Az üzembe helyezett gyorsfolyamat-alkalmazások minőségének és tokenhasználatának monitorozása
Fontos
A cikkben ismertetett funkciók némelyike csak előzetes verzióban érhető el. Ez az előzetes verzió szolgáltatásszint-szerződés nélkül érhető el, és éles számítási feladatokhoz nem javasoljuk. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. További információ: Kiegészítő használati feltételek a Microsoft Azure előzetes verziójú termékeihez.
Az éles környezetben üzembe helyezett alkalmazások monitorozása elengedhetetlen része a generatív AI-alkalmazások életciklusának. Az adatok és a fogyasztói viselkedés változásai idővel befolyásolhatják az alkalmazást, ami elavult rendszereket eredményez, amelyek negatívan befolyásolják az üzleti eredményeket, és a szervezeteket megfelelőségi, gazdasági és hírnévbeli kockázatoknak teszik ki.
A generatív AI-alkalmazások Azure AI-monitorozása lehetővé teszi az alkalmazások éles környezetben történő monitorozását a tokenhasználat, a létrehozás minősége és a működési metrikák alapján.
A folyamat gyors üzembe helyezésének figyelésére szolgáló integrációk lehetővé teszik a következő lehetőségeket:
- Éles következtetési adatok gyűjtése az üzembe helyezett parancssori alkalmazásból.
- Olyan felelős AI-kiértékelési metrikákat alkalmazhat, mint például az alapok, a koherencia, a fluency és a relevancia, amelyek a gyors folyamatértékelési metrikákkal együttműködve működnek.
- Monitorozza a kéréseket, a befejezést és a teljes jogkivonat-használatot az egyes modelltelepítésekben a parancssori folyamatban.
- Figyelje a működési metrikákat, például a kérések számát, a késést és a hibaarányt.
- A monitorozás ismétlődő futtatásához használjon előre konfigurált riasztásokat és alapértelmezett értékeket.
- Adatvizualizációk használata és speciális viselkedés konfigurálása az Azure AI Studióban.
Előfeltételek
A cikkben ismertetett lépések végrehajtása előtt győződjön meg arról, hogy rendelkezik a következő előfeltételekkel:
Érvényes fizetési móddal rendelkező Azure-előfizetés. Az ingyenes vagy próbaverziós Azure-előfizetések nem működnek. Ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy fizetős Azure-fiókot .
Üzembe helyezésre kész parancssori folyamat. Ha nincs ilyenje, olvassa el a Parancssori folyamat fejlesztése című témakört.
Az Azure szerepköralapú hozzáférés-vezérlései (Azure RBAC) az Azure AI Studióban végzett műveletekhez való hozzáférést biztosítják. A cikkben ismertetett lépések végrehajtásához a felhasználói fiókhoz hozzá kell rendelni az Azure AI Developer szerepkört az erőforráscsoportban. Az engedélyekről további információt az Azure AI Studio szerepköralapú hozzáférés-vezérlésében talál.
A metrikák monitorozására vonatkozó követelmények
A monitorozási metrikákat bizonyos, speciális kiértékelési utasítások (parancssori sablonok) konfigurált, korszerű GPT-nyelvi modellek generálják. Ezek a modellek kiértékelő modellként működnek a szekvencia-sorrendi feladatokhoz. Ennek a technikának a használata monitorozási metrikák létrehozásához erős empirikus eredményeket és magas korrelációt mutat az emberi ítélőképességgel a szabványos generatív AI-kiértékelési metrikákhoz képest. A folyamat gyors kiértékelésével kapcsolatos további információkért tekintse meg a tömeges tesztelés elküldését és a folyamat kiértékelését, valamint a generatív AI-hez tartozó kiértékelési és monitorozási metrikákat.
A monitorozási metrikákat létrehozó GPT-modellek a következők. Ezek a GPT-modellek az Azure OpenAI-erőforrásként való monitorozással és konfigurálással támogatottak:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Támogatott metrikák monitorozáshoz
A monitorozáshoz a következő metrikák támogatottak:
