









esemény
Intelligens alkalmazások létrehozása
márc. 17. 21 - márc. 21. 10
Csatlakozzon a meetup sorozathoz, hogy valós használati esetek alapján, skálázható AI-megoldásokat hozzon létre más fejlesztőkkel és szakértőkkel.
RegisztrációEzt a böngészőt már nem támogatjuk.
Frissítsen a Microsoft Edge-re, hogy kihasználhassa a legújabb funkciókat, a biztonsági frissítéseket és a technikai támogatást.
Ebből a cikkből megismerheti az Azure OpenAI On Your Data szolgáltatását, amely megkönnyíti a fejlesztők számára a vállalati adatok összekapcsolását, betöltését és őrzését a személyre szabott copilotok (előzetes verzió) gyors létrehozása érdekében. Javítja a felhasználók megértését, felgyorsítja a feladatok elvégzését, javítja a működési hatékonyságot, és segíti a döntéshozatalt.
Az Azure OpenAI On Your Data lehetővé teszi fejlett AI-modellek, például a GPT-35-Turbo és a GPT-4 futtatását saját vállalati adatain anélkül, hogy be kellene tanítania vagy finomhangolnia kellene a modelleket. Cseveghet a tetején, és nagyobb pontossággal elemezheti az adatokat. A kijelölt adatforrásokban elérhető legfrissebb információk alapján megadhatja, hogy mely források támogatják a válaszokat. Az Azure OpenAI on Your Data egy REST API-val érhető el az SDK-n vagy az Azure AI Foundry portál webes felületén. Létrehozhat egy olyan webalkalmazást is, amely az adatokhoz csatlakozva lehetővé teszi a továbbfejlesztett csevegési megoldást, vagy közvetlenül a Copilot Studióban (előzetes verzió) copilotként is üzembe helyezheti.
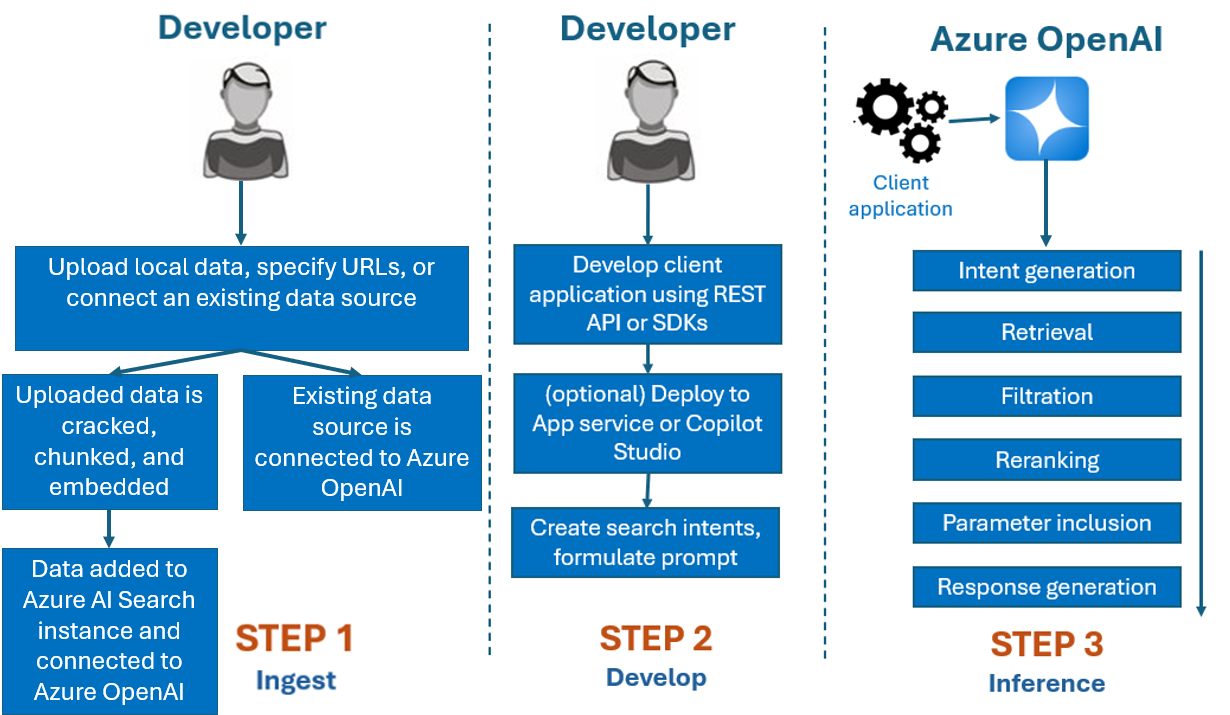
Az Azure OpenAI On Your Data szolgáltatással használt fejlesztési folyamat általában a következő:
Betöltés: Fájlok feltöltése az Azure AI Foundry portál vagy a betöltési API használatával. Ez lehetővé teszi, hogy az adatok repedjenek, darabosodjanak és beágyazódjanak egy Azure AI Search-példányba, amelyet az Azure OpenAI-modellek használhatnak. Ha már rendelkezik támogatott adatforrással, közvetlenül is csatlakoztathatja.
Fejlesztés: Az Azure OpenAI On Your Data kipróbálása után kezdje el fejleszteni az alkalmazást az elérhető REST API-k és SDK-k használatával, amelyek több nyelven is elérhetők. A rendszer kéréseket és keresési szándékokat hoz létre az Azure OpenAI szolgáltatásnak való továbbításhoz.
