Rövid útmutató: Szándékok felismerése beszélgetési Language Understanding
Referenciadokumentáció | Csomag (NuGet) | További minták a GitHubon
Ebben a rövid útmutatóban a Beszéd- és nyelvi szolgáltatások segítségével fogja felismerni a mikrofonból rögzített hangadatok szándékait. Pontosabban a Speech szolgáltatással fogja felismerni a beszédet, és egy beszélgetési Language Understanding (CLU) modellt a szándékok azonosításához.
Fontos
A beszélgetési Language Understanding (CLU) a Speech SDK 1.25-ös vagy újabb verziójával elérhető c# és C++ verziókhoz.
Előfeltételek
- Azure-előfizetés – Ingyenes létrehozás
- Hozzon létre egy nyelvi erőforrást a Azure Portal.
- Szerezze be a Language erőforráskulcsot és a végpontot. A nyelvi erőforrás üzembe helyezése után válassza az Erőforrás megnyitása lehetőséget a kulcsok megtekintéséhez és kezeléséhez. További információ az Azure AI-szolgáltatások erőforrásairól: Az erőforrás kulcsainak lekérése.
- Hozzon létre egy Speech-erőforrást a Azure Portal.
- Kérje le a Speech-erőforráskulcsot és -régiót. A Speech-erőforrás üzembe helyezése után válassza az Erőforrás megnyitása lehetőséget a kulcsok megtekintéséhez és kezeléséhez. További információ az Azure AI-szolgáltatások erőforrásairól: Az erőforrás kulcsainak lekérése.
A környezet beállítása
A Speech SDK NuGet-csomagként érhető el, és a .NET Standard 2.0-t implementálja. A Speech SDK-t később telepítheti ebben az útmutatóban, de először tekintse meg az SDK telepítési útmutatóját a további követelményekért.
Környezeti változók beállítása
Ehhez a példához a , LANGUAGE_ENDPOINT, SPEECH_KEYés SPEECH_REGIONnevű LANGUAGE_KEYkörnyezeti változók szükségesek.
Az alkalmazásnak hitelesítenie kell magát az Azure AI-szolgáltatások erőforrásainak eléréséhez. Éles környezetben biztonságos módon tárolhatja és érheti el a hitelesítő adatait. Miután például beszerezte a kulcsát, írja be egy új környezeti változóba az alkalmazást futtató helyi gépen.
Tipp
Ne foglalja bele a kulcsot közvetlenül a kódba, és soha ne tegye közzé nyilvánosan. További hitelesítési lehetőségekért, például az Azure Key Vault, tekintse meg az Azure AI-szolgáltatások biztonságicikkét.
A környezeti változók beállításához nyisson meg egy konzolablakot, és kövesse az operációs rendszer és a fejlesztési környezet utasításait.
- A
LANGUAGE_KEYkörnyezeti változó beállításához cserélje le a elemetyour-language-keyaz erőforrás egyik kulcsára. - A
LANGUAGE_ENDPOINTkörnyezeti változó beállításához cserélje le a elemetyour-language-endpointaz erőforrás egyik régiójára. - A
SPEECH_KEYkörnyezeti változó beállításához cserélje le a elemetyour-speech-keyaz erőforrás egyik kulcsára. - A
SPEECH_REGIONkörnyezeti változó beállításához cserélje le a elemetyour-speech-regionaz erőforrás egyik régiójára.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Megjegyzés
Ha csak az aktuális futó konzolon kell hozzáférnie a környezeti változóhoz, a környezeti változót a helyett a következővel set állíthatja setxbe: .
A környezeti változók hozzáadása után előfordulhat, hogy újra kell indítania azokat a futó programokat, amelyeknek be kell olvasniuk a környezeti változót, beleértve a konzolablakot is. Ha például a Visual Studiót használja szerkesztőként, indítsa újra a Visual Studiót a példa futtatása előtt.
Beszélgetési Language Understanding projekt létrehozása
Miután létrehozott egy Nyelvi erőforrást, hozzon létre egy beszélgetési nyelvfelismerési projektet a Language Studióban. A projektek olyan munkaterületek, ahol az adatok alapján egyéni ML-modelleket lehet létrehozni. A projekthez csak Ön és mások férhetnek hozzá, akik hozzáférnek a használt nyelvi erőforráshoz.
Nyissa meg a Language Studiót , és jelentkezzen be az Azure-fiókjával.
Beszélgetési nyelvfelismerési projekt létrehozása
Ebben a rövid útmutatóban letöltheti ezt a minta otthonautomatizálási projektet , és importálhatja. Ez a projekt előre tudja jelezni a kívánt parancsokat a felhasználói bemenetből, például be- és kikapcsolhatja a világítást.
A Language Studio Kérdések és társalgási nyelv értelmezése szakaszában válassza a Beszélgetési nyelvfelismerés lehetőséget.
Ekkor megnyílik a Beszélgetési nyelvfelismerés projektek oldala. Az Új projekt létrehozása gomb mellett válassza az Importálás lehetőséget.
