लीड स्कोरिंग मॉडल को संपादित करें और पुनः प्रशिक्षित करें
जब किसी मॉडल की सटीकता आपकी अपेक्षाओं को पूरा नहीं करती है, या कोई मॉडल किसी मौजूदा मॉडल की नकल करता है, तो आप उसके द्वारा उपयोग की जाने वाली विशेषताओं को संपादित कर सकते हैं और उसे पुनः प्रशिक्षित कर सकते हैं।
नोट
वास्तविक समय स्कोरिंग सुविधा शुरू होने से पहले प्रकाशित किए गए मॉडलों को वास्तविक समय स्कोरिंग के लिए उपयोग करने हेतु पुनः संपादित और प्रकाशित करने की आवश्यकता होती है। वास्तविक समय स्कोरिंग सुविधा को विभिन्न भौगोलिक क्षेत्रों में चरणबद्ध तरीके से लागू किया जा रहा है। यह सत्यापित करने के लिए कि क्या यह सुविधा आपके क्षेत्र में उपलब्ध है, नवीनतम संस्करण उपलब्धता अनुभाग में संस्करण 9.0.22121.10001 देखें। यह सुविधा रोलआउट के एक सप्ताह बाद सक्षम हो जाएगी। वास्तविक समय स्कोरिंग तभी उपलब्ध होगी जब इसे आपके क्षेत्र के लिए सक्षम किया जाएगा।
लाइसेंस और भूमिका आवश्यकताएँ
| आवश्यकता का प्रकार | आपको होना आवश्यक है |
|---|---|
| लाइसेंस | Dynamics 365 Sales प्रीमियम या Dynamics 365 Sales एंटरप्राइज़ अधिक जानकारी: Dynamics 365 Sales मूल्य निर्धारण |
| सुरक्षा भूमिकाएँ | सिस्टम व्यवस्थापक अधिक जानकारी: बिक्री के लिए पूर्वनिर्धारित सुरक्षा भूमिकाएँ |
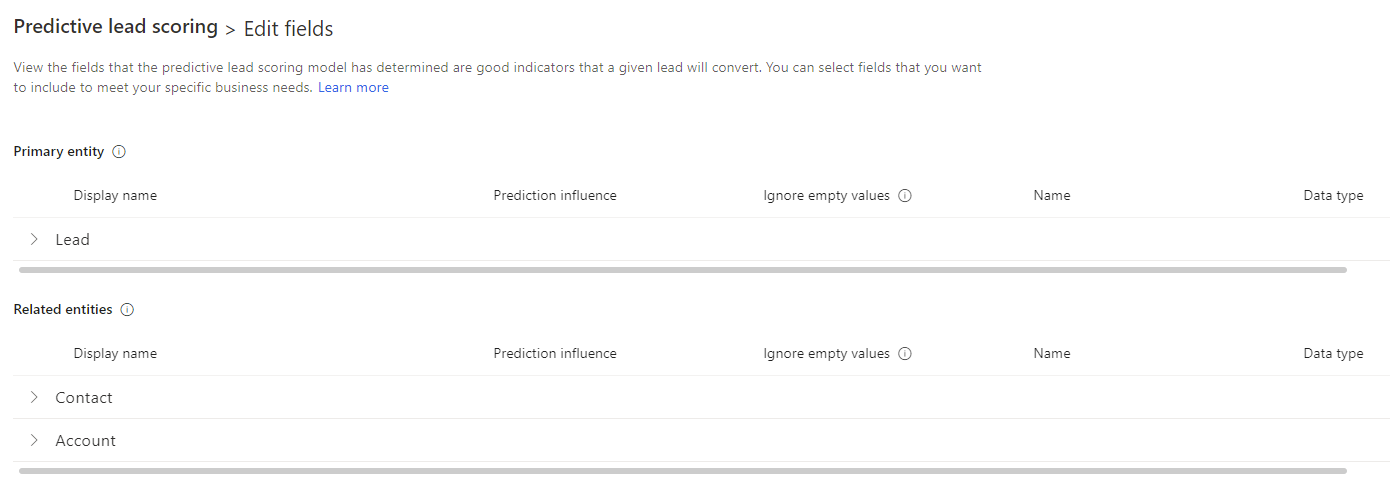
मॉडल संपादित करें
विक्रय हब ऐप के निचले-बाएँ कोने में क्षेत्र बदलें पर जाएँ और Sales Insights सेटिंग्स चुनें.