| Metrika | Leírás |
|---|---|
| Alapozottság | Azt méri, hogy a modell által létrehozott válaszok mennyire összhangban vannak a forrásadatokból (felhasználó által definiált környezetből) származó információkkal. |
| Relevancia | Azt méri, hogy a modell által generált válaszok mennyire lényegesek és közvetlenül kapcsolódnak az adott kérdésekhez. |
| Koherencia | Méri a modell által generált válaszok logikai konzisztens és összekapcsolt mértékét. |
| Folyékonyan | Egy generatív AI előrejelzett válaszának nyelvtani jártasságát méri. |
Oszlopnév-leképezés
A folyamat létrehozásakor meg kell győződnie arról, hogy az oszlopnevek le vannak képezve. A következő bemeneti adatoszlopnevek a generációs biztonság és a minőség mérésére szolgálnak:
| Bemeneti oszlop neve | Definíció | Kötelező/nem kötelező |
|---|---|---|
| Kérdés | Az eredeti kérés (más néven "bemenetek" vagy "kérdés") | Kötelező |
| Válasz | A visszaadott API-hívás végleges befejezése (más néven "kimenetek" vagy "válasz") | Kötelező |
| Környezet | Az API-hívásnak küldött környezeti adatok, valamint az eredeti kérés. Ha például csak bizonyos minősített adatforrásokból vagy webhelyről szeretne keresési eredményeket kapni, ezt a kontextust a kiértékelési lépésekben határozhatja meg. | Választható |
A metrikákhoz szükséges paraméterek
Az adategységben konfigurált paraméterek határozzák meg, hogy milyen metrikákat hozhat létre az alábbi táblázat szerint:
| Metrika | Kérdés | Válasz | Környezet |
|---|---|---|---|
| Koherencia | Szükséges | Szükséges | - |
| Folyékonyan | Szükséges | Szükséges | - |
| Alapozottság | Szükséges | Szükséges | Szükséges |
| Relevancia | Szükséges | Szükséges | Szükséges |
További információ az egyes metrikák konkrét adatleképezési követelményeiről: Kérdés megválaszolása metrikakövetelmények.
Monitorozás beállítása a parancssori folyamathoz
A gyorsfolyamat-alkalmazás figyelésének beállításához először a parancssori alkalmazást kell üzembe helyeznie a következtetési adatgyűjtéssel, majd konfigurálhatja az üzembe helyezett alkalmazás figyelését.
A parancssori alkalmazás üzembe helyezése következtetési adatgyűjtéssel
Ebben a szakaszban megtudhatja, hogyan helyezheti üzembe a parancssori folyamatot úgy, hogy engedélyezve van a következtetési adatgyűjtés. A parancssori folyamat üzembe helyezésével kapcsolatos részletes információkért lásd : Folyamat üzembe helyezése valós idejű következtetés céljából.
Nyissa meg az Azure AI Studio-projektet.
A bal oldali navigációs sávon nyissa meg az Eszközök>parancssori folyamatot.
Válassza ki a korábban létrehozott parancssori folyamatot.
Feljegyzés
Ez a cikk feltételezi, hogy már létrehozott egy parancssori folyamatot, amely készen áll az üzembe helyezésre. Ha nincs ilyenje, olvassa el a Parancssori folyamat fejlesztése című témakört.
Ellenőrizze, hogy a folyamat sikeresen fut-e, és hogy a szükséges bemenetek és kimenetek konfigurálva vannak-e az értékelni kívánt metrikákhoz.
A minimálisan szükséges paraméterek (kérdések/bemenetek és válasz/kimenetek) megadása csak két metrikát biztosít: a koherenciát és a flunciát. A folyamatot a monitorozási metrikák követelményei című szakaszban leírtak szerint kell konfigurálnia. Ez a példa a (Kérdés) és
chat_historya (Környezet) értéket használjaquestiona folyamat bemeneteként, aanswer(Válasz) pedig a folyamat kimenetét.Válassza az Üzembe helyezés lehetőséget a folyamat üzembe helyezésének megkezdéséhez.
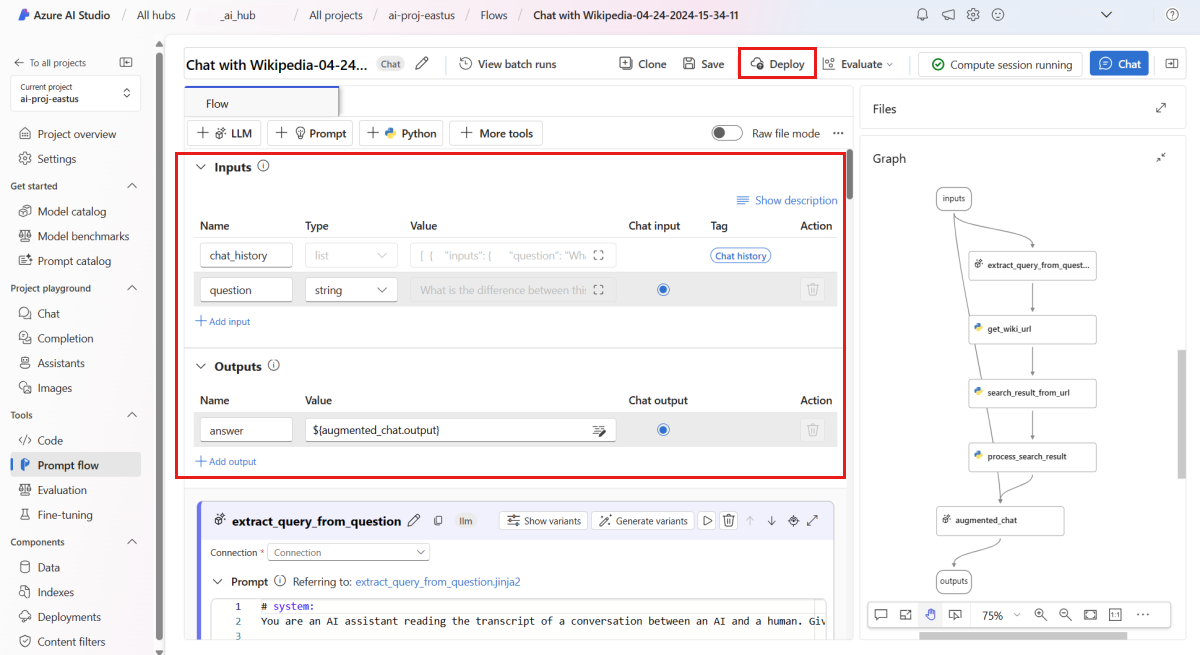
Az üzembe helyezési ablakban győződjön meg arról, hogy engedélyezve van a következtetési adatgyűjtés , amely zökkenőmentesen összegyűjti az alkalmazás következtetési adatait a Blob Storage-ba. Ez az adatgyűjtés szükséges a monitorozáshoz.