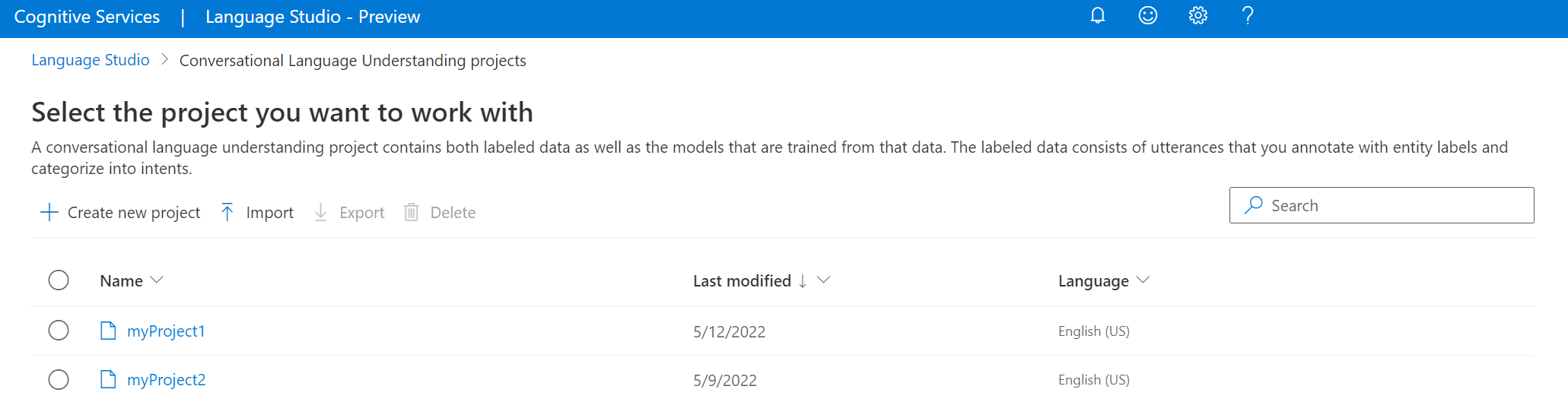
A megjelenő ablakban töltse fel az importálni kívánt JSON-fájlt. Győződjön meg arról, hogy a fájl a támogatott JSON-formátumot követi.


A feltöltés befejezése után a Sémadefiníció oldalra kerül. Ebben a rövid útmutatóban a séma már létre van hozva, és a kimondott szövegek már szándékokkal és entitásokkal vannak címkézve.
A modell betanítása
A projekt létrehozása után általában létre kell hoznia egy sémát , és meg kell címkéznie a kimondott szövegeket. Ebben a rövid útmutatóban már importáltunk egy kész projektet beépített sémával és címkézett kimondott szövegekkel.
A modellek betanításához el kell indítania egy betanítási feladatot. A sikeres betanítási feladat kimenete a betanított modell.
A modell betanítása a Language Studióban:
A bal oldali menüben válassza a Modell betanítása lehetőséget.
A felső menüben válassza a Betanítási feladat indítása lehetőséget.
Válassza az Új modell betanítása lehetőséget, és írjon be egy új modellnevet a szövegmezőbe. Ha egy meglévő modellt az új adatokon betanított modellre szeretne cserélni, válassza a Meglévő modell felülírása lehetőséget, majd válasszon ki egy meglévő modellt. A betanított modellek felülírása visszafordíthatatlan, de az új modell üzembe helyezéséig nem lesz hatással az üzembe helyezett modellekre.
Válassza ki a betanítási módot. A gyorsabb betanításhoz választhatja a Standard képzést , de csak angol nyelven érhető el. Választhat speciális képzést is, amely más nyelvekhez és többnyelvű projektekhez is támogatott, de hosszabb betanítási időt igényel. További tudnivalók a betanítási módokról.
Válasszon ki egy adatfelosztási módszert. A tesztelési készlet automatikus felosztása betanítási adatokból lehetőséget választhatja, ahol a rendszer a megadott százalékos arányok szerint felosztja a kimondott szövegeket a betanítási és a tesztelési készletek között. Vagy használhatja a betanítási és tesztelési adatok manuális felosztását is, ez a beállítás csak akkor engedélyezett, ha kimondott szövegeket adott hozzá a tesztkészlethez a kimondott szövegek címkézésekor.
Válassza a Betanítása gombot.