साइट मानचित्र पर पूर्वानुमानित मॉडल के अंतर्गत, लीड स्कोरिंग का चयन करें.
पूर्वानुमानित लीड स्कोरिंग पृष्ठ पर, मॉडल खोलें और सुनिश्चित करें कि स्वचालित रूप से पुनःप्रशिक्षण बंद है।
मॉडल संपादित करें चुनें और निम्न में से कोई भी क्रिया करें:
मॉडल पर इसके प्रभाव के बारे में जानकारी देखने के लिए एक विशेषता का चयन करें.
मॉडल को प्रशिक्षित करने के लिए लीड निकाय और उससे संबंधित निकायों (संपर्क और खाता) से उन विशेषताओं का चयन करें जिन पर आप मॉडल द्वारा विचार किया जाना चाहते हैं—कस्टम विशेषताओं सहित.
मॉडल में शामिल करने के लिए बुद्धिमान फ़ील्ड का चयन करें.
नोट
स्कोरिंग मॉडल निम्न प्रकार के विशेषताओं का समर्थन नहीं करता है:
- कस्टम निकायों पर विशेषताएं
- दिनांक और समय-संबंधित विशेषताएँ
- सिस्टम जनित विशेषताएँ जैसे, लीडस्कोर, लीडग्रेड, संस्करण संख्या, निकाय इमेज, विनिमय दर, और पूर्वानुमानित स्कोर ID
(वैकल्पिक) विशेषता सूची के दाईं ओर स्क्रॉल करें और खाली मानों को अनदेखा करें चालू करें.
डिफ़ॉल्ट रूप से, मॉडल को प्रशिक्षित करने के लिए विशेषता में रिक्त मान शामिल किए जाते हैं। यदि आप देखते हैं कि रिक्त मान अवरोधक के रूप में कार्य कर रहे हैं या गलत सकारात्मक परिणाम दे रहे हैं, तो रिक्त मानों को अनदेखा करें को चालू करें।
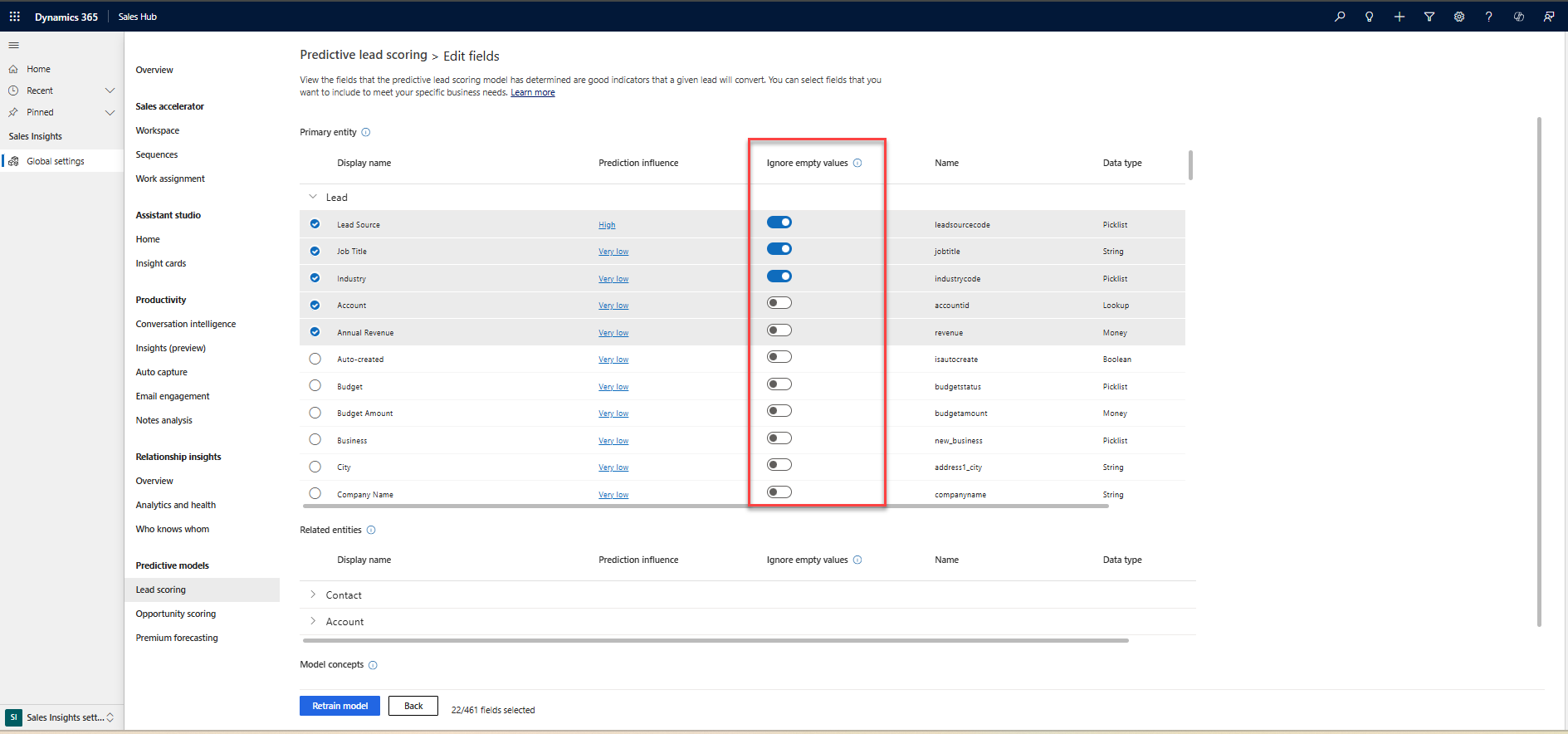
खाली मानों को अनदेखा करें विकल्प निम्न प्रकार की विशेषताओं के लिए अक्षम है:
- विशेषताएँ जो रिक्त मानों के लिए स्वचालित रूप से मान्य होती हैं, जैसे firstname_validation_engineered.
- वे विशेषताएँ जो मान के मौजूद होने या न होने के आधार पर स्कोर को प्रभावित करती हैं, जैसे कि ज़िपकोड या व्यावसायिक फ़ोन.