A Speciális beállítások elvégzéséhez folytassa az üzembe helyezési ablakban található lépéseket.
A "Véleményezés" lapon tekintse át az üzembehelyezési konfigurációt, és válassza a Létrehozás lehetőséget a folyamat üzembe helyezéséhez.

Feljegyzés
Alapértelmezés szerint a rendszer összegyűjti az üzembe helyezett parancssori alkalmazás összes bemenetét és kimenetét a Blob Storage-ba. Mivel a felhasználók meghívják az üzembe helyezést, a rendszer összegyűjti az adatokat, amelyeket a figyelő használ fel.
Válassza az üzembe helyezési lapon a Tesztelés lapot, és tesztelje az üzembe helyezést, hogy biztosan megfelelően működjön.

Feljegyzés
A figyeléshez legalább egy adatpontnak az üzembe helyezés Teszt lapjától eltérő forrásból kell származania. Javasoljuk, hogy a Felhasználás lapon elérhető REST API használatával küldjön mintakéréseket az üzemelő példánynak. További információ a mintakérések központi telepítésre való küldéséről: Online üzembe helyezés létrehozása.




Figyelés konfigurálása
Ebben a szakaszban megtudhatja, hogyan konfigurálhatja az üzembe helyezett parancssori alkalmazás figyelését.
A bal oldali navigációs sávon lépjen az Összetevők üzembe helyezések> elemre.
Válassza ki az imént létrehozott parancssori folyamat üzembe helyezését.
Válassza az Engedélyezés lehetőséget a Generációk minőségének monitorozása párbeszédpanelen.

