Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Ha még nem ismerkedik a Azure Data Factory, tekintse meg a Bevezetés a Azure Data Factory című témakört.
Ebben az oktatóanyagban az adatfolyam-vásznon olyan adatfolyamokat hozhat létre, amelyek lehetővé teszik az adatok elemzését és átalakítását Azure Data Lake Storage (ADLS) Gen2-ben, és tárolhatja azokat a Delta Lake-ben.
Előfeltételek
- Azure előfizetés. Ha nem rendelkezik Azure előfizetéssel, a kezdés előtt hozzon létre egy free Azure fiókot.
- Azure tárolófiók. Az ADLS-tárhelyet forrás és adatfogadó tárolóként használja. Ha nincs tárfiókja, a A Azure tárfiók létrehozása a létrehozás lépéseit ismerteti.
Az oktatóanyagban átalakítandó fájl MoviesDB.csv, amely itt található. A fájl GitHub való lekéréséhez másolja a tartalmat egy tetszőleges szövegszerkesztőbe, hogy helyileg .csv fájlként mentse. A fájl tárfiókba való feltöltéséhez lásd: Blobok feltöltése a Azure portállal. A példák egy "sample-data" nevű tárolóra hivatkoznak.
Adat-előállító létrehozása
Ebben a lépésben létrehoz egy adat-előállítót, és megnyitja a Data Factory UX-t egy folyamat létrehozásához az adat-előállítóban.
Nyissa meg Microsoft Edge vagy Google Chrome. A Data Factory felhasználói felülete jelenleg csak a Microsoft Edge és a Google Chrome böngészőkben támogatott.
A bal oldali menüben válassza a Erőforrás létrehozása>Integráció>Data Factory lehetőséget.
Az Új adat-előállító lap Név területén adja meg az ADFTutorialDataFactory nevet
Válassza ki azt a Azure subscription, amelyben létre szeretné hozni az adat-előállítót.
Erőforráscsoport: hajtsa végre a következő lépések egyikét:
a). Kattintson a Meglévő használata elemre, majd a legördülő listából válasszon egy meglévő erőforráscsoportot.
b. Kattintson az Új létrehozása elemre, és adja meg az erőforráscsoport nevét.
Az erőforráscsoportokról a A Azure erőforráscsoportok kezelése című témakörben olvashat.
A Verzió résznél válassza a V2 értéket.
A Hely területen válassza ki az adat-előállító helyét. A legördülő listán csak a támogatott helyek jelennek meg. Az adat-előállító által használt adattárak (például Azure Storage és SQL Database) és számítások (például Azure HDInsight) más régiókban is lehetnek.
Válassza a Létrehozás lehetőséget.
A létrehozás befejezése után megjelenik az értesítés az Értesítések központban. Válassza az Ugrás az erőforrásra lehetőséget a Data Factory lapra való navigáláshoz.
A Data Factory felhasználói felületének külön lapon történő elindításához válassza a Létrehozás és figyelés csempét.
Folyamat létrehozása adatfolyam-tevékenységgel
Ebben a lépésben egy adatfolyam-tevékenységet tartalmazó folyamatot hoz létre.
A kezdőlapon válassza az Orchestrate lehetőséget.
A folyamat lapjának Általános fülén adja meg a DeltaLake nevet a folyamat nevéhez.
A Tevékenységek panelen bontsa ki az Áthelyezés és átalakítás harmonika panelt. Húzza a Adatfolyam aktivitást a panelről a pipeline vászonra.
A folyamatvászon felső sávján kapcsolja be a Adatfolyam hibakeresés csúszkát. A hibakeresési mód lehetővé teszi az átalakítási logika interaktív tesztelését egy élő Spark-fürtön. Adatfolyam fürtök bemelegedése 5-7 percet vesz igénybe, és a felhasználóknak ajánlott először bekapcsolniuk a hibakeresést, ha Adatfolyam fejlesztést terveznek. További információ: Hibakeresési mód.
Átalakítási logika létrehozása az adatfolyam-vásznon
Ebben az oktatóanyagban két adatfolyamot hoz létre. Az első adatfolyam egy egyszerű forrás, amely egy új Delta Lake-t hoz létre a filmek CSV-fájljából. Végül létre kell hoznia az alábbi folyamattervet a Delta Lake adatainak frissítéséhez.

Oktatóanyag célkitűzései
- Használja a MoviesCSV adatkészlet forrását az előfeltételekből, és alakítsa ki belőle az új Delta Lake-t.
- Hozza létre a logikát, hogy az 1988-as filmek értékeléseit "1"-re frissítse.
- Törölje az összes filmet 1950-ből.
- Új filmek beszúrása 2021-ben a filmek 1960-ból való duplikálásával.
