Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben az oktatóanyagban létrehoz egy Java Retrieval Augmented Generation (RAG) alkalmazást a Spring Boot, az Azure OpenAI és az Azure AI Search használatával, majd üzembe helyezi az Azure App Service szolgáltatásban. Ez az alkalmazás bemutatja, hogyan implementálhat egy csevegőfelületet, amely információkat kér le a saját dokumentumaiból, és az AI-szolgáltatásokat használja Azure, hogy pontos, környezettudatos válaszokat biztosítson a megfelelő idézetekkel. A megoldás felügyelt identitásokat használ a szolgáltatások közötti jelszó nélküli hitelesítéshez.
Jótanács
Bár ez az oktatóanyag a Spring Bootot használja, a RAG-alkalmazások építésének alapvető koncepciói az Azure OpenAI-val és Azure AI Search-csel bármely Java webalkalmazásra vonatkoznak. Ha egy másik üzemeltetési lehetőséget használ az App Service-ben, például a Tomcatet vagy a JBoss EAP-t, az itt látható hitelesítési mintákat és Azure SDK használatot az előnyben részesített keretrendszerhez igazíthatja.
Ebben az oktatóanyagban a következőket sajátíthatja el:
- Helyezzen üzembe egy RAG-mintát használó Spring Boot-alkalmazást a Azure AI-szolgáltatásaival.
- Konfigurálja Azure OpenAI-t és Azure AI Search a hibrid kereséshez.
- Dokumentumok feltöltése és indexelése az AI-alapú alkalmazásban való használatra.
- Felügyelt identitások használata a szolgáltatások közötti biztonságos kommunikációhoz.
- A RAG-implementációt helyben teszteljük élő szolgáltatásokkal.
Az architektúra áttekintése
Az üzembe helyezés megkezdése előtt hasznos megismerni a létrehozandó alkalmazás architektúráját. A következő diagram az Azure AI Search Custom RAG mintájából származik:
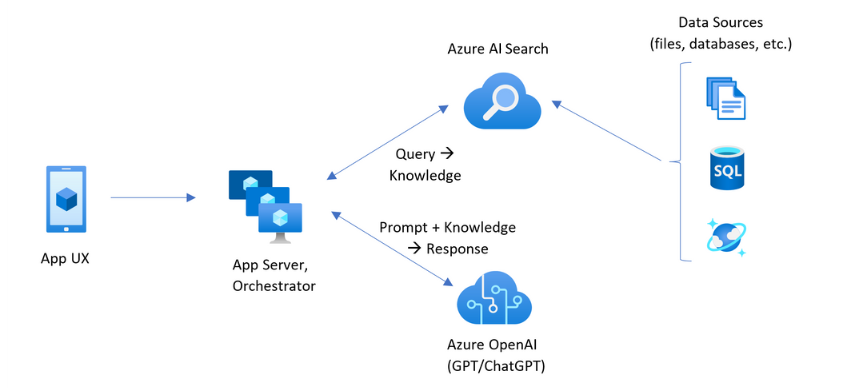
Ebben az oktatóanyagban az App Service Blazer-alkalmazása gondoskodik az alkalmazás-UX-ről és az alkalmazáskiszolgálóról is. Azonban nem készít külön tudásbázis-lekérdezést Azure AI Search. Ehelyett arra utasítja az Azure OpenAI-t, hogy hajtsa végre a tudás lekérdezését, az Azure AI Search-et adatforrásként meghatározva. Ez az architektúra számos fő előnyt kínál:
- Integrated Vectorization: Azure AI Search integrált vektorizálási képességeivel egyszerűen és gyorsan betöltheti az összes dokumentumot keresésre anélkül, hogy több kódra lenne szükség a beágyazások létrehozásához.
- Egyszerűsített API hozzáférés: Az Azure OpenAI On Your Data mintát használva, ahol az Azure AI Search az adatforrás az Azure OpenAI-kiegészítésekhez, nincs szükség összetett vektorkeresés vagy beágyazási generáció alkalmazására. Ez csak egy API-hívás, és Azure Az OpenAI mindent kezel, beleértve a parancssori tervezést és a lekérdezésoptimalizálást.