Kezdje el konfigurálni a monitorozást a kívánt metrikák kiválasztásával.
Ellenőrizze, hogy az oszlopnevek le vannak-e képezve a folyamatból az Oszlopnév-megfeleltetésben meghatározottak szerint.
Válassza ki azt az Azure OpenAI-Csatlakozás iont és üzembe helyezést, amellyel monitorozást szeretne végezni a gyorsfolyamat-alkalmazáshoz.
A Speciális beállítások lehetőséget választva további konfigurálható beállításokat jeleníthet meg.
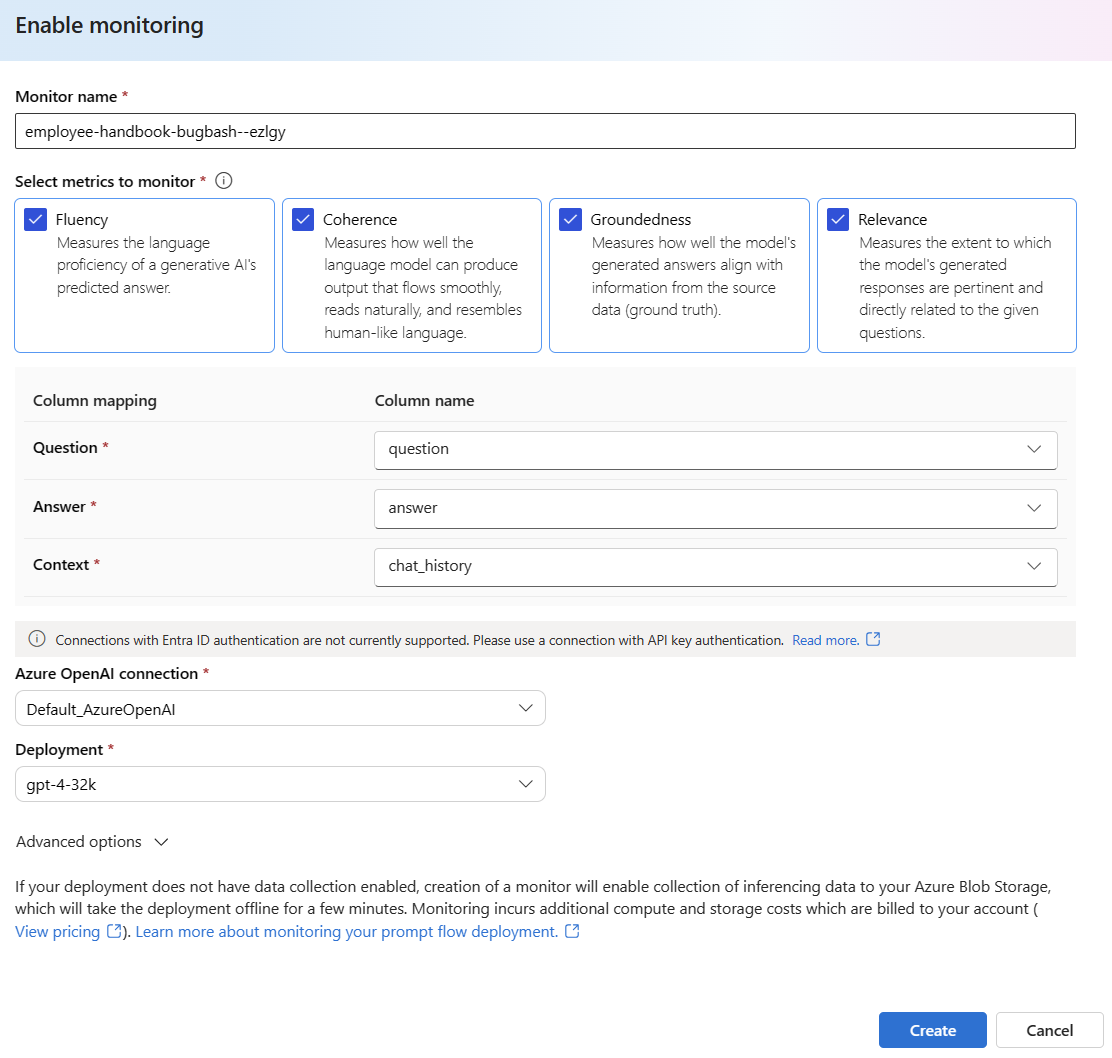
Módosítsa a mintavételezési sebességet, a konfigurált metrikák küszöbértékeit, és adja meg azokat az e-mail-címeket, amelyeknek riasztásokat kell kapniuk, ha egy adott metrika átlagos pontszáma a küszöbérték alá csökken.