Következtetés: Miután az alkalmazás üzembe lett helyezve az előnyben részesített környezetben, a rendszer kéri az Azure OpenAI-t, amely több lépést is végrehajt a válasz visszaadása előtt:
Szándékgenerálás: A szolgáltatás határozza meg a felhasználó kérésének szándékát a megfelelő válasz meghatározásához.
Lekérés: A szolgáltatás lekérdezéssel lekéri a csatlakoztatott adatforrásból az elérhető adatok releváns darabjait. Például szemantikai vagy vektoros kereséssel. Az olyan paraméterek, mint a szigorúság és a lekérendő dokumentumok száma, befolyásolják a lekérést.
Szűrés és reranking: A lekérési lépés keresési eredményei javulnak az adatok rangsorolásával és szűrésével a relevancia pontosítása érdekében.
Válaszgenerálás: Az eredményül kapott adatokat a rendszer más információkkal együtt elküldi, például a rendszerüzenetet a nagy nyelvi modellnek (LLM), és a rendszer visszaküldi a választ az alkalmazásnak.
Első lépésként csatlakoztassa az adatforrást az Azure AI Foundry portállal, és kezdjen el kérdéseket feltenni, és csevegni az adatain.
Az Azure OpenAI teljes körű használatához be kell állítania egy vagy több Azure RBAC-szerepkört. További információkért tekintse meg az Azure OpenAI On Your Data konfigurációját .
Az Azure OpenAI On Your Data a következő fájltípusokat támogatja:
.txt.md.html.docx.pptx.pdfVan egy feltöltési korlát, és van néhány kikötés a dokumentumszerkezettel kapcsolatban, és hogy ez hogyan befolyásolhatja a modell válaszainak minőségét:
Ha nem támogatott formátumból támogatott formátumba konvertálja az adatokat, a konvertálás biztosításával optimalizálja a modellválasz minőségét:
Ha a fájlok speciális formázással, például táblákkal és oszlopokkal vagy listajelekkel rendelkeznek, készítse elő az adatokat a GitHubon elérhető adat-előkészítési szkripttel.
A hosszú szöveggel rendelkező dokumentumok és adathalmazok esetében a rendelkezésre álló adat-előkészítési szkriptet kell használnia. A szkript adattömböket hoz létre annak érdekében, hogy a modell válaszai pontosabbak legyenek. Ez a szkript a beolvasott PDF-fájlokat és képeket is támogatja.
Az adatok feltöltéséhez csatlakoznia kell egy adatforráshoz. Ha egy Azure OpenAI-modellel szeretne csevegni az adataival, az adatok egy keresési indexbe kerülnek, hogy a releváns adatok a felhasználói lekérdezések alapján is megtalálhatók legyenek.
Megjegyzés
Az adatoknak strukturálatlan szövegnek kell lenniük a legjobb eredmény érdekében. Ha nem szöveges, részben strukturált vagy strukturált adatokkal rendelkezik, fontolja meg az adatok szöveggé alakítását. Ha a fájlok speciális formázással, például táblákkal és oszlopokkal vagy listajelekkel rendelkeznek, készítse elő az adatokat a GitHubon elérhető adat-előkészítési szkripttel.
A virtuális magalapú Azure Cosmos DB for MongoDB integrált vektoradatbázisa natív módon támogatja az Azure OpenAI On Your Data integrációját.
Egyes adatforrások, például fájlok feltöltése a helyi gépről (előzetes verzió) vagy egy blobtároló-fiókban (előzetes verzió) tárolt adatok esetében az Azure AI Search lesz használatban. Az alábbi adatforrások kiválasztásakor az adatok egy Azure AI Search-indexbe kerülnek.
| Az Azure AI Search szolgáltatással betöltött adatok | Leírás |
|---|---|
| Azure AI Search | Használjon egy meglévő Azure AI Search-indexet az Azure OpenAI-val az Adatain. |
| Fájlok feltöltése (előzetes verzió) | Töltsön fel fájlokat a helyi gépről, hogy egy Azure Blob Storage-adatbázisban tárolja, és betöltse az Azure AI Searchbe. |
| URL-cím/webcím (előzetes verzió) | Az URL-címekről származó webes tartalmakat az Azure Blob Storage tárolja. |
| Azure Blob Storage (előzetes verzió) | Töltsön fel fájlokat az Azure Blob Storage-ból, hogy betöltse őket egy Azure AI Search-indexbe. |

Érdemes megfontolnia egy Azure AI Search-index használatát, ha a következőkre van szüksége:
Megjegyzés
all az Engedélyezett forrástípus beállítást pedig a következőre*.Az Azure OpenAI On Your Data az alábbi keresési típusokat biztosítja, amelyek az adatforrás hozzáadásakor használhatók.
Vektorkeresés az Ada beágyazási modelljeivel, amelyek a kijelölt régiókban érhetők el
A vektorkeresés engedélyezéséhez egy meglévő beágyazási modellre van szükség az Azure OpenAI-erőforrásban. Válassza ki a beágyazási üzembe helyezést az adatok csatlakoztatásakor, majd válasszon egy vektorkeresési típust az Adatkezelés területen. Ha az Azure AI Searcht használja adatforrásként, győződjön meg arról, hogy van vektoroszlop az indexben.
Ha saját indexet használ, testre szabhatja a mezőleképezést , amikor hozzáadja az adatforrást a kérdések megválaszolásakor leképezett mezők meghatározásához. A mezőleképezés testreszabásához válassza az Adatforrás lapon az Egyéni mezőleképezés használata lehetőséget az adatforrás hozzáadásakor.