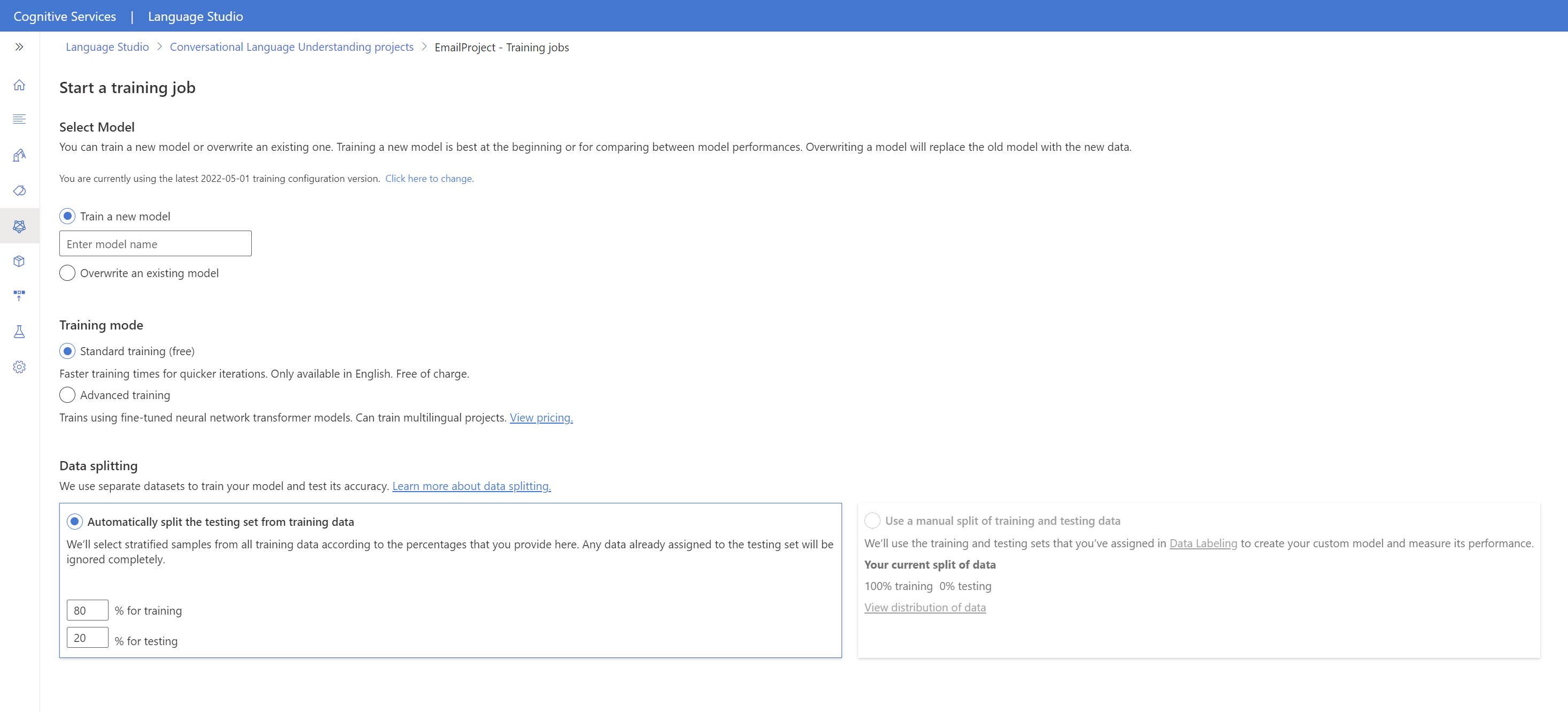
Válassza ki a betanítási feladat azonosítóját a listából. Megjelenik egy panel, ahol ellenőrizheti a betanítási folyamatot, a feladat állapotát és a feladat egyéb részleteit.
Megjegyzés
- Csak a sikeres betanítási feladatok hoznak létre modelleket.
- A betanítás eltarthat néhány perc és néhány óra között a kimondott szövegek számától függően.
- Egyszerre csak egy betanítási feladat futtatható. Nem indíthat el más betanítási feladatokat ugyanabban a projektben, amíg a futó feladat be nem fejeződik.
- A modellek betanítása során használt gépi tanulás rendszeresen frissül. Ha egy korábbi konfigurációs verzióra szeretne betanítást végezni, válassza a Kiválasztás elemet a Betanítási feladat indítása lapon, és válasszon ki egy korábbi verziót.

A modell üzembe helyezése
Általában a modell betanítása után érdemes áttekinteni annak kiértékelési részleteit. Ebben a rövid útmutatóban csak üzembe helyezi a modellt, és elérhetővé teszi a Language Studióban való kipróbáláshoz, vagy meghívhatja az előrejelzési API-t.
A modell üzembe helyezése a Language Studióban:
A bal oldali menüben válassza a Modell üzembe helyezése lehetőséget.
Az Üzembe helyezés hozzáadása varázsló elindításához válassza az Üzembe helyezés hozzáadása lehetőséget.
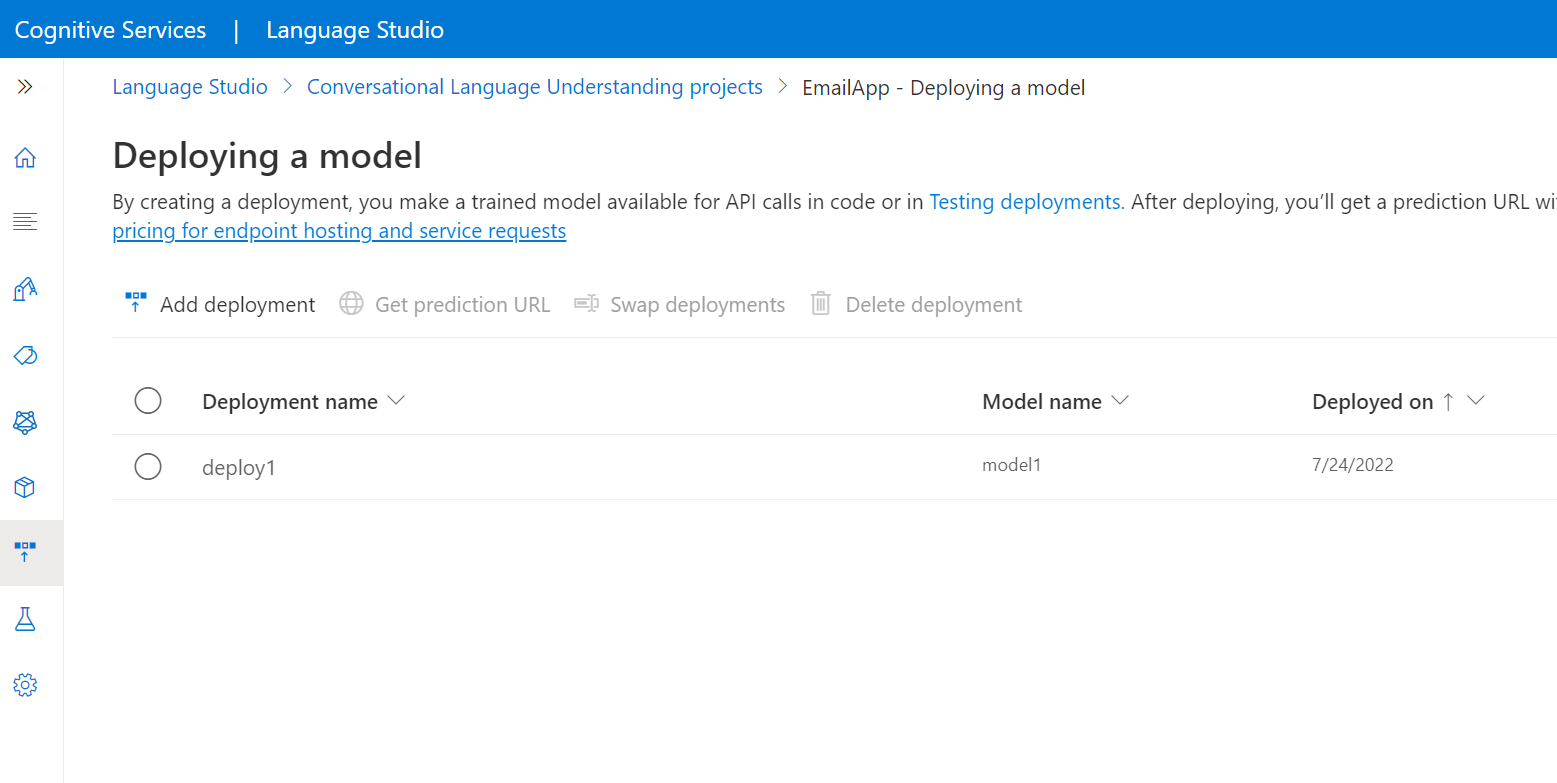
Válassza az Új üzembehelyezési név létrehozása lehetőséget egy új üzembe helyezés létrehozásához, és rendeljen hozzá egy betanított modellt az alábbi legördülő listából. A meglévő üzembehelyezési név felülírása lehetőséget választva hatékonyan lecserélheti a meglévő üzemelő példány által használt modellt.
Megjegyzés
Egy meglévő üzembe helyezés felülírásához nincs szükség a Prediction API-hívás módosítására, de a kapott eredmények az újonnan hozzárendelt modellen alapulnak.
