नोट
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप साइन इन करने या निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
आवश्यकताओं की समीक्षा करने के बाद, आप अपना दस्तावेज़ प्रसंस्करण मॉडल बनाना शुरू कर सकते हैं।
विज़ार्ड के साथ अपना मॉडल बनाएं
आप कस्टम मॉडल बनाएँ विज़ार्ड का उपयोग करके दस्तावेज़ प्रसंस्करण मॉडल बना सकते हैं. यह विज़ार्ड आपको दस्तावेज़ों से जानकारी निकालने के लिए मॉडल बनाने की प्रक्रिया में मार्गदर्शन करता है।
लॉग इन करें Power Apps या Power Automate.
बाएँ फलक पर, ... अधिक >AI हब का चयन करें.
(वैकल्पिक) आसान पहुंच के लिए मेनू पर AI मॉडल को स्थायी रूप से रखने के लिए, AI हब के बगल में पिन आइकन का चयन करें।
AI क्षमता खोजें के अंतर्गत, AI मॉडल चुनें.
दस्तावेजों से कस्टम जानकारी निकालें का चयन करें.
कस्टम मॉडल बनाएँ चुनें.
एक चरण-दर-चरण विज़ार्ड आपको प्रक्रिया के माध्यम से मार्गदर्शन करता है तथा आपसे आपके दस्तावेज़ से निकाले जाने वाले सभी डेटा की सूची बनाने के लिए कहता है।
इस लेख के दस्तावेज़ का प्रकार चुनें अनुभाग में अधिक जानें.
यदि आप अपने स्वयं के दस्तावेज़ों का उपयोग करके अपना मॉडल बनाना चाहते हैं, तो सुनिश्चित करें कि आपके पास कम से कम पांच उदाहरण हैं जो समान लेआउट का उपयोग करते हैं। अन्यथा, आप मॉडल बनाने के लिए नमूना डेटा का उपयोग कर सकते हैं।
ट्रेन का चयन करें.
त्वरित परीक्षण का चयन करके मॉडल का परीक्षण करें.
दस्तावेज़ का प्रकार चुनें
दस्तावेज़ प्रकार चुनें चरण पर, डेटा निष्कर्षण को स्वचालित करने के लिए AI मॉडल बनाने के लिए आप जिस दस्तावेज़ प्रकार को चाहते हैं उसे चुनें। तीन विकल्प हैं: निश्चित टेम्पलेट दस्तावेज़, सामान्य दस्तावेज़, और चालान.

- निश्चित टेम्पलेट दस्तावेज़: पहले इसे संरचित के रूप में जाना जाता था, यह विकल्प तब आदर्श होता है, जब किसी दिए गए लेआउट के लिए, फ़ील्ड, तालिकाएँ, चेकबॉक्स, हस्ताक्षर और अन्य आइटम समान स्थानों पर पाए जा सकते हैं। आप इस मॉडल को अलग-अलग लेआउट वाले संरचित दस्तावेज़ों से डेटा निकालना सिखा सकते हैं। इस मॉडल का प्रशिक्षण समय त्वरित है।
- सामान्य दस्तावेज़: पहले इसे असंरचित के रूप में जाना जाता था, यह विकल्प किसी भी प्रकार के दस्तावेज़ों के लिए आदर्श है, विशेष रूप से जब कोई निर्धारित संरचना न हो, या जब प्रारूप जटिल हो। आप इस मॉडल को अलग-अलग लेआउट वाले संरचित या असंरचित दस्तावेज़ों से डेटा निकालना सिखा सकते हैं। यह मॉडल शक्तिशाली है, लेकिन इसका प्रशिक्षण समय लम्बा है।
- चालान: डिफ़ॉल्ट फ़ील्ड के अतिरिक्त निकाले जाने वाले नए फ़ील्ड जोड़कर या उचित रूप से न निकाले गए दस्तावेज़ों के नमूने जोड़कर पूर्वनिर्मित चालान प्रसंस्करण मॉडल के व्यवहार को बढ़ाएं।...