जब आप किसी विशेषता के लिए रिक्त मानों को अनदेखा करें को चालू करते हैं, तो स्कोरिंग विज़ेट इंगित करता है कि स्कोर की गणना रिक्त मानों को छोड़ने के बाद की जाती है।
मॉडल पुनः प्रशिक्षित करें चुनें.
मॉडल को पुनः प्रशिक्षित होने के लिए कुछ मिनट का समय दें। जब यह तैयार हो जाएगा, तो आपको इस तरह का संदेश प्राप्त होगा:
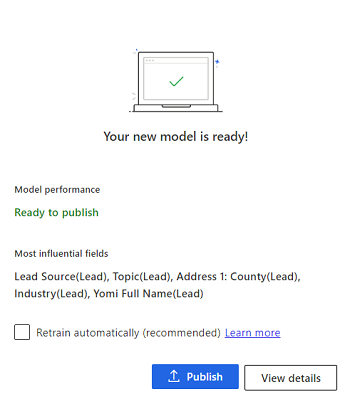
यदि आप चाहते हैं कि एप्लिकेशन प्रत्येक 15 दिनों के बाद मॉडल को स्वचालित रूप से पुनः प्रशिक्षित करे, तो स्वचालित रूप से पुनः प्रशिक्षित करें का चयन करें।
निम्न में से कोई एक एक्शन करें:
यदि आप प्रकाशित करने के लिए तैयार हैं, तो प्रकाशित करें चुनें. मॉडल को उन लीड पर लागू किया जाता है जो मॉडल कॉन्फ़िगरेशन में निर्दिष्ट मानदंडों से मेल खाते हैं। उपयोगकर्ता अपने व्यूज़ में लीड स्कोरिंग को लीड स्कोर कॉलम के अंतर्गत और लीड फ़ॉर्म में विज़ेट देख सकते हैं। अधिक जानकारी: लीड्स को अवसरों में बदलें
यदि आप मॉडल की सटीकता सत्यापित करना चाहते हैं, तो विवरण देखें चुनें और फिर प्रदर्शन टैब चुनें। अधिक जानकारी के लिए, पूर्वानुमान की सटीकता और प्रदर्शन देखें देखें।
यदि पुनः प्रशिक्षित मॉडल की सटीकता संतोषजनक नहीं है, तो विशेषताओं को संपादित करें और मॉडल को पुनः प्रशिक्षित करें। यदि आप पिछले संस्करण पर वापस जाना चाहते हैं, तो उस संस्करण पर वापस जाएँ।
बुद्धिमान क्षेत्रों का चयन करें
बुद्धिमान क्षेत्र मॉडल को रिकॉर्ड को बेहतर ढंग से समझने और स्कोर को बेहतर बनाने वाले कारकों और उसे नुकसान पहुंचाने वाले कारकों के बीच अंतर करने में मदद करते हैं। उदाहरण के लिए, मॉडल, एप्लिकेशन में उपलब्ध डेटा और मॉडल में जोड़ी गई