATableBLes méthodes utilisées pour extraire les données des différentes tables.
Il existe également différentes méthodes d'accès aux données dans chaque table. Si seules quelques lignes ayant des valeurs de clés spécifiques sont nécessaires, le serveur de base de données peut utiliser un index. Si toutes les lignes de la table sont nécessaires, le serveur de base de données peut ignorer les index et procéder à une analyse de la table. Si toutes les lignes de la table sont nécessaires mais qu’il existe un index dont les colonnes clés se trouvent dans une clauseORDER BY, l’analyse d’index plutôt que l’analyse de table peut éviter un tri séparé du jeu de résultats. Dans le cas d'une table très petite, les analyses de table peuvent s'avérer plus efficaces pour quasiment tous les accès à la table.Les méthodes utilisées pour effectuer les calculs, et filtrer, agréger et trier les données des différentes tables.
À mesure que les données sont consultées à partir des tables, différentes méthodes permettent d’effectuer des calculs sur les données, par exemple calculer des valeurs scalaires, et agréger et trier les données comme défini dans le texte de la requête, par exemple en utilisant une clauseGROUP BYouORDER BY, et filtrer les données, par exemple en utilisant une clauseWHEREouHAVING.
Le processus de sélection d'un plan d'exécution parmi plusieurs possibles est appelé optimisation. L'optimiseur de requête est un des composants les plus importants du moteur de base de données. Bien que l'optimiseur de requête puisse créer une certaine surcharge pour analyser la requête et sélectionner un plan, celle-ci est en général largement compensée par l'adoption d'un plan d'exécution efficace. Prenons l'exemple de deux entrepreneurs en bâtiment à qui l'on commande la même maison. Si l'un d'eux commence par consacrer quelques jours à planifier la construction de cette maison alors que l'autre lance immédiatement la construction sans aucune planification, il est fort probable que celui qui a pris le temps de planifier son projet finira le premier.
L’optimiseur de requête SQL Server est un optimiseur basé sur les coûts. À chaque plan d'exécution possible est associé un coût exprimé en termes de quantité de ressources informatiques utilisées. L'optimiseur de requêtes doit analyser les plans possibles et opter pour celui dont le coût estimé est le plus faible. Certaines instructions SELECT complexes disposent de milliers de plans d’exécution possibles. Dans ce cas, l'optimiseur de requêtes n'analyse pas toutes les combinaisons possibles. Il recourt alors à des algorithmes sophistiqués afin de trouver un plan d'exécution dont le coût se rapproche raisonnablement du minimum possible.
L’optimiseur de requête SQL Server choisit non seulement le plan d’exécution dont le coût en ressources est le plus faible, mais également celui qui retourne le plus rapidement les résultats à l’utilisateur moyennant un coût en ressources raisonnable. Par exemple, le traitement d'une requête en parallèle monopolise généralement davantage de ressources qu'un traitement en série, mais il est plus rapide. L'optimiseur de requête SQL Server utilise un plan d'exécution en parallèle pour retourner les résultats si la charge du serveur n'en est pas affectée de façon rédhibitoire.
L’optimiseur de requête SQL Server se base sur les statistiques de distribution lors de l’estimation du coût en ressources des différentes méthodes d’extraction d’informations à partir d’une table ou d’un index. Les statistiques de distribution sont conservées pour les colonnes et les index, et contiennent des informations sur la densité1 des données sous-jacentes. Elles indiquent la sélectivité des valeurs dans un index ou une colonne spécifique. Par exemple, dans une table représentant des voitures, plusieurs voitures proviennent du même constructeur mais chacune a un numéro d'identification unique. Un index sur le numéro d'identification du véhicule est plus sélectif qu'un index sur le constructeur, car le numéro d'identification du véhicule a une plus faible densité que le constructeur. Si les statistiques d’index ne sont pas à jour, l’optimiseur de requête peut ne pas effectuer le meilleur choix pour l’état actuel de la table. Pour plus d'informations sur les densités, consultez Statistiques.
1 La densité définit la distribution des valeurs uniques qui existent dans les données ou le nombre moyen des valeurs en double pour une colonne donnée. Lorsque la densité diminue, la sélectivité d’une valeur augmente.
L’optimiseur de requête SQL Server est important, car il permet l’ajustement dynamique du serveur de base de données au fur et à mesure que la base de données évolue sans recourir à l’intervention d’un programmeur ou d’un administrateur de bases de données. Cela permet aux programmeurs de se concentrer sur la description du résultat final de la requête. Ils peuvent faire confiance à l’optimiseur de requête SQL Server dans son choix d’un plan d’exécution efficace pour l’état de la base de données à chaque exécution de l’instruction.
Remarque
SQL Server Management Studio propose trois options pour afficher les plans d’exécution :
- Plan d’exécution estimé, qui est le plan compilé, tel que généré par l’optimiseur de requête.
- Plan d’exécution réel, qui correspond au plan compilé avec son contexte d’exécution. Cela inclut les informations d’exécution disponibles à la fin de l’exécution, comme les avertissements d’exécution, ou dans les versions plus récentes du moteur de base de données, le temps écoulé et le temps UC utilisés pendant l’exécution.
- Statistiques des requêtes actives, qui sont identiques au plan compilé auquel s’ajoute son contexte d’exécution. Cela inclut les informations d’exécution pendant la progression de l’exécution, lesquelles sont mises à jour chaque seconde. Les informations d’exécution incluent, par exemple, le nombre réel de lignes qui transitent par les opérateurs.
Traiter une instruction SELECT
Les étapes permettant à SQL Server de traiter une instruction SELECT unique sont les suivantes :
- L’analyseur examine l’instruction
SELECTet la décompose en unités logiques telles que mots clé, expressions, opérateurs et identificateurs. - Un arbre de requêtes, également appelé arbre de séquence, est créé pour décrire les étapes logiques nécessaires à la transformation des données source au format requis par le jeu de résultats.
- L'optimiseur de requête analyse plusieurs méthodes d'accès aux tables source. Il choisit ensuite la série d’étapes qui retournent les résultats le plus rapidement tout en consommant moins de ressources. L'arbre de requêtes est mis à jour pour enregistrer cette série exacte d'étapes. La version optimisée finale de l'arbre de requêtes est nommée plan d'exécution.
- Le moteur relationnel lance le plan d'exécution. Pendant le traitement des étapes qui requièrent des données issues des tables de base, le moteur relationnel demande que le moteur de stockage transmette les données des ensembles de lignes demandés à partir du moteur relationnel.
- Le moteur relationnel traite les données retournées du moteur de stockage dans le format défini pour le jeu de résultats et retourne ce jeu au client.
Pliage de constantes et évaluation d’expression
SQL Server évalue quelques expressions constantes à l'avance pour améliorer les performances des requêtes. On parle d'assemblage de constantes. Une constante est un littéral Transact-SQL, comme 3, 'ABC', '2005-12-31', 1.0e3 ou 0x12345678.
Expressions pouvant être assemblées
SQL Server utilise l'assemblage de constantes avec les types d'expressions suivants :
- Expressions arithmétiques, telles que
1 + 1et5 / 3 * 2, ne contenant que des constantes. - Expressions logiques telles que
1 = 1et1 > 2 AND 3 > 4ne contenant que des constantes. - Fonctions intégrées considérées comme pouvant être assemblées par SQL Server, y compris
CASTetCONVERT. En général, une fonction intrinsèque peut être assemblée si elle est fonction de ses données d'entrée uniquement, à l'exclusion de toute information contextuelle (options SET, paramètres de langue, options de base de données et clés de chiffrement). Les fonctions non déterministes ne peuvent pas être assemblées. Les fonctions intégrées déterministes peuvent être assemblées, à quelques exceptions près. - Méthodes déterministes de types CLR définis par l’utilisateur et fonctions CLR définies par l’utilisateur avec valeur scalaire déterministe (à partir de SQL Server 2012 (11.x)). Pour plus d’informations, consultez Assemblage de constantes pour les fonctions et les méthodes CLR définies par l’utilisateur.
Remarque
Les objets volumineux constituent une exception. Si le type de résultat du processus d’assemblage est un type d’objet volumineux (text, ntext, image, nvarchar(max), varchar(max), varbinary(max) ou XML), SQL Server n’assemble pas l’expression.
Expressions ne pouvant pas être assemblées
Aucun des autres types d’expressions ne peut être assemblé. C’est notamment le cas des types d’expressions suivants :
- Expressions non constantes, par exemple une expression dont le résultat dépend de la valeur d'une colonne.
- Expressions dont les résultats dépendent d'une variable locale ou d'un paramètre, par exemple @x.
- Fonctions non déterministes.
- Fonctions Transact-SQL définies par l’utilisateur1.
- Expressions dont les résultats dépendent de paramètres de langue.
- Expressions dont les résultats dépendent d'options SET.
- Expressions dont les résultats dépendent d'options de configuration du serveur.
1 Avant SQL Server 2012 (11.x), les fonctions CLR définies par l’utilisateur avec valeur scalaire déterministes et les méthodes des types CLR définis par l’utilisateur ne pouvaient pas être assemblées.
Exemples d'expressions constantes pouvant ou ne pouvant pas être assemblées
Considérez la requête suivante :
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Si l’option de base de données PARAMETERIZATION n’a pas la valeur FORCED pour cette requête, l’expression 117.00 + 1000.00 est évaluée et remplacée par son résultat, à savoir 1117.00, avant la compilation de la requête. Voici quelques avantages de l'assemblage des constantes :
- L'expression n'a pas à être évaluée à chaque exécution.
- L’optimiseur de requête calcule la valeur de l’expression, une fois celle-ci évaluée, pour estimer la taille du jeu de résultats de cette partie de la requête
TotalDue > 117.00 + 1000.00.
En revanche, si dbo.f est une fonction scalaire définie par l'utilisateur, l'expression dbo.f(100) n'est pas assemblée parce que SQL Server n'assemble pas les expressions qui font intervenir des fonctions définies par l'utilisateur, même si elles sont déterministes. Pour plus d’informations sur le paramétrage, consultez Paramétrage forcé plus loin dans cet article.
Évaluation d’expression
Certaines expressions qui ne sont pas assemblées, mais dont les arguments (qu’il s’agisse de paramètres ou de constantes) sont connus au moment de la compilation, sont évaluées pendant l’optimisation par l’estimateur de la taille de l’ensemble de résultats (cardinalité) inclus dans l’optimiseur.
Par exemple, les fonctions intégrées et opérateurs spéciaux suivants sont évalués lors de la compilation si leurs données d’entrée sont connues : UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST et CONVERT. Les opérateurs suivants sont également évalués au moment de la compilation si toutes leurs données d'entrée sont connues :
- Opérateurs arithmétiques : +, -, *, /, - unaire
- Opérateurs logiques :
AND,OR,NOT - Opérateurs de comparaison : <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
L’optimiseur de requête n’évalue aucune autre fonction ni aucun autre opérateur pendant l’estimation de cardinalité.
Exemples d'évaluation d'expression au moment de la compilation
Envisageons la procédure stockée suivante :
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Pendant l’optimisation de l’instruction SELECT de cette procédure, l’optimiseur de requête tente d’évaluer la cardinalité attendue du jeu de résultats pour la condition OrderDate > @d+1. L'expression @d+1 n'est pas assemblée de façon constante, puisque @d est un paramètre. Toutefois, la valeur de ce paramètre est connue au moment de l'optimisation. Cela permet à l’optimiseur de requête d’estimer précisément la taille du jeu de résultats, ce qui permet de sélectionner le plan de requête correct.
Examinons à présent un exemple similaire, mais dans lequel l'expression @d2 est remplacée par une variable locale @d+1 qui est évaluée dans une instruction SET et non dans la requête.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Lorsque l’instruction SELECT de la procédure dans MyProc2 est optimisée dans SQL Server, la valeur de @d2 n’est pas connue. Par conséquent, l’optimiseur de requête utilise une estimation par défaut pour la sélectivité de OrderDate > @d2, (en l’occurrence, 30 %).
Traiter les autres instructions
Les étapes de base décrites pour le traitement d’une instruction SELECT s’appliquent à d’autres instructions Transact-SQL comme INSERT, UPDATE et DELETE. Les instructionsUPDATE et DELETE doivent toutes deux cibler l’ensemble de lignes à modifier ou à supprimer. Le processus d’identification de ces lignes est le même que celui utilisé pour identifier les lignes sources qui participent au jeu de résultats d’une instruction SELECT . Les instructions UPDATE et INSERT peuvent toutes deux contenir des instructions SELECT incorporées qui fournissent les valeurs de données à mettre à jour ou à insérer.
Même les instructions DDL telles que CREATE PROCEDURE ou ALTER TABLE sont finalement réduites à une série d’opérations relationnelles sur les tables du catalogue système, voire (comme dans le cas de ALTER TABLE ADD COLUMN) sur les tables de données.
Tables de travail
Le moteur relationnel peut avoir besoin de générer une table de travail pour exécuter une opération logique spécifiée dans une instruction Transact-SQL. Les tables de travail sont des tables internes utilisées pour le stockage des résultats intermédiaires. Les tables de travail sont générées pour certaines requêtes GROUP BY, ORDER BY, ou UNION . Par exemple, si une clause ORDER BY fait référence à des colonnes qui ne sont couvertes par aucun index, le moteur relationnel peut être amené à générer une table de travail pour trier le jeu de résultats dans l’ordre demandé. En outre, les tables de travail sont parfois utilisées comme fichiers d'attente pour le stockage temporaire du résultat de l'exécution d'une partie d'un plan de requête. Les tables de travail sont créées dans tempdb et sont automatiquement supprimées lorsqu’elles ne sont plus nécessaires.
Résolution de vues
Le processeur de requêtes SQL Server traite différemment les vues indexées et les vues non indexées :
- Les lignes des vues indexées sont stockées dans la base de données dans le même format qu'une table. Si l'optimiseur de requête décide d'utiliser une vue indexée dans un plan de requête, celle-ci est traitée de la même façon qu'une table de base.
- Seule la définition d'une vue non indexée est stockée, tandis que les lignes de la vue ne le sont pas. L’optimiseur de requête incorpore la logique de la définition de vue dans le plan d’exécution qu’il génère pour l’instruction Transact-SQL référençant la vue non indexée.
La logique utilisée par l’optimiseur de requête SQL Server pour déterminer quand utiliser une vue indexée est similaire à la logique employée pour décider quand utiliser un index sur une table. Si les données de la vue indexée couvrent tout ou partie de l’instruction Transact-SQL et si l’optimiseur de requête détermine qu’un index sur la vue est le chemin d’accès le moins coûteux, l’optimiseur choisit l’index, que la vue soit référencée ou non par son nom dans la requête.