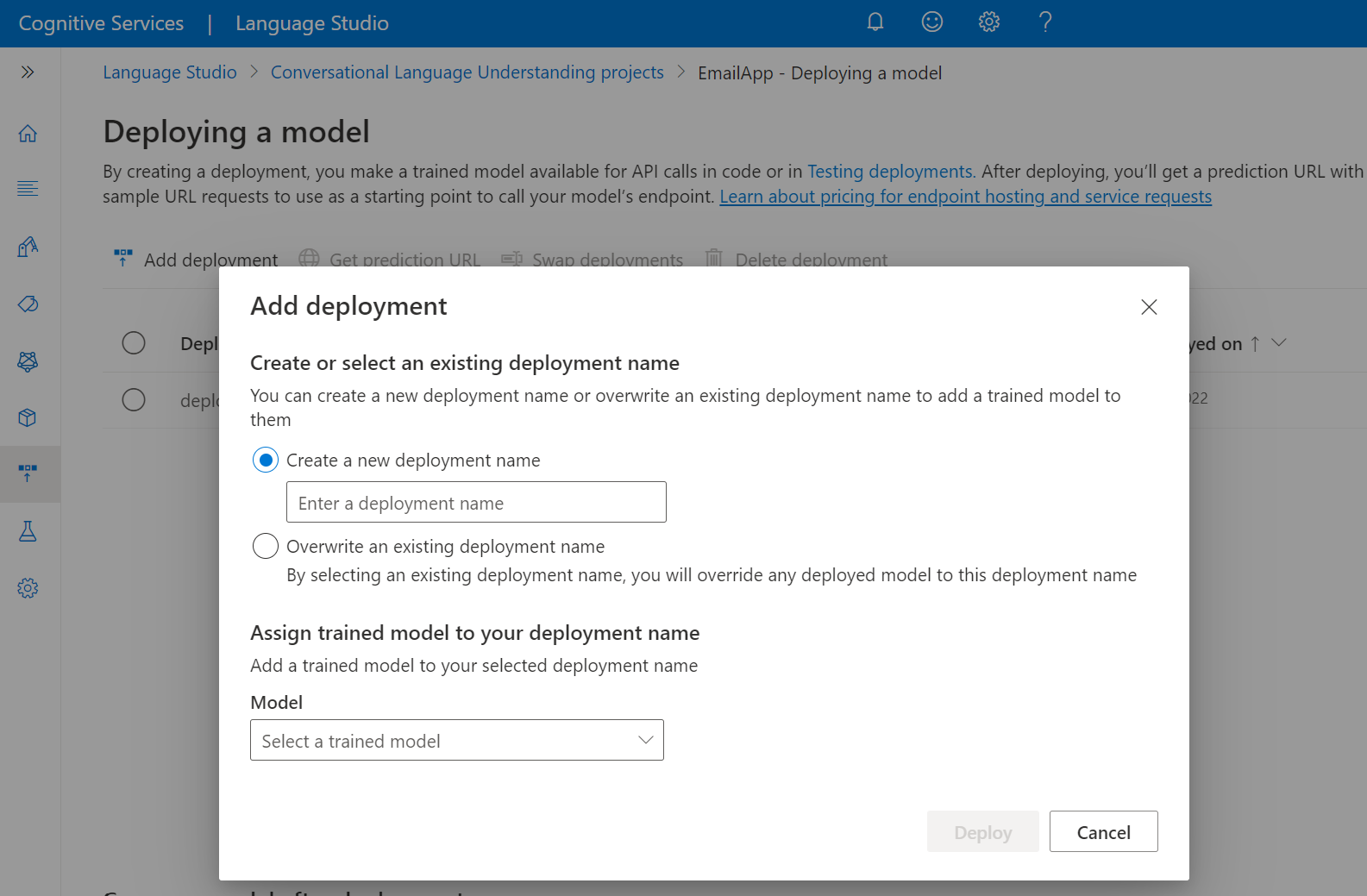
Válasszon ki egy betanított modellt a Modell legördülő listából.
Az üzembe helyezési feladat elindításához válassza az Üzembe helyezés lehetőséget.
A sikeres üzembe helyezés után mellette megjelenik egy lejárati dátum. Az üzembe helyezés lejárata az, amikor az üzembe helyezett modell nem lesz használható előrejelzéshez, ami általában tizenkét hónappal a betanítási konfiguráció lejárta után történik.


A következő szakaszban a projekt nevét és az üzembe helyezés nevét fogja használni.
Szándékok felismerése mikrofonból
Az alábbi lépéseket követve hozzon létre egy új konzolalkalmazást, és telepítse a Speech SDK-t.
Nyisson meg egy parancssort, ahol az új projektet szeretné, és hozzon létre egy konzolalkalmazást a .NET CLI-vel. A
Program.csfájlt a projektkönyvtárban kell létrehozni.dotnet new consoleTelepítse a Speech SDK-t az új projektbe a .NET CLI-vel.
dotnet add package Microsoft.CognitiveServices.SpeechCserélje le a tartalmát
Program.csa következő kódra.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Állítsa
Program.csbe a éscluDeploymentNameváltozókatcluProjectNamea projekt és az üzembe helyezés nevére. A CLU-projektek és az üzembe helyezés létrehozásáról további információt a Beszélgetési Language Understanding projekt létrehozása című témakörben talál.A beszédfelismerés nyelvének módosításához cserélje le a szöveget
en-USegy másik támogatott nyelvre. Példáules-ESa spanyol (Spanyolország) esetében. Az alapértelmezett nyelv azen-US, ha nem ad meg nyelvet. A beszélt nyelvek egyikének azonosításáról további információt a nyelvazonosítás című témakörben talál.
Az új konzolalkalmazás futtatásával indítsa el a beszédfelismerést egy mikrofonból:
dotnet run
Fontos
Győződjön meg arról, hogy a LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, és SPEECH_REGION környezeti változókat a fent leírtak szerint állította be. Ha nem állítja be ezeket a változókat, a minta hibaüzenettel fog meghiúsulni.
