Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Synapse Analytics-munkaterületen kétféle adatbázist hozhat létre a Spark-adattó tetején:
- Lake-adatbázisok, ahol apache Spark-jegyzetfüzetek , adatbázissablonok vagy Microsoft Dataverse (korábban Common Data Service) használatával definiálhat táblákat a tóadatok tetején. Ezek a táblák A T-SQL (Transact-SQL) nyelv használatával kérdezhetők le a kiszolgáló nélküli SQL-készlet használatával.
- SQL-adatbázisok , amelyekben saját adatbázisokat és táblákat határozhat meg közvetlenül a kiszolgáló nélküli SQL-készlet használatával. A T-SQL CREATE DATABASE, a CREATE EXTERNAL TABLE használatával definiálhatja az objektumokat, és további SQL-nézeteket, eljárásokat és beágyazott tábla-érték függvényeket adhat hozzá a táblákhoz.
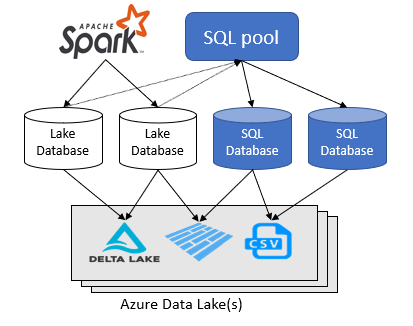
Ez a cikk az Azure Synapse Analytics kiszolgáló nélküli SQL-készletében lévő tóadatbázisokkal foglalkozik.
Az Azure Synapse Analytics lehetővé teszi, hogy lake-adatbázisokat és táblákat hozzon létre a Spark vagy az adatbázis-tervező használatával, majd elemezze az adatokat a tóadatbázisokban a kiszolgáló nélküli SQL-készlet használatával. Az Apache Spark-készleteken, a lake-adatbázissablonokon vagy a Dataverse-en létrehozott tóadatbázisok és táblák (parquet vagy CSV-alapú) automatikusan elérhetők a kiszolgáló nélküli SQL-készletmotorral való lekérdezéshez. A módosított tóadatbázisok és táblák egy idő után elérhetők a kiszolgáló nélküli SQL-készletben. A Sparkban vagy az adatbázis-tervezőben végrehajtott módosítások kiszolgáló nélküli környezetben való megjelenéséig késés tapasztalható.
Tóadatbázis kezelése
A Spark által létrehozott lake-adatbázisok kezeléséhez Apache Spark-készleteket vagy adatbázis-tervezőt használhat. Létrehozhat vagy törölhet például egy tóadatbázist egy Spark-készletfeladaton keresztül. A kiszolgáló nélküli SQL-készlet használatával nem hozhat létre tóadatbázist vagy objektumokat a tóadatbázisokban.
A Spark-adatbázis default a kiszolgáló nélküli SQL-készlet környezetében érhető el egy tóadatbázisként.default
Feljegyzés
Nem hozható létre tó és SQL-adatbázis a kiszolgáló nélküli SQL-készletben ugyanazzal a névvel.
A tóadatbázisokban lévő táblák nem módosíthatók kiszolgáló nélküli SQL-készletből. Az adatbázis-tervező vagy az Apache Spark-készletek segítségével módosíthatja a lake-adatbázist. A kiszolgáló nélküli SQL-készletben t-SQL-parancsokkal végezheti el a következő módosításokat egy tóadatbázisban:
- Nézetek, eljárások és beágyazott táblaértékfüggvények hozzáadása, módosítása és elvetése egy tóadatbázisban.
- Adatbázis-hatókörű Microsoft Entra-felhasználók hozzáadása és eltávolítása.
- Microsoft Entra-adatbázis felhasználóinak hozzáadása vagy eltávolítása a db_datareader szerepkörhöz. Az db_datareader szerepkörben lévő Microsoft Entra-adatbázis felhasználói jogosultak a tóadatbázis összes táblájának olvasására, de más adatbázisokból nem tudnak adatokat olvasni.