दस्तावेज़ इंटेलिजेंस संस्करणों को समझें
दस्तावेज़ इंटेलिजेंस मॉडल दो संस्करणों में उपलब्ध है: v4.0 और v3.1. आपके मॉडल का संस्करण इस बात पर निर्भर करता है कि आपने मॉडल को अंतिम बार कब संपादित किया था।
दस्तावेज़ इंटेलिजेंस v4.0 - सामान्य उपलब्धता (GA)
इस आलेख में सूचीबद्ध सुविधाओं के अतिरिक्त, v4.0 में v3.1 की सभी क्षमताएं बरकरार हैं।
- ओवरलैपिंग फ़ील्ड: v4.0 कस्टम मॉडल में ओवरलैपिंग फ़ील्ड का समर्थन करता है, जो आपको जटिल लेआउट वाले दस्तावेज़ों से अधिक प्रभावी ढंग से जानकारी निकालने देता है।
- हस्ताक्षर पहचान: v4.0 दस्तावेजों में हस्ताक्षरों का पता लगाता है, जो विशेष रूप से अनुबंधों, समझौतों और अन्य हस्ताक्षरित प्रपत्रों के लिए उपयोगी है।
- तालिकाओं के लिए विश्वास स्कोर: v4.0 तालिका और उनके कक्षों के लिए विश्वास स्कोर प्रदान करता है।
- OCR इंजन में सुधार: v4.0 ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR) इंजन में सुधार करता है, पाठ पहचान सटीकता को बढ़ाता है और अधिक दस्तावेज़ प्रकारों और प्रारूपों का समर्थन करता है।
दस्तावेज़ इंटेलिजेंस v3.1 सामान्य उपलब्धता (GA)