Kezdés egy üres adatfolyam-vászonról
Válassza ki a forrásátalakítást az adatfolyam-szerkesztő ablakának tetején, majd válassza az + Új lehetőséget az Adathalmaz tulajdonság mellett a Forrásbeállítások ablakban:
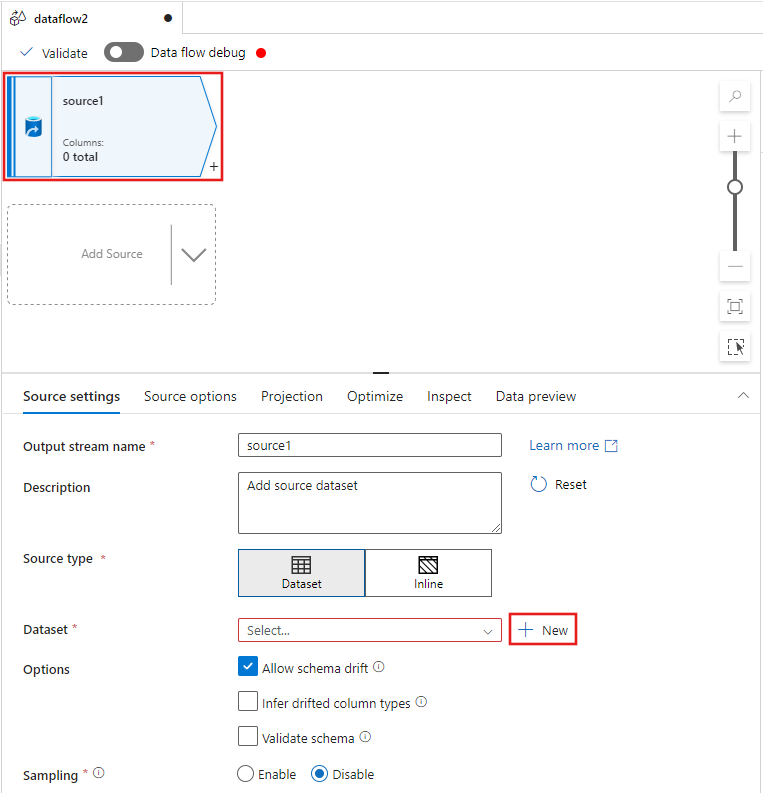
Válassza a Azure Data Lake Storage Gen2 lehetőséget a Új adathalmaz ablakban, majd válassza a Continue lehetőséget.
Az Új adatkészlet ablakban mutatja, hogy hol lehet kiválasztani az Azure Data Lake Storage Gen2-t.
Válassza a DelimitedText (Elválasztó szöveg) lehetőséget az adathalmaz típusához, majd válassza ismét a Folytatás lehetőséget.

Nevezze el a "MoviesCSV" adathalmazt, és válassza az + Új a Csatolt szolgáltatás területen lehetőséget egy új társított szolgáltatás létrehozásához a fájlhoz.
Adja meg a korábban az Előfeltételek szakaszban létrehozott tárfiók adatait, és keresse meg és válassza ki az ott feltöltött MoviesCSV-fájlt.
A csatolt szolgáltatás hozzáadása után jelölje be az Első sort fejlécként jelölőnégyzet, majd a forrás hozzáadásához kattintson az OK gombra .
Lépjen az adatfolyam-beállítások ablakának Vetítés lapjára, majd válassza a Adattípusok észlelése lehetőséget.
Most jelölje ki a + Forrás után az adatfolyam-szerkesztőablakban, és görgessen le a Cél szakaszban található Fogadó elemre, és adjon hozzá egy új fogadót az adatfolyamhoz.
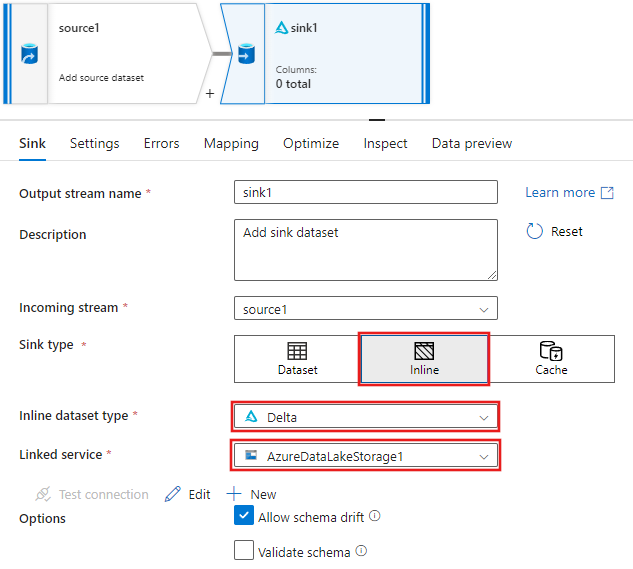
A Fogadó lapon a fogadó hozzáadása után megjelenő fogadóbeállításoknál válassza Beágyazott a Fogadó típus számára, majd Delta-t a Beágyazott adathalmaz típushoz. Ezután válassza ki a Azure Data Lake Storage Gen2 a Linked szolgáltatáshoz.
Válasszon egy mappanevet a tárolóban, ahol a szolgáltatás létre szeretné hozni a Delta Lake-t.
Végül lépjen vissza a folyamattervezőhöz, és válassza a Hibakeresés lehetőséget a folyamat hibakeresési módban való végrehajtásához, csak ezzel az adatfolyam-tevékenységgel a vásznon. Ez létrehozza az új Delta Lake-t az Azure Data Lake Storage Gen2-ben.