Feljegyzés
Ha az üzembe helyezés nem engedélyezi az adatgyűjtést, a figyelő létrehozása lehetővé teszi a következtetési adatok gyűjtését az Azure Blob Storage-ba, amely néhány percig offline állapotba állítja az üzembe helyezést.
A figyelő létrehozásához válassza a Létrehozás lehetőséget .



Figyelési eredmények felhasználása
A monitor létrehozása után a rendszer naponta futtatja a tokenhasználatot és a generációs minőségi metrikákat.
A figyelési eredmények megtekintéséhez nyissa meg az üzemelő példány Figyelés (előzetes verzió) lapját. Itt megtekintheti a figyelési eredmények áttekintését a kiválasztott időablakban. A dátumválasztóval módosíthatja a figyelt adatok időablakát. Az alábbi metrikák érhetők el ebben az áttekintésben:
- Kérések teljes száma: Az üzembe helyezésnek küldött kérelmek teljes száma a kiválasztott időablakban.
- Összes jogkivonat száma: Az üzembe helyezés által a kiválasztott időablakban használt tokenek teljes száma.
- Parancssori jogkivonatok száma: Az üzembe helyezés által a kiválasztott időablakban használt parancssori jogkivonatok száma.
- Befejezési jogkivonatok száma: Az üzembe helyezés által a kiválasztott időablakban használt befejezési jogkivonatok száma.
Tekintse meg a metrikákat a Jogkivonat használata lapon (ez a lap alapértelmezés szerint ki van jelölve). Itt megtekintheti az alkalmazás tokenhasználatát az idő függvényében. A parancssori és befejezési jogkivonatok időbeli eloszlását is megtekintheti. A Trendline hatókörét úgy módosíthatja, hogy a teljes alkalmazás összes jogkivonatát monitorozza, vagy az alkalmazáson belül használt adott üzemelő példány (például gpt-4) jogkivonat-használatát.