Quand une instruction Transact-SQL fait référence à une vue non indexée, l’analyseur et l’optimiseur de requête analysent la source de l’instruction Transact-SQL et de la vue, puis les résolvent dans un même plan d’exécution. Il n’y a pas de plans distincts pour l’instruction Transact-SQL et pour la vue.
Imaginons par exemple la vue suivante :
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Sur la base de cette vue, les deux instructions Transact-SQL exécutent les mêmes opérations sur les tables de base et produisent les mêmes résultats :
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
La fonctionnalité Showplan de SQL Server Management Studio montre que le moteur relationnel crée le même plan d’exécution pour ces deux instructions SELECT .
Utiliser des indicateurs avec les vues
Les indicateurs placés sur une vue dans une requête peuvent être en conflit avec d'autres indicateurs découverts lors du développement de la vue pour l'accès à ses tables de base. Lorsque cela se produit, la requête retourne une erreur. Imaginons par exemple la vue suivante, dont la définition contient un indicateur de table :
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Supposons à présent cette requête :
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
La requête échoue, car l’indicateur SERIALIZABLE appliqué à la vue Person.AddrState de la requête est propagé dans les tables Person.Address et Person.StateProvince de la vue lors du développement de cette dernière. Cependant, le développement de la vue révèle également l’indicateur NOLOCK sur Person.Address. La requête résultante est incorrecte parce que les indicateurs SERIALIZABLE et NOLOCK sont en conflit.
Les indicateurs de table PAGLOCK, NOLOCK, ROWLOCK, TABLOCKou TABLOCKX sont en conflit les uns avec les autres, tout comme les indicateurs de table HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREADet SERIALIZABLE .
Les indicateurs peuvent se propager à différents niveaux des vues imbriquées. Imaginons par exemple une requête qui applique l’indicateur HOLDLOCK sur une vue v1. Lorsque v1 est développé, il est établit que la vue v2 fait partie de sa définition. La définition dev2inclut un indicateur NOLOCK sur l’une de ses tables de base. Cependant, cette table hérite également de l’indicateur HOLDLOCK de la requête sur la vue v1. La requête échoue parce que les indicateurs NOLOCK et HOLDLOCK sont en conflit.
Si l’indicateur FORCE ORDER est utilisé dans une requête contenant une vue, l’ordre de jointure des tables de la vue est déterminé par la position de la vue dans la construction ordonnée. Par exemple, la requête suivante effectue une sélection dans trois tables et une vue :
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
View1 est définie comme suit :
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
L’ordre de jointure dans le plan de requête est Table1, Table2, TableA, TableB, Table3.
Résoudre des index sur les vues
Comme avec tout index, SQL Server choisit d’utiliser une vue indexée dans son plan de requête uniquement si l’optimiseur de requête le juge opportun.
Les vues indexées peuvent être créées dans n’importe quelle version de SQL Server. Dans certaines éditions de certaines versions antérieures de SQL Server, l’optimiseur de requête considère automatiquement la vue indexée. Dans certaines éditions de certaines versions antérieures de SQL Server, l’indicateur de table NOEXPAND est nécessaire pour utiliser une vue indexée. Avant SQL Server 2016 (13.x) Service Pack 1, l’utilisation automatique d’une vue indexée par l’optimiseur de requête est prise en charge seulement dans certaines éditions de SQL Server. Depuis, toutes les éditions prennent en charge l’utilisation automatique d’une vue indexée. Azure SQL Database et Azure SQL Managed Instance prennent également en charge l’utilisation automatique de vues indexées sans spécification de l’indicateur NOEXPAND.
L’optimiseur de requête SQL Server utilise une vue indexée lorsque les conditions suivantes sont satisfaites :
- Ces options de session sont activées à
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- L’option de session
NUMERIC_ROUNDABORTest désactivée (OFF). - L'optimiseur de requête trouve une correspondance entre les colonnes d'index des vues et les éléments de la requête, notamment :
- Prédicats de la condition de recherche dans la clause WHERE
- Opérations de jointure
- Fonctions d’agrégation
- Clauses
GROUP BY - Références de table
- Le coût estimé de l'utilisation de l'index est le plus faible de tous les mécanismes d'accès envisagés par l'optimiseur de requête.
- Dans la requête, vous devez appliquer le même ensemble d'indicateurs à chaque table que vous référencez, soit directement, soit en développant une vue afin d'accéder à ses tables sous-jacentes, et qui correspond à une référence de table dans la vue indexée.
Remarque
Les indicateurs READCOMMITTED et READCOMMITTEDLOCK sont toujours considérés comme des indicateurs différents dans ce contexte, indépendamment du niveau d’isolation de la transaction en cours.
En dehors des exigences relatives aux indicateurs de table et aux options SET, l’optimiseur de requête emploie ces mêmes règles pour déterminer si l’index d’une table couvre une requête. Vous n'avez pas besoin de spécifier autre chose dans la requête pour utiliser une vue indexée.
Une requête ne doit pas obligatoirement référencer explicitement une vue indexée dans la clause FROM pour que l’optimiseur de requête utilise la vue indexée. Si la requête contient des références à des colonnes dans des tables de base qui sont également présentes dans la vue indexée, et si l’optimiseur de requête estime que l’emploi de la vue indexée offre le mécanisme d’accès le moins coûteux, il choisit la vue indexée, un peu comme il choisit les index des tables de base lorsque ceux-ci ne sont pas directement référencés dans une requête. L’optimiseur de requête peut choisir la vue lorsqu’elle contient des colonnes qui ne sont pas référencées par la requête, à condition que cette dernière offre l’option la moins coûteuse pour couvrir une ou plusieurs colonnes spécifiées dans la requête.
L’optimiseur de requête traite une vue indexée référencée dans la clause FROM comme une vue standard. L'optimiseur de requête développe la définition de la vue dans la requête au début du processus d'optimisation. Ensuite, la mise en correspondance des éléments de la vue indexée est réalisée. La vue indexée peut être utilisée dans le plan d’exécution final sélectionné par l’optimiseur de requête ou, sinon, le plan peut matérialiser les données nécessaires à partir de la vue en accédant aux tables de base référencées par celle-ci. L’optimiseur de requête choisit la solution la plus économique.
Utiliser des indicateurs avec les vues indexées
Vous pouvez empêcher l’utilisation d’index de vue pour une requête à l’aide de l’indicateur de requête EXPAND VIEWS ou recourir à l’indicateur de table NOEXPAND afin d’imposer l’utilisation d’un index pour une vue indexée spécifiée dans la clause FROM d’une requête. Toutefois, vous devez laisser l'optimiseur de requête déterminer dynamiquement les meilleures méthodes d'accès à utiliser pour chaque requête. Limitez l’utilisation des indicateurs EXPAND et NOEXPAND aux cas spécifiques où les tests ont démontré qu’ils améliorent les performances de façon significative.
L’option
EXPAND VIEWSordonne à l’optimiseur de requête de ne pas utiliser des index de vue pour toute la requête.Quand
NOEXPANDest spécifié dans une vue, l’optimiseur de requête envisage l’utilisation de n’importe quel index défini sur la vue.NOEXPANDspécifié avec la clauseINDEX()facultative force l’optimiseur de requête à utiliser les index spécifiés.NOEXPANDpeut être spécifié uniquement pour une vue indexée et ne peut pas être spécifié pour une vue qui n’a pas été indexée. Avant SQL Server 2016 (13.x) Service Pack 1, l’utilisation automatique d’une vue indexée par l’optimiseur de requête est prise en charge seulement dans certaines éditions de SQL Server. Depuis, toutes les éditions prennent en charge l’utilisation automatique d’une vue indexée. Azure SQL Database et Azure SQL Managed Instance prennent également en charge l’utilisation automatique de vues indexées sans spécification de l’indicateurNOEXPAND.
Lorsque ni NOEXPAND ni EXPAND VIEWS ne sont spécifiés dans une requête qui contient une vue, celle-ci est développée de manière à permettre l’accès aux tables sous-jacentes. Si la requête qui compose la vue contient des indicateurs de table, ceux-ci sont propagés aux tables sous-jacentes. (Ce processus est expliqué en détail dans Résolution de vues.) Si les ensembles d'indicateurs existant sur les tables sous-jacentes de la vue sont identiques, la requête peut être mise en correspondance avec une vue indexée. La plupart du temps, ces indicateurs correspondent les uns aux autres car ils sont hérités directement de la vue. Toutefois, si la requête référence des tables au lieu de vues et que les indicateurs appliqués directement à ces tables ne sont pas identiques, cette requête ne peut pas être mise en correspondance avec une vue indexée. Si les indicateurs INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCKou XLOCK s’appliquent aux tables référencées dans la requête une fois la vue développée, la requête ne peut pas être mise en correspondance avec la vue indexée.
Si un indicateur de table de la forme INDEX (index_val[ ,...n] ) référence une vue dans une requête et que vous ne spécifiez pas l’indicateur NOEXPAND , l’indicateur d’index est ignoré. Pour spécifier l’utilisation d’un index particulier, utilisez NOEXPAND.
En règle générale, quand l’optimiseur de requête fait correspondre une vue indexée avec une requête, tous les indicateurs spécifiés sur les tables ou vues dans la requête sont appliqués directement à la vue indexée. Si l'optimiseur de requête choisit de ne pas utiliser une vue indexée, tous les indicateurs sont propagés directement aux tables référencées dans la vue. Pour plus d’informations, consultez Résolution de vues. Cette propagation ne s'applique pas aux indicateurs de jointure. Ils ne sont appliqués qu'à leur emplacement initial dans la requête. Les indicateurs de jointure ne sont pas envisagés par l’optimiseur de requête lors de la mise en correspondance des requêtes avec les vues indexées. Si un plan de requête utilise une vue indexée qui correspond à une partie d'une requête contenant un indicateur de jointure, celui-ci n'est pas utilisé dans le plan.
L’utilisation d’indicateurs n’est pas autorisée dans les définitions de vues indexées. Dans les modes de compatibilité 80 et supérieurs, SQL Server ignore les indicateurs présents dans les définitions de vues indexées lorsqu’il gère ces définitions ou qu’il exécute des requêtes qui utilisent des vues indexées. Bien que l'utilisation d'indicateurs dans les définitions de vues indexées ne génère pas d'erreur de syntaxe dans le mode de compatibilité 80, ils sont ignorés.
Pour plus d’informations, consultez Indicateurs de table (Transact-SQL).
Résoudre des vues partitionnées distribuées
Le processeur de requêtes SQL Server optimise les performances des vues partitionnées distribuées. L'aspect le plus important des performances d'une vue distribuée partitionnée est de minimiser la quantité de données à transférer entre des serveurs membres.
SQL Server construit des plans intelligents et dynamiques qui utilisent efficacement les requêtes distribuées pour accéder aux données à partir des tables membres distantes :
- Le processeur de requêtes utilise d’abord OLE DB pour récupérer les définitions des contraintes de vérification de chaque table membre. Ceci permet au processeur de requêtes de mapper la distribution des valeurs de clés entre les tables membres.
- Le processeur de requêtes compare les groupes de clés spécifiés dans la clause
WHEREd’une instruction Transact-SQL au mappage qui représente la distribution des lignes dans les tables membres. Le processeur de requêtes construit alors un plan d’exécution de requête qui utilise les requêtes distribuées pour récupérer uniquement les lignes distantes nécessaires pour exécuter l’instruction Transact-SQL. Le plan d'exécution est également construit de telle sorte que tout accès aux tables membres distantes pour les données ou les métadonnées est différé jusqu'à ce que les informations soient requises.
Par exemple, prenons un système où une table de Customers est partitionnée entre Server1 (CustomerID de 1 à 3299999), Server2 (CustomerID de 3300000 à 6599999) et Server3 (CustomerID de 6600000 à 9999999).
Étudiez le plan d’exécution qui est construit pour chaque requête exécutée sur Server1 :
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Le plan d’exécution pour cette requête extrait les lignes avec des valeurs de clés CustomerID de 3200000 à 3299999 de la table membre locale et émet une requête distribuée pour récupérer les lignes dont les valeurs de clés sont comprises entre 3300000 et 3400000 de Server2.
Le processeur de requêtes SQL Server peut également générer une logique dynamique dans les plans d’exécution de requête pour les instructions Transact-SQL dont les valeurs de clés ne sont pas connues au moment de la génération du plan. Prenons par exemple cette procédure stockée :
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server ne peut pas prévoir quelle valeur de clé sera fournie par le paramètre @CustomerIDParameter à chaque exécution de la procédure. Puisque la valeur de la clé ne peut pas être prévue, le processeur de requêtes ne peut pas non plus prévoir quelle table membre devra faire l'objet d'un accès. Pour gérer ce cas, SQL Server construit un plan d’exécution comportant une logique conditionnelle, également appelée filtres dynamiques, pour contrôler quelle table membre fait l’objet d’un accès en fonction de la valeur du paramètre d’entrée. En partant du principe que la procédure stockée GetCustomer a été exécutée sur Server1, la logique du plan d’exécution peut être représentée sous la forme suivante :
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server crée parfois ces types de plans d’exécution dynamique même pour des requêtes qui ne sont pas paramétrables. L’optimiseur peut paramétrer une requête pour que le plan d’exécution puisse être réutilisé. Si l’optimiseur de requête paramètre une requête faisant référence à une vue partitionnée, il ne peut plus supposer que les lignes requises proviendront d’une table de base spécifiée. Il devra alors utiliser des filtres dynamiques dans le plan d'exécution.
Exécution d'une procédure stockée et d'un déclencheur
SQL Server stocke uniquement le code source des procédures stockées et des déclencheurs. Quand une procédure stockée ou un déclencheur est exécuté pour la première fois, la source est compilée dans un plan d'exécution. Si la procédure stockée ou le déclencheur doit à nouveau être exécuté alors que le plan d'exécution se trouve encore en mémoire, le moteur relationnel détecte le plan existant et le réutilise. Si le plan est trop ancien et a été évacué de la mémoire, le système crée un nouveau plan. Ce processus est similaire à celui suivi par SQL Server pour toutes les instructions Transact-SQL. L’avantage principal en termes de performances dont bénéficient les procédures stockées et les déclencheurs dans SQL Server par rapport aux lots du code Transact-SQL dynamique est que leurs instructions Transact-SQL sont toujours les mêmes. Par conséquent, le moteur relationnel les associe facilement à n'importe quel plan d'exécution existant. Les plans des procédures stockées et des déclencheurs sont faciles à réutiliser.