- Speciális keresési képességek: Az integrált vektorizáció mindent biztosít a fejlett hibrid kereséshez szemantikai rerankinggel, amely egyesíti a kulcsszóegyeztetés erősségeit, a vektorok hasonlóságát és az AI-alapú rangsorolást.
- Teljes idézettámogatás: A válaszok automatikusan tartalmaznak idézeteket a forrásdokumentumokra, így az információk ellenőrizhetők és nyomon követhetők.
Előfeltételek
- Aktív előfizetéssel rendelkező Azure-fiók – Fiók létrehozása ingyenesen.
- GitHub fiók GitHub kódterek használatára – A GitHub kódterekről.
1. Nyissa meg a mintát a Codespaces használatával
Az első lépések legegyszerűbb módja a GitHub Codespaces használata, amely teljes fejlesztési környezetet biztosít az összes szükséges előre telepített eszközzel.
Lépjen a GitHub adattárra a https://github.com/Azure-Samples/app-service-rag-openai-ai-search-java címen.
Válassza a Kód gombot, válassza a Kódterek lapot, majd kattintson a Fő kódtér létrehozása parancsra.
Várjon néhány percet a Codespace inicializálására. Ha elkészült, egy teljesen konfigurált VS Code-környezetet fog látni a böngészőben.
2. A mintaarchitektúra üzembe helyezése
A terminálon jelentkezzen be Azure Azure fejlesztői parancssori felülettel:
azd auth loginKövesse az utasításokat a hitelesítési folyamat befejezéséhez.
A Azure erőforrások kiépítése az AZD-sablonnal:
azd provisionAmikor megkérdezik, adja meg a következő válaszokat:
Kérdés Válasz Adjon meg egy új környezetnevet: Írjon be egy egyedi nevet. Válassza ki a használni kívánt Azure-előfizetést: Válassza ki az előfizetést. Válasszon egy használandó erőforráscsoportot: Válassza az Új erőforráscsoport létrehozása lehetőséget. Válasszon ki egy helyet az erőforráscsoport létrehozásához a következő helyen: Jelöljön ki egy régiót. Az erőforrások ténylegesen az USA 2. keleti régiójában jönnek létre. Adja meg az új erőforráscsoport nevét: Nyomja meg az Enter billentyűt. Várjon, amíg az üzembe helyezés befejeződik. Ez a folyamat a következő lesz:
- Hozza létre az összes szükséges Azure erőforrást.
- Telepítse az alkalmazást az Azure App Service-re.
- Biztonságos szolgáltatásközi hitelesítés konfigurálása felügyelt identitások használatával.
- Állítsa be a szolgáltatások közötti biztonságos hozzáféréshez szükséges szerepkör-hozzárendeléseket.
Megjegyzés:
A felügyelt identitások működésével kapcsolatos további információkért lásd: Mi a felügyelt identitások Azure erőforrásokhoz? és A felügyelt identitások használata az App Service-ben.
A sikeres üzembe helyezés után megjelenik az üzembe helyezett alkalmazás URL-címe. Jegyezze fel ezt az URL-címet, de még ne fér hozzá, mert még be kell állítania a keresési indexet.
3. Dokumentumok feltöltése és keresési index létrehozása
Az infrastruktúra üzembe helyezése után fel kell töltenie a dokumentumokat, és létre kell hoznia egy keresési indexet, amelyet az alkalmazás használni fog:
A Azure portálon lépjen az üzembe helyezés által létrehozott tárfiókra. A név a korábban megadott környezetnévvel kezdődik.
A bal oldali navigációs menüben válassza az Adattárolók> lehetőséget, és nyissa meg a dokumentumtárolót.
