Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
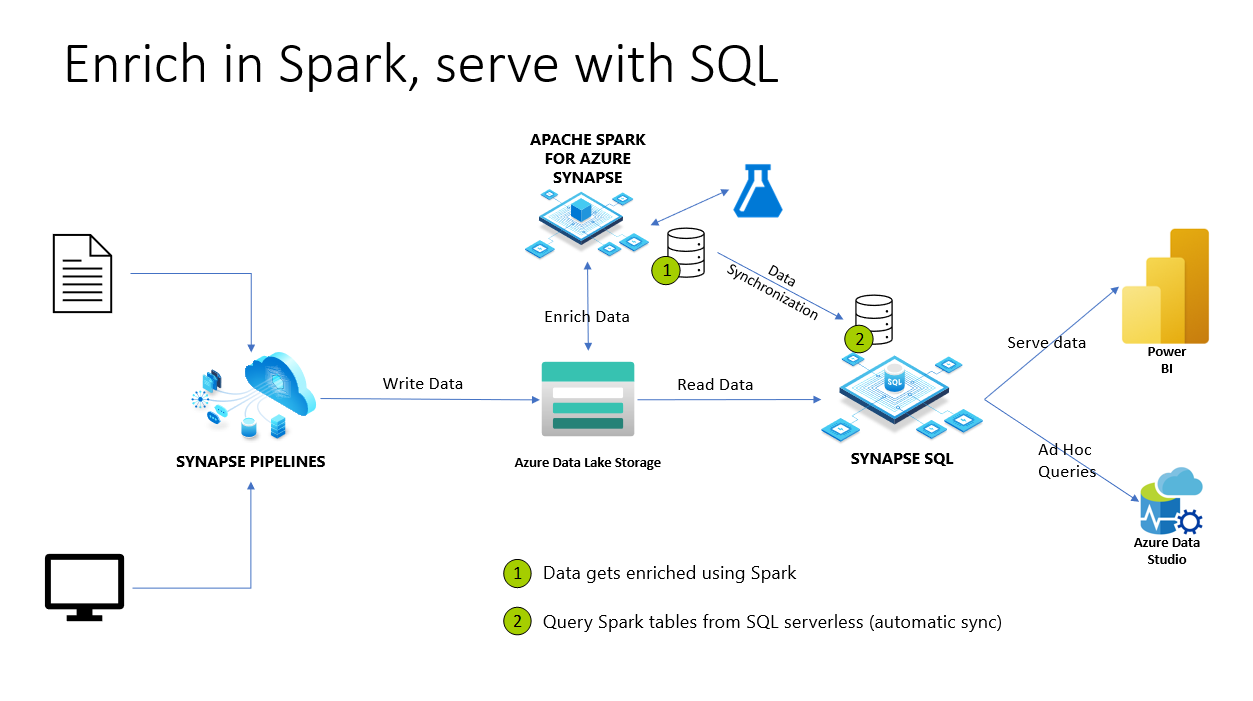
Az Azure Synapse Analyticsben a Spark-adatbázisok és -táblák kiszolgáló nélküli SQL-készlettel vannak megosztva. A Sparkkal létrehozott tóadatbázisok, Parquet- és CSV-háttértáblák automatikusan elérhetők a kiszolgáló nélküli SQL-készletben. Ez a funkció lehetővé teszi a kiszolgáló nélküli SQL-készlet használatát a Spark-készletek használatával készített adatok feltárásához és lekérdezéséhez. Az alábbi ábrán egy magas szintű architektúra áttekintést láthat a funkció használatához. Először is az Azure Synapse Pipelines a helyszíni (vagy egyéb) tárolóból az Azure Data Lake Storage-ba helyezi át az adatokat. A Spark mostantól bővítheti az adatokat, és adatbázisokat és táblákat hozhat létre, amelyek szinkronizálódnak a kiszolgáló nélküli Synapse SQL-hez. Később a felhasználó eseti lekérdezéseket hajthat végre a bővített adatokon, vagy például kiszolgálhatja őket a Power BI-ban.