Le plan d'exécution des procédures stockées et des déclencheurs est exécuté séparément du plan d'exécution du traitement qui appelle la procédure stockée ou qui active le déclencheur. Cela permet une meilleure réutilisation des plans d'exécution des procédures stockées et des déclencheurs.
Mise en cache et réutilisation du plan d’exécution
SQL Server dispose d’un pool de mémoire utilisé pour stocker les plans d’exécution et les tampons de données. Le pourcentage de ce pool alloué aux plans d'exécution ou aux tampons de données évolue de façon dynamique en fonction de l'état du système. La part du pool de mémoire utilisée pour stocker les plans d’exécution est appelée « cache du plan ».
Le cache du plan dispose de deux magasins pour tous les plans compilés :
- Le magasin du cache Objet Plans (OBJCP) utilisé pour les plans liés aux objets persistants (procédures stockées, fonctions et déclencheurs).
- Le magasin du cache Plans SQL (SQLCP) utilisé pour les plans liés aux requêtes automatiquement paramétrées, dynamiques ou préparées.
La requête ci-dessous fournit des informations sur l’utilisation de la mémoire pour ces deux magasins de cache :
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Remarque
Le cache du plan comprend deux magasins supplémentaires qui ne sont pas utilisés pour le stockage des plans :
- Le magasin du cache Arborescences liées (PHDR) destiné aux structures de données utilisées pendant la compilation du plan pour les vues, les contraintes et les valeurs par défaut. Ces structures sont appelées « Arborescences liées » ou « Arborescences d’algébrisation ».
- Le magasin du cache Procédures stockées étendues (XPROC) utilisé pour les procédures système prédéfinies, comme
sp_executeSqlouxp_cmdshell, qui sont définies à l’aide d’une DLL et non à l’aide d’instructions Transact-SQL. La structure mise en cache contient uniquement le nom de la fonction et le nom de la DLL dans laquelle la procédure est implémentée.
Les plans d’exécution de SQL Server comprennent les composants principaux suivants :
Plan compilé (ou Plan de requête)
Le plan de requête produit par le processus de compilation est principalement une structure de données réentrantes en lecture seule utilisée par un nombre quelconque d’utilisateurs. Il stocke des informations sur les éléments suivants :Les opérateurs physiques qui mettent en œuvre l'opération décrite par des opérateurs logiques.
L’ordre de ces opérateurs, qui détermine l’ordre dans lequel les données sont accessibles, filtrées et agrégées.
Le nombre de lignes estimées qui transitent par les opérateurs.
Remarque
Dans les versions plus récentes du moteur de base de données, les informations sur les objets de statistiques qui ont été utilisés pour l’estimation de la cardinalité sont également stockées.
Les objets de prise en charge qui doivent être créés, par exemple des tables de données ou des fichiers de travail dans
tempdb. Aucun contexte utilisateur ni aucune information d’exécution n’est stocké dans le plan de requête. Il n'y a jamais plus d'une ou deux copies du plan de requête en mémoire : une copie pour toutes les exécutions en série et une autre pour toutes les exécutions en parallèle. La copie en parallèle couvre toutes les exécutions en parallèle, indépendamment de leur degré de parallélisme.
Contexte d’exécution
Chaque utilisateur exécutant actuellement la requête dispose d'une structure de données qui contient les données spécifiques à son exécution, telles que la valeur des paramètres. Cette structure de données constitue le contexte d'exécution. Les structures de données du contexte d’exécution sont réutilisées, mais pas leur contenu. Si un autre utilisateur exécute la même requête, les structures de données sont réinitialisées avec le contexte du nouvel utilisateur.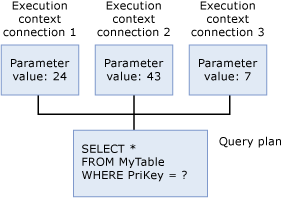
Quand une instruction Transact-SQL est exécutée dans SQL Server, le Moteur de base de données parcourt d’abord le cache du plan afin de vérifier qu’il existe un plan d’exécution pour la même instruction Transact-SQL. L’instruction Transact-SQL est considérée comme existante si elle correspond littéralement à une instruction Transact-SQL exécutée précédemment avec un plan mis en cache, caractère par caractère. SQL Server réutilise le plan existant qu’il trouve, évitant ainsi la recompilation de l’instruction Transact-SQL. S’il n’existe aucun plan d’exécution, SQL Server en génère un nouveau pour la requête.
Remarque
Les plans d’exécution pour certaines instructions Transact-SQL ne sont pas conservés dans le cache du plan, par exemple les instructions d’opérations en bloc s’exécutant sur rowstore ou les instructions contenant des littéraux de chaîne dont la taille est supérieure à 8 Ko. Ces plans n’existent que pendant l’exécution de la requête.
SQL Server dispose d’un algorithme efficace qui permet de trouver un plan d’exécution existant pour toute instruction Transact-SQL spécifique. Dans la plupart des systèmes, les ressources minimales utilisées par cette analyse sont inférieures à celles économisées par la réutilisation de plans existants au lieu de la compilation de chaque instruction Transact-SQL.
Les algorithmes qui permettent d’associer de nouvelles instructions Transact-SQL à des plans d’exécution inutilisés existants dans le cache du plan imposent que toutes les références d’objets soient complètes. Par exemple, supposons que Person est le schéma par défaut pour l’utilisateur exécutant les instructions SELECT ci-dessous. Même si dans cet exemple, la table Person n’a pas besoin d’être totalement apte à s’exécuter, cela signifie que la deuxième instruction n’est associée à aucun plan existant, mais que la troisième l’est :
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Le changement de l’une des options SET suivantes pour une exécution donnée affecte la capacité à réutiliser des plans, car le moteur de base de données effectue un pliage de constantes et ces options affectent les résultats de telles expressions :
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Mise en cache de plusieurs plans pour la même requête
Les requêtes et les plans d’exécution sont identifiables de manière unique dans le moteur de base de données, à l’instar d’une empreinte digitale :
- Le hachage de plan de requête est une valeur de hachage binaire calculée sur le plan d’exécution pour une requête donnée et utilisée pour identifier de manière unique des plans d’exécution semblables.
- Le hachage de requête est une valeur de hachage binaire calculée sur le texte Transact-SQL d’une requête qui est utilisée pour identifier de manière unique des requêtes.
Un plan compilé peut être récupéré à partir du cache du plan à l’aide d’un handle de plan. Il s’agit d’un identificateur temporaire qui reste constant uniquement pendant que le plan reste dans le cache. Le handle de plan est une valeur de hachage dérivée du plan compilé de l’ensemble du lot. Le handle de plan pour un plan compilé ne change pas même si une ou plusieurs instructions du lot sont recompilées.
Remarque
Si un plan a été compilé pour un lot plutôt que pour une instruction unique, le plan pour les instructions individuelles du lot peut être récupéré à l’aide du handle de plan et des décalages d’instructions.
La DMV sys.dm_exec_requests contient les colonnes statement_start_offset et statement_end_offset pour chaque enregistrement. Elles font référence à l’instruction en cours d’exécution d’un objet persistant ou d’un lot en cours d’exécution. Pour plus d’informations, consultez sys.dm_exec_requests (Transact-SQL).
La DMV sys.dm_exec_query_stats contient également ces colonnes pour chaque enregistrement. Elles font référence à la position d’une instruction dans un lot ou un objet persistant. Pour plus d’informations, consultez sys.dm_exec_query_stats (Transact-SQL).
Le texte Transact-SQL réel d’un lot est stocké dans un espace mémoire distinct du cache du plan, appelé cache SQL Manager (SQLMGR). Le texte Transact-SQL d’un plan compilé peut être récupéré à partir du cache SQL Manager à l’aide d’un handle SQL. Il s’agit d’un identificateur temporaire qui reste constant uniquement le temps qu’au moins un plan qui le référence reste dans le cache du plan. Le handle SQL est une valeur de hachage dérivée du texte de l’ensemble du lot et son unicité est garantie pour chaque lot.
Remarque
À l’instar d’un plan compilé, le texte Transact-SQL est stocké par lot, ce qui inclut les commentaires. Le handle SQL contient le hachage MD5 du texte de l’ensemble du lot et son unicité est garantie pour chaque lot.
La requête ci-dessous fournit des informations sur l’utilisation de la mémoire pour le cache SQL Manager :
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Il existe une relation 1:N entre un handle SQL et des handles de plan. Une telle condition se produit quand la clé de cache des plans compilés est différente. Cela peut être dû à un changement des options SET entre deux exécutions du même lot.
Examinez la procédure stockée suivante :
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Vérifiez ce qui se trouve dans le cache du plan en utilisant la requête ci-dessous :
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Voici le jeu de résultats.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Exécutez maintenant la procédure stockée avec un autre paramètre, mais n’apportez aucun autre changement au contexte d’exécution :
EXEC usp_SalesByCustomer 8
GO
Vérifiez à nouveau ce qui se trouve dans le cache du plan. Voici le jeu de résultats.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Notez que la valeur usecounts est passé à 2, ce qui signifie que le même plan mis en cache a été réutilisé tel quel, car les structures de données du contexte d’exécution ont été réutilisées. Changez maintenant l’option SET ANSI_DEFAULTS, puis exécutez la procédure stockée avec le même paramètre.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Vérifiez à nouveau ce qui se trouve dans le cache du plan. Voici le jeu de résultats.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Notez qu’il y a désormais deux entrées dans la sortie de la DMV sys.dm_exec_cached_plans :
- La colonne
usecountsindique la valeur1dans le premier enregistrement, qui est le plan exécuté une fois avecSET ANSI_DEFAULTS OFF. - La colonne
usecountsaffiche la valeur2dans le deuxième enregistrement, qui est le plan exécuté avecSET ANSI_DEFAULTS ON, car il a été exécuté deux fois. - La valeur
memory_object_addressdifférente fait référence à une entrée de plan d’exécution différente dans le cache du plan. Toutefois, la valeursql_handleest la même pour les deux entrées, car elles font référence au même lot.- L’exécution avec
ANSI_DEFAULTSdéfini sur OFF a un nouveauplan_handle, et il peut être réutilisé pour les appels qui ont le même ensemble d’options SET. Le nouveau handle de plan est nécessaire car le contexte d’exécution a été réinitialisé en raison d’options SET modifiées. Mais cela ne déclenche pas une recompilation : les deux entrées font référence au même plan et à la même requête, comme le prouvent les valeursquery_plan_hashetquery_hashidentiques.
- L’exécution avec
Cela signifie que nous avons, dans le cache, deux entrées de plan correspondant au même lot. Cela souligne l’importance de garantir que le cache du plan qui affecte les options SET est le même quand les mêmes requêtes sont exécutées à plusieurs reprises, afin d’optimiser la réutilisation du plan et de maintenir la taille du cache du plan à son minimum requis.
Conseil
Un piège courant est que différents clients peuvent avoir des valeurs par défaut différentes pour les options SET. Par exemple, une connexion effectuée par le biais de SQL Server Management Studio affecte automatiquement à QUOTED_IDENTIFIER la valeur ON, alors que SQLCMD définit QUOTED_IDENTIFIER sur OFF. L’exécution des mêmes requêtes à partir de ces deux clients donne lieu à plusieurs plans (comme décrit dans l’exemple ci-dessus).
Supprimer les plans d’exécution du cache du plan
Les plans d’exécution restent dans le cache du plan tant qu’il y a suffisamment de mémoire pour les stocker. En cas de sollicitation élevée de la mémoire, le moteur de base de données SQL Server utilise une approche basée sur les coûts pour identifier les plans d’exécution à supprimer du cache du plan. Pour prendre une décision basée sur les coûts, le moteur de base de données SQL Server augmente et diminue une variable de coût actuel pour chaque plan d’exécution en fonction des facteurs suivants.
Lorsqu'un processus utilisateur insère un plan d'exécution dans le cache, il définit le coût actuel de sorte qu'il soit égal au coût de compilation de la requête d'origine ; pour les plans d'exécution ad hoc, le processus utilisateur définit le coût actuel à zéro. Ensuite, chaque fois qu'un processus utilisateur fait référence à un plan d'exécution, il réinitialise le coût actuel au coût de compilation d'origine ; pour les plans d'exécution ad hoc, le processus utilisateur augmente le coût actuel. Pour tous les plans, la valeur maximale du coût actuel correspond au coût de compilation d'origine.
En cas de sollicitation élevée de la mémoire, le moteur de base de données SQL Server répond en supprimant des plans d’exécution du cache du plan. Pour identifier les plans à supprimer, le moteur de base de données SQL Server examine plusieurs fois l’état de chaque plan d’exécution et supprime des plans lorsque leur coût actuel est nul. Un plan d’exécution avec un coût nul n’est pas supprimé automatiquement en cas de sollicitation élevée de la mémoire ; il est supprimé uniquement lorsque le moteur de base de données SQL Server examine le plan et que son coût actuel est nul. Lors de l’examen d’un plan d’exécution, le moteur de base de données SQL Server pousse le coût actuel vers la valeur zéro en réduisant le coût actuel si aucune requête n’utilise actuellement le plan.
Le moteur de base de données SQL Server examine plusieurs fois les plans d’exécution jusqu’à ce que le nombre de plans supprimés soit suffisant pour répondre aux exigences mémoire. En cas de sollicitation élevée de la mémoire, un plan d'exécution peut voir son coût augmenter et diminuer à plusieurs reprises. Quand la mémoire n’est plus sollicitée, le moteur de base de données SQL Server cesse de réduire le coût actuel des plans d’exécution inutilisés et tous les plans d’exécution demeurent dans le cache du plan, même si leur coût est égal à zéro.
Le moteur de base de données SQL Server utilise le moniteur de ressources et des threads de travail utilisateur pour libérer de la mémoire dans le cache du plan en réponse à une sollicitation élevée de la mémoire. Le moniteur de ressources et les threads de travail utilisateur peuvent examiner les plans exécutés simultanément afin de réduire le coût actuel de chaque plan d’exécution inutilisé. Le moniteur de ressources supprime des plans d’exécution du cache du plan en cas de sollicitation élevée globale de la mémoire. Il libère de la mémoire afin d'appliquer les stratégies en matière de mémoire système, de mémoire de processus, de mémoire du pool de ressources et de taille maximale pour tous les caches.
La taille maximale de tous les caches dépend de la taille du pool de mémoires tampons et ne peut pas dépasser la quantité maximale de mémoire du serveur. Pour plus d’informations sur la configuration de la quantité maximale de mémoire du serveur, consultez le paramètre max server memory dans sp_configure.
Les threads de travail utilisateur suppriment des plans d’exécution du cache du plan en cas de sollicitation élevée de la mémoire d’un cache unique. Ils appliquent les stratégies de taille maximale de cache unique et de nombre maximal d'entrées de cache unique.