- v3.1 विशिष्ट डेटा पैटर्न, जैसे अद्वितीय टेक्स्ट फ़ील्ड या संरचनाओं को पहचानने के लिए प्रशिक्षित कस्टम मॉडल का समर्थन करता है।
- v3.1 में कस्टम टेम्पलेट मॉडल शामिल हैं जो उपयोगकर्ताओं को उनके दस्तावेज़ लेआउट और संरचना के आधार पर टेम्पलेट बनाने की सुविधा देते हैं।
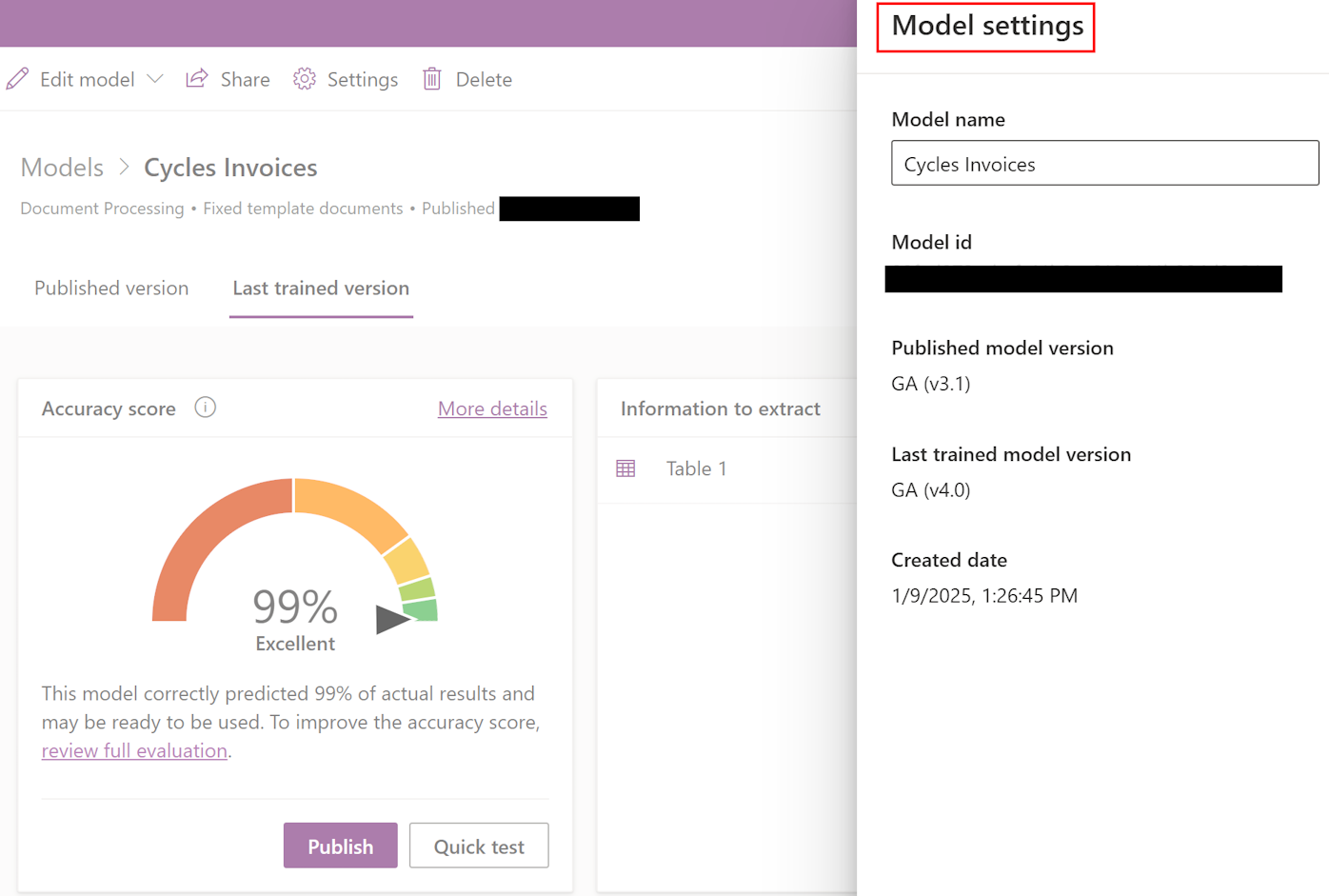
मॉडल संस्करण की जाँच करें
आप अपने मॉडल को प्रशिक्षित करने और प्रकाशित करने के लिए उपयोग किए गए संस्करण को सत्यापित कर सकते हैं। ऐसा करने के लिए, सेटिंग्स>प्रकाशित मॉडल संस्करण>अंतिम प्रशिक्षित मॉडल संस्करण का चयन करें।
आप किसी मॉडल को संपादित, पुनः प्रशिक्षित और प्रकाशित करके उसे v3.1 से v4.0 में स्थानांतरित कर सकते हैं। पुनः टैगिंग और अन्य विशिष्ट संशोधन आवश्यक नहीं हैं। दस्तावेज़ प्रसंस्करण के लिए अक्सर पूछे जाने वाले प्रश्न में अधिक जानें .
निकालने के लिए जानकारी परिभाषित करें
निकालने के लिए जानकारी चुनें स्क्रीन पर, उन फ़ील्ड, तालिकाओं और चेकबॉक्स को परिभाषित करें जिन्हें आप अपने मॉडल को निकालना सिखाना चाहते हैं। इन्हें परिभाषित करने के लिए, +Add का चयन करें.