Fontos
| Keresés lehetőség | Lekérés típusa | További díjszabás? | Juttatások |
|---|---|---|---|
| kulcsszó | Kulcsszavas keresés | Nincs további díjszabás. | Gyors és rugalmas lekérdezési elemzést és egyeztetést végez kereshető mezőkön keresztül, bármilyen támogatott nyelven, operátorokkal vagy anélkül. |
| szemantikai | Szemantikai keresés | A szemantikai keresések használatának további díjszabása. | A keresési eredmények pontosságának és relevanciájának javítása rerankerrel (AI-modellekkel) a kezdeti keresési rangsoroló által visszaadott lekérdezési kifejezések és dokumentumok szemantikai jelentésének megértéséhez |
| vektor | Vektoros keresés | Az Azure OpenAI-fiók további díjszabása a beágyazási modell meghívásától. | Lehetővé teszi az adott lekérdezési bemenethez hasonló dokumentumok megkeresését a tartalom vektoros beágyazása alapján. |
| hibrid (vektor + kulcsszó) | A vektorkeresés és a kulcsszókeresés hibridje | Az Azure OpenAI-fiók további díjszabása a beágyazási modell meghívásától. | Vektoros beágyazások használatával hajtja végre a hasonlóságkeresést a vektormezők között, ugyanakkor támogatja a rugalmas lekérdezési elemzést és a teljes szöveges keresést alfanumerikus mezőkön kifejezéses lekérdezések használatával. |
| hibrid (vektor + kulcsszó) + szemantika | A vektorkeresés, szemantikai keresés és kulcsszókeresés hibridje. | Az Azure OpenAI-fiók további díjszabása a beágyazási modell meghívásától, valamint a szemantikus keresési használat további díjszabásától. | Vektoros beágyazásokkal, nyelvfelismeréssel és rugalmas lekérdezés-elemzéssel gazdag keresési szolgáltatásokat és összetett és változatos információlekérési forgatókönyveket kezelő generatív AI-alkalmazásokat hozhat létre. |
Az Azure OpenAI On Your Data intelligens kereséssel rendelkezik az adataihoz. A szemantikai keresés alapértelmezés szerint engedélyezve van, ha szemantikai és kulcsszókereséssel is rendelkezik. Ha rendelkezik beágyazási modellekkel, az intelligens keresés alapértelmezés szerint hibrid és szemantikai keresésre használható.
Megjegyzés
A dokumentumszintű hozzáférés-vezérlés akkor támogatott, ha adatforrásként az Azure AI Searcht választja.
Az Azure OpenAI On Your Data segítségével korlátozhatja a különböző felhasználók válaszaiban használható dokumentumokat az Azure AI Search biztonsági szűrőivel. A dokumentumszintű hozzáférés engedélyezésekor az Azure AI Search által visszaadott és a válasz létrehozásához használt keresési eredmények a Microsoft Entra-csoporttagság alapján lesznek levágva. Dokumentumszintű hozzáférést csak meglévő Azure AI Search-indexeken engedélyezhet. További információkért tekintse meg az Azure OpenAI On Your Data Network szolgáltatást és a hozzáférési konfigurációt .
Ha saját indexet használ, a rendszer az Azure AI Foundry portálon kéri, hogy határozza meg, mely mezőket szeretné megfeleltetni az adatforrás hozzáadásakor felmerülő kérdések megválaszolásához. A tartalomadatokhoz több mezőt is megadhat, és minden olyan mezőt tartalmaznia kell, amely a használati esethez kapcsolódó szövegekkel rendelkezik.

Ebben a példában a Tartalomadatok és a Cím mezői információkat adnak a modellnek a kérdések megválaszolásához. A cím az idézet szövegének címére is használható. A Fájlnévre leképezett mező létrehozza az idézetek nevét a válaszban.
Ezeknek a mezőknek a helyes leképezése segít biztosítani a modell jobb válasz- és idézetminőségét. Emellett konfigurálhatja az API-ban a fieldsMapping paraméterrel.
Ha további értékalapú feltételeket szeretne implementálni a lekérdezések végrehajtásához, beállíthat egy keresési szűrőt a filterREST API paraméterével.
2024 szeptemberétől a betöltési API-k integrált vektorizálásra váltottak. Ez a frissítés nem módosítja a meglévő API-szerződéseket. Az Azure AI Search új ajánlata, az integrált vektorizáció előre összeállított készségeket használ a bemeneti adatok adattömbökbe való beágyazásához és beágyazásához. Az Azure OpenAI On Your Data ingestion szolgáltatás már nem alkalmaz egyéni készségeket. Az integrált vektorizálásra való migrálást követően a betöltési folyamat néhány módosításon ment keresztül, ezért csak a következő eszközök jönnek létre:
{job-id}-index{job-id}-indexer, ha óránkénti vagy napi ütemezés van megadva, ellenkező esetben az indexelő a betöltési folyamat végén törlődik.{job-id}-datasourceAz adattömbtároló már nem érhető el, mivel ezt a funkciót mostantól az Azure AI Search felügyeli.
Meg kell adnia, hogyan szeretné hitelesíteni a kapcsolatot az Azure OpenAI, az Azure AI Search és az Azure Blob Storage használatával. Választhat rendszer által hozzárendelt felügyelt identitást vagy API-kulcsot. Ha az API-kulcsot választja hitelesítési típusként, a rendszer automatikusan feltölti az API-kulcsot, hogy csatlakozzon az Azure AI Search, az Azure OpenAI és az Azure Blob Storage-erőforrásokhoz. A rendszer által hozzárendelt felügyelt identitás kiválasztásával a hitelesítés a szerepkör-hozzárendelésen alapul. A rendszer által hozzárendelt felügyelt identitás alapértelmezés szerint ki van választva a biztonság szempontjából.