Amikor a rendszer kéri, beszéljen a mikrofonba. A beszédnek szövegként kell lennie:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Megjegyzés
A CLU JSON-válaszának LanguageUnderstandingServiceResponse_JsonResult tulajdonságon keresztüli támogatása a Speech SDK 1.26-os verziójában lett hozzáadva.
A szándékok a legvalószínűbb valószínűségi sorrendben lesznek visszaadva. Íme a JSON-kimenet formázott verziója, ahol a topIntentHomeAutomation.TurnOn megbízhatósági pontszám 0,97712576 (97,71%). A második legvalószínűbb szándék HomeAutomation.TurnOff 0,8985081 megbízhatósági pontszámmal (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Megjegyzések
Most, hogy befejezte a rövid útmutatót, íme néhány további szempont:
- Ez a példa a
RecognizeOnceAsyncművelettel legfeljebb 30 másodperces beszédelemeket ír át, vagy amíg a rendszer nem észlel csendet. További információ a hosszabb hang folyamatos felismeréséről, beleértve a többnyelvű beszélgetéseket is, lásd: A beszéd felismerése. - Ha hangfájlból szeretné felismerni a beszédet, használja
FromWavFileInputa következő helyett:FromDefaultMicrophoneInputusing var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Tömörített hangfájlok, például MP4 esetén telepítse a GStreamert, és használja a vagy
PushAudioInputStreama parancsotPullAudioInputStream. További információ: Tömörített bemeneti hang használata.
Az erőforrások eltávolítása
Az Azure Portal vagy az Azure Parancssori felület (CLI) használatával eltávolíthatja a létrehozott Nyelvi és beszédfelismerési erőforrásokat.
Referenciadokumentáció | Csomag (NuGet) | További minták a GitHubon
Ebben a rövid útmutatóban a Beszéd- és nyelvi szolgáltatások használatával fogja felismerni a mikrofonból rögzített hangadatok szándékait. Pontosabban a Speech szolgáltatással fogja felismerni a beszédet, és egy beszélgetési Language Understanding (CLU) modellt a szándékok azonosításához.
Fontos
A beszélgetési Language Understanding (CLU) a C# és a C++ verzióhoz érhető el a Speech SDK 1.25-ös vagy újabb verziójával.
Előfeltételek
- Azure-előfizetés – Ingyenes létrehozás
- Hozzon létre egy nyelvi erőforrást a Azure Portal.
- Szerezze be a Language erőforráskulcsot és a végpontot. A Nyelvi erőforrás üzembe helyezése után válassza az Erőforrás megnyitása lehetőséget a kulcsok megtekintéséhez és kezeléséhez. További információ az Azure AI-szolgáltatások erőforrásairól: Az erőforrás kulcsainak lekérése.
- Hozzon létre egy Speech-erőforrást a Azure Portal.
- Kérje le a Speech erőforráskulcsát és a régiót. A Speech-erőforrás üzembe helyezése után válassza az Erőforrás megnyitása lehetőséget a kulcsok megtekintéséhez és kezeléséhez. További információ az Azure AI-szolgáltatások erőforrásairól: Az erőforrás kulcsainak lekérése.
A környezet beállítása
A Speech SDK NuGet-csomagként érhető el, és a .NET Standard 2.0-t implementálja. Az útmutató későbbi részében telepítheti a Speech SDK-t, de először ellenőrizze az SDK telepítési útmutatóját , hogy van-e további követelmény.
Környezeti változók beállítása
Ehhez a példához a , , LANGUAGE_ENDPOINTSPEECH_KEYés SPEECH_REGIONnevű LANGUAGE_KEYkörnyezeti változók szükségesek.
Az azure AI-szolgáltatások erőforrásainak eléréséhez hitelesíteni kell az alkalmazást. Éles környezetben használjon biztonságos módot a hitelesítő adatok tárolására és elérésére. Miután például lekért egy kulcsot a Speech erőforráshoz, írja be egy új környezeti változóba az alkalmazást futtató helyi gépen.
Tipp
Ne foglalja bele a kulcsot közvetlenül a kódba, és soha ne tegye közzé nyilvánosan. Az Azure AI-szolgáltatások biztonsági cikkében további hitelesítési lehetőségeket talál, például az Azure Key Vault.
A környezeti változók beállításához nyisson meg egy konzolablakot, és kövesse az operációs rendszer és a fejlesztési környezet utasításait.
- A
LANGUAGE_KEYkörnyezeti változó beállításához cserélje le a elemetyour-language-keyaz erőforrás egyik kulcsára. - A
LANGUAGE_ENDPOINTkörnyezeti változó beállításához cserélje le a elemetyour-language-endpointaz erőforrás egyik régiójára. - A
SPEECH_KEYkörnyezeti változó beállításához cserélje le a elemetyour-speech-keyaz erőforrás egyik kulcsára. - A
SPEECH_REGIONkörnyezeti változó beállításához cserélje le a elemetyour-speech-regionaz erőforrás egyik régiójára.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Megjegyzés
Ha csak az aktuális futó konzolon kell hozzáférnie a környezeti változóhoz, a környezeti változót a helyett a következővel set állíthatja setxbe: .
A környezeti változók hozzáadása után előfordulhat, hogy újra kell indítania a futó programokat, amelyeknek be kell olvasniuk a környezeti változót, beleértve a konzolablakot is. Ha például a Visual Studiót használja szerkesztőként, indítsa újra a Visual Studiót a példa futtatása előtt.
Beszélgetési Language Understanding projekt létrehozása
Miután létrehozott egy Nyelvi erőforrást, hozzon létre egy beszélgetési nyelvfelismerési projektet a Language Studióban. A projektek olyan munkaterületek, ahol az adatok alapján egyéni ML-modelleket lehet létrehozni. A projekthez csak Ön és mások férhetnek hozzá, akik hozzáférnek a használt nyelvi erőforráshoz.
Nyissa meg a Language Studiót , és jelentkezzen be az Azure-fiókjával.
Beszélgetési nyelvfelismerési projekt létrehozása
Ebben a rövid útmutatóban letöltheti ezt a minta otthonautomatizálási projektet , és importálhatja. Ez a projekt előre tudja jelezni a kívánt parancsokat a felhasználói bemenetből, például be- és kikapcsolhatja a világítást.
A Language Studio Kérdések és társalgási nyelv értelmezése szakaszában válassza a Beszélgetési nyelvfelismerés lehetőséget.
Ekkor megnyílik a Beszélgetési nyelvfelismerés projektek oldala. Az Új projekt létrehozása gomb mellett válassza az Importálás lehetőséget.
A megjelenő ablakban töltse fel az importálni kívánt JSON-fájlt. Győződjön meg arról, hogy a fájl a támogatott JSON-formátumot követi.
A feltöltés befejezése után a Sémadefiníció oldalra kerül. Ebben a rövid útmutatóban a séma már létre van hozva, és a kimondott szövegek már szándékokkal és entitásokkal vannak címkézve.
A modell betanítása
A projekt létrehozása után általában létre kell hoznia egy sémát , és meg kell címkéznie a kimondott szövegeket. Ebben a rövid útmutatóban már importáltunk egy kész projektet beépített sémával és címkézett kimondott szövegekkel.
A modellek betanításához el kell indítania egy betanítási feladatot. A sikeres betanítási feladat kimenete a betanított modell.
A modell betanítása a Language Studióban:
A bal oldali menüben válassza a Modell betanítása lehetőséget.
A felső menüben válassza a Betanítási feladat indítása lehetőséget.
Válassza az Új modell betanítása lehetőséget, és írjon be egy új modellnevet a szövegmezőbe. Ha egy meglévő modellt az új adatokon betanított modellre szeretne cserélni, válassza a Meglévő modell felülírása lehetőséget, majd válasszon ki egy meglévő modellt. A betanított modellek felülírása visszafordíthatatlan, de az új modell üzembe helyezéséig nem lesz hatással az üzembe helyezett modellekre.
Válassza ki a betanítási módot. A gyorsabb betanításhoz választhatja a Standard képzést , de csak angol nyelven érhető el. Választhat speciális képzést is, amely más nyelvekhez és többnyelvű projektekhez is támogatott, de hosszabb betanítási időt igényel. További tudnivalók a betanítási módokról.
Válasszon ki egy adatfelosztási módszert. A tesztelési készlet automatikus felosztása betanítási adatokból lehetőséget választhatja, ahol a rendszer a megadott százalékos arányok szerint felosztja a kimondott szövegeket a betanítási és a tesztelési készletek között. Vagy használhatja a betanítási és tesztelési adatok manuális felosztását is, ez a beállítás csak akkor engedélyezett, ha kimondott szövegeket adott hozzá a tesztkészlethez a kimondott szövegek címkézésekor.
Válassza a Betanítása gombot.
Válassza ki a betanítási feladat azonosítóját a listából. Megjelenik egy panel, ahol ellenőrizheti a betanítási folyamatot, a feladat állapotát és a feladat egyéb részleteit.
Megjegyzés
- Csak a sikeres betanítási feladatok hoznak létre modelleket.
- A betanítás eltarthat néhány perc és néhány óra között a kimondott szövegek számától függően.
- Egyszerre csak egy betanítási feladat futtatható. Nem indíthat el más betanítási feladatokat ugyanabban a projektben, amíg a futó feladat be nem fejeződik.
- A modellek betanítása során használt gépi tanulás rendszeresen frissül. Ha egy korábbi konfigurációs verzióra szeretne betanítást végezni, válassza a Kiválasztás itt lehetőséget a betanítási feladat indítása lapon, és válasszon ki egy korábbi verziót.
A modell üzembe helyezése
Általában a modell betanítása után érdemes áttekinteni annak kiértékelési részleteit. Ebben a rövid útmutatóban csak üzembe helyezi a modellt, és elérhetővé teszi a Language Studióban való kipróbáláshoz, vagy meghívhatja az előrejelzési API-t.