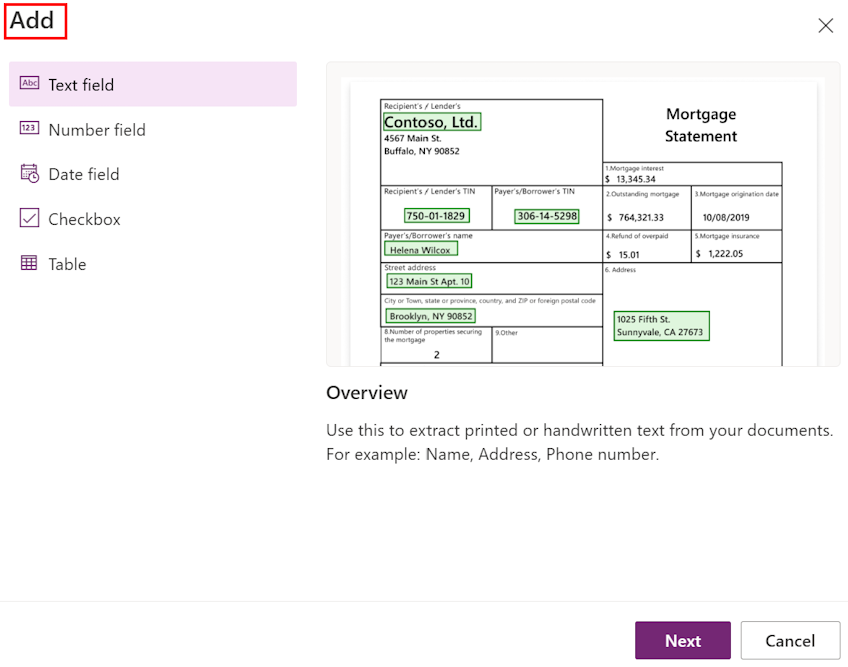
प्रत्येक पाठ फ़ील्ड के लिए, मॉडल में उपयोग करने हेतु फ़ील्ड का नाम प्रदान करें।
प्रत्येक संख्या फ़ील्ड के लिए, मॉडल में उपयोग करने हेतु फ़ील्ड का नाम प्रदान करें.
दशमलव विभाजक के रूप में प्रारूप बिंदु (.) या अल्पविराम (,) को परिभाषित करें।
प्रत्येक दिनांक फ़ील्ड के लिए, मॉडल में उपयोग करने के लिए फ़ील्ड के लिए एक नाम प्रदान करें।