Miután kiválasztotta a következő gombot, a rendszer automatikusan ellenőrzi a beállítást a kiválasztott hitelesítési módszer használatához. Ha hibát tapasztal, tekintse meg a szerepkör-hozzárendelésekről szóló cikket a beállítás frissítéséhez.
A beállítás kijavítása után a következő gombra kattintva érvényesítheti és folytathatja a műveletet. Az API-felhasználók a hitelesítést hozzárendelt felügyelt identitással és API-kulcsokkal is konfigurálhatják.
Miután csatlakoztatta az Azure OpenAI-t az adataihoz, üzembe helyezheti azOkat az Azure AI Foundry portál Üzembe helyezés gombja segítségével.

Ez több lehetőséget is kínál a megoldás üzembe helyezésére.
A Copilot Studióban (előzetes verzió) közvetlenül az Azure AI Foundry portálról telepítheti a copilotokat, így beszélgetési élményeket hozhat létre különböző csatornákon, például a Microsoft Teamsben, a webhelyeken, a Dynamics 365-ben és más Azure Bot Service-csatornákon. Az Azure OpenAI szolgáltatásban és a Copilot Studióban (előzetes verzió) használt bérlőnek azonosnak kell lennie. További információkért lásd : Kapcsolat használata az Azure OpenAI-hez az adatokon.
Megjegyzés
A Copilot Studióban (előzetes verzió) való üzembe helyezés csak az USA régióiban érhető el.
A Microsoft Entra ID szerepköralapú hozzáférés-vezérléssel, virtuális hálózatokkal és privát végpontokkal használhatja az Azure OpenAI On Your Data alkalmazást, és megvédheti az adatokat és az erőforrásokat. Az Azure AI Search biztonsági szűrőivel korlátozhatja a különböző felhasználók válaszaiban használható dokumentumokat is. Lásd: Azure OpenAI On Your Data access and network configuration.
A következő szakaszokból megtudhatja, hogyan javíthatja a modell által adott válaszok minőségét.
Amikor az adatok az Azure AI Searchbe kerülnek, a következő további beállításokat módosíthatja a studióban vagy a betöltési API-ban.
Az Azure OpenAI On Your Data úgy dolgozza fel a dokumentumokat, hogy azokat adattömbökre osztja, mielőtt betöltené őket. Az adattömb mérete a keresési indexben lévő adattömbök tokenjeinek számát tekintve a maximális méret. Az adattömb mérete és a lekért dokumentumok száma együttesen határozza meg, hogy a modellnek küldött kérés mennyi információt (jogkivonatot) tartalmaz. Általánosságban elmondható, hogy az adattömb mérete és a lekért dokumentumok számának szorzata a modellnek küldött tokenek teljes száma.
Az alapértelmezett adattömbméret 1024 token. Az adatok egyedisége miatt azonban előfordulhat, hogy egy másik adattömbméret (például 256, 512 vagy 1536 token) hatékonyabb.
Az adattömb méretének módosítása javíthatja a csevegőrobot teljesítményét. Az optimális adattömb méretének megkereséséhez próbaidőszakra és hibára van szükség, először is vegye figyelembe az adathalmaz természetét. A kisebb adattömbök általában jobbak a közvetlen tényekkel és kevesebb kontextussal rendelkező adathalmazok esetében, míg a nagyobb adattömbméret hasznos lehet a környezetfüggőbb információk esetében, bár ez befolyásolhatja a lekérési teljesítményt.
A 256-hoz hasonló kis adattömbök részletesebb adattömböket eredményeznek. Ez a méret azt is jelenti, hogy a modell kevesebb jogkivonatot használ a kimenet létrehozásához (kivéve, ha a lekért dokumentumok száma nagyon magas), ami valószínűleg kevesebbe kerül. A kisebb adattömbök azt is jelentik, hogy a modellnek nem kell feldolgoznia és értelmeznie a hosszú szövegszakaszokat, ezáltal csökkentve a zajt és a zavaró tényezőket. Ez a részletesség és a fókusz azonban potenciális problémát jelent. Előfordulhat, hogy a fontos információk nem tartoznak a legjobban lekért adattömbök közé, különösen akkor, ha a lekért dokumentumok száma alacsony értékre van állítva, például 3.
Tipp.
Ne feledje, hogy az adattömb méretének módosításához újra be kell tölteni a dokumentumokat, ezért érdemes először módosítani a futtatókörnyezet paramétereit, például a szigorúságot és a lekért dokumentumok számát. Fontolja meg az adattömb méretének módosítását, ha még mindig nem kapja meg a kívánt eredményeket:
Az alábbi további beállításokat az Azure AI Foundry portál Adatparaméterek szakaszában és az API-ban módosíthatja. Ezeknek a paramétereknek a frissítésekor nem kell újból betöltenie az adatokat.