Az alkalmazás minőségének időbeli monitorozásához nyissa meg a Generáció minőség lapját. Az idődiagram a következő metrikákat jeleníti meg:
- Szabálysértések száma: Egy adott metrika (például Fluency) megsértéseinek száma a kijelölt időkereten belül elkövetett szabálysértések összege. A metrikák esetében szabálysértés történik a metrikák kiszámításakor (az alapértelmezett érték napi), ha a metrika számított értéke a megadott küszöbérték alá esik.
- Átlagos pontszám: Egy adott metrika (például Fluency) átlagos pontszáma az összes példány (vagy kérés) pontszámainak összege, osztva a példányok (vagy kérelmek) számával a kiválasztott időablakban.
A generációs minőségi szabálysértési kártya a kijelölt időkereten belül jeleníti meg a szabálysértési arányt . A szabálysértési arány a szabálysértések száma a lehetséges szabálysértések teljes számával osztva. A beállításokban módosíthatja a metrikák küszöbértékeit. Alapértelmezés szerint a metrikák naponta lesznek kiszámítva; ez a gyakoriság a beállításokban is módosítható.
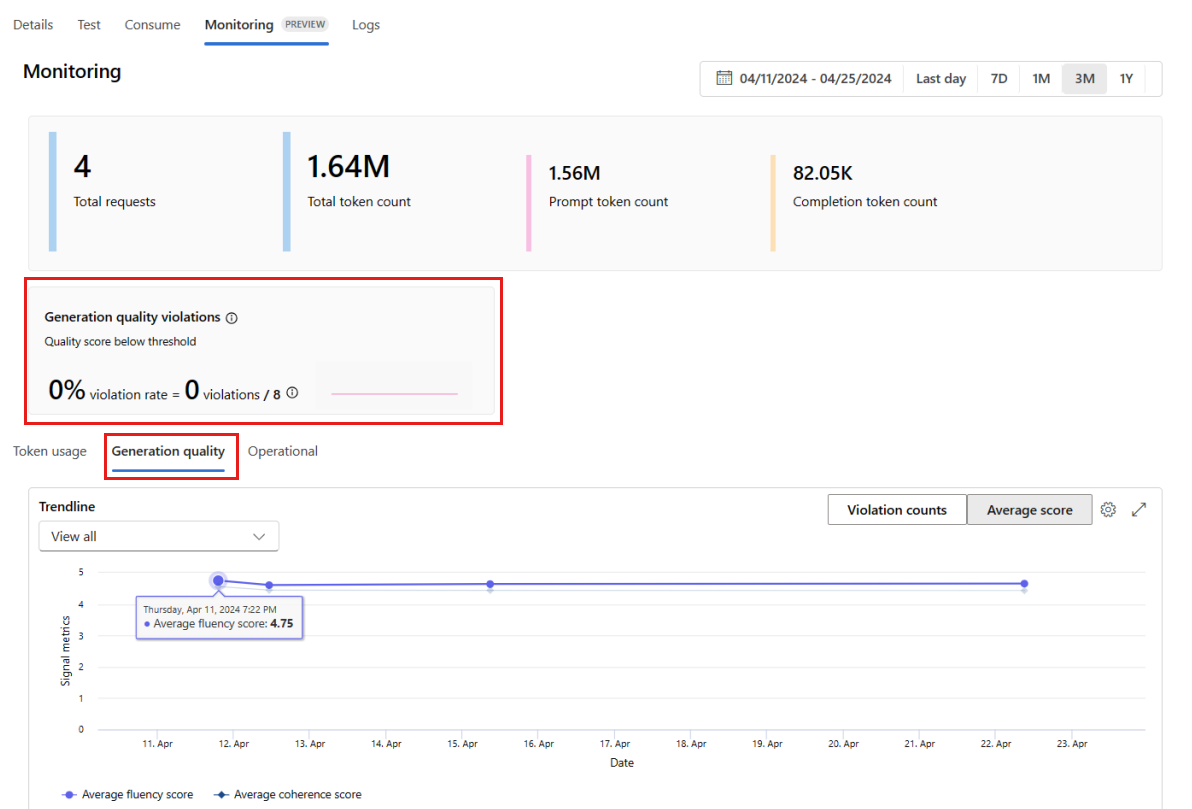
A Figyelés (előzetes verzió) lapon átfogó táblázatot is megtekinthet az üzembe helyezésnek küldött összes mintakérésről a kiválasztott időablakban.
Feljegyzés
A monitorozás az alapértelmezett mintavételezési arányt 10%-ra állítja. Ez azt jelenti, hogy ha 100 kérést küld az üzembe helyezéshez, 10-et mintát kap, és a generációs minőségi metrikák kiszámításához használja. A mintavételezési sebességet a beállítások között módosíthatja.

Az adott kérés nyomkövetési részleteinek megtekintéséhez válassza a táblázat egy sorának jobb oldalán található Nyomkövetés gombot. Ez a nézet átfogó nyomkövetési adatokat biztosít az alkalmazásnak küldött kéréshez.

Zárja be a Nyomkövetés nézetet.
Az Üzemelés lapra lépve közel valós időben tekintheti meg az üzembe helyezés működési mérőszámait. A következő működési metrikákat támogatjuk:
- Kérésszám
- Késés
- Hibaarány






Az üzembe helyezés Monitorozás (előzetes verzió) lapján található eredmények elemzéseket nyújtanak, amelyekkel proaktívan javíthatja a gyors folyamatalkalmazás teljesítményét.
Speciális monitorozási konfiguráció az SDK 2-vel
A monitorozás az SDK v2-vel is támogatja a speciális konfigurációs beállításokat. A következő forgatókönyvek támogatottak:
A jogkivonatok használatának monitorozásának engedélyezése
Ha csak a jogkivonat-használat figyelését szeretné engedélyezni az üzembe helyezett parancssori alkalmazáshoz, az alábbi szkriptet a forgatókönyvéhez igazíthatja:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
A generációs minőség monitorozásának engedélyezése
Ha csak a generációs minőségfigyelést szeretné engedélyezni az üzembe helyezett parancssori alkalmazáshoz, az alábbi szkriptet a forgatókönyvhöz igazíthatja:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Miután létrehozta a monitort az SDK-ból, felhasználhatja a figyelési eredményeket az AI Studióban.
Kapcsolódó tartalom
- További információ az Azure AI Studióban elvégezhető műveletekről
- Válaszok a gyakori kérdésekre az Azure AI GYIK-cikkben
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: