नोट
इस पृष्ठ तक पहुंच के लिए प्राधिकरण की आवश्यकता होती है। आप साइन इन करने या निर्देशिकाएँ बदलने का प्रयास कर सकते हैं।
इस पृष्ठ तक पहुंच के लिए प्राधिकरण की आवश्यकता होती है। आप निर्देशिकाएँ बदलने का प्रयास कर सकते हैं।
Power Fx, ओपन-सोर्स लो-कोड फ़ार्मुलों के उपयोग से, आप अपने Power App में AI मॉडल के अधिक शक्तिशाली और लचीले एकीकरण जोड़ सकते हैं। AI मॉडल पूर्वानुमान सूत्रों को कैनवास ऐप में किसी भी नियंत्रण के साथ एकीकृत किया जा सकता है। उदाहरण के लिए, आप टेक्स्ट इनपुट नियंत्रण में टेक्स्ट की भाषा का पता लगा सकते हैं और परिणामों को लेबल नियंत्रण में आउटपुट कर सकते हैं जैसा कि नीचे नियंत्रणों के साथ मॉडल का उपयोग करें अनुभाग में देखा जा सकता है।
आवश्यकताएँ
मॉडल में उपयोग करने के लिए, आपके पास निम्न होना चाहिए: Power Fx AI Builder
डेटाबेस वाले Microsoft Power Platform पर्यावरण तक पहुंच।
AI Builder लाइसेंस (परीक्षण या भुगतान)। अधिक जानने के लिए, AI Builder लाइसेंसिंग पर जाएं।
कैनवास ऐप्स में मॉडल चुनें
Power Fxके साथ AI मॉडल का उपभोग करने के लिए, आपको एक कैनवास ऐप बनाना होगा, एक नियंत्रण चुनना होगा और नियंत्रण गुणों को अभिव्यक्तियाँ असाइन करनी होंगी.
नोट
आपके द्वारा उपयोग किए जा सकने वाले मॉडलों की सूची के लिए, AI मॉडल और व्यावसायिक परिदृश्य देखें। AI Builder आप Microsoft Azure मशीन लर्निंग में निर्मित मॉडलों का उपयोग अपना स्वयं का मॉडल लाएँ सुविधा के साथ भी कर सकते हैं।
कोई ऐप बनाएँ. अधिक जानकारी: शुरुआत से एक खाली कैनवास ऐप बनाएं.
डेटा>डेटा जोड़ें>AI मॉडल चुनें.
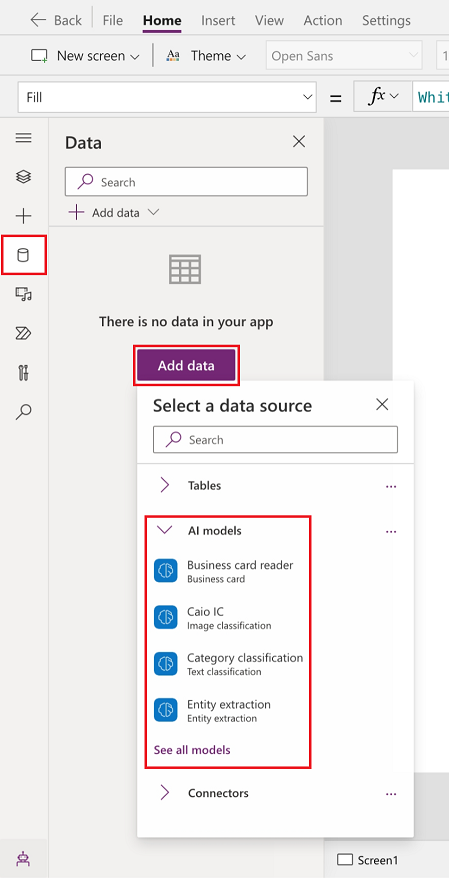
जोड़ने के लिए एक या अधिक मॉडल चुनें.
यदि आपको सूची में अपना मॉडल दिखाई नहीं देता है, तो संभवतः आपके पास इसे उपयोग करने की अनुमति नहीं है। Power Apps इस समस्या को हल करने के लिए अपने व्यवस्थापक से संपर्क करें.
नियंत्रण वाले मॉडल का उपयोग करें
अब जब आपने अपने कैनवास ऐप में AI मॉडल जोड़ लिया है, तो आइए देखें कि नियंत्रण से मॉडल को कैसे कॉल किया जाए. AI Builder
निम्नलिखित उदाहरण में, हम एक ऐसा ऐप बनाएंगे जो ऐप में उपयोगकर्ता द्वारा दर्ज की गई भाषा का पता लगा सकेगा।
कोई ऐप बनाएँ. अधिक जानकारी: शुरुआत से एक खाली कैनवास ऐप बनाएं.
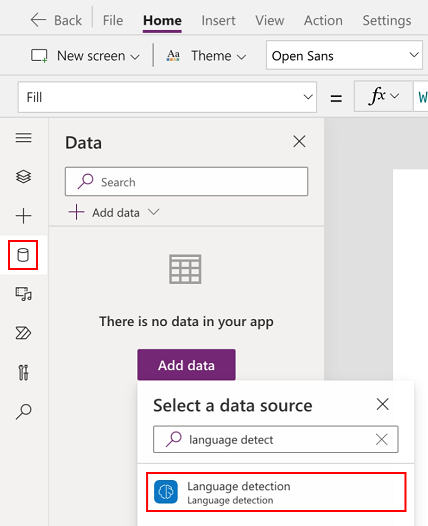
डेटा>डेटा जोड़ें>AI मॉडल चुनें.
भाषा पहचान AI मॉडल खोजें और चुनें.
नोट
आपको ऐप को विभिन्न परिवेशों में ले जाने पर नए परिवेश में मॉडल को मैन्युअल रूप से ऐप में फिर से जोड़ना होगा.
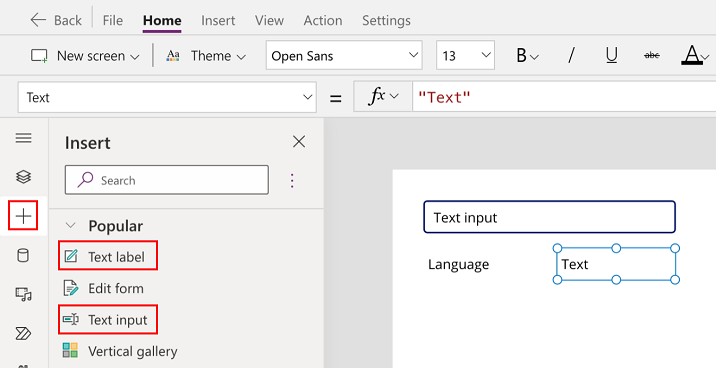
बाएँ फलक से + का चयन करें, और फिर पाठ इनपुट नियंत्रण का चयन करें.
टेक्स्ट लेबल नियंत्रण जोड़ने के लिए पिछले चरण को दोहराएँ।
टेक्स्ट लेबल का नाम बदलकर भाषा करें.
"भाषा" लेबल के आगे एक और टेक्स्ट लेबल जोड़ें.
पिछले चरण में जोड़े गए पाठ लेबल का चयन करें।
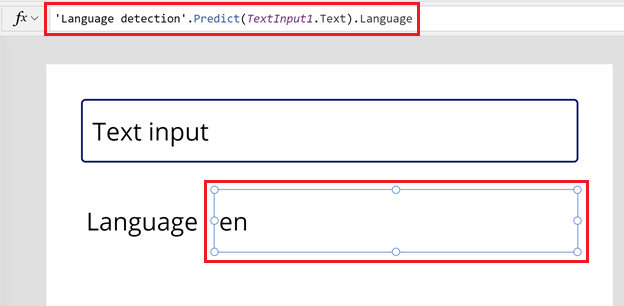
टेक्स्ट लेबल के टेक्स्ट गुण के लिए सूत्र पट्टी में निम्नलिखित सूत्र दर्ज करें।
'Language detection'.Predict(TextInput1.Text).Languageलेबल आपके स्थान के आधार पर भाषा कोड में बदल जाता है। इस उदाहरण के लिए, en (अंग्रेज़ी).
पूर्वावलोकन स्क्रीन के ऊपरी-दाएँ कोने से प्ले बटन का चयन करके ऐप खोलें।
टेक्स्टबॉक्स में
bonjourदर्ज करें. ध्यान दें कि फ्रेंच भाषा (fr) की भाषा टेक्स्ट बॉक्स के नीचे दिखाई देती है।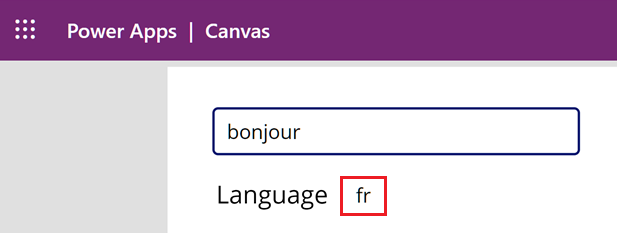
इसी प्रकार, अन्य भाषा के पाठ का प्रयास करें। उदाहरण के लिए,
guten tagदर्ज करने से पता लगाई गई भाषा de जर्मन भाषा में बदल जाती है।
सर्वश्रेष्ठ व्यवहार
क्रेडिट का कुशल उपयोग सुनिश्चित करने के लिए OnChange क्रिया के बजाय OnClick AI Builder बटन का उपयोग करने जैसी एकल क्रियाओं से मॉडल पूर्वानुमान को ट्रिगर करने का प्रयास करें।
समय और संसाधन बचाने के लिए, मॉडल कॉल के परिणाम को सहेजें ताकि आप उसका उपयोग कई स्थानों पर कर सकें। आप आउटपुट को वैश्विक चर में सहेज सकते हैं। मॉडल परिणाम को सहेजने के बाद, आप पहचानी गई भाषा और उसके कॉन्फिडेंस स्कोर को दो अलग-अलग लेबल में दिखाने के लिए अपने ऐप में कहीं और भाषा का उपयोग कर सकते हैं।
Set(lang, 'Language detection'.Predict("bonjour").Language)
मॉडल प्रकार के अनुसार इनपुट और आउटपुट
यह अनुभाग मॉडल प्रकार के अनुसार कस्टम और पूर्वनिर्मित मॉडल के लिए इनपुट और आउटपुट प्रदान करता है।
कस्टम मॉडल
| मॉडल का प्रकार | सिंटैक्स | आउटपुट |
|---|---|---|
| श्रेणी वर्गीकरण | 'Custom text classification model name'.Predict(Text: String, Language?: Optional String) |
{AllClasses: {Name: String, Confidence: Number}[],TopClass: {Name: String,Confidence: Number}} |
| निकाय निष्कर्षण | 'Custom entity extraction model name’.Predict(Text: String,Language?:String(Optional)) |
{Entities:[{Type: "name",Value: "Bill", StartIndex: 22, Length: 4, Confidence: .996, }, { Type: "name", Value: "Gwen", StartIndex: 6, Length: 4, Confidence: .821, }]} |
| ऑब्जेक्ट पहचान | 'Custom object detection model name'.Predict(Image: Image) |
{ Objects: { Name: String, Confidence: Number, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }}[]} |
पूर्वनिर्मित मॉडल
नोट
पूर्वनिर्मित मॉडल नाम आपके परिवेश के लोकेल में दिखाए जाते हैं. निम्नलिखित उदाहरण अंग्रेजी भाषा (en) के लिए मॉडल नाम दिखाते हैं।
| मॉडल का प्रकार | सिंटैक्स | आउटपुट |
|---|---|---|