| Paraméter neve | Leírás |
|---|---|
| Az adatokra adott válaszok korlátozása | Ez a jelző konfigurálja a csevegőrobot megközelítését az adatforrástól független lekérdezések kezelésére, vagy ha a keresési dokumentumok nem elegendőek a teljes válaszhoz. Ha ez a beállítás le van tiltva, a modell a dokumentumok mellett saját tudással egészíti ki a válaszokat. Ha ez a beállítás engedélyezve van, a modell csak a dokumentumokra próbál támaszkodni a válaszokhoz. Ez az inScope API paramétere, és alapértelmezés szerint igaz értékre van állítva. |
| Lekért dokumentumok | Ez a paraméter egy olyan egész szám, amely 3, 5, 10 vagy 20 értékre állítható be, és szabályozza a nagy nyelvi modellnek biztosított dokumentumtömbök számát a végső válasz megfogalmazásához. Alapértelmezés szerint ez az 5 értékre van állítva. A keresési folyamat zajos lehet, és előfordulhat, hogy az adattömbök miatt a releváns információk a keresési index több adattömbjében is el vannak osztva. Az 5-hez hasonló legfelső K-szám kiválasztása biztosítja, hogy a modell a keresés és az adattömbök eredendő korlátozásai ellenére is kinyerje a releváns információkat. A túl magas szám növelése azonban megzavarhatja a modellt. Emellett a hatékonyan használható dokumentumok maximális száma a modell verziójától függ, mivel mindegyiknek más a környezet mérete és kapacitása a dokumentumok kezeléséhez. Ha úgy találja, hogy a válaszok hiányoznak a fontos környezetből, próbálja meg növelni ezt a paramétert. Ez az topNDocuments API paramétere, és alapértelmezés szerint 5. |
| Szigorúság | Meghatározza a rendszer agresszivitását a keresési dokumentumok szűrésében a hasonlósági pontszámok alapján. A rendszer lekérdezi az Azure Searcht vagy más dokumentumtárolókat, majd eldönti, hogy mely dokumentumokat adja meg a nagy nyelvi modelleknek, például a ChatGPT-nek. Az irreleváns dokumentumok kiszűrése jelentősen javíthatja a végpontok közötti csevegőrobot teljesítményét. Egyes dokumentumok ki vannak zárva az első K eredményekből, ha alacsony hasonlósági pontszámmal rendelkeznek, mielőtt továbbítanák őket a modellnek. Ezt egy 1 és 5 közötti egész szám szabályozza. Az érték 1 értékre állítása azt jelenti, hogy a rendszer minimálisan szűri a dokumentumokat a felhasználói lekérdezéshez hasonló keresési hasonlóság alapján. Ezzel szemben az 5-ös beállítás azt jelzi, hogy a rendszer agresszíven szűri ki a dokumentumokat, és nagyon magas hasonlósági küszöbértéket alkalmaz. Ha úgy találja, hogy a csevegőrobot kihagyja a releváns információkat, csökkentse a szűrő szigorúságát (állítsa az értéket közelebb az 1-hez), hogy több dokumentumot is tartalmazzon. Ezzel szemben, ha az irreleváns dokumentumok elvonják a válaszokat, növelje a küszöbértéket (az értéket 5-höz közelebb állítsa). Ez az strictness API paramétere, és alapértelmezés szerint 3 értékre van állítva. |
Lehetséges, hogy a modell az API helyett "TYPE":CONTENT az adatforrásból lekért, de az idézetben nem szereplő dokumentumokhoz tér vissza"TYPE":"UNCITED_REFERENCE". Ez hasznos lehet a hibakereséshez, és ezt a viselkedést a fent ismertetett szigorúsági és lekéréses dokumentumok futtatókörnyezeti paramétereinek módosításával szabályozhatja.
Az Azure OpenAI On Your Data használatakor megadhat egy rendszerüzenetet a modell válaszának irányításához. Ez az üzenet lehetővé teszi a válaszok testreszabását az Azure OpenAI on Your Data által használt kibővített generációs (RAG) minta alapján. A rendszerüzenet a belső alapkérésen kívül a felhasználói élmény biztosításához is használható. Ennek támogatásához egy adott számú jogkivonat után csonkítjuk a rendszerüzenetet , hogy a modell válaszolhasson az adatokkal kapcsolatos kérdésekre. Ha az alapértelmezett felületen felül további viselkedést határoz meg, győződjön meg arról, hogy a rendszerkérés részletes, és elmagyarázza a pontos elvárt testreszabást.
Miután kiválasztotta az adatkészlet hozzáadását, használhatja az Azure AI Foundry portál Rendszerüzenet szakaszát vagy az role_informationAPI paraméterét.

Szerepkör definiálása
Meghatározhat egy szerepkört, amelyet az asszisztensének szeretne. Ha például egy támogatási robotot hoz létre, felveheti a "Ön egy szakértői incidenstámogatási asszisztens, amely segít a felhasználóknak az új problémák megoldásában".
A lekérendő adatok típusának meghatározása
Az asszisztensnek megadott adatok természetét is hozzáadhatja.
A kimeneti stílus definiálása
A modell kimenetét rendszerüzenet definiálásával is módosíthatja. Ha például meg szeretné győződni arról, hogy az asszisztens válaszai franciául vannak, hozzáadhat egy olyan kérdést, mint például : "Ön egy AI-asszisztens, amely segít a franciául értő felhasználóknak az információk megtalálásában. A felhasználói kérdések lehetnek angol vagy francia nyelven. Kérjük, olvassa el figyelmesen a lekért dokumentumokat, és válaszoljon rájuk franciául. Kérjük, lefordítsa a tudást a dokumentumokból franciára, hogy minden válasz francia nyelven legyen."
Kritikus viselkedés megerősítése
Az Azure OpenAI On Your Data úgy működik, hogy utasításokat küld egy nagy nyelvi modellnek az adatok felhasználói lekérdezéseinek megválaszolására vonatkozó kérések formájában. Ha van egy bizonyos viselkedés, amely kritikus fontosságú az alkalmazás számára, megismételheti a viselkedést a rendszerüzenetben a pontosság növelése érdekében. Ha például azt szeretné, hogy a modell csak dokumentumokból válaszoljon, hozzáadhatja a "Válasz csak lekért dokumentumok használatával, a tudás használata nélkül. Hozzon létre idézeteket a válaszban szereplő összes jogcím dokumentumainak lekéréséhez. Ha a felhasználói kérdést nem lehet megválaszolni a lekért dokumentumok használatával, kérjük, magyarázza el, hogy miért relevánsak a dokumentumok a felhasználói lekérdezések szempontjából. Mindenesetre ne a saját tudása alapján válaszoljon."
Parancssori mérnöki trükkök
Számos trükk van a gyors tervezésben, amelyeket megpróbálhat javítani a kimeneten. Az egyik példa a gondolatláncra való rákérdezés, ahová felveheti a következőt: "Gondoljuk át lépésről lépésre a lekért dokumentumok információiról a felhasználói lekérdezések megválaszolásához. A dokumentumokból lépésről lépésre kinyerheti a releváns ismereteket a felhasználói lekérdezésekből, és a megfelelő dokumentumokból kinyert információkból alulról választ alkothat."
Megjegyzés
A rendszerüzenet segítségével módosíthatja, hogy a GPT-asszisztens hogyan válaszol egy felhasználói kérdésre a lekért dokumentáció alapján. Ez nem befolyásolja a lekérési folyamatot. Ha útmutatást szeretne adni a lekérési folyamathoz, jobb, ha belefoglalja őket a kérdésekbe. A rendszerüzenet csak útmutatás. Előfordulhat, hogy a modell nem tartja be az összes megadott utasítást, mert bizonyos viselkedésekkel, például az objektivitással és az ellentmondásos állítások elkerülésével lett előállítva. Váratlan viselkedés akkor fordulhat elő, ha a rendszerüzenet ellentmond ezeknek a viselkedéseknek.
Ez a beállítás arra ösztönzi a modellt, hogy csak az ön adataival válaszoljon, és alapértelmezés szerint ki van választva. Ha nem választja ki ezt a beállítást, a modell könnyebben alkalmazhatja a belső tudását a válaszadáshoz. A használati eset és a forgatókönyv alapján határozza meg a megfelelő kijelölést.
A modellel folytatott csevegés során az alábbi eljárásokkal érheti el a legjobb eredményeket.
Beszélgetési előzmények
Modell válasza
Ha nem elégedett egy adott kérdés modellválaszával, próbálja meg konkrétabbá vagy általánosabbá tenni a kérdést, hogy lássa, hogyan reagál a modell, és ennek megfelelően újrakeretezi a kérdést.
A gondolatlánc-rákérdezés hatékonynak bizonyult abban, hogy a modell összetett kérdésekhez/feladatokhoz kívánt kimeneteket állít elő.
Kérdés hossza
Kerülje a hosszú kérdések feltevését, és ha lehetséges, több kérdésre bontsa őket. A GPT-modellek korlátokkal rendelkeznek az elfogadható jogkivonatok számára vonatkozóan. A jogkivonatok korlátai a következőkre számítanak: a felhasználói kérdés, a rendszerüzenet, a lekért keresési dokumentumok (adattömbök), a belső kérések, a beszélgetési előzmények (ha vannak ilyenek) és a válasz. Ha a kérdés túllépi a jogkivonat korlátját, a rendszer csonkolja.
Többnyelvű támogatás
Az Azure OpenAI On Your Data szolgáltatásban jelenleg a kulcsszókeresés és a szemantikai keresés támogatja a lekérdezéseket, és az indexben lévő adatokkal azonos nyelven vannak. Ha például az adatok japán nyelvűek, akkor a bemeneti lekérdezéseket is japán nyelven kell megadni. A többnyelvű dokumentumok lekéréséhez javasoljuk, hogy az indexet engedélyezze a Vektorkeresés funkcióval.
Az információlekérés és a modellválasz minőségének javítása érdekében javasoljuk, hogy engedélyezze a szemantikai keresést a következő nyelvekre: angol, francia, spanyol, portugál, olasz, német, kínai (Zh), japán, koreai, orosz, arab
Javasoljuk, hogy egy rendszerüzenettel tájékoztassa a modellt arról, hogy az adatok más nyelven találhatóak. Példa:
*"*Ön egy AI-asszisztens, amelyet arra terveztek, hogy segítsen a felhasználóknak kinyerni az információkat a lekért japán dokumentumokból. Mielőtt választ ad, gondosan vizsgálja meg a japán dokumentumokat. A felhasználó lekérdezése japán nyelven lesz, és japánul is válaszolnia kell."
Ha több nyelven is rendelkezik dokumentumokkal, javasoljuk, hogy minden nyelvhez hozzon létre egy új indexet, és külön csatlakoztassa őket az Azure OpenAI-hoz.
Streamelési kérést küldhet a stream paraméterrel, így az adatok növekményesen küldhetők és fogadhatók anélkül, hogy a teljes API-válaszra kellene várniuk. Ez javíthatja a teljesítményt és a felhasználói élményt, különösen a nagy vagy dinamikus adatok esetében.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Ha egy modellel cseveg, a csevegés előzményeinek megadásával a modell jobb minőségű eredményeket ad vissza. A jobb válaszminőség érdekében nem kell belefoglalnia a context segédüzenetek tulajdonságát az API-kérésekbe. Példákért tekintse meg az API referenciadokumentációját .
Egyes Azure OpenAI-modellek lehetővé teszik eszközök és tool_choice paraméterek definiálására a függvényhívás engedélyezéséhez. A rest API-val /chat/completionshívható függvények beállíthatók. Ha mind tools az adatforrások szerepelnek a kérelemben, a rendszer a következő szabályzatot alkalmazza.
tool_choice igen none, a rendszer figyelmen kívül hagyja az eszközöket, és csak az adatforrások használják a választ.tool_choice nincs megadva, vagy objektumként auto van megadva, a rendszer figyelmen kívül hagyja az adatforrásokat, és a válasz tartalmazza a kiválasztott függvények nevét és az argumentumokat, ha vannak ilyenek. Még ha a modell úgy dönt, hogy nincs kiválasztva függvény, az adatforrások továbbra is figyelmen kívül maradnak.Ha a fenti szabályzat nem felel meg az igényeinek, fontolja meg más lehetőségeket is, például: prompt flow vagy Assistants API.
Az Azure OpenAI On Your Data Retrieveal Augmented Generation (RAG) egy olyan szolgáltatás, amely a keresési szolgáltatás (például az Azure AI Search) és a generációs (Azure OpenAI-modellek) használatával lehetővé teszi, hogy a felhasználók a megadott adatok alapján választ kaphassanak kérdéseikre.
Ennek a RAG-folyamatnak a részeként három lépés áll rendelkezésre magas szinten:
A felhasználói lekérdezés átalakítása a keresési szándékok listájára. Ezt úgy végezheti el, hogy egy utasításokat, a felhasználói kérdést és a beszélgetési előzményeket tartalmazó üzenettel hívja meg a modellt. Hívjuk ezt szándékkérésnek.
Minden szándékhoz több dokumentumtömb lesz lekérve a keresési szolgáltatásból. Miután a felhasználó által megadott szigorúsági küszöbérték alapján szűrte ki az irreleváns adattömböket, és belső logikán alapuló adattömböket adott át/összesít, a rendszer kiválasztja a felhasználó által megadott számú dokumentumtömböt.
Ezeket a dokumentumrészleteket, valamint a felhasználói kérdést, a beszélgetési előzményeket, a szerepkör-információkat és az utasításokat a rendszer elküldi a modellnek a végső modellválasz létrehozásához. Hívjuk ezt a generációs kérésnek.
A modellnek összesen két hívása van:
A szándék feldolgozásához: A szándékkérelem jogkivonat-becslése tartalmazza a felhasználói kérdéshez, a beszélgetési előzményekhez és a modellnek a szándékgeneráláshoz küldött utasításokat.
A válasz létrehozásához: A generációs kérdés jogkivonat-becslése tartalmazza a felhasználói kérdéshez, a beszélgetési előzményekhez, a dokumentumtömbök lekért listájához, a szerepkör-információkhoz és a generációhoz küldött utasításokat.
A modell által létrehozott kimeneti jogkivonatokat (mind a szándékokat, mind a választ) figyelembe kell venni a teljes jogkivonat-becsléshez. Az alábbi négy oszlop összegzése a válasz létrehozásához használt átlagos összes jogkivonatot adja meg.
| Modell | Parancssori jogkivonatok száma | Szándékkérési jogkivonatok száma | Válasz jogkivonatok száma | Szándék jogkivonatának száma |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
A fenti számok egy olyan adatkészleten végzett tesztelésen alapulnak, amely a következőkkel rendelkezik:
És a következő paraméterek.
| Beállítás | Érték |
|---|---|
| Lekért dokumentumok száma | 5 |
| Szigorúság | 3 |
| Adattömb mérete | 1024 |
| Korlátozza a betöltött adatokra adott válaszokat? | Igaz |
Ezek a becslések a fenti paraméterekhez beállított értékektől függően változnak. Ha például a lekért dokumentumok száma 10, a szigorúság pedig 1, akkor a jogkivonatok száma megnő. Ha a visszaadott válaszok nem korlátozódnak a betöltött adatokra, kevesebb utasítást kap a modell, és a jogkivonatok száma csökken.
A becslések a dokumentumok jellegétől és a feltett kérdésektől is függenek. Ha például a kérdések nyitottak, a válaszok valószínűleg hosszabbak lesznek. Hasonlóképpen egy hosszabb rendszerüzenet is hozzájárul egy hosszabb, több jogkivonatot használó kérdéshez, és ha a beszélgetési előzmények hosszúak, a kérés hosszabb lesz.
| Modell | A rendszerüzenethez tartozó jogkivonatok maximális kihasználása |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000. |
| GPT-35-turbo-0125 | 2000. |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
A fenti táblázat a rendszerüzenethez használható jogkivonatok maximális számát mutatja. A modellválasz maximális jogkivonatainak megtekintéséhez tekintse meg a modellekről szóló cikket. Emellett a következők is használnak jogkivonatokat:
A metaüzenet: ha a modell válaszait az alapozó adattartalomra (inScope=True az API-ban) korlátozza, a jogkivonatok maximális száma magasabb. Ellenkező esetben (például ha inScope=False) a maximális érték alacsonyabb. Ez a szám a felhasználói kérdés és beszélgetés előzményeinek tokenhosszától függően változó. Ez a becslés tartalmazza az alapkérést és a lekérdezés újraírását kérő kéréseket a lekéréshez.
Felhasználói kérdés és előzmények: Változó, de 2000 jogkivonatra van megfeleltetve.
Lekért dokumentumok (adattömbök): A lekért dokumentumtömbök által használt tokenek száma több tényezőtől függ. Ennek felső határa a beolvasott dokumentumtömbök száma és az adattömb méretének szorzata. A többi mező megszámlálása után azonban csonkolja az adott modellhez használt jogkivonatok alapján.