Les exemples suivants illustrent les plans d’exécution qui sont supprimés du cache du plan :
- Un plan d'exécution est fréquemment référencé de sorte que son coût n'est jamais égal à zéro. Le plan reste dans le cache du plan et n’est pas supprimé tant qu’il n’y a pas de sollicitation de la mémoire et que le coût actuel n’est pas égal à zéro.
- Un plan d'exécution ad hoc est inséré ; il n'est plus référencé tant que la mémoire n'est pas sollicitée de manière élevée. Dans la mesure où les plans d’exécution ad hoc sont initialisés avec un coût actuel égal à zéro, quand le moteur de base de données SQL Server examine le plan d’exécution, il constate que le coût actuel est égal à zéro et supprime le plan du cache du plan. Le plan d’exécution ad hoc reste dans le cache du plan avec un coût actuel égal à zéro en l’absence de sollicitation de la mémoire.
Pour supprimer manuellement un seul plan ou l’ensemble des plans du cache, utilisez DBCC FREEPROCCACHE. DBCC FREESYSTEMCACHE peut également servir à effacer tout cache, dont le cache du plan. À compter de SQL Server 2016 (13.x), utilisez ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE pour effacer le cache (du plan) de procédure pour la base de données dans l’étendue.
Une modification de certains paramètres de configuration via sp_configure et reconfigure entraîne également la suppression des plans du cache du plan. Vous trouverez la liste de ces paramètres de configuration dans la section Notes de l’article DBCC FREEPROCCACHE. Une modification de configuration telle que celle-ci consigne le message d’information suivant dans le journal des erreurs :
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Recompiler les plans d'exécution
Certaines modifications dans une base de données peuvent entraîner l'inefficacité ou la non-validité d'un plan d'exécution, selon le nouvel état de la base de données. SQL Server détecte les modifications qui rendent un plan d'exécution non valide et marque ce plan comme tel. Il faut donc recompiler un nouveau plan pour la prochaine connexion qui exécute la requête. Les conditions qui provoquent l'invalidité d'un plan sont les suivantes :
- Les modifications apportées à une table ou à une vue référencée par la requête (
ALTER TABLEetALTER VIEW). - Les modifications apportées à une seule procédure, ce qui supprimerait tous les plans de cette procédure dans le cache (
ALTER PROCEDURE). - Les modifications apportées à des index utilisés par le plan d'exécution.
- Les mises à jour de statistiques utilisées par le plan d’exécution, générées explicitement à partir d’une instruction, telle que
UPDATE STATISTICS, ou automatiquement. - La suppression d'un index utilisé par le plan d'exécution.
- Un appel explicite à
sp_recompile. - Un nombre important de modifications de clés (générées par les instructions
INSERTouDELETEdes autres utilisateurs qui modifient une table référencée par la requête). - Pour les tables contenant des déclencheurs, si le nombre de lignes des tables inserted ou deleted augmente de manière significative.
- L’exécution d’une procédure stockée à l’aide de l’option
WITH RECOMPILE.
La plupart des recompilations sont nécessaires pour que les instructions soient correctes ou pour obtenir des plans d'exécution de requête potentiellement plus rapides.
Dans les versions de SQL Server antérieures à la version 2005, chaque fois qu’une instruction d’un lot entraînait une recompilation, la totalité du lot était recompilée, qu’il soit soumis par le biais d’une procédure stockée, d’un déclencheur, d’un lot ad hoc ou d’une instruction préparée. À compter de SQL Server 2005 (9.x), seule l’instruction qui déclenche la recompilation dans le lot est recompilée. En outre, il existe davantage de types de recompilations dans SQL Server 2005 (9.x) et dans les versions ultérieures en raison de son ensemble de fonctionnalités étendu.
La recompilation de niveau instruction améliore les performances car, dans la plupart des cas, un nombre réduit d'instructions est à l'origine des recompilations et de leurs effets secondaires, en termes de temps processeur et de verrous. Par conséquent, ces effets épargnent les autres instructions du traitement qui n'ont pas besoin d'être recompilées.
L’événement sql_statement_recompile étendu (XEvent) signale les recompilations au niveau de l’instruction. Cet événement XEvent se produit lorsqu’une recompilation au niveau de l’instruction est requise par n’importe quel type de lot. Cela comprend les procédures stockées, les déclencheurs, les lots ad hoc et les requêtes. Les lots peuvent être envoyés par l’intermédiaire de plusieurs interfaces, notamment sp_executesql, SQL dynamique, ou des méthodes Prepare ou Execute.
La recompile_cause colonne de sql_statement_recompile XEvent contient un code entier qui indique la raison de la recompilation. Le tableau suivant contient les raisons possibles :
Schéma modifié
Statistiques modifiées
Compilation différée
Option SET modifiée
Table temporaire modifiée
Ensemble de lignes à distance modifié
AutorisationFOR BROWSE modifiée
Environnement de notification de requête modifié
Vue partitionnée modifiée
Options de curseur modifiées
OPTION (RECOMPILE) requis
Plan paramétré vidé
Plan affectant la version de base de données modifié
Stratégie de forçage de plan de Magasin des requêtes modifiée
Échec de forçage de plan de Magasin des requêtes
Plan manquant dans le Magasin des requêtes
Remarque
Dans les versions de SQL Server où XEvents ne sont pas disponibles, l’événement de trace SQL Server Profiler SP :Recompile peut être utilisé à la même fin que les recompilations au niveau de l’instruction de création de rapports.
L’événement de trace SQL:StmtRecompile signale également les recompilations au niveau de l’instruction, et vous pouvez aussi l’utiliser pour suivre et déboguer les recompilations.
Tandis que SP:Recompile est généré uniquement pour les procédures stockées et les déclencheurs, SQL:StmtRecompile est généré pour les procédures stockées, les déclencheurs, les lots ad hoc, les lots exécutés à l’aide de sp_executesql, les requêtes préparées et le code SQL dynamique.
La colonne EventSubClass de SP:Recompile et SQL:StmtRecompile contient un code entier qui indique la raison de la recompilation. Les codes sont décrits ici.
Remarque
Quand l’option de base de données AUTO_UPDATE_STATISTICS a pour valeur ON, les requêtes sont recompilées quand elles ciblent des tables ou des vues indexées dont les statistiques ont été mises à jour ou dont les cardinalités ont sensiblement évolué depuis la dernière exécution.
Ce comportement s’applique aux tables temporaires, aux tables définies par l’utilisateur standard, ainsi qu’aux tables inserted et deleted créées par des déclencheurs DML. Si les performances des requêtes sont affectées par des recompilations excessives, vous pouvez attribuer à ce paramètre la valeur OFF. Quand l’option de base de données AUTO_UPDATE_STATISTICS a pour valeur OFF, aucune recompilation ne se produit en fonction des statistiques ou des modifications de cardinalité, à l’exception des tables inserted et deleted qui sont créées par des déclencheurs DML INSTEAD OF. Comme ces tables sont créées dans tempdb, la recompilation de requêtes qui accèdent à ces tables dépend du paramétrage de AUTO_UPDATE_STATISTICS dans tempdb.
Dans les versions de SQL Server antérieures à la version 2005, la recompilation des requêtes se poursuit en fonction des modifications de cardinalité apportées aux tables « inserted » et « deleted » créées par des déclencheurs DML, même si ce paramètre a pour valeur OFF.
Réutilisation des paramètres et des plans d’exécution
L'utilisation de paramètres, notamment de marqueurs de paramètres dans les applications ADO, OLE DB et ODBC, peut favoriser la réutilisation des plans d'exécution.
Avertissement
L’utilisation de paramètres ou de marqueurs de paramètres pour la conservation des valeurs entrées par les utilisateurs finaux est plus fiable que la concaténation des valeurs dans une chaîne qui sera exécutée à l’aide de la méthode API d’accès aux données, à savoir l’instruction EXECUTE , ou de la procédure stockée sp_executesql .
La seule différence entre les deux instructions SELECT suivantes porte sur les valeurs comparées dans la clause WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
La seule différence entre les plans d’exécution de ces requêtes est la valeur stockée pour la comparaison avec la colonne ProductSubcategoryID . Bien que SQL Server soit conçu pour toujours reconnaître que les instructions génèrent essentiellement le même plan et réutilisent les plans, il peut arriver que SQL Server ne le détecte pas dans les instructions Transact-SQL complexes.
La séparation des constantes de l’instruction Transact-SQL à l’aide de paramètres permet au moteur relationnel de reconnaître plus facilement les plans en double. Vous pouvez utiliser les paramètres des manières suivantes :
Dans Transact-SQL, utilisez
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmCette méthode est recommandée pour les scripts Transact-SQL, les procédures stockées ou les déclencheurs SQL qui génèrent dynamiquement des instructions SQL.
ADO, OLE DB et ODBC utilisent des marqueurs de paramètres. Les marqueurs de paramètres sont des points d’interrogation ( ?) qui remplacent une constante dans une instruction SQL et sont liés à une variable de programme. Dans une application ODBC, vous pourriez par exemple procéder comme suit :
Permet
SQLBindParameterde lier une variable entière au premier marqueur de paramètre dans une instruction SQL.Placez la valeur de type entier dans la variable.
Exécutez l'instruction en spécifiant le marqueur de paramètres (?) :
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Le fournisseur OLE DB SQL Server Native Client et le pilote ODBC SQL Server Native Client fournis avec SQL Server utilisent
sp_executesqlpour envoyer des instructions à SQL Server lorsque les marqueurs de paramètres sont utilisés dans les applications.Pour concevoir des procédures stockées qui utilisent les paramètres par définition.
Si vous ne construisez pas explicitement des paramètres dans la conception de vos applications, vous pouvez toujours vous fier à l’optimiseur de requête SQL Server qui paramètre automatiquement certaines requêtes à l’aide du comportement par défaut de paramétrage simple. Vous pouvez également forcer l’optimiseur de requête à paramétrer l’ensemble des requêtes de la base de données en attribuant la valeur FORCED à l’option PARAMETERIZATION de l’instruction ALTER DATABASE.
En cas d’activation du paramétrage forcé, il est toujours possible d’utiliser le paramétrage simple. Par exemple, la requête suivante ne peut être paramétrée conformément aux règles de paramétrage forcé :
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Elle peut toutefois être paramétrée conformément aux règles de paramétrage simple. En cas de tentative infructueuse de paramétrage forcé, le paramétrage simple est activé.
Paramétrisation simple
Dans SQL Server, l’utilisation de paramètres ou de marqueurs de paramètres dans les instructions Transact-SQL augmente la capacité du moteur relationnel à associer les nouvelles instructions Transact-SQL aux plans d’exécution préalablement compilés existants.
Avertissement
L’utilisation de paramètres ou de marqueurs de paramètres pour la conservation des valeurs entrées par les utilisateurs finaux est plus fiable que la concaténation des valeurs dans une chaîne qui sera exécutée à l’aide de la méthode API d’accès aux données, à savoir l’instruction EXECUTE , ou de la procédure stockée sp_executesql .
Si vous exécutez une instruction Transact-SQL sans paramètres, SQL Server paramètre cette instruction en interne afin d’augmenter la possibilité de l’associer à un plan d’exécution existant. Ce processus est appelé « paramétrage simple ». Dans les versions de SQL Server antérieures à la version 2005, le processus était désigné par le terme « autoparamétrage ».
Imaginons l'instruction suivante :
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Vous pouvez spécifier comme paramètre la valeur 1 de la fin de l'instruction. Le moteur relationnel génère le plan d'exécution pour ce lot comme si un paramètre avait été spécifié au lieu de la valeur 1. En raison de ce paramétrage simple, SQL Server reconnaît que les deux instructions suivantes génèrent essentiellement le même plan d’exécution et réutilise le premier plan pour la deuxième instruction :
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Lors du traitement d’instructions Transact-SQL complexes, il est possible que le moteur relationnel rencontre certaines difficultés pour déterminer les expressions qui peuvent être paramétrables. Afin d’augmenter la capacité du moteur relationnel à associer des instructions Transact-SQL complexes à des plans d’exécution existants inutilisés, spécifiez les paramètres de manière explicite à l’aide de sp_executesql ou de marqueurs de paramètres.
Remarque
Lorsque les opérateurs arithmétiques +, -, *, /, ou % sont utilisés pour réaliser une conversion implicite ou explicite de valeurs constantes int, smallint, tinyint ou bigint pour les types de données float, real, decimal ou numeric, SQL Server applique des règles spécifiques pour calculer le type et la précision des résultats des expressions. Toutefois, ces règles diffèrent selon que la requête est paramétrable ou non. Par conséquent, dans certains cas, des expressions similaires dans les requêtes peuvent produire des résultats différents.
Avec le comportement par défaut du paramétrage simple, SQL Server paramètre une classe relativement réduite de requêtes. Toutefois, vous pouvez attribuer la valeur PARAMETERIZATION à l’option ALTER DATABASE de la commande FORCEDpour spécifier que toutes les requêtes d’une base de données soient paramétrables, sous réserve de certaines contraintes. Cette opération peut améliorer les performances des bases de données soumises à des volumes élevés de requêtes simultanées en réduisant la fréquence des compilations de requête.
Une autre solution consiste à spécifier que ne soient paramétrables qu'une requête et toutes autres requêtes dont la syntaxe ne se différencie que par les valeurs des paramètres.
Conseil
Avec une solution de mapping objet-relationnel (ORM, Object-Relational Mapping) telle qu’Entity Framework (EF), les requêtes d’application comme les arborescences de requêtes LINQ manuelles ou certaines requêtes SQL brutes peuvent ne pas être paramétrables, ce qui a un impact sur la réutilisation des plans et la possibilité d’effectuer un suivi des requêtes dans le Magasin des requêtes. Pour plus d’informations, consultez Mise en cache et paramétrage des requêtes EF et Requêtes SQL EF brutes.
Paramétrisation forcée
Vous pouvez remplacer le comportement de paramétrage simple par défaut de SQL Server en spécifiant que toutes les instructions SELECT, INSERT, UPDATEet DELETE de la base de données soient paramétrables dans certaines limites. Le paramétrage forcé s’active en attribuant la valeur PARAMETERIZATION à l’option FORCED dans l’instruction ALTER DATABASE . La paramétrisation forcée peut améliorer les performances de certaines bases de données en réduisant la fréquence des compilations et recompilations des requêtes. Les bases de données qui peuvent tirer profit du paramétrage forcé sont généralement des bases de données devant gérer un nombre important de requêtes simultanées émanant de sources telles que des applications de point de vente.