Töltse fel a mintadokumentumokat a Feltöltés gombra kattintva. A mintadokumentumokat az adattár
sample-docsmappájából, illetve saját PDF-, Word- vagy szövegfájljaiból is használhatja.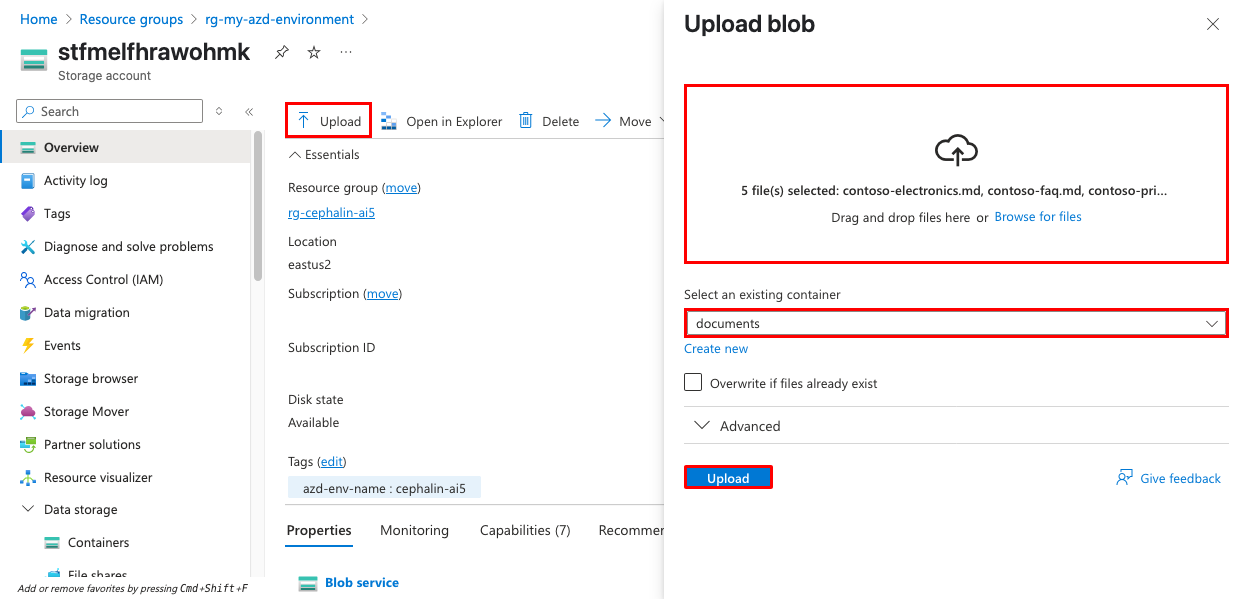
Lépjen a Azure AI Search szolgáltatáshoz a Azure portálon.
Válassza az Adatok importálása (új) lehetőséget a keresési index létrehozásának megkezdéséhez.

A Csatlakozás az adatokhoz lépésben:
- Adatforrásként válassza a Azure Blob Storage lehetőséget.
- Válassza a RAG lehetőséget.
- Válassza ki a tárfiókot és a dokumentumtárolót .
- Válassza a Hitelesítés felügyelt identitással lehetőséget.
- Válassza a Következőlehetőséget.
A Szöveg vektorizálása lépésben:
- Válassza ki a Azure OpenAI szolgáltatást.
- A beágyazási modellként válassza a text-embedding-ada-002 elemet. Az AZD-sablon már üzembe helyezte ezt a modellt.
- Válassza ki a rendszer által hozzárendelt identitást a hitelesítéshez.
- További költségek esetén jelölje be a nyugtázás jelölőnégyzetet.
- Válassza a Következőlehetőséget.
Jótanács
További információ a vektorkeresésről az Azure AI Search-ben és a szövegbeágyazásokról az Azure OpenAI-ban.
A Képeid vektorizálása és gazdagítása lépésben:
- Tartsa meg az alapértelmezett beállításokat.
- Válassza a Következőlehetőséget.
A Speciális beállítások lépésben:
- Győződjön meg arról, hogy a szemantikai rangsoroló engedélyezése be van jelölve.
- (Nem kötelező) Válasszon ki egy indexelési ütemezést. Ez akkor hasznos, ha rendszeresen frissíteni szeretné az indexet a legújabb fájlmódosításokkal.
- Válassza a Következőlehetőséget.
A Véleményezés és létrehozás lépésben:
- Másolja ki az Objektumnév előtag értékét. Ez a te keresési indexed neve.
- Az indexelési folyamat elindításához válassza a Létrehozás lehetőséget .
Várja meg, amíg az indexelési folyamat befejeződik. Ez a dokumentumok méretétől és számától függően eltarthat néhány percig.
Az adatimportálás teszteléséhez válassza a Keresés indítása lehetőséget, és próbálkozzon egy keresési lekérdezéssel , például a "Mutasd meg a cégről" lehetőséget.
A Codespace-terminálban állítsa be a keresési index nevét AZD környezeti változóként:
azd env set SEARCH_INDEX_NAME <your-search-index-name>Cserélje le
<your-search-index-name>az indexnévre, amelyet korábban másolt. Az AZD ezt a változót használja a későbbi üzembe helyezések során az App Service alkalmazásbeállításának beállításához.
4. Az alkalmazás tesztelése és üzembe helyezése
Ha az alkalmazást az üzembe helyezés előtt vagy után szeretné helyileg tesztelni, közvetlenül a Codespace-ből futtathatja:
A Codespace-terminálban kérje le az AZD környezeti értékeket:
azd env get-valuesNyissa meg az src/main/resources/application.properties elemet. A terminálkimenettel frissítse a következő értékeket a megfelelő helyőrzőkben
<input-manually-for-local-testing>:azure.openai.endpointazure.search.urlazure.search.index.name
Jelentkezzen be az Azure-ba az Azure CLI segítségével:
az loginEz lehetővé teszi, hogy a mintakódban lévő Azure Identity ügyfélkönyvtár hitelesítési tokent kapjon a bejelentkezett felhasználó számára.
Futtassa az alkalmazást helyileg:
mvn spring-boot:runHa azt látja, hogy az alkalmazás a 8080-s porton fut, válassza a Megnyitás böngészőben lehetőséget.
Tegyen fel néhány kérdést a csevegőfelületen. Ha választ kap, az alkalmazás sikeresen csatlakozik az Azure OpenAI-erőforráshoz.
Állítsa le a fejlesztőkiszolgálót a Ctrl+C billentyűkombinációval.
Alkalmazza az új
SEARCH_INDEX_NAMEkonfigurációt Azure, és telepítse a mintaalkalmazás kódját:azd up
5. Az üzembe helyezett RAG-alkalmazás tesztelése
Az alkalmazás teljes üzembe helyezésével és konfigurálva mostantól tesztelheti a RAG funkciót:
Nyissa meg az üzembe helyezés végén megadott alkalmazás URL-címét.
Megjelenik egy csevegőfelület, ahol kérdéseket tehet fel a feltöltött dokumentumok tartalmával kapcsolatban.
Próbáljon meg olyan kérdéseket feltenni, amelyek a dokumentumok tartalmára vonatkoznak. Ha például feltöltötte a dokumentumokat a mintadokumentumok mappába, kipróbálhatja az alábbi kérdéseket:
- Hogyan használja a Contoso a személyes adataimat?
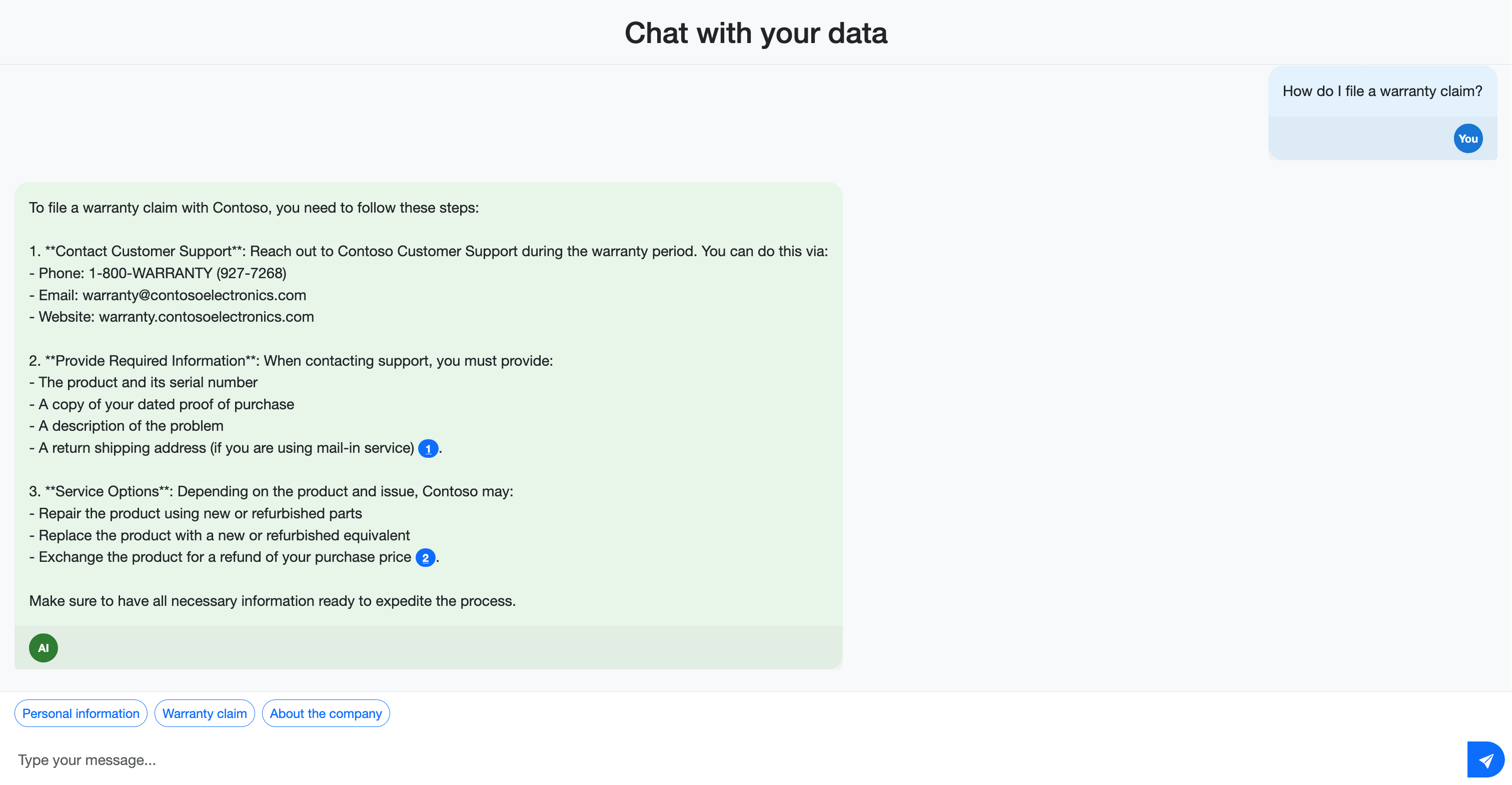
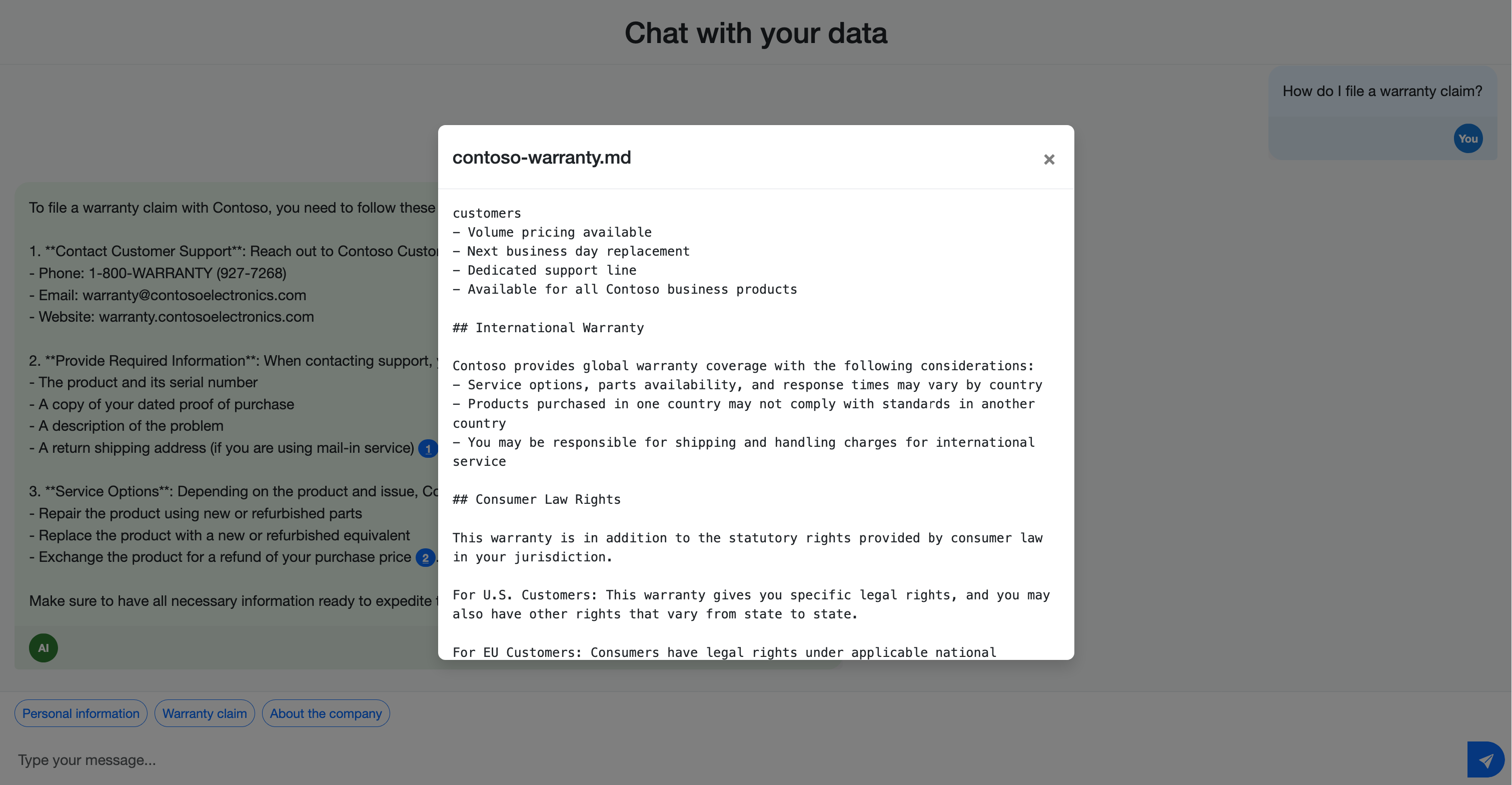
- Hogyan nyújt be jótállási igényt?
Figyelje meg, hogy a válaszok a forrásdokumentumokra hivatkozó idézeteket tartalmaznak. Ezek az idézetek segítenek a felhasználóknak ellenőrizni az információk pontosságát, és további részleteket találni a forrásanyagban.
Tesztelje a hibrid keresési képességeket olyan kérdések feltevésével, amelyek hasznosak lehetnek a különböző keresési megközelítésekben:
- Adott terminológiával kapcsolatos kérdések (kulcsszókeresésre alkalmas).
- Olyan fogalmakkal kapcsolatos kérdések, amelyek különböző kifejezések használatával írhatók le (jó vektorkereséshez).
- Összetett kérdések, amelyek megértést igényelnek (jó szemantikai rangsoroláshoz).
Erőforrások tisztítása
Ha végzett az alkalmazással, törölheti az összes erőforrást a további költségek elkerülése érdekében:
azd down --purge
Ez a parancs törli az alkalmazáshoz társított összes erőforrást.
Gyakori kérdések
- Hogyan kéri le a mintakód az idézeteket Azure OpenAI-csevegés befejezéseiből?
- Mi az előnye a felügyelt identitások használatának ebben a megoldásban?
- Hogyan használja a rendszer által hozzárendelt felügyelt identitást ebben az architektúrában és mintaalkalmazásban?
- Hogyan történik a hibrid keresés szemantikai rangsorolóval a mintaalkalmazásban?
- Miért jönnek létre az összes erőforrás az USA 2. keleti régiójában?
- Használhatom a saját OpenAI-modelleimet az Azure által biztosítottak helyett?
- Hogyan javíthatom a válaszok minőségét?
Hogyan kéri le a mintakód az idézeteket Azure OpenAI-csevegések befejezéséből?
A minta az idézeteket AzureSearchChatExtensionConfiguration adatforrásként használja a csevegőügyfél számára. Ha a csevegés befejezését kérik, a válasz tartalmaz egy Citations objektumot az üzenetkörnyezetben. A kód az alábbi idézeteket nyeri ki:
public static ChatResponse fromChatCompletions(ChatCompletions completions) {
ChatResponse response = new ChatResponse();
if (completions.getChoices() != null && !completions.getChoices().isEmpty()) {
var message = completions.getChoices().get(0).getMessage();
if (message != null) {
response.setContent(message.getContent());
if (message.getContext() != null && message.getContext().getCitations() != null) {
var azureCitations = message.getContext().getCitations();
for (int i = 0; i < azureCitations.size(); i++) {
var azureCitation = azureCitations.get(i);
Citation citation = new Citation();
citation.setIndex(i + 1);
citation.setTitle(azureCitation.getTitle());
citation.setContent(azureCitation.getContent());
citation.setFilePath(azureCitation.getFilepath());
citation.setUrl(azureCitation.getUrl());
response.getCitations().add(citation);
}
}
}
}
return response;
}
A csevegési válaszban a tartalom [doc#] jelöléssel hivatkozik a listában szereplő megfelelő idézetre, így a felhasználók visszakövethetik az információkat az eredeti forrásdokumentumokhoz. További információkért lásd:
Mi az előnye a felügyelt identitások használatának ebben a megoldásban?
A felügyelt identitások nem igénylik a hitelesítő adatok tárolását a kódban vagy a konfigurációban. A felügyelt identitások használatával az alkalmazás biztonságosan hozzáférhet Azure szolgáltatásokhoz, például Azure OpenAI-hez és Azure AI Search titkos kódok kezelése nélkül. Ez a megközelítés Zero Trust biztonsági alapelveket követ, és csökkenti a hitelesítő adatok expozíciójának kockázatát.
Hogyan használja a rendszer által hozzárendelt felügyelt identitást ebben az architektúrában és mintaalkalmazásban?
Az AZD-telepítés rendszer által hozzárendelt felügyelt identitásokat hoz létre Azure App Service, Azure OpenAI és Azure AI Search számára. Az egyes szerepkör-hozzárendeléseket is végrehajtja (lásd a main.bicep fájlt). A szükséges szerepkör-hozzárendelésekről további információt a Network and access configuration for Azure OpenAI On Your Data című témakörben talál.
A minta Java alkalmazásban a Azure SDKs ezt a felügyelt identitást használja a biztonságos hitelesítéshez, így nem kell sehol tárolnia a hitelesítő adatokat vagy titkos kulcsokat. Például a OpenAIAsyncClient inicializálása a DefaultAzureCredential segítségével történik, amely automatikusan használja a felügyelt identitást, amikor az Azure-ban fut.
@Bean
public TokenCredential tokenCredential() {
return new DefaultAzureCredentialBuilder().build();
}
@Bean
public OpenAIAsyncClient openAIClient(TokenCredential tokenCredential) {
return new OpenAIClientBuilder()
.endpoint(openAiEndpoint)
.credential(tokenCredential)
.buildAsyncClient();
}
Hasonlóképpen, ha az adatforrást Azure AI Search konfigurálja, a felügyelt identitás a hitelesítéshez van megadva:
AzureSearchChatExtensionConfiguration searchConfiguration =
new AzureSearchChatExtensionConfiguration(
new AzureSearchChatExtensionParameters(appSettings.getSearch().getUrl(), appSettings.getSearch().getIndex().getName())
.setAuthentication(new OnYourDataSystemAssignedManagedIdentityAuthenticationOptions())
// ...
);
Ez a beállítás biztonságos, jelszó nélküli kommunikációt tesz lehetővé a Spring Boot-alkalmazás és Azure szolgáltatások között, a Zero Trust biztonságra vonatkozó ajánlott eljárásokat követve. További információ a DefaultAzureCredential és a Azure Identity ügyfélkódtárról Java.