Most a képernyő bal oldalán található Gyári erőforrások menüben válassza az + új erőforrás hozzáadásához, majd az Adatfolyam lehetőséget.
A korábbiakhoz hasonlóan válassza ki ismét a MoviesCSV fájlt forrásként, majd válassza ismét az Adattípusok észlelése lehetőséget a Vetítés lapon.
Ezúttal a forrás létrehozása után jelölje ki az + adatfolyam-szerkesztő ablakát, és adjon hozzá szűrőátalakítást a forráshoz.
Adjon hozzá egy feltételt a Szűrőbeállítások ablakban, amely csak az 1950-nek, 1960-nak és 1988-nak megfelelő filmsorokat engedélyezi.
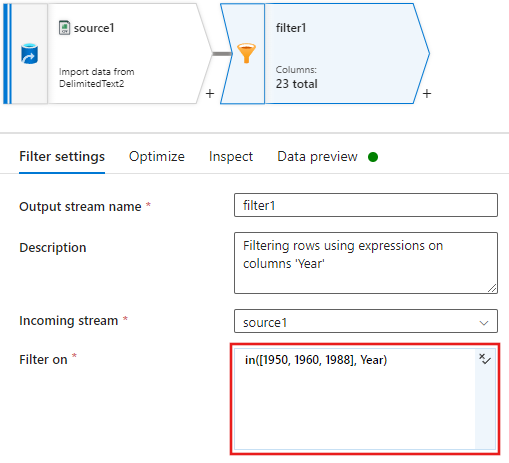
Most adjon hozzá egy származtatott oszlopátalakítást az egyes 1988-filmek minősítéseinek frissítéséhez az "1" értékre.
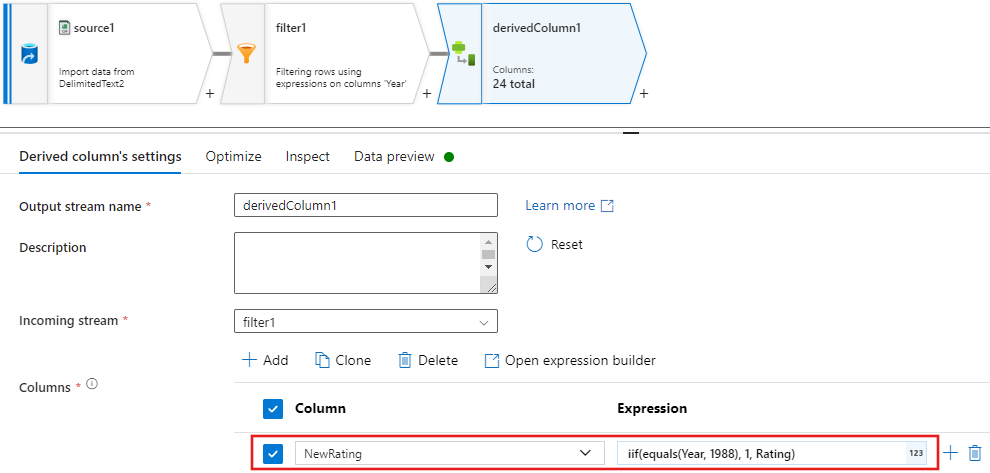
Update, insert, delete, and upserta szabályzatok az alter Row átalakításban jönnek létre. Adjon hozzá egy módosítósor-átalakítást a származtatott oszlop után.Az Ön sor módosítási szabályainak így kellene kinéznie.

Most, hogy beállította a megfelelő szabályzatot az egyes módosító sor típusokhoz, ellenőrizze, hogy a megfelelő frissítési szabályok be lettek-e állítva a cél transzformáción.
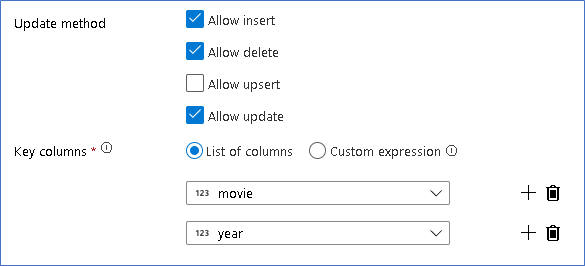
Itt a Delta Lake-fogadót használjuk a Azure Data Lake Storage Gen2 data lake-hez, és lehetővé tesszük a beszúrásokat, frissítéseket és törléseket.
Vegye figyelembe, hogy a kulcsoszlopok a film elsődleges kulcs oszlopából és az év oszlopból álló összetett kulcsok. Ennek az az oka, hogy hamis 2021-filmeket hoztunk létre az 1960-os sorok duplikálásával. Ez az egyediség biztosításával elkerüli az ütközéseket a meglévő sorok keresésekor.
Befejezett minta letöltése
Íme egy mintamegoldás a Delta-folyamathoz egy adatfolyammal a tóban lévő sorok frissítéséhez/törléséhez.
Kapcsolódó tartalom
További információ az adatfolyam-kifejezés nyelvéről.