Lorsque l’option PARAMETERIZATION a la valeur FORCED, toute valeur littérale apparaissant dans une instruction SELECT, INSERT, UPDATEou DELETE , dans n’importe quel format, est convertie en paramètre au moment de la compilation de la requête. Les littéraux apparaissant dans les constructions de requêtes suivantes font toutefois exception :
- Instructions
INSERT...EXECUTE. - Les instructions internes au corps de procédures stockées, de déclencheurs ou de fonctions définies par l’utilisateur. SQL Server réutilise les plans de requête pour ces routines.
- Les instructions préparées ayant déjà été paramétrées dans l'application cliente.
- Les instructions contenant des appels de méthode XQuery, où la méthode apparaît dans un contexte nécessitant généralement que ses arguments soient paramétrés (clause
WHERE, par exemple). Si la méthode figure dans un contexte où le paramétrage de ses arguments n'est pas requis, le reste de l'instruction est paramétré. - Instructions à l’intérieur d’un curseur Transact-SQL. (Les instructions
SELECTà l’intérieur des curseurs API sont paramétrables.) - Constructions de requêtes déconseillées.
- Toute instruction exécutée dans le contexte de
ANSI_PADDINGouANSI_NULLSayant la valeurOFF. - Les instructions contenant plus de 2 097 littéraux pouvant être paramétrables.
- Les instructions faisant référence à des variables comme
WHERE T.col2 >= @bb. - Les instructions contenant l’indicateur de requête
RECOMPILE. - Les instructions contenant une clause
COMPUTE. - Les instructions contenant une clause
WHERE CURRENT OF.
En outre, les clauses de requête suivantes ne sont pas paramétrables. Dans de tels cas, seules les clauses ne sont pas paramétrables. D'autres clauses au sein de la même requête peuvent être l'objet d'un paramétrage forcé.
- <select_list> d’une instruction
SELECT. Notamment les listesSELECTdes sous-requêtes et les listesSELECTdes instructionsINSERT. - Les instructions
SELECTde sous-requêtes apparaissant dans une instructionIF. - Les clauses
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOouFOR XMLd’une requête. - Les arguments, qu’il s’agisse d’un argument direct ou d’une sous-expression, des opérateurs
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLouFULLTEXT. - Les arguments pattern et escape_character d’une clause
LIKE. - L’argument style d’une clause
CONVERT. - Les constantes entières d’une clause
IDENTITY. - Les constantes spécifiées à l'aide de la syntaxe d'extension ODBC.
- Les expressions de constantes pouvant être évaluées lors de la compilation et qui sont des arguments des opérateurs
+,-,*,/et%. Lors de l’examen d’un paramétrage forcé éventuel, SQL Server considère qu’une expression est constituée de constantes pouvant être évaluées lors de la compilation lorsque l’une des conditions suivantes est vraie :- l'expression ne contient pas de colonnes, de variables ou de sous-requêtes ;
- l’expression contient une clause
CASE.
- Les arguments des clauses d'indicateur de requête. Notamment l’argument number_of_rows de l’indicateur de requête
FAST, l’argument number_of_processors de l’indicateur de requêteMAXDOPet l’argument number de l’indicateur de requêteMAXRECURSION.
Le paramétrage est effectué au niveau des instructions Transact-SQL individuelles. En d'autres termes, les instructions individuelles d'un traitement sont paramétrables. Une fois la compilation terminée, la requête paramétrable est exécutée dans le contexte du traitement pour lequel elle a été initialement soumise. Dans le cas d’un plan d’exécution mis en cache, vous pouvez déterminer si la requête a été paramétrée en référençant la colonne sql de la vue de gestion dynamique sys.syscacheobjects. Si la requête est paramétrable, les noms et les types de données des paramètres sont spécifiés avant le texte de chaque lot soumis dans cette colonne, par exemple (@1 tinyint).
Remarque
Les noms des paramètres sont arbitraires. Les utilisateurs et les applications ne doivent par conséquent pas se fier à un ordre particulier d'affectation des noms. En outre, les éléments suivants peuvent varier dans les versions de SQL Server et les mises à niveau des Service Packs : les noms des paramètres, le choix des littéraux paramétrés et l’espacement dans le texte paramétré.
Types de données des paramètres
Lorsque SQL Server paramètre des littéraux, les paramètres sont convertis dans les types de données suivants :
- Les littéraux entiers dont la taille correspondrait en d’autres circonstances au type de données int sont paramétrés sur int. Les littéraux de taille plus importante qui font partie d’un prédicat impliquant un opérateur de comparaison quelconque (notamment
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEEN, etIN) sont paramétrés sur numeric(38,0). Les littéraux de taille plus importante qui ne font pas partie d’un prédicat impliquant un opérateur de comparaison sont paramétrés sur numeric dont la précision suffit à prendre en charge leur taille et dont l’échelle correspond à 0. - Les littéraux numériques à virgule fixe qui font partie d’un prédicat impliquant un opérateur de comparaison sont paramétrés sur numeric dont la précision est de 38 et dont l’échelle suffit à prendre en charge leur taille. Les littéraux numériques à virgule fixe qui ne font pas partie d’un prédicat impliquant un opérateur de comparaison sont paramétrés sur numeric dont la précision et l’échelle suffisent à prendre en charge leur taille.
- Les littéraux numériques à virgule flottante sont paramétrés sur float(53).
- Les littéraux de chaîne non-Unicode sont paramétrés sur varchar(8000) lorsqu’ils comptent moins de 8 000 caractères et sur varchar(max) lorsqu’ils en comptent plus de 8 000.
- Les littéraux de chaîne Unicode sont paramétrés sur nvarchar(4000) lorsqu’ils comptent moins de 4 000 caractères Unicode et sur nvarchar(max) lorsqu’ils en comptent plus de 4 000.
- Les littéraux binaires sont paramètres en varbinary(8000) si le littéral n’excède pas 8 000 octets. S’il dépasse 8 000 octets, il est converti en varbinary(max).
- Les littéraux de type monétaire sont paramétrés sur money.
Principes d'utilisation du paramétrage forcé
Lorsque vous affectez à l’option PARAMETERIZATION la valeur FORCED, tenez compte des points suivants :
- Le paramétrage forcé convertit les constantes des littéraux d'une requête en paramètres lors de la compilation d'une requête. Par conséquent, l'optimiseur de requête peut opter pour des plans d'exécution de requêtes non optimisés. Plus spécifiquement, il est moins probable que l'optimiseur de requête établisse une correspondance avec une vue indexée ou un index d'une colonne calculée. Il peut également opter pour des plans non optimisés dans le cas de requêtes soumises pour des tables partitionnées ou des vues partitionnées et distribuées. Il n'est pas recommandé d'utiliser le paramétrage forcé dans des environnements reposant principalement sur des vues indexées ou des index de colonnes calculées. Dans l’ensemble, l’option
PARAMETERIZATION FORCEDdevrait être utilisée exclusivement par des administrateurs de bases de données expérimentés qui se seront assurés que cela n’affectera pas les performances. - Les requêtes distribuées qui font référence à plusieurs bases de données sont éligibles pour le paramétrage forcé pour autant que l’option
PARAMETERIZATIONait la valeurFORCEDdans la base de données dont le contexte fait l’objet de la requête. - L’affectation de la valeur
PARAMETERIZATIONà l’optionFORCEDvide tous les plans de requêtes du cache de plans d’une base de données, à l’exception de ceux qui sont en cours de compilation, de recompilation ou d’exécution. Tout plan d'une requête en cours de compilation ou d'exécution lors de la modification des paramètres est paramétré lors de la prochaine exécution de la requête. - La définition de l’option
PARAMETERIZATIONest une opération en ligne qui ne requiert aucun verrou exclusif au niveau de la base de données. - Le paramètre actuel de l’option
PARAMETERIZATIONest conservé en cas de rattachement ou de restauration d’une base de données.
Pour remplacer le comportement de paramétrage forcé, il suffit de spécifier qu'un paramétrage simple soit tenté sur une requête unique, à l'instar des autres requêtes de syntaxe équivalente mais présentant des valeurs de paramètres différentes. À l'inverse, vous pouvez spécifier que le paramétrage forcé soit tenté sur seul jeu de requêtes de syntaxe équivalente, même en cas de désactivation de l'option de paramétrage forcé dans la base de données. Vous pouvez utiliser lesrepères de plan à cet effet.
Remarque
Quand l’option PARAMETERIZATION est définie avec la valeur FORCED, le rapport des messages d’erreur peut ne pas être le même que quand l’option PARAMETERIZATION est définie avec la valeur SIMPLE : davantage de messages d’erreur peuvent être signalés avec le paramétrage forcé qu’avec le paramétrage simple et les numéros de ligne où interviennent les erreurs peuvent ne pas être corrects.
Préparation des instructions SQL
Le moteur relationnel de SQL Server permet la prise en charge intégrale de la préparation des instructions Transact-SQL avant leur exécution. Si une application doit exécuter une instruction Transact-SQL plusieurs fois, elle peut recourir à l’API de base de données pour effectuer les opérations suivantes :
- Préparer l'instruction en une seule fois. L’instruction Transact-SQL est compilée dans un plan d’exécution.
- Exécuter le plan d'exécution précompilé chaque fois qu'elle doit exécuter l'instruction. Cela évite de recompiler l’instruction Transact-SQL après chaque exécution suivant la première. La préparation et l'exécution des instructions sont contrôlées par les fonctions et les méthodes API. Ceci ne fait pas partie du langage Transact-SQL. Le modèle de préparation et d’exécution des instructions Transact-SQL est pris en charge par le fournisseur OLE DB SQL Server Native Client et par le pilote ODBC SQL Server Native Client. Lors d’une demande de préparation, le fournisseur ou le pilote envoie l’instruction à SQL Server avec une demande de préparation de l’instruction. SQL Server compile un plan d’exécution et retourne un descripteur de ce plan au fournisseur ou au pilote. Pour toute requête d'exécution, le fournisseur ou le pilote envoie au serveur une requête d'exécution du plan associé au descripteur.
Les instructions préparées ne peuvent pas être utilisées pour la création d’objets temporaires dans SQL Server. Elles ne peuvent pas faire référence à des procédures stockées du système qui créent des objets temporaires, tels que des tables temporaires. Ces procédures doivent être exécutées directement.
L'utilisation excessive du modèle de préparation et d'exécution peut nuire aux performances. Si une instruction n'est exécutée qu'une seule fois, son exécution directe ne requiert qu'un seul aller-retour au serveur. La préparation suivie de l’exécution unique d’une instruction Transact-SQL nécessite un aller-retour supplémentaire : un pour préparer l’instruction et un pour l’exécuter.
La préparation d'une instruction est plus efficace si vous utilisez les marqueurs de paramètres. Par exemple, supposons que vous demandez occasionnellement à une application d’extraire des informations sur un produit à partir de l’exemple de base de données AdventureWorks . Il existe deux moyens pour y arriver :
Premièrement, l'application peut exécuter une requête différente pour chaque produit demandé :
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Deuxièmement, l'application peut procéder comme suit :
Préparer une instruction contenant un marqueur de paramètres (?) :
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Lier une variable de programme au marqueur de paramètres.
Chaque fois que vous avez besoin d'informations sur un produit, l'application remplit la variable liée avec la valeur de la clé et exécute l'instruction.
La seconde méthode est plus efficace lorsque l'instruction est exécutée plus de trois fois.
Dans SQL Server, le modèle de préparation et d’exécution présente très peu d’avantages en terme de performances par rapport à l’exécution directe en raison du mode de réutilisation des plans d’exécution par SQL Server. SQL Server intègre des algorithmes efficaces associant les instructions Transact-SQL actuelles aux plans d’exécution générés pour des exécutions antérieures de la même instruction Transact-SQL. Si une application exécute plusieurs fois une instruction Transact-SQL avec des marqueurs de paramètres, SQL Server réutilisera le plan d’exécution de la première exécution pour les exécutions suivantes (sauf si le plan a été supprimé du cache du plan suite à son expiration). Le modèle de préparation et d'exécution offre encore d'autres avantages :
- La recherche d’un plan d’exécution à l’aide d’un descripteur d’identification est plus efficace que les algorithmes utilisés pour associer une instruction Transact-SQL à des plans d’exécution existants.
- L'application peut contrôler le moment où le plan d'exécution est créé et réutilisé.
- Le modèle de préparation et d’exécution peut être transféré à d’autres bases de données, y compris des versions antérieures de SQL Server.
Sensibilité du paramètre
La sensibilité du paramètre, aussi appelée « détection de paramètres », fait référence à un processus par lequel SQL Server « espionne » les valeurs de paramètres actuelles pendant la compilation ou la recompilation, et les transmet à l’optimiseur de requête afin qu’elles puissent servir à générer des plans d’exécution de requête potentiellement plus efficaces.
Les valeurs de paramètres sont détectées pendant la compilation ou la recompilation pour les types de lots suivants :
- Procédures stockées
- Requêtes soumises via
sp_executesql - Requêtes préparées
Pour plus d’informations sur la résolution des problèmes de détection de paramètres incorrects, consultez :
- Examinez et résolvez les problèmes de sensibilité aux paramètres.
- Réutilisation des paramètres et des plans d’exécution
- Optimisation du plan de sensibilité aux paramètres
- Résoudre les problèmes des requêtes relatifs aux plans d’exécution des requêtes sensible aux paramètres dans la base de données Azure SQL
- Résoudre les problèmes des requêtes relatifs aux plans d’exécution des requêtes sensible aux paramètres dans Azure SQL Managed Instance
Remarque
Pour les requêtes utilisant l’indicateur RECOMPILE, les valeurs de paramètres et les valeurs actuelles des variables locales sont détectées. Les valeurs détectées (des paramètres et variables locales) sont celles présentes dans le lot juste avant l’instruction avec l’indicateur RECOMPILE. Pour les paramètres en particulier, les valeurs fournies avec l’appel du lot ne sont pas détectées.
Traitement de requêtes en parallèle
SQL Server permet les requêtes parallèles afin d’optimiser leur exécution et les opérations d’index sur les ordinateurs dotés de plusieurs processeurs (ou unités centrales). Comme SQL Server peut exécuter une requête ou une opération d’index en parallèle à l’aide de plusieurs threads de travail du système d’exploitation, l’opération peut être exécutée rapidement et efficacement.
Durant l’optimisation, SQL Server recherche les requêtes ou les opérations d’index qui pourraient tirer profit d’une exécution en parallèle. Pour ces requêtes, SQL Server insère des opérateurs d’échange dans le plan d’exécution de la requête afin de la préparer à l’exécution en parallèle. Un opérateur d'échange est un opérateur dans un plan d'exécution de requêtes qui assure la gestion du processus, la redistribution des données et le contrôle de flux. L’opérateur d’échange inclut les opérateurs logiques Distribute Streams, Repartition Streamset Gather Streams comme sous-types, qui peuvent apparaître dans la sortie Showplan du plan de requête d’une requête parallèle.
Important
Certaines constructions empêchent SQL Server de faire usage du parallélisme sur tout ou partie du plan d’exécution.
Les constructions qui empêchent le parallélisme sont les suivantes :
Fonctions UDF scalaires
Pour plus d’informations sur les fonctions scalaires définies par l’utilisateur, consultez Créer des fonctions définies par l’utilisateur. Depuis SQL Server 2019 (15.x), le moteur de base de données SQL Server a la possibilité d’incorporer ces fonctions et de débloquer l’utilisation du parallélisme pendant le traitement des requêtes. Pour plus d’informations sur l’incorporation (inlining) de fonctions UDF scalaires, consultez Traitement de requêtes intelligent dans les bases de données SQL.Remote Query
Pour plus d’informations sur Remote Query, consultez Guide de référence des opérateurs Showplan logiques et physiques.Curseurs dynamiques
Pour plus d’informations sur les curseurs, consultez DECLARE CURSOR.Requêtes récursives
Pour plus d’informations sur la récursivité, consultez Principes de définition et d’utilisation des expressions de table communes récursives et Recursion in T-SQL.Fonctions table à instructions multiples (MSTVF)
Pour plus d’informations sur les MSTVF, consultez Créer des fonctions définies par l’utilisateur (moteur de base de données).Mot clé TOP
Pour plus d’informations, consultez TOP (Transact-SQL).
Un plan d’exécution de requête peut contenir l’attribut NonParallelPlanReason dans l’élément QueryPlan qui décrit pourquoi le parallélisme n’a pas été utilisé. Les valeurs de cet attribut peuvent notamment être les suivantes :
| NonParallelPlanReason Valeur | Description |
|---|---|
| MaxDOPSetToOne | Degré maximal de parallélisme défini sur 1. |
| EstimatedDOPIsOne | Le degré de parallélisme estimé est de 1. |
| NoParallelWithRemoteQuery | Le parallélisme n’est pas pris en charge pour les requêtes distantes. |
| NoParallelDynamicCursor | Plans parallèles non pris en charge pour les curseurs dynamiques. |
| NoParallelFastForwardCursor | Plans parallèles non pris en charge pour les curseurs d’avance rapide. |
| NoParallelCursorFetchByBookmark | Plans parallèles non pris en charge pour les curseurs extraits par signet. |
| NoParallelCreateIndexInNonEnterpriseEdition | La création d’index parallèles n’est pas prise en charge pour les éditions hors Entreprise. |
| NoParallelPlansInDesktopOrExpressEdition | Plans parallèles non pris en charge pour les éditions Desktop et Express. |
| NonParallelizableIntrinsicFunction | La requête fait référence à une fonction intrinsèque non parallélisable. |
| CLRUserDefinedFunctionRequiresDataAccess | Parallélisme non pris en charge pour une fonction CLR définie par l’utilisateur qui requiert l’accès aux données. |
| TSQLUserDefinedFunctionsNotParallelizable | La requête fait référence à une fonction T-SQL définie par l’utilisateur qui n’était pas parallélisable. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | Les transactions de variable de table ne prennent pas en charge les transactions imbriquées parallèles. |
| DMLQueryReturnsOutputToClient | La requête DML retourne la sortie au client et n’est pas parallélisable. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | Combinaison non prise en charge de plans série et parallèle pour une seule génération d’index en ligne. |
| CouldNotGenerateValidParallelPlan | Échec de la vérification du plan parallèle, rétablissement en série. |
| NoParallelForMemoryOptimizedTables | Parallélisme non pris en charge pour les tables OLTP en mémoire référencées. |
| NoParallelForDmlOnMemoryOptimizedTable | Parallélisme non pris en charge pour DML sur une table OLTP en mémoire. |
| NoParallelForNativelyCompiledModule | Parallélisme non pris en charge pour les modules référencés compilés en mode natif. |
| NoRangesResumableCreate | Échec de la génération de la plage pour une opération de création pouvant être reprise. |
Une fois les opérateurs d'échange insérés, vous obtenez un plan d'exécution de requêtes en parallèle. Un plan d’exécution de requêtes en parallèle peut utiliser plusieurs threads de travail. Un plan d’exécution en série utilisé par requête (série) non parallèle n’utilise qu’un seul thread de travail pour son exécution. Le nombre réel de threads de travail utilisés par une requête parallèle est déterminé au moment de l’initialisation de l’exécution du plan de requête et dépend de la complexité et du degré de parallélisme du plan.
Le degré de parallélisme détermine le nombre maximal de processeurs (UC) utilisés ; il n’indique pas le nombre de threads de travail utilisés. La limite de degré de parallélisme est définie par tâche. Il ne s’agit pas d’une limite par demande ou par requête. Cela signifie que lors d’une exécution de requête parallèle, une requête unique peut générer plusieurs tâches qui sont affectées à un planificateur. Il est possible que plus de processeurs que le nombre spécifié par MAXDOP soient utilisés à un moment donné de l’exécution de la requête, quand différentes tâches sont exécutées simultanément. Pour plus d’informations, consultez le Guide de l’architecture des threads et des tâches.
L’optimiseur de requête SQL Server n’utilise pas de plan d’exécution parallèle pour une requête si l’une des conditions suivantes est vraie:
- Le plan d’exécution en série est trivial ou ne dépasse pas le seuil de coût pour le paramètre de parallélisme.
- Le plan d’exécution en série a un coût de sous-arborescence estimé inférieur à n’importe quel plan d’exécution parallèle exploré par l’optimiseur.
- La requête contient des opérateurs scalaires ou relationnels qui ne peuvent être exécutés en parallèle. Certains opérateurs peuvent entraîner l'exécution d'une section du plan de requête ou de la totalité du plan en mode série.
Remarque
Le coût total estimé de sous-arborescence d’un plan parallèle peut être inférieur au seuil de coût du paramètre de parallélisme. Cela indique que le coût total estimé de sous-arborescence du plan en série l’a dépassé et que le plan de requête avec le coût total estimé inférieur de sous-arborescence a été choisi.
Degré de parallélisme (DOP)
SQL Server détecte automatiquement le meilleur degré de parallélisme pour chaque instance d’une exécution de requête en parallèle ou d’une opération DDL (Data Definition Language) d’index. Cette détection se fait sur la base des critères suivants :
SQL Server fonctionne sur un ordinateur doté de plusieurs microprocesseurs ou UC, tel qu’un ordinateur à multitraitement symétrique (SMP, symmetric multiprocessing). Seuls les ordinateurs dotés de plusieurs UC peuvent utiliser des requêtes en parallèle.
Si le nombre de threads de travail disponibles est suffisant. Chaque requête ou opération d’index nécessite un certain nombre de threads de travail. Pour être exécuté, un plan parallèle nécessite plus de threads de travail qu’un plan série, le nombre de threads de travail nécessaires allant de pair avec le degré de parallélisme. Quand les threads de travail disponibles sont insuffisants pour un certain degré de parallélisme, le moteur de base de données SQL Server diminue automatiquement le degré de parallélisme ou abandonne complètement le plan parallèle dans le contexte de charge de travail spécifié. Ensuite, il exécute le plan série (un thread de travail).
Le type de requête ou d’opération d’index exécuté. Les requêtes qui utilisent fortement les cycles microprocesseur et les opérations d'index qui créent ou reconstruisent un index, ou qui suppriment un index cluster, sont les candidates idéales pour un plan parallèle. Par exemple, les jointures de grandes tables, les agrégations importantes et le tri d'ensembles de résultats volumineux s'y prêtent bien. Pour les requêtes simples, typiques des applications de traitement de transactions, il s'avère que la coordination supplémentaire nécessaire à l'exécution d'une requête en parallèle n'est pas rentabilisée par l'augmentation potentielle des performances. Pour faire la distinction entre les requêtes qui tirent profit du parallélisme et les autres, le moteur de base de données SQL Server compare le coût estimé de l’exécution de la requête ou de l’opération d’index à la valeur cost threshold for parallelism. L’utilisateur peut changer la valeur par défaut (5) à l’aide de sp_configure si un test approprié a révélé qu’une valeur différente est mieux adaptée pour la charge de travail en cours d’exécution.
S’il y a un nombre suffisant de lignes à traiter. Si l'optimiseur de requête détermine que le nombre de lignes est trop faible, il n'introduit pas les opérateurs d'échange qui servent à distribuer les lignes. Par conséquent, ces opérateurs sont exécutés en série. L'exécution des opérateurs dans un plan série permet d'éviter que les coûts de démarrage, de distribution et de coordination dépassent les bénéfices d'une exécution en parallèle.
Si des statistiques de distribution actuelles sont disponibles. Si ce niveau ne peut être atteint, le moteur de base de données envisage de passer à un degré inférieur avant d'abandonner totalement le plan parallèle. Par exemple, lorsque vous créez un index cluster sur une vue, les statistiques de distribution ne peuvent pas être prises en compte étant donné que l'index en question n'existe pas encore. Dans ce cas, le moteur de base de données SQL Server est incapable de garantir le degré de parallélisme le plus élevé pour l’opération d’index. Toutefois, certains opérateurs, tels que le tri et l'analyse, peuvent malgré tout bénéficier de l'exécution en parallèle.
Remarque
Les opérations d’index parallèles ne sont disponibles que dans les éditions Entreprise, Developer et Evaluation de SQL Server.
Lors de l’exécution, le moteur de base de données SQL Server détermine si la charge de travail actuelle du système et les informations de configuration décrites ci-dessus permettent une exécution parallèle. Si c’est le cas, le moteur de base de données SQL Server détermine le nombre optimal de threads de travail et répartit l’exécution du plan parallèle parmi ces derniers. Quand une requête ou une opération d’index commence à s’exécuter en parallèle sur plusieurs threads de travail, un nombre identique de threads de travail est utilisé jusqu’à ce que l’opération soit terminée. Le moteur de base de données SQL Server réexamine le nombre optimal de threads de travail chaque fois qu’un plan d’exécution est récupéré à partir du cache du plan. Par exemple, la première exécution d’une requête peut nécessiter l’utilisation d’un plan série, la deuxième d’un plan parallèle et de trois threads de travail, et la troisième exécution d’un plan parallèle et de quatre threads.
Les opérateurs Update et Delete d’un plan d’exécution de requêtes parallèles sont exécutés en série, mais la clause WHERE d’une instruction UPDATE ou DELETE peut être exécutée en parallèle. Les modifications réelles des données sont ensuite appliquées en série à la base de données.
Jusqu’à SQL Server 2012 (11.x), l’opérateur Insert est également exécuté en série. Toutefois, la partie SELECT d’une instruction INSERT peut être exécutée en parallèle. Les modifications réelles des données sont ensuite appliquées en série à la base de données.
À partir de SQL Server 2014 (12.x) et du niveau de compatibilité de base de données 110, l’instruction SELECT ... INTO peut être exécutée en parallèle. D’autres formes d’opérateurs d’insertion fonctionnent de la même façon que celle décrite pour SQL Server 2012 (11.x).
À partir de SQL Server 2016 (13.x) et du niveau de compatibilité de la base de données 130, l’instruction INSERT ... SELECT peut être exécutée en parallèle lors de l’insertion dans des segments de mémoire ou des index columnstore en cluster (ICC) et à l’aide de l’indicateur TABLOCK. Les insertions dans les tables temporaires locales (identifiées par le préfixe #) et les tables temporaires globales (identifiées par les préfixes ##) sont également activées pour le parallélisme à l’aide de l’indicateur TABLOCK. Pour plus d’informations, consultez INSERT (Transact-SQL).
Les curseurs statiques et les curseurs pilotés par jeux de clés peuvent être complétés par des plans d'exécution parallèle. Cependant, le comportement des curseurs dynamiques ne peut être fourni que par une exécution en série. L'optimiseur de requête génère toujours un plan d'exécution en série pour une requête qui fait partie d'un curseur dynamique.
Remplacer les degrés de parallélisme
Le degré maximal de parallélisme définit le nombre de processeurs à utiliser lors l’exécution des plans parallèles. Cette configuration peut être définie à différents niveaux :
Au niveau du serveur, avec l’option de configuration du serveur Degré maximal de parallélisme (MAXDOP).
S’applique à : SQL ServerRemarque
SQL Server 2019 (15.x) offre désormais des recommandations automatiques pour la définition de l’option de configuration du serveur MAXDOP lors du processus d’installation. L’interface utilisateur du programme d’installation vous permet d’accepter les paramètres recommandés ou d’entrer vos propres valeurs. Pour plus d’informations, consultez la page Configuration du moteur de base de données - MaxDOP.
Au niveau de la charge de travail, avec l’option de configuration de groupe de charges de travail MAX_DOP Resource Governor.
S’applique à : SQL ServerAu niveau de la base de données, avec la configuration étendue à la base de données MAXDOP.
S’applique à : SQL Server et la base de données Azure SQLAu niveau de l’instruction de requête ou d’index, avec l’indicateur de requête MAXDOP ou option d’index MAXDOP. Par exemple, vous pouvez utiliser l’option MAXDOP pour contrôler (à savoir augmenter ou réduire) le nombre de processeurs alloués à une opération d’index en ligne. Ceci vous permet d’équilibrer les ressources utilisées par une opération d’index et celles des utilisateurs simultanés.
S’applique à : SQL Server et Azure SQL Database
L’attribution de la valeur 0 (valeur par défaut) à l’option Degré maximal de parallélisme permet à SQL Server d’utiliser tous les processeurs disponibles, jusqu’à 64, dans une exécution de plan parallèle. Bien que SQL Server définisse une cible d’exécution de 64 processeurs logiques quand l’option MAXDOP a la valeur 0, une autre valeur peut être définie manuellement si nécessaire. Attribuer la valeur 0 à MAXDOP pour les requêtes et les index permet à SQL Server d’utiliser tous les processeurs disponibles, 64 au maximum, pour les requêtes ou les index donnés dans une exécution de plan parallèle. MAXDOP n’est pas une valeur appliquée pour toutes les requêtes parallèles, mais plutôt une cible provisoire pour toutes les requêtes éligibles pour le parallélisme. Cela signifie que si le nombre de threads de travail disponibles n’est pas suffisant au moment de l’exécution, une requête peut s’exécuter avec un degré de parallélisme inférieur à l’option MAXDOP.