इसके अलावा, प्रारूप (वर्ष, माह, दिन), या (मासिक, दिन, वर्ष), या (दिन, माह, वर्ष) भी परिभाषित करें।
प्रत्येक चेकबॉक्स के लिए, मॉडल में उपयोग करने हेतु चेकबॉक्स को एक नाम प्रदान करें।
दस्तावेज़ में चेक किए जा सकने वाले प्रत्येक आइटम के लिए अलग चेकबॉक्स परिभाषित करें।
प्रत्येक तालिका के लिए, तालिका का नाम प्रदान करें.
उन विभिन्न स्तंभों को परिभाषित करें जिन्हें मॉडल को निकालना चाहिए.
नोट
कस्टम इनवॉइस मॉडल डिफ़ॉल्ट फ़ील्ड के साथ आता है जिसे संपादित नहीं किया जा सकता है।
संग्रह के आधार पर दस्तावेज़ों को समूहीकृत करें
एक संग्रह दस्तावेजों का एक समूह है जो समान लेआउट साझा करते हैं। आप अपने मॉडल द्वारा संसाधित किए जाने वाले दस्तावेज़ लेआउट के अनुसार उतने ही संग्रह बनाएँ। उदाहरण के लिए, यदि आप दो अलग-अलग विक्रेताओं के चालानों को संसाधित करने के लिए एक AI मॉडल बना रहे हैं, जिनमें से प्रत्येक के पास अपना स्वयं का चालान टेम्पलेट है, तो दो संग्रह बनाएं।
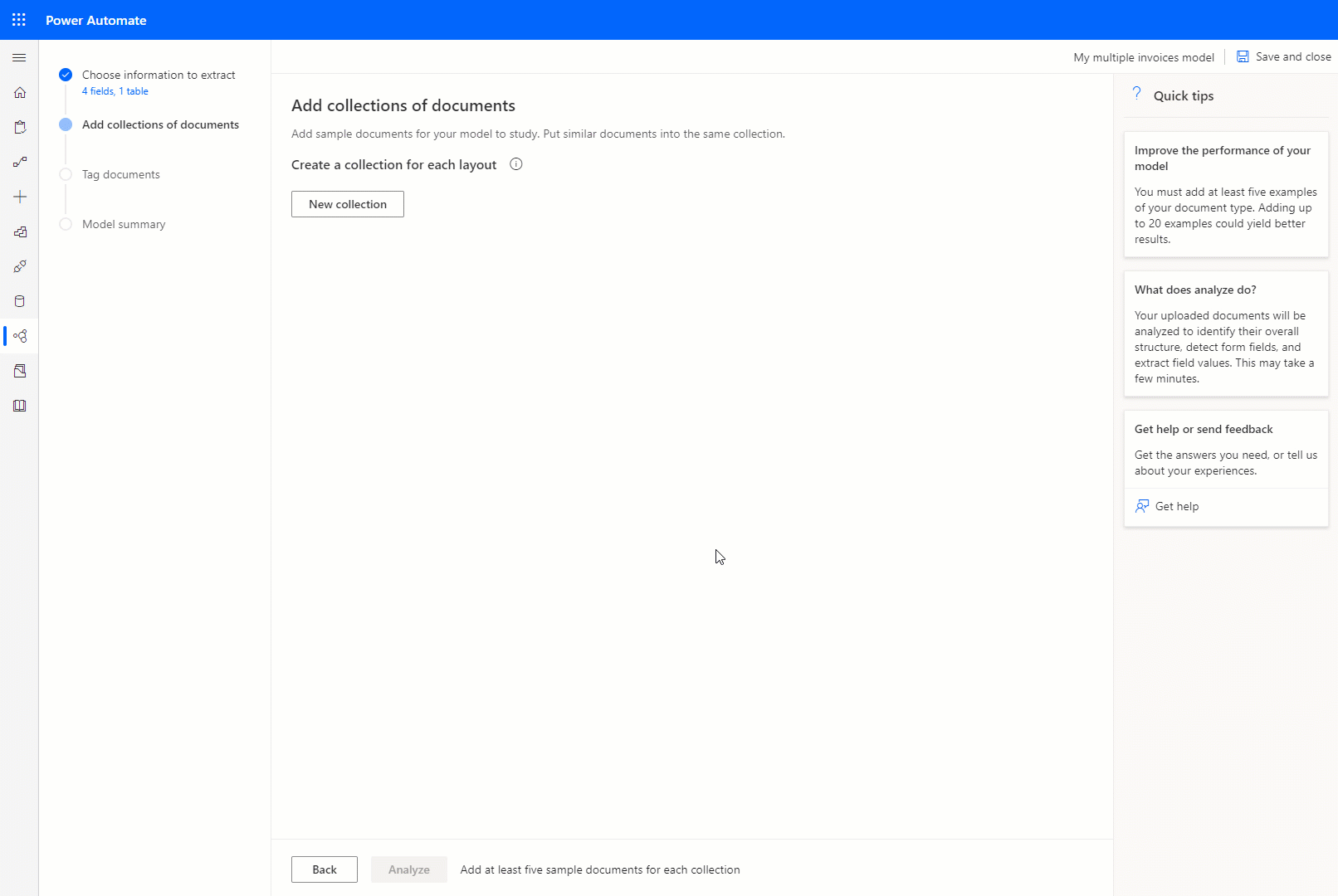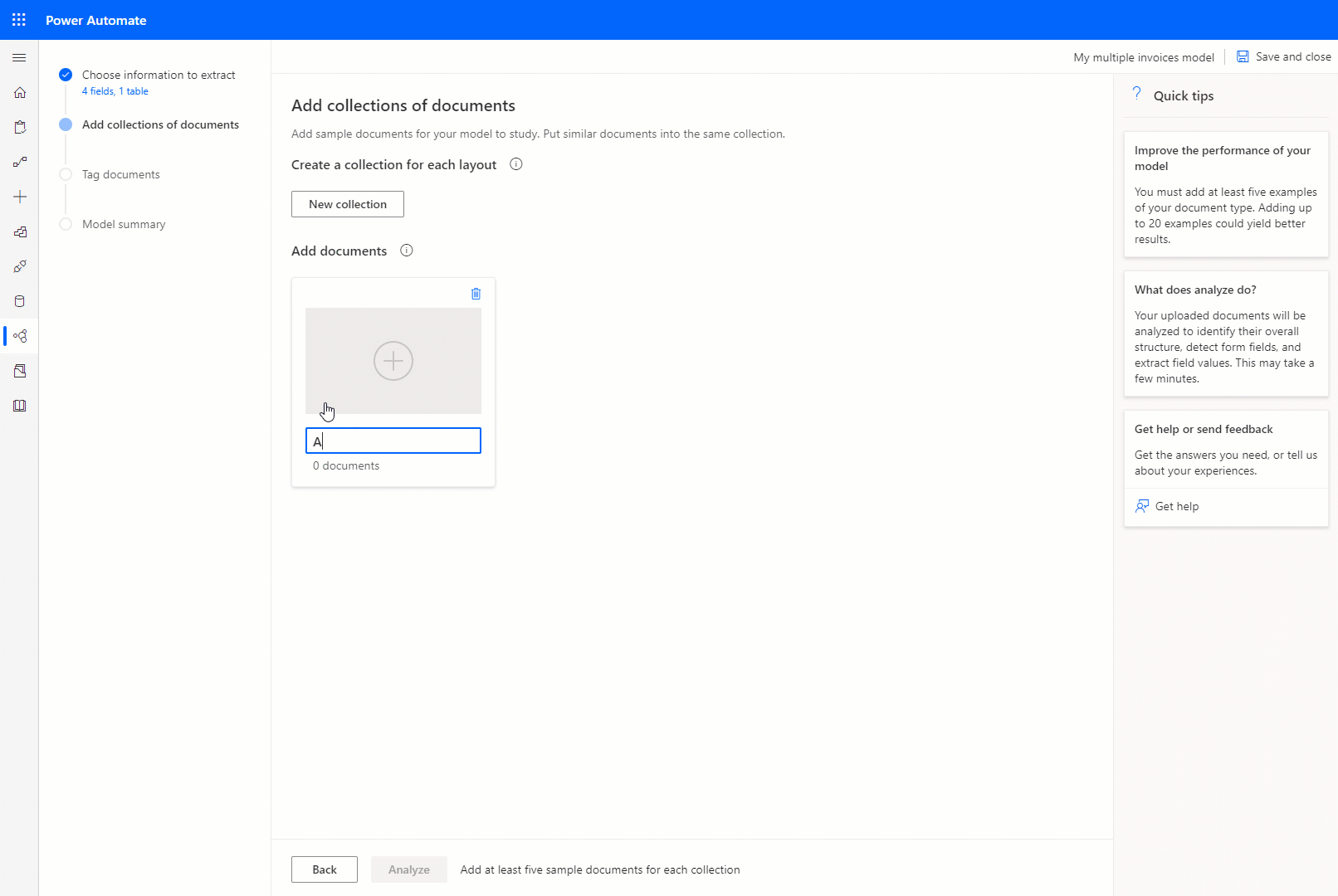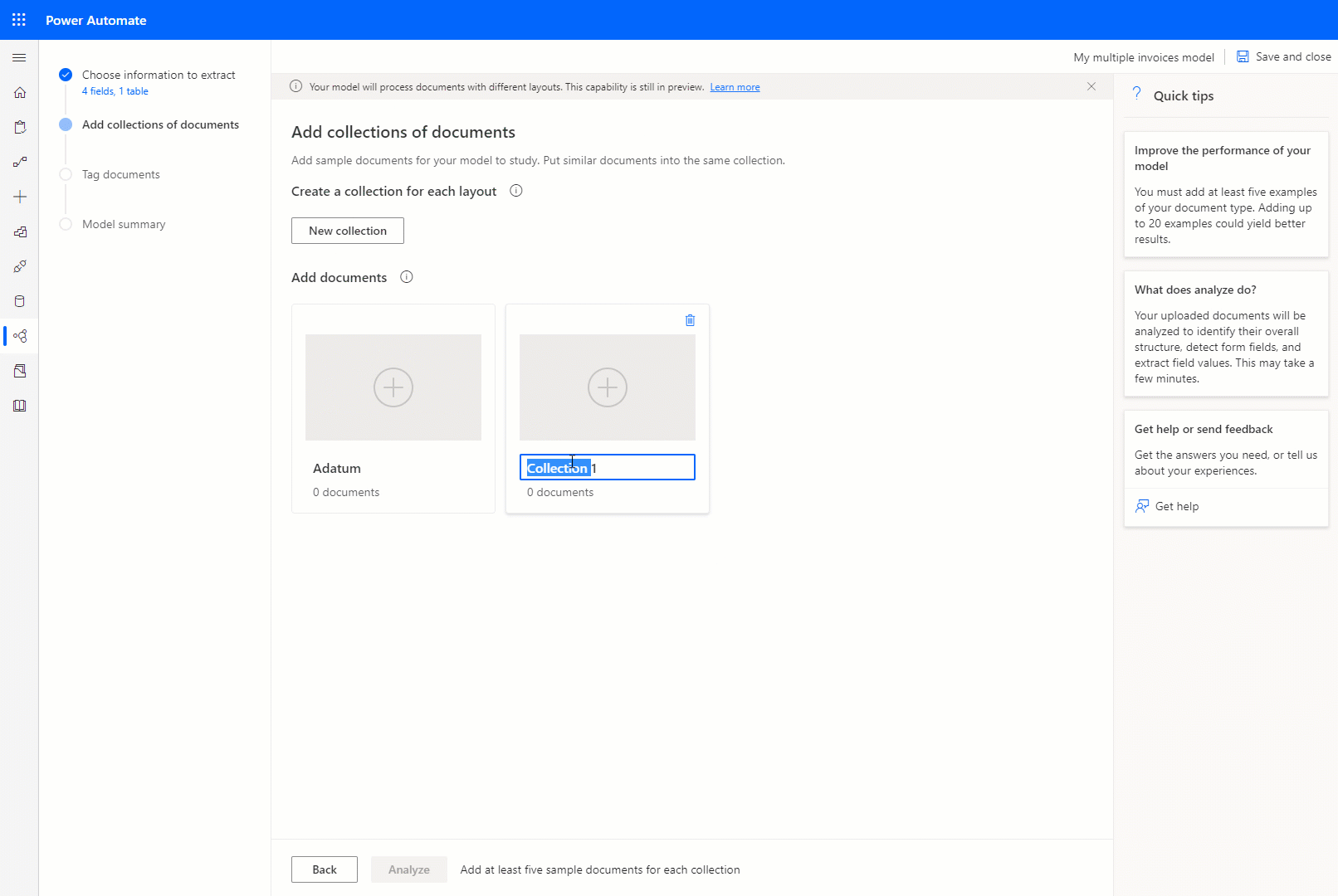