Az elérhető jogkivonatok 20%-a a modell válaszához van fenntartva. Az elérhető jogkivonatok fennmaradó 80%-a tartalmazza a metaüzenetet, a felhasználói kérdést és a beszélgetési előzményeket, valamint a rendszerüzenetet. A fennmaradó jogkivonat-költségvetést a lekért dokumentumtömbök használják.
A bemenet által felhasznált tokenek számának kiszámításához (például a kérdés, a rendszerüzenet/szerepkör adatai) használja az alábbi kódmintát.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
A sikertelen műveletek hibaelhárításához mindig keresse meg az API-válaszban vagy az Azure AI Foundry portálon megadott hibákat vagy figyelmeztetéseket. Íme néhány gyakori hiba és figyelmeztetés:
Kvótakorlátozásokkal kapcsolatos problémák
Nem hozható létre X nevű index az Y szolgáltatásban. A szolgáltatás indexkvótája túllépte az indexkvótát. Először törölnie kell a nem használt indexeket, késleltetnie kell az indexlétrehozási kérelmeket, vagy frissítenie kell a szolgáltatást a magasabb korlátok érdekében.
A szolgáltatás esetében túllépte az X standard indexelőkvótát. Jelenleg X standard indexelőkkel rendelkezik. Először törölnie kell a nem használt indexelőket, módosítania kell a "executionMode" indexelőt, vagy frissítenie kell a szolgáltatást a magasabb korlátok érdekében.
Megoldás:
Frissítsen magasabb tarifacsomagra, vagy törölje a nem használt eszközöket.
Időtúllépési problémák előfeldolgozása
Nem sikerült végrehajtani a képességet, mert a webes API-kérés meghiúsult
Nem sikerült végrehajtani a képességet, mert a webes API-képesség válasza érvénytelen
Megoldás:
Bontsa le a bemeneti dokumentumokat kisebb dokumentumokra, és próbálkozzon újra.
Engedélyekkel kapcsolatos problémák
Ez a kérés nem jogosult a művelet végrehajtására
Megoldás:
Ez azt jelenti, hogy a tárfiók nem érhető el a megadott hitelesítő adatokkal. Ebben az esetben tekintse át az API-nak átadott tárfiók hitelesítő adatait, és győződjön meg arról, hogy a tárfiók nem rejthető el privát végpont mögött (ha egy privát végpont nincs konfigurálva ehhez az erőforráshoz).
Minden felhasználói üzenet több keresési lekérdezésre is lefordítható, amelyek mindegyike párhuzamosan lesz elküldve a keresési erőforrásnak. Ez szabályozást eredményezhet, ha a keresési replikák és partíciók száma alacsony. Előfordulhat, hogy egy partíció és egy replika által támogatott másodpercenkénti lekérdezések maximális száma nem elegendő. Ebben az esetben fontolja meg a replikák és partíciók növelését, vagy az alvó/újrapróbálkozások logikáját az alkalmazásban. További információkért tekintse meg az Azure AI Search dokumentációját .
Megjegyzés
Az Azure OpenAI nem támogatja a következő modelleket az Adatain:
| Régió | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Kelet-Ausztrália | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Kelet-Kanada | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| USA keleti régiója | ✅ | ✅ | ✅ | |||||
| USA 2. keleti régiója | ✅ | ✅ | ✅ | ✅ | ||||
| Közép-Franciaország | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Kelet-Japán | ✅ | |||||||
| USA északi középső régiója | ✅ | ✅ | ✅ | |||||
| Kelet-Norvégia | ✅ | ✅ | ||||||
| USA déli középső régiója | ✅ | ✅ | ||||||
| Dél-India | ✅ | ✅ | ||||||
| Közép-Svédország | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Észak-Svájc | ✅ | ✅ | ✅ | |||||
| Az Egyesült Királyság déli régiója | ✅ | ✅ | ✅ | ✅ | ||||
| USA nyugati régiója | ✅ | ✅ | ✅ |
**Ez csak szöveges implementáció
Ha az Azure OpenAI-erőforrás egy másik régióban található, nem fogja tudni használni az Azure OpenAI-t az adatain.
esemény
Intelligens alkalmazások létrehozása
márc. 17. 21 - márc. 21. 10
Csatlakozzon a meetup sorozathoz, hogy valós használati esetek alapján, skálázható AI-megoldásokat hozzon létre más fejlesztőkkel és szakértőkkel.
RegisztrációOktatás
Modul
Utilize an Azure OpenAI model to create an app - Training
Upon completing this module, you'll be prepared to deploy an application to Microsoft Teams using Azure OpenAI resources.
Tanúsítvány
Microsoft Tanúsítvány: Azure AI Mérnök Társ=minősítéssel Rendelkező - Certifications
Azure AI-megoldás tervezése és implementálása Az Azure AI-szolgáltatások, az Azure AI Search és az Azure Open AI használatával.
Dokumentáció
Saját adatok használata az Azure OpenAI szolgáltatással - Azure OpenAI
Ebből a cikkből importálhatja és használhatja adatait az Azure OpenAI-ban.
Ajánlott eljárások az Azure OpenAI adatokon való használatához - Azure OpenAI Service
Megismerheti az Azure OpenAI on Your Data használatának ajánlott eljárásait, valamint a gyakori problémák megoldását.
Azure OpenAI az Azure Search-adatokon – Python & REST API-referencia - Azure OpenAI
Megtudhatja, hogyan használhatja az Azure OpenAI-t az Azure Search-adatok Python & REST API-ján.