Conseil
Pour plus d’informations, consultez les recommandations MAXDOP pour obtenir des instructions sur la configuration de MAXDOP au niveau du serveur, de la base de données, de la requête ou de l’indicateur.
Exemple de requête en parallèle
La requête suivante compte le nombre de commandes passées dans le courant du trimestre débutant le 1er avril 2000, dont au moins un poste a été livré au client à une date postérieure à la date prévue. Cette requête affiche le nombre de ce type de commandes groupées par priorité de commande et triées en ordre de priorité croissant.
Cet exemple utilise des noms de tables et de colonnes théoriques.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Supposons que les index suivants soient définis dans les tables lineitem et orders :
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Voici un plan d'exécution en parallèle possible, généré pour la requête illustrée précédemment :
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
L’illustration ci-après montre un plan de requête exécuté avec un degré de parallélisme de 4 et comprenant une jointure entre deux tables.
Le plan en parallèle comprend trois opérateurs de parallélisme. L’opérateur Index Seek de l’index o_datkey_ptr et l’opérateur Index Scan de l’index l_order_dates_idx sont exécutés en parallèle, ce qui produit plusieurs flux exclusifs. Cela peut être déterminé à partir des opérateurs Parallelism les plus proches des opérateurs Index Scan et Index Seek, respectivement. Dans les deux cas, le type d'échange est repartitionné. En d'autres termes, les données sont tout simplement distribuées aux flux en produisant le même nombre de flux en sortie qu'en entrée. Ce nombre de flux est égal au degré de parallélisme.
L’opérateur de parallélisme qui se trouve au-dessus de l’opérateur L_ORDERKEY Index Scan repartitionne ses flux d’entrée en utilisant la valeur de l_order_dates_idx comme clé. De cette façon, toutes les valeurs identiques de L_ORDERKEY se retrouvent dans un même flux de sortie. Au même moment, les flux de sortie gèrent l’ordre de la colonne L_ORDERKEY afin qu’elle réponde aux conditions d’entrée de l’opérateur Merge Join.
L’opérateur de parallélisme qui se trouve au-dessus de l’opérateur Index Seek repartitionne ses flux d’entrée en utilisant la valeur de O_ORDERKEY. Étant donné que son entrée n’est pas triée dans les valeurs de la colonne O_ORDERKEY et qu’il s’agit de la colonne de jointure de l’opérateur Merge Join, l’opérateur Sort qui se trouve entre les opérateurs de parallélisme et Merge Join s’assure que l’entrée est triée pour l’opérateur Merge Join dans les colonnes de jointure. L’opérateur Sort, tout comme l’opérateur Merge Join, est exécuté en parallèle.
Le premier opérateur de parallélisme rassemble les résultats de plusieurs flux en un seul flux. Les agrégations partielles effectuées par l’opérateur Stream Aggregate situé sous l’opérateur de parallélisme sont ensuite accumulées dans une seule valeur SUM pour chaque valeur différente de O_ORDERPRIORITY dans l’opérateur Stream Aggregate qui se trouve au-dessus de l’opérateur de parallélisme. Étant donné que le plan comporte deux segments d’échange avec un degré de parallélisme de 4, il utilise huit threads de travail.
Pour plus d’informations sur les opérateurs utilisés dans cet exemple, consultez le Guide de référence des opérateurs Showplan logiques et physiques.
Opérations d'indexation parallèles
Les plans de requête générés pour les opérations d’index qui créent ou régénèrent un index, ou suppriment un index cluster, autorisent les opérations multithread parallèles sur des ordinateurs dotés de plusieurs microprocesseurs.
Remarque
Les opérations d’index parallèles sont uniquement disponibles dans Enterprise Edition, à compter de SQL Server 2008 (10.0.x).
SQL Server utilise les mêmes algorithmes pour déterminer le degré de parallélisme (le nombre total de threads de travail séparés à exécuter) des opérations d’index, comme il le fait pour les autres instructions. Le degré maximal de parallélisme pour une opération d’index est fonction de l’option de configuration de serveur max degree of parallelism . Vous pouvez remplacer la valeur de max degree of parallelism pour des opérations d’index particulières en définissant l’option d’index MAXDOP dans les instructions CREATE INDEX, ALTER INDEX, DROP INDEX et ALTER TABLE.
Lorsque le moteur de base de données SQL Server génère un plan d’exécution d’index, le nombre d’opérations parallèles est défini sur la valeur la plus faible parmi les suivantes :
- Nombre d'UC dans l'ordinateur
- Nombre spécifié dans l’option de configuration de serveur max degree of parallelism
- nombre de processeurs (UC) ne dépassant pas déjà un seuil de travail effectué pour les threads de travail de SQL Server.
Par exemple, sur un ordinateur doté de huit UC, mais où max degree of parallelism a la valeur 6, pas plus de six threads de travail parallèles sont générés pour une création d’index. Si cinq des UC de l’ordinateur ont déjà dépassé le seuil de travail SQL Server lors de la création d’un plan d’exécution d’index, ce dernier spécifie uniquement trois threads de travail parallèles.
Les phases principales d'une opération d'index parallèle sont les suivantes :
- Un thread de travail de coordination analyse rapidement et de façon aléatoire la table pour évaluer la distribution des clés d’index. Le threadde travail de coordination établit les limites des clés qui créeront un nombre de plages de clés égal au degré d’opérations parallèles, où chaque plage de clés est évaluée pour couvrir des nombres de lignes similaires. Par exemple, si la table comporte quatre millions de lignes et que le degré de parallélisme est de 4, le thread de travail de coordination détermine les valeurs de clé qui délimitent quatre ensembles de lignes avec un million de lignes dans chaque ensemble. Si un nombre suffisant de plages de clés ne peut être établi pour l'utilisation de toutes les UC, le degré de parallélisme est réduit en conséquence.
- Le thread de travail de coordination répartit un nombre de threads de travail égal au degré d’opérations parallèles, et attend que ces threads de travail terminent leur travail. Chaque thread de travail analyse la table de base en utilisant un filtre qui extrait uniquement les lignes avec des valeurs de clé situées dans la plage affectée au thread de travail. Chaque thread de travail construit une structure d’index pour les lignes contenues dans sa plage de clés. Dans le cas d’un index partitionné, chaque thread de travail génère un nombre spécifié de partitions. Les partitions ne sont pas partagées entre les threads de travail.
- Une fois que tous les threads de travail parallèles ont été exécutés, le thread de travail de coordination connecte les sous-unités d’index dans un index unique. Cette phase s'applique uniquement aux opérations d'index hors ligne.
Les instructions CREATE TABLE ou ALTER TABLE individuelles peuvent avoir plusieurs contraintes imposant la création d’un index. Ces opérations de création d'index multiples sont exécutées en série, bien que chaque opération de création d'index individuelle puisse être une opération parallèle sur un ordinateur doté de plusieurs UC.
Architecture des requêtes distribuées
Microsoft SQL Server prend en charge deux méthodes distinctes pour référencer des sources de données OLE DB hétérogènes dans les instructions Transact-SQL :
Noms de serveurs liés
Les procédures stockées systèmesp_addlinkedserveretsp_addlinkedsrvloginservent à donner un nom de serveur à une source de données OLE DB. Les objets inclus dans ces serveurs liés peuvent être référencés dans des instructions Transact-SQL en utilisant un nom en quatre parties. Par exemple, si le nom d’un serveur liéDeptSQLSrvrest défini par rapport à une autre instance de SQL Server, l’instruction suivante fait référence à une table de ce serveur :SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Le nom de serveur lié peut également être spécifié dans une instruction
OPENQUERYafin d’ouvrir un ensemble de lignes à partir d’une source de données OLE DB. Cet ensemble de lignes peut ensuite être référencé en tant que table dans les instructions Transact-SQL.Noms de connecteurs appropriés
Dans le cas de références rares à une source de données, la fonctionOPENROWSETouOPENDATASOURCEest spécifiée avec les informations nécessaires à la connexion au serveur lié. Il est donc possible de faire référence à l’ensemble de lignes comme à une table dans les instructions Transact-SQL :SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server utilise OLE DB pour la communication entre le moteur relationnel et le moteur de stockage. Le moteur relationnel décompose chaque instruction Transact-SQL en une série d’opérations sur des ensembles de lignes OLE DB simples ouverts par le moteur de stockage à partir des tables de base. En d'autres termes, le moteur relationnel peut également ouvrir des ensembles de lignes OLE DB simples dans n'importe quelle source de données OLE DB.
Le moteur relationnel utilise l'API OLE DB pour ouvrir les ensembles de lignes sur les serveurs liés, pour extraire les lignes et pour gérer les transactions.
Pour chaque source de données OLE DB à laquelle vous accédez en tant que serveur lié, un fournisseur OLE DB doit être présent sur le serveur exécutant SQL Server. L’ensemble d’opérations Transact-SQL qui peut être utilisé sur une source de données OLE DB spécifique dépend des capacités du fournisseur OLE DB.
Pour chaque instance de SQL Server, les membres du rôle serveur fixe sysadmin peuvent activer ou désactiver l’utilisation de noms de connecteurs ad hoc pour un fournisseur OLE DB à l’aide de la propriété DisallowAdhocAccess SQL Server. Si l’accès approprié est activé, tout utilisateur connecté à cette instance peut exécuter des instructions Transact-SQL contenant des noms de connecteurs appropriés, en faisant référence à n’importe quelle source de données sur le réseau accessible par le biais du fournisseur OLE DB. Afin de contrôler l’accès aux sources de données, les membres du rôle sysadmin peuvent désactiver l’accès ad hoc pour ce fournisseur OLE DB, limitant ainsi l’accès des utilisateurs aux sources de données référencées par les noms de serveurs liés définis par les administrateurs. Par défaut, ce type d’accès ad hoc est activé pour le fournisseur OLE DB pour SQL Server, mais désactivé pour tous les autres fournisseurs OLE DB.
Les requêtes distribuées permettent aux utilisateurs d’accéder à une autre source de données (par exemple, des fichiers, des sources de données non relationnelles telles que Active Directory, etc.) par le biais du contexte de sécurité du compte Microsoft Windows sous lequel le service SQL Server s’exécute. SQL Server emprunte l’identité de la connexion appropriée aux connexions Windows ; cet emprunt ne peut cependant pas être effectué pour les connexions SQL Server. Ceci permet d’autoriser éventuellement l’utilisateur d’une requête distribuée à accéder à une autre source de données pour laquelle il ne bénéficie pas de droits d’accès, mais où le compte sous lequel le service SQL Server s’exécute dispose des autorisations appropriées. Utilisez la procédure stockée sp_addlinkedsrvlogin afin de définir les connexions spécifiques autorisées à accéder au serveur lié correspondant. Ce type de contrôle n'est pas ouvert aux noms appropriés. Il est donc impératif d'activer un fournisseur OLE DB pour un accès approprié avec précaution.
Lorsque c’est possible, SQL Server envoie les opérations relationnelles telles que les jointures, les restrictions, les projections, les tris ou les regroupements à la source de données OLE DB. SQL Server n’analyse pas par défaut la table de base dans SQL Server et n’assure pas les opérations relationnelles de son propre chef. SQL Server interroge le fournisseur OLE DB afin de déterminer le niveau de grammaire SQL et, en fonction de ces informations, envoie autant d’opérations relationnelles que possible au fournisseur.
SQL Server spécifie un mécanisme permettant à un fournisseur OLE DB de renvoyer des statistiques indiquant comment les valeurs clés sont distribuées dans la source de données OLE DB. Cela permet à l’optimiseur de requête SQL Server de mieux analyser le modèle de données dans la source de données par rapport aux exigences spécifiques à chaque instruction Transact-SQL, augmentant ainsi sa capacité à générer des plans d’exécution optimaux.
Améliorations du traitement des requêtes sur les tables et les index partitionnés
SQL Server 2008 (10.0.x) a amélioré les performances du traitement des requêtes sur les tables partitionnées pour de nombreux plans parallèles, modifié la façon dont les plans parallèles et en série sont représentés, et amélioré les informations de partitionnement fournies dans les plans d’exécution de compilation et au moment de l’exécution. Cette article décrit ces améliorations, fournit des indications sur la façon d'interpréter les plans d'exécution de requêtes de tables et d'index partitionnés, et fournit des recommandations pour améliorer les performances des requêtes sur les objets partitionnés.
Remarque
Jusqu’à SQL Server 2014 (12.x), les tables et les index partitionnés sont uniquement pris en charge dans les éditions Enterprise, Developer et Evaluation de SQL Server. À compter de SQL Server 2016 (13.x) SP1, les tables et index partitionnés sont également pris en charge dans l’édition SQL Server Standard.
Nouvelle opération de recherche sensible aux partitions
Dans SQL Server, la représentation interne d’une table partitionnée est modifiée afin que la table apparaisse au processeur de requêtes sous forme d’un index multicolonne avec PartitionID comme colonne principale. PartitionID est une colonne calculée cachée utilisée en interne pour représenter l’ ID de la partition contenant une ligne spécifique. Supposons, par exemple, que la table T définie comme T(a, b, c)est partitionnée sur la colonne a et possède un index cluster sur la colonne b. Dans SQL Server, cette table partitionnée est traitée en interne comme une table non partitionnée, avec le schéma T(PartitionID, a, b, c) et un index cluster sur la clé composite (PartitionID, b). Cela permet à l’optimiseur de requête d’effectuer des opérations de recherche basées sur PartitionID sur n’importe quel table ou index partitionné.
L'élimination de partition est maintenant réalisée dans cette opération de recherche.
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (comme colonne principale logique) et éventuellement d'autres colonnes clés d'index, puis une recherche de second niveau, avec une condition différente, peut être réalisée sur une ou plusieurs colonnes supplémentaires, pour chaque valeur distincte répondant à la qualification de l'opération de recherche de premier niveau. Autrement dit, cette opération, appelée analyse par saut, permet à l’optimiseur de requête d’effectuer une opération de recherche ou d’analyse basée sur une condition pour déterminer à quelles partitions accéder et une opération de recherche d’index de second niveau au sein de cet opérateur pour retourner les lignes de ces partitions qui répondent à une condition différente. Examinez, par exemple, la requête suivante.
SELECT * FROM T WHERE a < 10 and b = 2;
Dans cet exemple, supposons que la table T définie comme T(a, b, c)est partitionnée sur la colonne a et possède un index cluster sur la colonne b. Les limites de partition pour la table T sont définies par la fonction de partition suivante :
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Pour résoudre la requête, le processeur de requêtes effectue une opération de recherche de premier niveau pour rechercher chaque partition contenant des lignes répondant à la condition T.a < 10. Cela identifie les partitions à accéder. Dans chaque partition identifiée, le processeur effectue ensuite une recherche de second niveau dans l’index cluster sur la colonne b pour rechercher les lignes qui répondent aux conditions T.b = 2 et T.a < 10.