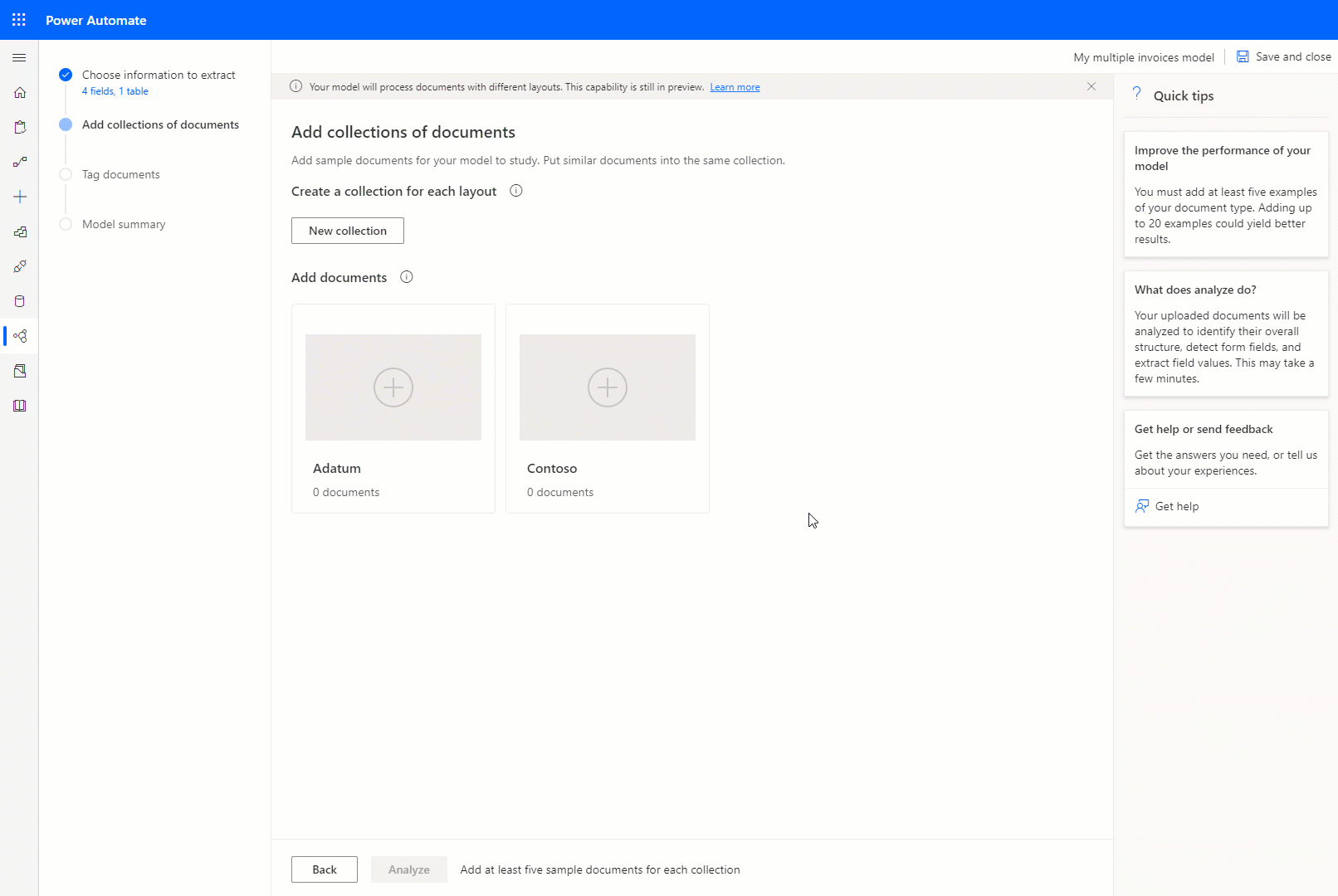
आपके द्वारा बनाए गए प्रत्येक संग्रह के लिए, आपको प्रति संग्रह कम से कम पांच नमूना दस्तावेज़ अपलोड करने होंगे। जेपीजी, पीएनजी और पीडीएफ प्रारूप वाली फाइलें स्वीकार की जाती हैं।
नोट
आप प्रति मॉडल 200 तक संग्रह बना सकते हैं।
अगला कदम
दस्तावेज़ प्रसंस्करण मॉडल में दस्तावेज़ों को टैग करें