A modell üzembe helyezése a Language Studióban:
A bal oldali menüben válassza a Modell üzembe helyezése lehetőséget.
Az Üzembe helyezés hozzáadása varázsló elindításához válassza az Üzembe helyezés hozzáadása lehetőséget.
Válassza az Új üzembehelyezési név létrehozása lehetőséget egy új üzembe helyezés létrehozásához, és rendeljen hozzá egy betanított modellt az alábbi legördülő listából. A meglévő üzembe helyezési név felülírása lehetőséget választva hatékonyan lecserélheti a meglévő üzemelő példány által használt modellt.
Megjegyzés
Egy meglévő üzemelő példány felülírásához nincs szükség a Prediction API-hívás módosítására, de a kapott eredmények az újonnan hozzárendelt modellen alapulnak.
Válasszon ki egy betanított modellt a Modell legördülő listából.
Az üzembe helyezési feladat elindításához válassza az Üzembe helyezés lehetőséget.
Az üzembe helyezés sikerességét követően megjelenik mellette egy lejárati dátum. Az üzembe helyezés lejárata az, amikor az üzembe helyezett modell nem lesz elérhető az előrejelzéshez, ami általában tizenkét hónappal a betanítási konfiguráció lejárta után következik be.
A következő szakaszban a projekt nevét és az üzembe helyezés nevét fogja használni.
Szándékok felismerése mikrofonból
Az alábbi lépéseket követve hozzon létre egy új konzolalkalmazást, és telepítse a Speech SDK-t.
Hozzon létre egy új C++ konzolprojektet Visual Studio Community 2022-ben nevű néven
SpeechRecognition.Telepítse a Speech SDK-t az új projektbe a NuGet-csomagkezelővel.
Install-Package Microsoft.CognitiveServices.SpeechCserélje le a tartalmát
SpeechRecognition.cppa következő kódra:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }A és
SpeechRecognition.cppacluProjectNamecluDeploymentNameváltozót állítsa be a projekt és az üzembe helyezés nevére. A CLU-projekt és az üzembe helyezés létrehozásáról további információt a Beszélgetési Language Understanding projekt létrehozása című témakörben talál.A beszédfelismerés nyelvének módosításához cserélje le a elemet
en-USegy másik támogatott nyelvre. Példáules-ESa spanyol (Spanyolország) esetében. Az alapértelmezett nyelv azen-US, ha nem ad meg nyelvet. A több beszélt nyelv egyikének azonosításával kapcsolatos részletekért tekintse meg a nyelvazonosítást ismertető cikket.
Hozza létre és futtassa az új konzolalkalmazást a beszédfelismerés mikrofonból való elindításához.
Fontos
Győződjön meg arról, hogy a ,LANGUAGE_ENDPOINT , SPEECH_KEYés SPEECH_REGION környezeti változókat a LANGUAGE_KEYfent leírtak szerint állította be. Ha nem állítja be ezeket a változókat, a minta hibaüzenettel fog meghiúsulni.
Amikor a rendszer kéri, beszéljen a mikrofonba. A beszédnek szövegként kell lennie:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Megjegyzés
A CLU JSON-válaszának támogatása a LanguageUnderstandingServiceResponse_JsonResult tulajdonságon keresztül lett hozzáadva a Speech SDK 1.26-os verziójához.
A szándékok a legvalószínűbb valószínűségi sorrendben lesznek visszaadva. Íme a JSON-kimenet formázott verziója, ahol a topIntentHomeAutomation.TurnOn megbízhatósági pontszám 0,97712576 (97,71%). A második legvalószínűbb szándék a HomeAutomation.TurnOff 0,8985081 megbízhatósági pontszámmal (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Megjegyzések
Most, hogy befejezte a rövid útmutatót, íme néhány további szempont:
- Ez a példa a
RecognizeOnceAsyncművelettel legfeljebb 30 másodperces beszédelemeket ír át, vagy amíg a rendszer nem észleli a csendet. További információ a hosszabb hang folyamatos felismeréséről, beleértve a többnyelvű beszélgetéseket is, lásd: A beszéd felismerése. - Ha hangfájlból szeretné felismerni a beszédet, használja
FromWavFileInputa következő helyett:FromDefaultMicrophoneInputauto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Tömörített hangfájlok, például MP4 esetén telepítse a GStreamert, és használja a vagy
PushAudioInputStreama parancsotPullAudioInputStream. További információ: A tömörített bemeneti hang használata.
Az erőforrások eltávolítása
Az Azure Portal vagy az Azure Parancssori felület (CLI) használatával eltávolíthatja a létrehozott Nyelvi és beszédfelismerési erőforrásokat.
Referenciadokumentáció | További minták a GitHubon
A Java-hoz készült Speech SDK nem támogatja a beszélgetési nyelvfelismerés (CLU) szándékfelismerését. Válasszon egy másik programozási nyelvet vagy a cikk elején hivatkozott Java-referenciát és -mintákat.