L'illustration suivante est une représentation logique de l'opération d'analyse par saut. Elle montre la table T avec des données dans les colonnes a et b. Les partitions sont numérotées de 1 à 4 et les limites de partition sont indiquées par des lignes verticales en pointillé. Une opération de recherche de premier niveau dans les partitions (non représentée dans l'illustration) a déterminé que les partitions 1, 2 et 3 répondent à la condition de recherche impliquée par le partitionnement défini pour la table et le prédicat sur la colonne a. À savoir, T.a < 10. Le chemin d'accès parcouru par la partie de la recherche de second niveau de l'opération d'analyse par saut est illustré par la ligne courbée. Fondamentalement, l'opération d'analyse par saut recherche dans chacune de ces partitions les lignes qui répondent à la condition b = 2. Le coût total de l'opération d'analyse par saut est le même que celui de trois recherches d'index séparées.
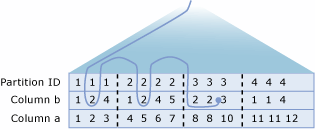
Affichage d'informations de partitionnement dans les plans d'exécution de requêtes
Les plans d’exécution de requêtes sur les tables et les index partitionnés peuvent être examinés en utilisant les instructions SET Transact-SQL SET SHOWPLAN_XML ou SET STATISTICS XML, ou en utilisant la sortie du plan d’exécution graphique dans SQL Server Management Studio. Par exemple, vous pouvez afficher le plan d’exécution de compilation en sélectionnant Afficher le plan d’exécution estimé dans la barre d’outils de l’éditeur de requête et le plan au moment de l’exécution en sélectionnant Inclure le plan d’exécution réel.
À l'aide de ces outils, vous pouvez déterminer les informations suivantes :
- les opérations telles que
scans,seeks,inserts,updates,mergesetdeletesqui accèdent aux tables ou aux index partitionnés ; - les partitions auxquelles accède la requête (par exemple, le nombre total de partitions ayant fait l'objet d'un accès et les plages de partitions contiguës qui font l'objet d'un accès sont disponibles dans les plans au moment de l'exécution) ;
- lorsque l'opération d'analyse par saut est utilisée dans une opération de recherche ou d'analyse pour récupérer les données d'une ou de plusieurs partitions.
Améliorations apportées aux informations de partition
SQL Server fournit des informations de partitionnement améliorées pour les plans d’exécution de compilation et au moment de l’exécution. Les plans d'exécution fournissent désormais les informations suivantes :
- Un attribut
Partitionedfacultatif qui indique qu’un opérateur, tel queseek,scan,insert,update,mergeoudelete, est effectué sur une table partitionnée. - Un nouvel élément
SeekPredicateNewavec un sous-élémentSeekKeysqui inclutPartitionIDcomme la colonne clé d’index principale et des conditions de filtrage qui spécifient les recherches de plage surPartitionID. La présence de deux sous-élémentsSeekKeysindique qu’une opération d’analyse par saut surPartitionIDest utilisée. - Des informations de résumé qui indiquent le nombre total de partitions ayant fait l'objet d'un accès. Ces informations sont uniquement disponibles dans les plans au moment de l'exécution.
Pour démontrer comment ces informations sont affichées dans la sortie du plan d’exécution graphique et dans la sortie du plan d’exécution de requêtes XML, considérez la requête suivante sur la table partitionnée fact_sales. Cette requête met à jour les données dans deux partitions.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
L’illustration suivante montre les propriétés de l’opérateur Clustered Index Seek dans le plan d’exécution du runtime pour cette requête. Pour examiner la définition de la table fact_sales et la définition de la partition, consultez la section « Exemple » dans cette article.

Attribut partitionné
Quand un opérateur comme Index Seek est exécuté sur une table ou un index partitionné, l’attribut Partitioned apparaît dans le plan au moment de la compilation et au moment de l’exécution, et a pour valeur True (1). L'attribut ne s'affiche pas lorsqu'il a pour valeur False (0).
L’attribut Partitioned peut apparaître dans les opérateurs physiques et logiques suivants :
- Table Scan
- Index Scan
- Index Seek
- Insérer
- Update
- Delete
- Fusionner (Merge)
Comme indiqué dans l'illustration précédente, cet attribut est affiché dans les propriétés de l'opérateur dans lequel il est défini. Dans la sortie du plan d’exécution XML, cet attribut apparaît comme Partitioned="1" dans le nœud RelOp de l’opérateur dans lequel il est défini.
Nouveau prédicat de recherche
Dans la sortie du plan d’exécution XML, l’élément SeekPredicateNew apparaît dans l’opérateur dans lequel il est défini. Il peut contenir jusqu’à deux occurrences du sous-élément SeekKeys. Le premier élément SeekKeys spécifie l’opération de recherche de premier niveau au niveau de l’ID de partition de l’index logique. Autrement dit, cette recherche détermine les partitions qui doivent être faire l'objet d'un accès pour satisfaire aux conditions de la requête. Le deuxième élément SeekKeys spécifie la partie de la recherche de second niveau de l’opération d’analyse par saut qui se produit dans chaque partition identifiée dans la recherche de premier niveau.
Informations de résumé sur les partitions
Dans les plans au moment de l'exécution, les informations de résumé sur les partitions fournissent le nombre des partitions ayant fait l'objet d'un accès et l'identité des partitions ayant réellement fait l'objet d'un accès. Vous pouvez utiliser ces informations pour vérifier que la requête accède aux bonnes partitions et que toutes les autres partitions sont ignorées.
Les informations suivantes sont fournies : Actual Partition Countet Partitions Accessed.
Actual Partition Count est le nombre total de partitions auxquelles la requête a accédé.
Partitions Accessed, dans la sortie du plan d’exécution XML, correspond aux informations de résumé sur les partitions qui apparaissent dans le nouvel élément RuntimePartitionSummary dans le nœud RelOp de l’opérateur dans lequel il est défini. L’exemple suivant affiche le contenu de l’élément RuntimePartitionSummary , indiquant que deux partitions au total font l’objet d’un accès (partitions 2 et 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Affichage d'informations sur les partitions en utilisant d'autres méthodes de plan d'exécution de requêtes
Les méthodes de plan d’exécution de requêtes SHOWPLAN_ALL, SHOWPLAN_TEXTet STATISTICS PROFILE ne signalent pas les informations sur les partitions décrites dans cet article, avec toutefois l’exception suivante. Dans le cadre du prédicat SEEK , les partitions devant faire l’objet d’un accès sont identifiées par un prédicat de plage sur la colonne calculée qui représente l’ID de partition. L’exemple suivant affiche le prédicat SEEK pour un opérateur Clustered Index Seek . Les partitions 2 et 3 font l'objet d'un accès et l'opérateur de recherche filtre les lignes qui répondent à la condition date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpréter les plans d'exécution pour les segments de mémoire partitionnés
Un segment de mémoire partitionné est traité comme un index logique sur l’ID de partition. Une élimination de partition sur un segment de mémoire partitionné est représentée dans un plan d’exécution en tant qu’opérateur Table Scan avec un prédicat SEEK sur l’ID de partition. L’exemple suivant illustre les informations du plan d’exécution de requêtes fournies :
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpréter les plans d'exécution pour les jointures en colocation
La colocation de jointure peut se produire lorsque deux tables sont partitionnées à l'aide de la même fonction de partitionnement ou d'une fonction de partitionnement équivalente et que les colonnes de partitionnement des deux côtés de la jointure sont spécifiées dans la condition de jointure de la requête. L'optimiseur de requête peut générer un plan où les partitions de chaque table avec des ID de partition identiques sont jointes séparément. Les jointures en colocation peuvent être plus rapides que les autres jointures car elles peuvent nécessiter moins de mémoire et occasionner un temps de traitement inférieur. L’optimiseur de requête choisit un plan en colocation ou non en fonction des estimations de coût.
Dans un plan en colocation, la jointure Nested Loops lit une ou plusieurs partitions de table ou d’index jointes en interne. Les nombres dans les opérateurs Constant Scan représentent les numéros de partition.
Lorsque des plans parallèles pour des jointures en colocation sont générés pour des tables ou des index partitionnés, un opérateur Parallelism apparaît entre les opérateurs de jointure Constant Scan et Nested Loops . Dans ce cas, chacun des threads de travail du côté extérieur de la jointure lit et opère sur une partition distincte.
L'illustration suivante montre un plan de requête parallèle pour une jointure en colocation.
Stratégie d'exécution de requête parallèle pour les objets partitionnés
Le processeur de requêtes utilise une stratégie d'exécution parallèle pour les requêtes qui sélectionnent parmi des objets partitionnés. Dans le cadre de la stratégie d’exécution, le processeur de requêtes détermine les partitions de table requises pour la requête et la proportion de threads de travail à allouer à chaque partition. Dans la plupart des cas, le processeur de requêtes alloue un nombre de threads de travail égal ou presque égal à chaque partition, puis il exécute la requête en parallèle sur les partitions. Les paragraphes suivants expliquent l’allocation des threads de travail de manière détaillée.
Si le nombre de threads de travail est inférieur au nombre de partitions, le processeur de requêtes affecte chaque thread de travail à une partition différente, laissant initialement une ou plusieurs partitions sans thread de travail affecté. Quand un thread de travail a fini de s’exécuter sur une partition, le processeur de requêtes l’assigne à la partition suivante jusqu’à ce qu’un seul thread de travail ait été assigné à chaque partition. Il s’agit du seul cas dans lequel le processeur de requêtes réaffecte des threads de travail à d’autres partitions.
Montre le thread de travail réaffecté une fois terminé. Si le nombre de threads de travail est égal au nombre de partitions, le processeur de requêtes assigne un thread de travail à chaque partition. Quand un thread de travail se termine, il n’est pas réassigné à une autre partition.

Si le nombre de threads de travail est supérieur au nombre de partitions, le processeur de requêtes alloue une quantité égale de threads de travail à chaque partition. Si le nombre de threads de travail n’est pas un multiple exact du nombre de partitions, le processeur de requêtes alloue un thread de travail supplémentaire à certaines partitions afin d’utiliser tous les threads de travail disponibles. S’il n’y a qu’une seule partition, tous les threads de travail sont assignés à cette partition. Dans le schéma ci-dessous, il y a quatre partitions et 14 threads de travail. Trois threads de travail sont assignés à chaque partition et deux partitions ont un thread de travail supplémentaire, pour un total de 14 affectations de threads de travail. Quand un thread de travail se termine, il n’est pas réassigné à une autre partition.

Bien que les exemples ci-dessus suggèrent une méthode simple pour allouer des threads de travail, la stratégie réelle est plus complexe et prend en considération d’autres variables durant l’exécution de la requête. Par exemple, si la table est partitionnée et a un index cluster sur la colonne A et qu’une requête a la clause de prédicat WHERE A IN (13, 17, 25), le processeur de requêtes alloue un ou plusieurs threads de travail à chacune de ces trois valeurs de recherche (A=13, A=17 et A=25) au lieu de chaque partition de table. Il est nécessaire d’exécuter la requête uniquement dans les partitions qui contiennent ces valeurs, et si tous ces prédicats de recherche se trouvent être dans la même partition de table, tous les threads de travail sont assignés à la même partition de table.
Pour prendre un autre exemple, supposons que la table a quatre partitions sur la colonne A avec des points de limite (10, 20, 30), un index sur la colonne B, et que la requête a une clause de prédicat WHERE B IN (50, 100, 150). Les partitions de table étant basées sur les valeurs de A, les valeurs de B peuvent se produire dans chacune des partitions de table. Par conséquent, le processeur de requêtes recherche chacune des trois valeurs de B (50, 100, 150) dans chacune des quatre partitions de table. Le processeur de requêtes assignera des threads de travail proportionnellement afin de pouvoir exécuter chacune de ces 12 analyses de requête en parallèle.
| Partitions de table basées sur la colonne A | Recherches pour la colonne B dans chaque partition de table |
|---|---|
| Partition de table 1 : A < 10 | B=50, B=100, B=150 |
| Partition de table 2 : A >= 10 AND A < 20 | B=50, B=100, B=150 |
| Partition de table 3 : A >= 20 AND A < 30 | B=50, B=100, B=150 |
| Partition de table 4 : A >= 30 | B=50, B=100, B=150 |
Bonnes pratiques
Pour améliorer les performances des requêtes qui accèdent à une grande quantité de données à partir de tables et d'index partitionnés volumineux, nous vous recommandons d'appliquer les méthodes conseillées suivantes :
- Agrégez par bandes chaque partition sur plusieurs disques. Cette opération est particulièrement appropriée quand vous utilisez des disques de rotation.
- Dans la mesure du possible, utilisez un serveur avec suffisamment de mémoire principale pour prendre en charge les partitions faisant l'objet d'un accès fréquent ou toutes les partitions afin de réduire le coût des E/S.
- Si les données que vous interrogez ne tiennent pas en mémoire, compressez les tables et les index. Cela réduira le coût des E/S.
- Utilisez un serveur avec des processeurs rapides et autant de noyaux de processeur que^possible selon vos moyens pour tirer parti des capacités de traitement de requête parallèle.
- Assurez-vous que le serveur possède une bande passante de contrôleur d'E/S suffisante.
- Créez un index cluster sur chaque grande table partitionnée pour tirer parti des optimisations d'analyse d'arbre B (B-tree).
- Appliquez les recommandations mentionnées dans le livre blanc « The Data Loading Performance Guide» lors du chargement en masse des données dans des tables partitionnées.
Exemple
L'exemple suivant crée une base de données de test contenant une table unique avec sept partitions. Utilisez les outils décrits précédemment lors de l'exécution des requêtes dans cet exemple pour afficher des informations de partitionnement pour le plan de compilation et le plan au moment de l'exécution.
Remarque
Cet exemple insère plus d'un million de lignes dans la table. En fonction de votre matériel, l'exécution de cet exemple peut prendre plusieurs minutes. Avant d'exécuter cet exemple, vérifiez que l'espace disque dont vous disposez est supérieur à 1,5 Go.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Contenu connexe
- Guide de référence des opérateurs Showplan logiques et physiques
- Aperçu des événements étendus
- Meilleures pratiques pour la supervision des charges de travail avec le Magasin des requêtes
- Estimation de la cardinalité (SQL Server)
- Traitement de requêtes intelligent dans les bases de données SQL
- Priorités des opérateurs (Transact-SQL)
- Vue d’ensemble du plan d’exécution
- Centre de performances pour le moteur de base de données SQL Server et Azure SQL Database