इंटेलिजेंस का उपयोग करके ईमेल प्रकारों की पहचान करके और उन्हें समूहीकृत करके व्यावसायिक ईमेल पतों और व्यक्तिगत ईमेल पतों के बीच अंतर कर सकता है। इस पहचान के माध्यम से, मॉडल इस बारे में विस्तृत जानकारी जेनरेट कर सकता है कि क्षेत्रों के समूह पूर्वानुमान स्कोर को कैसे प्रभावित करते हैं.
पिछले अनुभाग में बताए अनुसार मॉडल को संपादित करें और उन बुद्धिमान फ़ील्ड को चुनें जिन्हें आप अपने मॉडल में उपयोग करना चाहते हैं। निम्न छवि यह दर्शाती है कि आप इंटेलीजेंट फ़ील्ड का चयन कैसे कर सकते हैं.
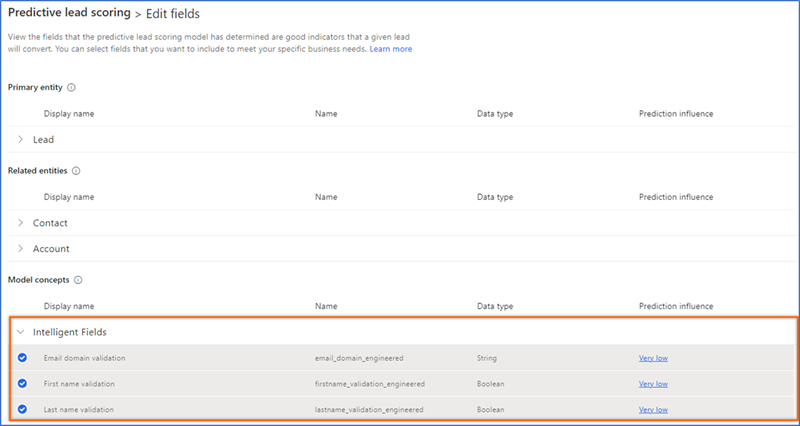
क्षेत्र के प्रभाव के बारे में जानकारी देखने के लिए पूर्वानुमान प्रभाव कॉलम में लिंक का चयन करें, जैसे कि इसकी योग्यता दर और दर के लिए सबसे प्रभावशाली कारक, सकारात्मक और नकारात्मक दोनों। मॉडल पर किसी विशेषता के प्रभाव को देखने का तरीका जानें.
आप निम्नलिखित फ़ील्ड का चयन कर सकते हैं: ईमेल डोमेन सत्यापन (ईमेल), प्रथम नाम सत्यापन (प्रथम नाम), और अंतिम नाम सत्यापन (अंतिम नाम). मॉडल हमेशा वरीयता देता है:
- ईमेल पते जो किसी व्यवसाय डोमेन का हिस्सा हैं
- प्रथम और अंतिम नाम जिसमें अल्फ़ान्यूमेरिक अक्षर हों और कोई विशेष अक्षर न हों
डिफ़ॉल्ट तौर पर, आउट-ऑफ-द-बॉक्स मानों का उपयोग करके मॉडल को प्रशिक्षित करते समय इंटेलीजेंट फ़ील्ड पर विचार किया जाता है. यदि इंटेलीजेंट फ़ील्ड का परिणाम संतोषजनक रहता है, तो मॉडल में प्रशिक्षित करने के लिए फ़ील्ड शामिल रहते हैं; अन्यथा, फ़ील्ड को अनदेखा कर दिया जाता है. हालांकि, भले ही परिणाम संतोषजनक न रहे, फिर भी यदि आवश्यक हो तो आप मॉडल को प्रशिक्षित करने के लिए इंटेलीजेंट फ़ील्ड को शामिल करना चुन सकते हैं.