Hogyan történik a hibrid keresés szemantikai rangsorolóval a mintaalkalmazásban?
A mintaalkalmazás szemantikai rangsorolással konfigurálja a hibrid keresést az Azure OpenAI és Azure AI Search Java SDK-k használatával. A háttérrendszerben az adatforrás a következőképpen van beállítva:
AzureSearchChatExtensionParameters parameters = new AzureSearchChatExtensionParameters(
appSettings.getSearch().getUrl(),
appSettings.getSearch().getIndex().getName())
// ...
.setQueryType(AzureSearchQueryType.VECTOR_SEMANTIC_HYBRID)
.setEmbeddingDependency(new OnYourDataDeploymentNameVectorizationSource(appSettings.getOpenai().getEmbedding().getDeployment()))
.setSemanticConfiguration(appSettings.getSearch().getIndex().getName() + "-semantic-configuration");
Ez a konfiguráció lehetővé teszi, hogy az alkalmazás egyetlen lekérdezésben kombinálja a vektorkeresést (szemantikai hasonlóságot), a kulcsszóegyezést és a szemantikai rangsorolást. A szemantikai rangsoroló átrendezi az eredményeket, hogy a legrelevánsabb és környezetfüggő válaszokat adja vissza, amelyeket aztán Azure OpenAI használ a válaszok létrehozásához.
A szemantikai konfiguráció nevét az integrált vektorizálási folyamat automatikusan definiálja. Előtagként a keresési index nevét használja, utótagként pedig hozzáfűzi -semantic-configuration . Ez biztosítja, hogy a szemantikai konfiguráció egyedileg legyen társítva a megfelelő indexhez, és egy konzisztens elnevezési konvenciót követ.
Miért jönnek létre az összes erőforrás az USA 2. keleti régiójában?
A minta a gpt-4o-mini és a text-embedding-ada-002 modelleket használja, amelyek mindegyike az USA 2. keleti régiójában elérhető standard üzemi típussal érhető el. Ezek a modellek azért is vannak kiválasztva, mert nem lesznek hamarosan nyugdíjba vonulásra ütemezve, ami stabilitást biztosít a mintatelepítéshez. A modell rendelkezésre állási és üzembehelyezési típusai régiónként eltérőek lehetnek, ezért az USA 2. keleti régiója van kiválasztva, hogy a minta a dobozon kívül működjön. Ha másik régiót vagy modellt szeretne használni, ügyeljen arra, hogy olyan modelleket válasszon ki, amelyek ugyanabban a régióban ugyanahhoz az üzembe helyezési típushoz érhetők el. A saját modellek kiválasztásakor ellenőrizze a rendelkezésre állási és a kivonási dátumokat is, hogy elkerülje a fennakadásokat.
- Modell rendelkezésre állása: Azure OpenAI Service modellek
- Modell nyugdíjazási dátumai: Azure OpenAI Service modellek elavulása és nyugdíjazása.
Használhatom a saját OpenAI-modelleimet a Azure által biztosítottak helyett?
Ez a megoldás úgy lett kialakítva, hogy együttműködjön a Azure OpenAI Service-szel. Bár módosíthatja a kódot más OpenAI-modellek használatára, elveszíti az integrált biztonsági funkciókat, a felügyelt identitástámogatást és a megoldás által biztosított Azure AI Search való zökkenőmentes integrációt.
Hogyan javíthatom a válaszok minőségét?
A válaszminőséget a következő lépésekkel javíthatja:
- Jobb minőségű, relevánsabb dokumentumok feltöltése.
- Az adattömb-stratégiák módosítása az Azure AI Search indexelési folyamatban. Azonban az ebben az oktatóanyagban bemutatott integrált vektorizációval nem szabhatja testre a szövegrészletek csoportosítását.
- Kísérletezés különböző parancssori sablonokkal az alkalmazáskódban.
- A keresés finomhangolása más tulajdonságokkal az AzureSearchChatExtensionParameters osztályban.
- Speciálisabb Azure OpenAI-modellek használata az adott tartományhoz.