| बिजनेस कार्ड रीडर | ‘Business card reader’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text", Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| श्रेणी वर्गीकरण | 'Category classification'.Predict( Text: String,Language?: Optional String, ) |
{ AllClasses: { Name: String, Confidence: Number }[], TopClass: { Name: String, Confidence: Number }} |
| आइडेंटिटी डॉक्यूमेंट रीडर | ‘Identity document reader’.Predict( Document: Base64 encoded image ) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text", Confidence: Number, Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| इनवॉयस संसाधन | ‘Invoice processing’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number,Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: { Items: { Rows: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } }} |
| मुख्य वाक्यांश का निष्कर्षण | 'Key phrase extraction'.Predict(Text: String, Language?: Optional String)) |
{ Phrases: String[]} |
| भाषा का पहचान | 'Language Detection'.Predict(Text: String) |
{ Language: String, Confidence: Number} |
| रसीद प्रोसेसिंग | ‘Receipt processing’.Predict( Document: Base64 encoded image) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: {Items: {Rows: {FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } } } |
| मनोभाव विश्लेषण | 'Sentiment analysis'.Predict( Text: String, Language?: Optional String ) |
{ Document: { AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } } Sentences: { StartIndex: Number, Length: Number, AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } }[]} |
| टेक्स्ट पहचान | 'Text recognition'.Predict( Document: Base64 encoded image) |
{Pages: {Page: Number,Lines: { Text: String, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }, Confidence: Number }[] }[]} |
| टेक्स्ट अनुवाद | 'Text translation'.Predict( Text: String, TranslateTo?: String, TranslateFrom?: String) |
{ Text: String, // Translated text DetectedLanguage?: String, DetectedLanguageConfidence: Number} } |
उदाहरण
प्रत्येक मॉडल को पूर्वानुमान क्रिया का प्रयोग करके लागू किया जाता है। उदाहरण के लिए, एक भाषा पहचान मॉडल पाठ को इनपुट के रूप में लेता है और उस भाषा के स्कोर के अनुसार क्रमबद्ध संभावित भाषाओं की एक तालिका लौटाता है। स्कोर यह दर्शाता है कि मॉडल अपने पूर्वानुमान के प्रति कितना आश्वस्त है।
| इनपुट | आउटपुट |
|---|---|
'Language detection'.Predict("bonjour") |
{ Language: “fr”, Confidence: 1} |
‘Text Recognition’.Predict(Image1.Image) |
{ Pages: [ {Page: 1, Lines: [ { Text: "Contoso account", BoundingBox: { Left: .15, Top: .05, Width: .8, Height: .10 }, Confidence: .97 }, { Text: "Premium service", BoundingBox: { Left: .15, Top: .20, Width: .8, Height: .10 }, Confidence: .96 }, { Text: "Paid in full", BoundingBox: { Left: .15, Top: .35, Width: .8, Height: .10 }, Confidence: .99 } } ] } |