Biztonsági modell
A tóadatbázisok és -táblák két szinten vannak biztosítva:
- A háttértárolási réteget a Microsoft Entra-felhasználókhoz rendelje hozzá az alábbiak egyikével:
- Azure szerepköralapú hozzáférés-vezérlés (Azure RBAC)
- Azure attribútumalapú hozzáférés-vezérlési (Azure ABAC) szerepkör
- Hozzáférés-vezérlési lista (ACL) engedélyei
- Az SQL-réteg, ahol meghatározhat egy Microsoft Entra-felhasználót, és sql-engedélyeket adhat a tóadatokra hivatkozó táblák adataihoz
SELECT.
Lake biztonsági modell
A tóadatbázis-fájlokhoz való hozzáférés a tárrétegen lévő tóengedélyek használatával van szabályozva. Csak a Microsoft Entra-felhasználók használhatnak táblákat a tóadatbázisokban, és saját identitásukkal férhetnek hozzá a tó adataihoz.
A külső táblák alapjául szolgáló adatokhoz hozzáférést adhat egy biztonsági tagnak, például egy felhasználónak, egy Hozzárendelt szolgáltatásnévvel rendelkező Microsoft Entra-alkalmazásnak vagy egy biztonsági csoportnak. Adathozzáféréshez adja meg az alábbi engedélyeket:
- Engedélyek megadása
read (R)fájlokon (például a tábla alapjául szolgáló adatfájlokon). - Adjon
execute (X)engedélyt arra a mappára, ahol a fájlok tárolva vannak, és minden szülőmappára egészen a gyökérkönyvtárig. Ezekről az engedélyekről a hozzáférés-vezérlési listákon (ACL-eken) olvashat bővebben.
A biztonsági alapelveknek például a https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/ következőkre van szükségük:
-
execute (X)az összes mappára vonatkozó engedélyek a<fs>-től amyparquettable-ig. -
read (R)engedélyek amyparquettable-on és a mappán belüli fájlokon, hogy legyen képes olvasni egy táblázatot egy adatbázisban (szinkronizált vagy eredeti).
Ha egy biztonsági tag megköveteli, hogy objektumokat hozzon létre vagy helyezzen el objektumokat egy adatbázisban, további write (W) engedélyekre van szükség a raktármappában lévő mappákhoz és fájlokhoz. Az adatbázisok objektumainak módosítása kiszolgáló nélküli SQL-készletből nem lehetséges, csak Spark-készletekből vagy az adatbázis-tervezőből.
SQL biztonsági modell
Az Azure Synapse-munkaterület egy T-SQL-végpontot biztosít, amely lehetővé teszi a tóadatbázis lekérdezését a kiszolgáló nélküli SQL-készlet használatával. Az adathozzáférés mellett az SQL-felület lehetővé teszi annak szabályozását, hogy ki férhet hozzá a táblákhoz. Engedélyeznie kell egy felhasználónak, hogy a kiszolgáló nélküli SQL-készlet használatával hozzáférjen a megosztott tóadatbázisokhoz. A tóadatbázisokhoz háromféle felhasználó fér hozzá:
- Rendszergazdák: Rendelje hozzá a Synapse SQL-rendszergazdai munkaterületi szerepkört vagy sysadmin kiszolgálószintű szerepkört a serverless SQL-fürtön belül. Ez a szerepkör teljes ellenőrzést biztosít minden adatbázison. A Synapse-rendszergazdai és a Synapse SQL-rendszergazdai szerepkörök alapértelmezés szerint minden engedéllyel rendelkeznek a kiszolgáló nélküli SQL-készlet összes objektumához.
- Munkaterület olvasók: Adja meg a kiszolgálószintű engedélyeket a GRANT CONNECT ANY DATABASE és a GRANT SELECT ALL USER SECURABLES serverless SQL poolon egy bejelentkezéshez, amely lehetővé teszi számára, hogy bármely adatbázist elérjen és beolvasson. Ez jó választás lehet, ha olvasói/nem rendszergazdai hozzáférést rendel egy felhasználóhoz.