नोट
लीड इकाई या उससे संबंधित इकाइयों, संपर्क और खाते में इंटेलिजेंट फ़ील्ड उपलब्ध नहीं हैं.
मॉडल को पुनः प्रशिक्षित करें
जब किसी मॉडल का पूर्वानुमान सटीक स्कोर आपके संगठन के मानकों के अनुरूप न हो, या मॉडल बहुत पुराना हो, तो उसे पुनः प्रशिक्षित करें। आम तौर पर, पुनःप्रशिक्षण से मॉडल की पूर्वानुमान सटीक स्कोर. बढ़ जाती है यह एप्लिकेशन मॉडल को प्रशिक्षित करने के लिए आपके संगठन में नवीनतम लीड का उपयोग करता है, ताकि यह आपके विक्रेताओं को अधिक सटीक स्कोर प्रदान कर सके।
बेहतर पूर्वानुमान सटीकता स्कोरिंग के लिए, अपने संगठन में डेटा रीफ़्रेश होने के बाद मॉडल को पुनः प्रशिक्षित करें.
आप किसी मॉडल को स्वचालित रूप से या मैन्युअल रूप से पुनः प्रशिक्षित कर सकते हैं।
स्वचालित पुनर्प्रशिक्षण
स्वचालित पुनःप्रशिक्षण, एप्लिकेशन को प्रत्येक 15 दिन में एक मॉडल को पुनःप्रशिक्षित करने की अनुमति देता है। इससे मॉडल को नवीनतम डेटा से सीखने में मदद मिलती है और इसकी पूर्वानुमान सटीक स्कोर. में सुधार होता है
किसी मॉडल को स्वचालित रूप से पुनः प्रशिक्षित करने के लिए, मॉडल के पूर्वानुमानित लीड स्कोरिंग पृष्ठ पर जाएं और स्वचालित रूप से पुनः प्रशिक्षित करें चुनें. डिफ़ॉल्ट रूप से, यह विकल्प किसी मॉडल के प्रकाशित होने पर चालू होता है.
मॉडल की सटीकता के आधार पर, अनुप्रयोग एक सूचित निर्णय लेता है कि पुनर्प्रशिक्षित मॉडल को प्रकाशित या अनदेखा करना है या नहीं. अनुप्रयोग निम्नलिखित परिदृश्यों में मॉडल को स्वचालित रूप से प्रकाशित करता है:
- जब पुनर्प्रशिक्षित मॉडल की सटीकता सक्रिय मॉडल की सटीकता के 95प्रतिशत के बराबर या उससे अधिक हो.
- जब मौजूदा मॉडल तीन महीनों से अधिक पुराना हो.
अन्यथा, अनुप्रयोग वर्तमान मॉडल को बनाए रखता है।
मैन्युअल पुनर्प्रशिक्षण
आप निम्नलिखित मामलों में मॉडल को मैन्युअल रूप से पुनः प्रशिक्षित कर सकते हैं:
- आप बेहतर सटीकता के लिए मॉडल को संपादित करना चाहते हैं और उसे पुनः प्रशिक्षित करना चाहते हैं।
- आपने स्वचालित रूप से पुनःप्रशिक्षण को बंद कर दिया है।
दोनों ही मामलों में, आपको मैन्युअल पुनःप्रशिक्षण को सक्रिय करने के लिए मॉडल को संपादित करना होगा। ...
आपके ऐप में विकल्प नहीं मिल रहे हैं?
तीन संभावनाएं हैं:
- आपके पास आवश्यक लाइसेंस या भूमिका नहीं है।
- आपके व्यवस्थापक ने सुविधा चालू नहीं की है.
- आपका संगठन किसी कस्टम ऐप का उपयोग कर रहा है. सटीक चरणों के लिए अपने व्यवस्थापक से संपर्क करें. इस आलेख में वर्णित चरण आउट-ऑफ़-द-बॉक्स विक्रय हब और Sales Professional ऐप के लिए विशिष्ट हैं.