Teljes rendszergazdai hozzáférés (sysadmin)
Miután ezeket az adatbázisokat és táblákat szinkronizálta a Sparkból a kiszolgáló nélküli SQL-készletbe, ezek a kiszolgáló nélküli SQL-készletben lévő külső táblák is használhatók ugyanazon adatok eléréséhez. A kiszolgáló nélküli SQL-készlet objektumai azonban írásvédettek, mert a Spark-készletek objektumaival konzisztenciát tart. A korlátozás miatt csak a Synapse SQL-rendszergazdai vagy Synapse-rendszergazdai szerepkörrel rendelkező felhasználók férhetnek hozzá ezekhez az objektumokhoz kiszolgáló nélküli SQL-készletben. Ha egy nem rendszergazda felhasználó megpróbál lekérdezést végrehajtani a szinkronizált adatbázison/táblán, a következőhöz hasonló hibaüzenet jelenik meg:
External table '<table>' is not accessible because content of directory cannot be listed. annak ellenére, hogy hozzáférnek az alapul szolgáló tárfiók(ok) adataihoz.
Mivel a kiszolgáló nélküli SQL-készlet szinkronizált adatbázisai írásvédettek, nem módosíthatók. A felhasználó létrehozása vagy más engedélyek megadása sikertelen lesz, ha megkísérlik. A szinkronizált adatbázisok olvasásához jogosultsági szintű kiszolgálószintű engedélyekkel (például sysadmin) kell rendelkeznie. Ez a korlátozás a kiszolgáló nélküli SQL-készlet külső tábláira is vonatkozik az Azure Synapse Link for Dataverse és a lake databases táblák használatakor.
Nem rendszergazdai hozzáférés szinkronizált adatbázisokhoz
Azok a felhasználók, akiknek adatokat kell olvasniuk és jelentéseket kell létrehozniuk, általában nem rendelkeznek teljes rendszergazdai hozzáféréssel (sysadmin). Ez a felhasználó általában adatelemző, akinek csak a meglévő táblák használatával kell adatokat olvasnia és elemeznie. Nem kell új objektumokat létrehozniuk.
Egy minimális engedéllyel rendelkező felhasználónak képesnek kell lennie a következőre:
- Csatlakozás a Sparkból replikált adatbázishoz
- Válasszon ki adatokat külső táblákon keresztül, és férhessen hozzá a mögöttes ADLS-adatokhoz.
Az alábbi kódszkript végrehajtása után lehetővé teszi, hogy a nem rendszergazdai felhasználók kiszolgálószintű engedélyekkel rendelkezzenek bármely adatbázishoz való csatlakozáshoz. Emellett lehetővé teszi a felhasználók számára, hogy minden sémaszintű objektumból, például táblákból vagy nézetekből származó adatokat is megtekinthessenek. Az adathozzáférés biztonsága a tárolási rétegen kezelhető.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Megjegyzés
Ezeket az utasításokat a főadatbázison kell végrehajtani, mivel ezek mind kiszolgálószintű engedélyek.
Bejelentkezés és engedélyek megadása után a felhasználók lekérdezéseket futtathatnak a szinkronizált külső táblákon. Ez a kockázatcsökkentés a Microsoft Entra biztonsági csoportokra is alkalmazható.
Az objektumok nagyobb biztonsága adott sémákon keresztül kezelhető, és zárolható egy adott sémához való hozzáférés. A megoldáshoz további adatdefiníciós nyelv (DDL) szükséges. Ebben a forgatókönyvben létrehozhat új kiszolgáló nélküli adatbázist, sémákat és nézeteket, amelyek az ADLS Spark-táblák adataira mutatnak.
A tárfiók adataihoz való hozzáférés a Microsoft Entra-felhasználók/-csoportok esetében ACL-en vagy normál Storage Blob-adattulajdonosi/olvasói/közreműködői szerepkörökön keresztül kezelhető. Szolgáltatási Főazonosítók (Microsoft Entra alkalmazások esetén) esetén győződjön meg róla, hogy az ACL beállításait használja.
Megjegyzés
- Ha meg szeretné tiltani az OPENROWSET használatát az adatokhoz, használhatja
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];. További információért látogasson el a DENY kiszolgáló engedélyei megtekintéséhez. - Ha bizonyos sémák használatát meg szeretné tiltani, további információt a
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];című témakörben talál.
Következő lépések
További információ: SQL Authentication.