- Adatbázis-olvasók: Hozzon létre adatbázis-felhasználókat a Microsoft Entra ID-ból a tóadatbázisban, és vegye fel őket db_datareader szerepkörbe, amely lehetővé teszi számukra az adatok olvasását a tóadatbázisban.
További információ a hozzáférés-vezérlés beállításáról a megosztott adatbázisokon.
Egyéni SQL-objektumok a tóadatbázisokban
A Lake-adatbázisok lehetővé teszik egyéni T-SQL-objektumok, például sémák, eljárások, nézetek és beágyazott táblaértékfüggvények (iTVF-ek) létrehozását. Egyéni SQL-objektumok létrehozásához létre kell hoznia egy sémát, ahol elhelyezi az objektumokat. Az egyéni SQL-objektumok nem helyezhetők sémába dbo , mert a Sparkban, az adatbázis-tervezőben vagy a Dataverseben definiált tótáblák számára vannak fenntartva.
Fontos
Egyéni SQL-sémát kell létrehoznia, ahol elhelyezi az SQL-objektumokat. Az egyéni SQL-objektumok nem helyezhetők el a dbo sémában. A dbo séma a Sparkban vagy az adatbázis-tervezőben eredetileg létrehozott tótáblák számára van fenntartva.
Példák
SQL-adatbázis-olvasó létrehozása a Lake Database-ben
Ebben a példában hozzáadunk egy Microsoft Entra-felhasználót a tóadatbázishoz, aki megosztott táblákon keresztül tud adatokat olvasni. A felhasználók a kiszolgáló nélküli SQL-készleten keresztül kerülnek a tóadatbázisba. Ezután rendelje hozzá a felhasználót a db_datareader szerepkörhöz, hogy adatokat tudjon olvasni.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Munkaterületszintű adatolvasó létrehozása
A bejelentkezéssel GRANT CONNECT ANY DATABASE és GRANT SELECT ALL USER SECURABLES engedélyekkel minden táblát beolvashat a kiszolgáló nélküli SQL-készlet használatával, de nem hozhat létre SQL-adatbázisokat, és nem módosíthatja a bennük lévő objektumokat.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Ez a szkript lehetővé teszi, hogy rendszergazdai jogosultságokkal nem rendelkező felhasználókat hozzon létre, akik bármilyen táblát elolvashatnak a Lake-adatbázisokban.
Spark-adatbázis létrehozása és csatlakoztatása kiszolgáló nélküli SQL-készlettel
Először készítsen el egy új Spark-adatbázist a mytestlakedb nevű munkaterületen, egy olyan Spark-fürt használatával, amelyet már létrehozott a munkaterületén. Ezt például egy Spark C#-jegyzetfüzettel érheti el az alábbi .NET for Spark utasítással:
spark.sql("CREATE DATABASE mytestlakedb")
Rövid késés után láthatja a tóadatbázist a kiszolgáló nélküli SQL-készletből. Futtassa például a következő utasítást kiszolgáló nélküli SQL-készletből.
SELECT * FROM sys.databases;
Ellenőrizze, hogy mytestlakedb szerepel-e az eredmények között.
Egyéni SQL-objektumok létrehozása a Lake Database-ben
Az alábbi példa bemutatja, hogyan hozhat létre egyéni nézetet, eljárást és beágyazott táblaérték függvényt (iTVF) a reports sémában:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Kapcsolódó tartalom
- Az Azure Synapse Analytics megosztott metaadatai
- Az Azure Synapse Analytics megosztott metaadat-táblázatai
- Gyorsútmutató: Új tóadatbázis létrehozása adatbázissablonok használatával
- Oktatóanyag: Kiszolgáló nélküli SQL-készlet használata a Power BI Desktoppal & jelentés létrehozása
- Az Apache Spark for Azure Synapse külső tábladefinícióinak szinkronizálása kiszolgáló nélküli SQL-készletben
- Oktatóanyag: Adattavak feltárása és elemzése kiszolgáló nélküli SQL-készlettel